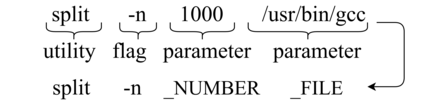
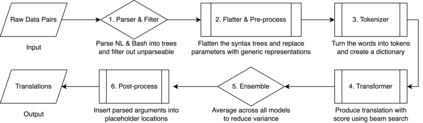
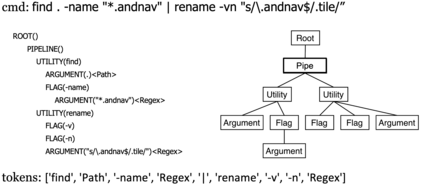
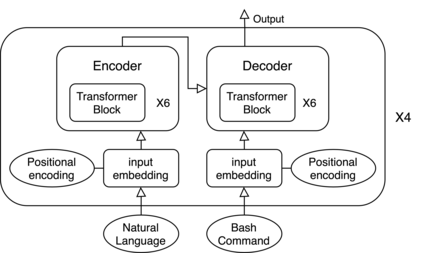
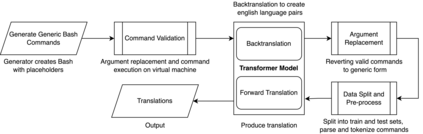
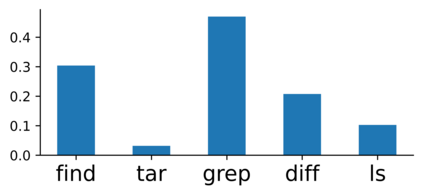
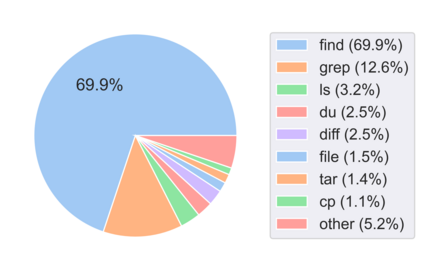
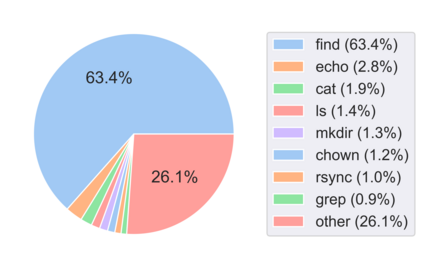
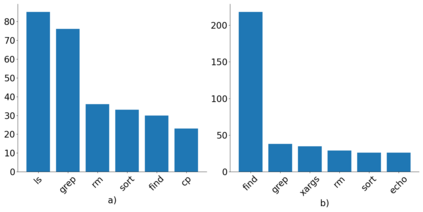
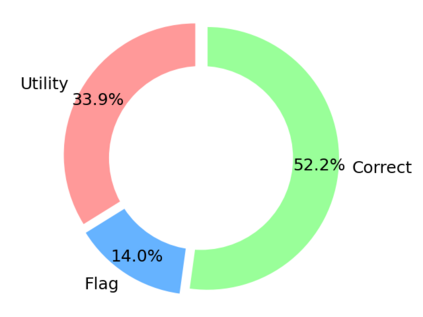
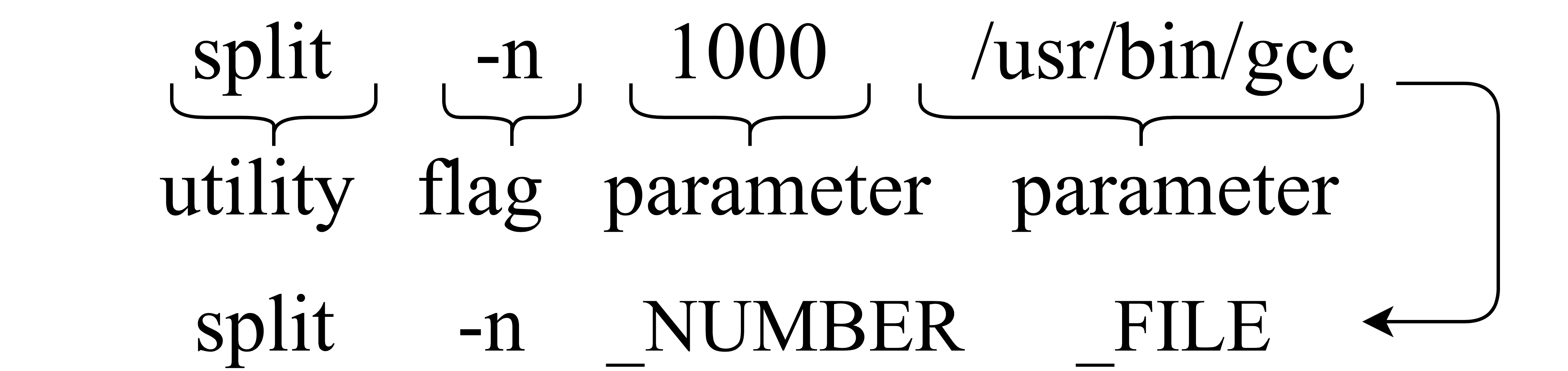
Translating natural language into Bash Commands is an emerging research field that has gained attention in recent years. Most efforts have focused on producing more accurate translation models. To the best of our knowledge, only two datasets are available, with one based on the other. Both datasets involve scraping through known data sources (through platforms like stack overflow, crowdsourcing, etc.) and hiring experts to validate and correct either the English text or Bash Commands. This paper provides two contributions to research on synthesizing Bash Commands from scratch. First, we describe a state-of-the-art translation model used to generate Bash Commands from the corresponding English text. Second, we introduce a new NL2CMD dataset that is automatically generated, involves minimal human intervention, and is over six times larger than prior datasets. Since the generation pipeline does not rely on existing Bash Commands, the distribution and types of commands can be custom adjusted. Our empirical results show how the scale and diversity of our dataset can offer unique opportunities for semantic parsing researchers.
翻译:将自然语言转换成 Bash 指令是一个新兴的研究领域,近年来引起了人们的注意。 大部分努力都集中在制作更准确的翻译模型上。 根据我们的最佳知识,只有两个数据集, 其中一个基于另一个。 两个数据集都涉及通过已知的数据源( 诸如堆叠溢、 众包等平台) 进行分类, 以及雇用专家来验证和校正英文文本或 Bash 指令。 本文为从零开始合成 Bash 指令的研究提供了两项贡献。 首先, 我们描述了用于从相应的英文文本中生成 Bash 指令的最先进的翻译模型。 其次, 我们引入了一个新的 NL2CMD 数据集, 该数据集是自动生成的, 涉及最低限度的人类干预, 比先前的数据集大六倍以上。 由于生成的管道不依赖于现有的 Bash 指令, 命令的分布和类型可以自定调整。 我们的实验结果显示我们数据集的规模和多样性如何为语义分析者提供独特的机会 。