- 1
- 2
- 3
- 4
- 5
- 6
- 1000

项目名称: 复杂数据的统计分析与建模
项目编号: No.11171012
项目类型: 面上项目
立项/批准年度: 2012
项目学科: 数理科学和化学
项目作者: 薛留根
作者单位: 北京工业大学
项目金额: 40万元
中文摘要: 本项目主要致力于复杂数据下几种半参数回归模型的研究,其研究内容包括以下几个方面:第一,在时间删失的纵向数据下,研究变系数单指标模型的统计推断问题。提出新的估计和检验方法,发展变量选择方法;研究所提出的估计量的大样本性质。第二,在纵向数据、缺失数据或删失数据下,研究变系数部分线性EV模型的参数估计、模型检验和变量选择问题;探索参数估计和变量选择同时完成的方法。第三,在纵向数据、缺失数据或删失数据下,研究超高维数据下部分线性EV模型和部分线性单指标EV模型的变量选择问题,发展降维方法。第四,进行实际应用研究。探讨复杂数据的统计建模技术,研究如何将所得到的统计方法和理论结果应用到解决实际问题之中。本课题的研究成果将丰富和发展复杂数据的统计分析方法,从而为生物医学、计量经济学、环境科学、社会科学以及公共卫生和健康等领域的研究提供科学的理论依据。
中文关键词: 复杂数据;半参数回归模型;纵向数据;缺失数据;统计推断
英文摘要:
英文关键词: Complicated data;semiparametric regression model;longitudinal data;missing data;statistics inference
项目名称: 单片式集成光学陀螺基础研究
项目编号: No.61171004
项目类型: 面上项目
立项/批准年度: 2012
项目学科: 无线电电子学、电信技术
项目作者: 冯丽爽
作者单位: 北京航空航天大学
项目金额: 62万元
中文摘要: 针对未来信息化系统对微小型化、高可靠性惯性器件的迫切需求,开展单片式集成光学陀螺技术研究。揭示窄线宽半导体激光器频率稳定机理和微纳尺度下导波机制,建立陀螺系统仿真分析平台;探索有源器件与无源器件的单片集成和工艺兼容性问题,确定光波导结构一体化集成的精密加工方法;开展陀螺单片集成封装技术研究,为下一步应用提供技术支撑。通过物理学、光学工程、微纳米技术等学科的交叉融合,深入研究光电子集成技术、微纳米跨尺度制造技术、高效光电耦合技术等前沿科学问题,争取在微纳光学惯性器件技术上取得重大突破,为我国微小型惯性器件及系统的研究和应用提供核心竞争力。
中文关键词: 陀螺;集成光学;单片式;光电子集成;
英文摘要:
英文关键词: Gyroscope;Integrated optic;Single-chip;Opto-electronic Integrated;
项目名称: 幼苗定居过程中根区水氮对骆驼刺根系生物学特性调节的研究
项目编号: No.31200352
项目类型: 青年科学基金项目
立项/批准年度: 2013
项目学科: 生物科学
项目作者: 黄彩变
作者单位: 中国科学院新疆生态与地理研究所
项目金额: 25万元
中文摘要: 骆驼刺为塔里木盆地南缘绿洲-沙漠过渡带上的优势建群种植物,已出现退化,在水分和养分共同胁迫下很难实现自然更新;但多年生骆驼刺可通过发达的根系来接触地下水生存。因此,如何通过人工措施调控根系生长,尽快实现骆驼刺幼苗的成功定居是当前期待解决的关键问题。依托策勒国家站长期生态学试验场和人工控制试验小区,结合田间和盆栽试验,通过调节根区水氮条件,采用人工挖掘法、15N标记和15N自然丰度法等,分析骆驼刺幼苗根系生长动态和分布规律、根系结瘤和固氮能力以及植物氮素分配和利用特征对根区水氮条件变化的响应和适应;探明骆驼刺幼苗根系未接触地下水之前,生物固氮对其适应环境胁迫的贡献;查明氮素营养在骆驼刺幼苗根系生长中的作用;阐明水氮组合对其根系生长和分布的影响,证明根区水氮调节是否为骆驼刺植被恢复过程中的有效措施。以期形成骆驼刺人工恢复过程中的水氮调节技术,为干旱区优势植物的修复提供理论依据和技术指导。
中文关键词: 骆驼刺;水氮交互;根系;根瘤;生物固氮
英文摘要: In arid ecosystems, plant life and distribution is limited by the spatial and temporal availability of water and nutrients. Observation suggests plants in such ecosystems develop, almost exclusively, deep root systems to reach moist soil layers and ground
英文关键词: Alhagi sparsifolia;water and nitrogen interaction;root;nodules;biological nitrogen fixation
项目名称: 基于现代GNSS测量的编队星载InSAR系统时空动态基线确定
