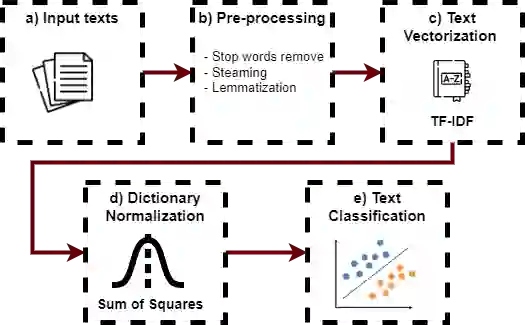
With the popularization of the internet, smartphones and social media, information is being spread quickly and easily way, which implies bigger traffic of information in the world, but there is a problem that is harming society with the dissemination of fake news. With a bigger flow of information, some people are trying to disseminate deceptive information and fake news. The automatic detection of fake news is a challenging task because to obtain a good result is necessary to deal with linguistics problems, especially when we are dealing with languages that not have been comprehensively studied yet, besides that, some techniques can help to reach a good result when we are dealing with text data, although, the motivation of detecting this deceptive information it is in the fact that the people need to know which information is true and trustful and which one is not. In this work, we present the effect the pre-processing methods such as lemmatization and stemming have on fake news classification, for that we designed some classifier models applying different pre-processing techniques. The results show that the pre-processing step is important to obtain betters results, the stemming and lemmatization techniques are interesting methods and need to be more studied to develop techniques focused on the Portuguese language so we can reach better results.
翻译:暂无翻译