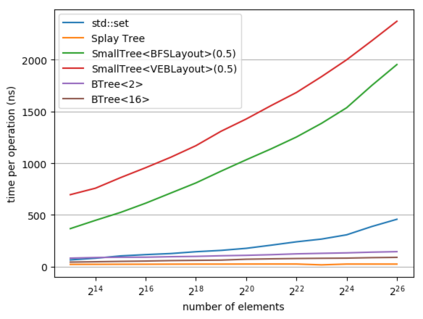
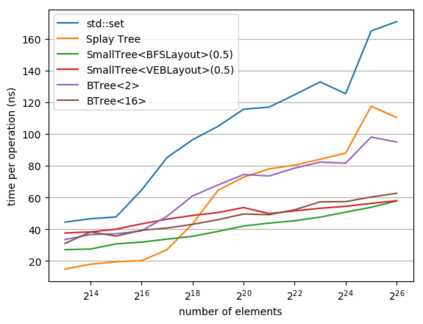
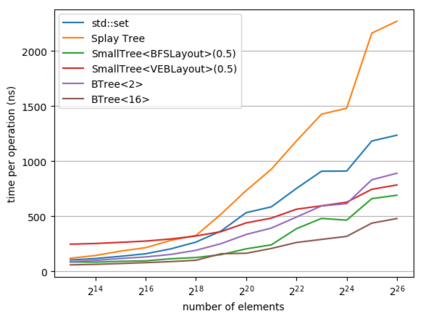
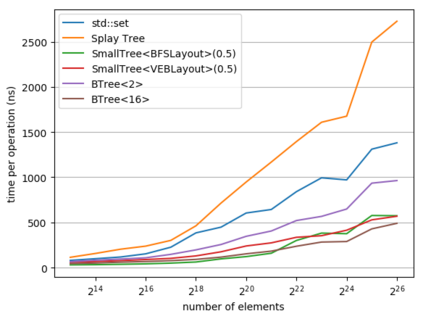
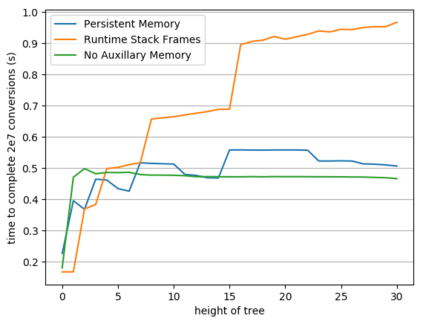
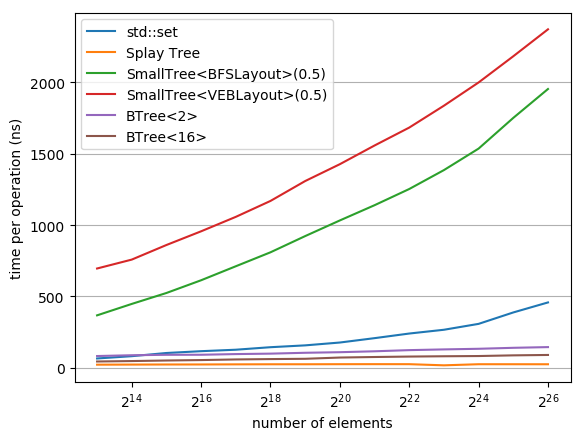
While a lot of work in theoretical computer science has gone into optimizing the runtime and space usage of data structures, such work very often neglects a very important component of modern computers: the cache. In doing so, very often, data structures are developed that achieve theoretically-good runtimes but are slow in practice due to a large number of cache misses. In 1999, Frigo et al. introduced the notion of a cache-oblivious algorithm: an algorithm that uses the cache to its advantage, regardless of the size or structure of said cache. Since then, various authors have designed cache-oblivious algorithms and data structures for problems from matrix multiplication to array sorting. We focus in this work on cache-oblivious search trees; i.e. implementing an ordered dictionary in a cache-friendly manner. We will start by presenting an overview of cache-oblivious data structures, especially cache-oblivious search trees. We then give practical results using these cache-oblivious structures on modern-day machinery, comparing them to the standard std::set and other cache-friendly dictionaries such as B-trees.
翻译:虽然在理论计算机科学方面做了大量工作,以优化数据结构的运行时间和空间使用,但这类工作往往忽视了现代计算机中非常重要的组成部分:缓存。在这样做的过程中,常常开发出实现理论上良好的运行时间的数据结构,但实际上由于大量缓存缺失而进展缓慢。1999年,Frigo等人提出了缓存隐蔽算法的概念:一种使用缓存的算法,而不管缓存的大小或结构如何。此后,各种作者设计了缓存隐蔽算法和数据结构,以解决从矩阵乘法到阵列排序的问题。我们集中研究缓存隐蔽隐蔽的搜索树;即以方便缓存的方式执行有序的字典。我们首先要概要介绍缓存隐蔽性数据结构,特别是缓存隐蔽隐蔽隐蔽的搜索树。然后在现代机器上使用这些缓存隐蔽隐蔽结构,我们给出实际结果,将其与标准标准标准标准标准标准标准标准标准标准标准标准标准标准标准标准词:设置:便利和其他缓存的缓存词典,如B树。