项目编号: No.60902089
项目类型: 青年科学基金项目
立项/批准年度: 2010
项目学科: 金属学与金属工艺
项目作者: 姚静
作者单位: 中国人民解放军国防科学技术大学
项目金额: 20万元
中文摘要: 星载InSAR系统是当前国际遥感领域先进的测绘侦察体制之一,分布式卫星平台之间的时空动态基线高精度获取则是其成功实现的重要前提。基线确定过程包含了大量复杂非确定模型与参数而不利于高精度解算,星间相对运动的高度动态性与收发波束的时间差异性更是增加了编队空间环境下保精度获取高数据率基线信息的难度。本项目拟揭示基线时空动态变化规律,阐明现代GNSS测量编队星间基线的机制,提供基线确定的先进理论,包括:合理的数据信息开采、可靠的观测模型与误差模型、精确的相对运动最优参数化表示模型、有效的融合估计方法、整周模糊度解算与校验方法、星间状态到基线的映射转换模型以及客观的评价体系等,从而获取复杂空间环境下的高精度时空动态基线。同时结合我国"北斗"二代导航系统,研究InSAR基线测量新体制与新方法,给出客观的精度评价体系,提供GNSS测量信息优质开采的思路,为编队精确控制和科学数据的精确解译奠定基础。
中文关键词: 编队星载InSAR系统;编队空间环境;时空动态基线;简化动力学模型;最优表示模型
英文摘要:
英文关键词: spaceborne distributed InSAR;formation flying environment;dynamic baseline;reduced dynamic model;optimal representation model
项目名称: 联立求解高温气冷堆多物理场多尺度多回路问题的方法研究
项目编号: No.11375099
项目类型: 面上项目
立项/批准年度: 2013
项目学科: 数理科学和化学
项目作者: 李富
作者单位: 清华大学
项目金额: 96万元
中文摘要: 高温气冷堆核电站是一个大型、复杂、耦合的非线性动态系统,包含反应堆、蒸汽发电回路、余热排出系统等耦合回路,具有多物理场、多回路、多尺度等多种耦合方式。当前多采用各变量之间反复显式迭代的计算方法,仅能实现子系统单独求解或少数几个子系统的耦合求解,存在计算效率低、计算精度低、稳定性差的问题,很难扩展到大规模、多系统的完整系统。针对包含堆芯、一回路、蒸汽发生器、蒸汽发电回路、余热排出系统的耦合、完整的高温气冷堆电站,课题拟采用Jacobian free Newton Krylov(JFNK)框架,研究高效的基于物理的Krylov子空间预处理方法,针对多物理场、多回路、多尺度的不同耦合方式发展不同的处理方式,并集成JFNK框架下,联立求解这个耦合的系统,最终实现高温气冷堆核电站系统的高效、稳定、精确的整体联立求解。这样的处理方式和分析程序未见先例,发展的算法和开发的程序将具有可扩展性。
中文关键词: JFNK;高温气冷堆;多物理;多尺度;多回路
英文摘要: As a large, complicated, coupled, nonlinear dynamics system, High Temperature Gas Cooled Reactor (HTR) power plant contains many coupled parts such as the reactor, steam turbine, residual heat removal system. The coupling types between HTR subsystems incl
英文关键词: JFNK;High Temperature gas cooled reactor;Multi-physics;Multi-Scale;Multi-Circuit
项目名称: CSE和CBS对胎盘血管生成因子和抗血管生成因子的调节作用及其与子痫前期发生和发展的关系
项目编号: No.81370734
项目类型: 面上项目
立项/批准年度: 2013
项目学科: 医药、卫生
项目作者: 倪鑫
作者单位: 中国人民解放军第二军医大学
项目金额: 70万元
中文摘要: 胎盘产生过量抗血管生成因子和较少血管生成因子是导致子痫前期血管内皮损伤的重要原因。我们以往研究表明胎盘表达与H2S和同型半胱氨酸代谢有关的酶- - 胱硫醚β合成酶(CBS)和胱硫醚γ合酶(CSE),CSE和CBS在子痫前期胎盘表达降低,同时H2S生成减少及同型半胱氨酸升高,这两种酶与血管生成因子VEGF呈正相关、与抗血管生成因子sFlt1呈负相关,提示它们参与胎盘血管生成因子和抗血管生成因子的调节。我们将进一步研究由这两种酶产生的H2S、同型半胱氨酸对胎盘细胞血管生成因子和抗血管生成因子的调节及其分子机制;胎盘这两种酶表达减少是否导致子痫前期的表现、血中抗血管生成因子增多而血管生成因子减少以及同型半胱氨酸的蓄积;胎盘缺血是否可导致这两种酶表达的减少、H2S生成减少、同型半胱氨酸的蓄积;过表达这两种酶是否可改善子痫前期的表现等,以阐明这两种酶在子痫前期发病中的作用及其可能的分子机制。
