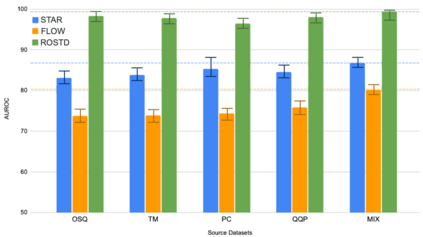
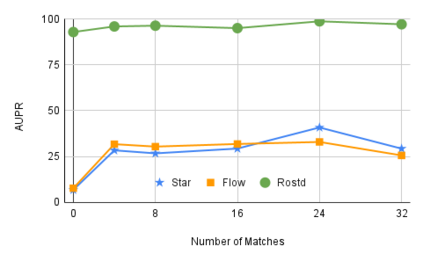
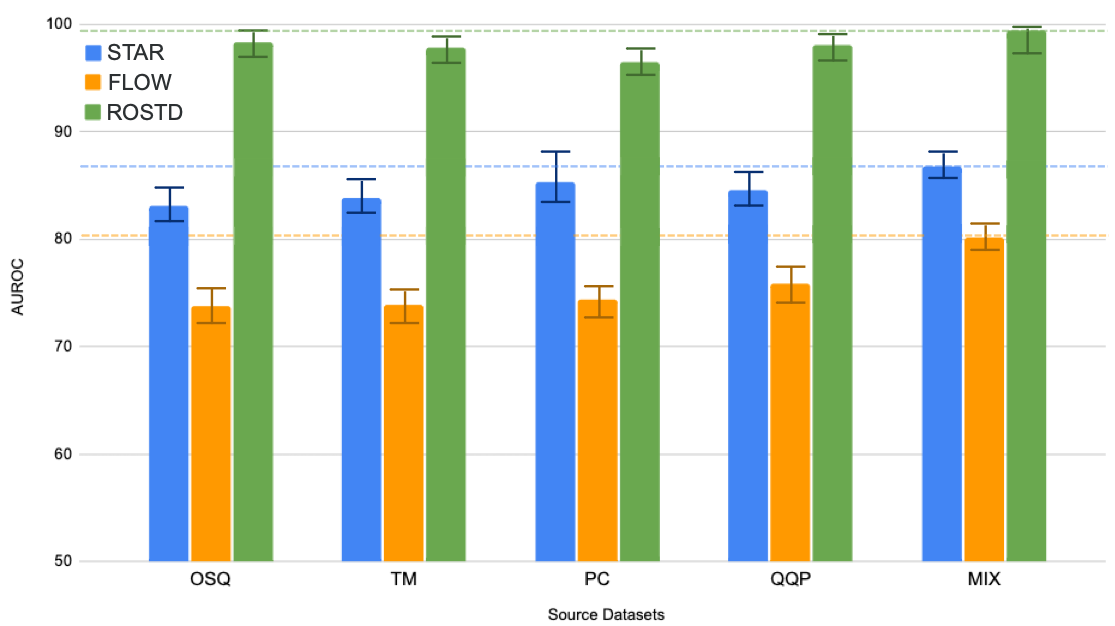
Practical dialogue systems require robust methods of detecting out-of-scope (OOS) utterances to avoid conversational breakdowns and related failure modes. Directly training a model with labeled OOS examples yields reasonable performance, but obtaining such data is a resource-intensive process. To tackle this limited-data problem, previous methods focus on better modeling the distribution of in-scope (INS) examples. We introduce GOLD as an orthogonal technique that augments existing data to train better OOS detectors operating in low-data regimes. GOLD generates pseudo-labeled candidates using samples from an auxiliary dataset and keeps only the most beneficial candidates for training through a novel filtering mechanism. In experiments across three target benchmarks, the top GOLD model outperforms all existing methods on all key metrics, achieving relative gains of 52.4%, 48.9% and 50.3% against median baseline performance. We also analyze the unique properties of OOS data to identify key factors for optimally applying our proposed method.
翻译:实际对话系统要求用强有力的方法来探测外望(OOS)语句,以避免谈话破裂和相关故障模式。直接以贴有标签的OOS示例进行模型培训可以产生合理的性能,但获得这些数据是一个资源密集型的过程。为了解决这一有限的数据问题,以往的方法侧重于更好地模拟在范围(INS)中实例的分布。我们采用GOLD,作为一种正统技术,以扩大现有数据,培训在低数据系统中运行的更好的OOS探测器。GOLD利用辅助数据集的样本生成假标的候选数据,并且仅保留最有利的候选数据,通过新颖的过滤机制进行培训。在三个目标基准的实验中,顶级GOLD模型比所有关键指标都优于所有现有方法,相对基准性能达到52.4%、48.9%和50.3%的相对收益。我们还分析了OOS数据的独特性,以确定最佳应用我们拟议方法的关键因素。