中文关键词: 胎盘;子痫前期;硫化氢;抗血管生成因子;血管生成因子
英文摘要: It is known that excess amount of antiangiogenic factors released by placenta is critical to dysfunction of endothelia in preeclampsia (PE). The mechanisms underlying regulation of angiogenic factors and antiangiogenic factors remain largely unknown. We h
英文关键词: placenta;preeclampsia;hydrogen sulfide;angiogenic factors;antiangiogenic fators
项目名称: miR-15a/16a簇在金葡菌诱导的奶牛乳腺炎症反应中的调控作用及其分子机制
项目编号: No.31401050
项目类型: 青年科学基金项目
立项/批准年度: 2014
项目学科: 生物科学
项目作者: 鞠志花
作者单位: 山东省农业科学院
项目金额: 25万元
中文摘要: 奶牛乳腺炎是由多种病原体感染引起的重要疾病。我们通过健康和金葡菌感染的乳腺炎奶牛乳腺组织miRNA表达芯片实验,发现并验证了乳腺炎奶牛的miR-15a/16a簇表达明显下调。我们推测miR-15a/16a簇可能通过调控下游TNFSF13B、CXCL10和CD163等免疫相关靶基因和炎症因子的表达,在乳腺炎症反应中发挥功能。拟通过Q-PCR和原位杂交定量和定位该miRNA簇在健康和金葡菌感染奶牛乳腺组织和中性粒细胞中的表达;利用热灭活的金葡菌诱导乳腺上皮细胞建立实验模型,在此基础上,采用基因过表达、抑制表达、免疫荧光、流式细胞等技术,检测该miRNA簇在炎症反应中的调控作用;分析miR-15a/16a簇成员的表达模式,比较该miRNA簇与单个miRNA对下游蛋白及炎症因子表达的影响。研究结果以期阐明miR-15a/16a簇在金葡菌诱导乳腺炎症反应中的调控机制,为奶牛乳腺炎抗病育种提供依据。
中文关键词: 奶牛;乳腺炎;bta-miR-15a/16a簇;金黄色葡葡球菌;调控机制
英文摘要: Mastitis is a common disease caused by a variety of pathogens. We have compared the miRNA expression profiling of the mammary tissues between healthy cow and Staphylococcus aureus (Staph. aureus) infected mastitis cow using miRNA chips and Q-PCR methods.
英文关键词: cow;mastitis;bta-miR-15a/16a cluster;Staphylococcus aureus;regulatory mechanism
项目名称: 柴达木盆地东缘祁连圆柏树轮碳、氧和氢同位素长序列的建立及其气候意义
项目编号: No.40871002
项目类型: 面上项目
立项/批准年度: 2009
项目学科: 轻工业、手工业
项目作者: 刘晓宏
作者单位: 中国科学院寒区旱区环境与工程研究所
项目金额: 49万元
中文摘要: 柴达木盆地东缘山地生长着对气候变化敏感的千年祁连圆柏,结合德令哈和乌兰境内分布的唐朝时期埋藏的古墓内的大量祁连圆柏立木,通过多样本交叉定年,现已建立了长达3500年的祁连圆柏的宽度年表。本项目在前期研究的基础上,首先建立研究区过去100年的高分辨率(1~2年)树轮同位素(碳、氢和氧)序列,分析和阐明树轮各同位素指标与气候环境要素之间的关系及其所指示的气候意义。然后,在建立2000年树轮宽度年表所用样本出土古木和现生立木样本中选择合适样本,建立长达2000年以上3~5年分辨率的可靠树轮碳、氧和氢同位素长年表,并利用序列进行过去2000年气候变化重建与变化规律分析,同时将重建结果与邻近区域其它代用指标进行比较综合。本项目的研究成果将为我国研究2000年时间尺度的环境变化提供基础数据。
中文关键词: 树轮同位素气候学;稳定碳;氧;氢同位素;气候变化;柴达木盆地东缘
英文摘要:
英文关键词:
项目名称: 基于结构光照明的数字全息显微研究
项目编号: No.61377008
项目类型: 面上项目
立项/批准年度: 2013
项目学科: 无线电电子学、电信技术
项目作者: 姚保利
作者单位: 中国科学院西安光学精密机械研究所
项目金额: 82万元
中文摘要: 本项目旨在研究基于结构光照明的超分辨数字全息显微(DHM)方法。由空间光调制器(SLM)产生两种不同的结构照明光(条纹结构照明光和随机相位结构照明光)用于照明样品。利用光栅衍射和针孔滤波构建物参共路的点衍射DHM装置,克服环境扰动对DHM测量和成像结果的影响。条纹结构照明和随机相位结构照明通过"合成数值孔径",可将DHM空间成像分辨率提高一倍。与传统结构照明显微方法相比,本方法除了可以对振幅型物体进行超分辨成像,还可以对相位型物体进行超分辨成像。同时,这两种结构照明光还可以实现DHM的自动调焦和纵向层析成像。该研究将为高性能、实用化数字全息显微镜的开发和应用打下良好的理论和技术基础。
中文关键词: 数字全息显微;结构光照明;超分辨成像;自动调焦;层析成像
英文摘要: This project aims at investigating the Digital Holographic Microscopy (DHM) with super-resolution and slicing imaging ability based on structured illumination. Two kinds of structured illuminations, i.e., fringe structured illumination and random-phase il
英文关键词: digital holographic microscopy;structured illumination;super-resolution imaging;autofocusing;slicing imaging
项目名称: 曲线形钢管混凝土桁架结构的工作机理研究
项目编号: No.50978150
项目类型: 面上项目
立项/批准年度: 2010
项目学科: 一般工业技术
项目作者: 韩林海
作者单位: 清华大学
项目金额: 36万元
中文摘要: 建立曲线形钢管混凝土桁架结构受力全过程分析的计算模型,并通过典型曲线形钢管混凝土桁架试件的试验进行验证。采用有限元模型,细致剖析曲线形钢管混凝土桁架结构的工作机理和力学实质,如桁架结构的破坏模态、腹杆的剪切变形、弦杆的受力性能以及结构的极限承载能力和变形特性等。分析曲线形钢管混凝土桁架结构的矢跨比、曲线形结构的轴线形式、竖向荷载分布形式和腹杆类型等重要参数的影响规律。对曲线形钢管混凝土桁架结构的刚度折减、承载力简化计算模型进行分析。研究曲线形钢管混凝土桁架结构的构造措施,如弦杆和腹杆的钢管径厚比、腹杆布置方式以及腹杆交角等的确定原则及其对整体结构受力性能的影响规律。通过对理论计算结果进行分析和归纳,提出曲线形钢管混凝土桁架结构的刚度和承载力简化计算方法,并给出合理的构造措施设计建议,以期为有关工程应用和设计规程的制订提供参考。
中文关键词: 钢管混凝土;曲线形;桁架;工作机理;承载力
英文摘要:
英文关键词: Concrete filled steel tube;Curved;Truss;Mechanism;Bearing capacity


本文件旨在为无人机系统的探测、跟踪与识别系统开发一种标准化的测试方法。其是在由欧盟"内部安全基金-警察"根据赠款协议101034655资助的COURAGEOUS项目框架内制定的。此标准化测试方法基于一系列代表广泛用例的标准用户定义场景。目前,这些标准场景主要面向民事安全最终用户。然而,鉴于反无人机系统领域具有高度的军民两用特性,更多军事场景无疑也高度相关。因此,本标准提供了一个开放架构,其中标准场景以模块化方式在附录中作为示例提供,使标准用户能够轻松添加新场景。针对每个场景,都提供了作战需求与功能性能要求。利用这些信息,提出了一种完整的测试方法,允许在不同反无人机系统之间进行公平的定性和定量比较。此测试方法在三次用户脚本验证试验中得到了验证。
其目标是,该标准化测试方法将使欧盟执法机构网络内的成员更好地理解反无人机系统的能力。这迫切需要,因为成员国正面临无人机威胁的增加,而整个地区尚未制定统一政策来尝试和管理该威胁。然而,应强调的是,大多数欧盟执法机构并没有一个完整且详细的无人机应对策略。
需要强调的是,此标准测试方法完全侧重于反无人机系统"杀伤链"中的探测、跟踪与识别方面,不涵盖压制/处置方面。该标准测试方法也集中于对DTI系统进行定性和定量评估,评估对象是呈现给最终用户的、配置为集成解决方案的系统。虽然测试方法包含了对反无人机解决方案界面的最终用户主导的定性评估,但对指挥与控制界面的全面可用性分析不在此标准测试方法的范围内。
本文件可分为四个主要部分:
- 第一部分,提供总体介绍
- 第二部分,侧重于标准场景
- 第三部分,侧重于性能要求
- 第四部分,侧重于实际的标准测试方法
本文件范围广泛,旨在为反无人机行业、执法机构和政策制定者等不同利益相关方提供可操作的见解。
对反无人机行业的主要启示:
- 深入了解最终用户的作战需求和性能要求,以指导反无人机解决方案的设计
- 一种用于测试和传达其产品性能规格与能力的标准化方法
对最终用户的主要启示:
- 深入了解反无人机领域态势
- 一种用于开发和验证需求规格的方法,以便做出更好的采购决策
- 一种性能测量的标准化方法,以便更好地将选定的反无人机解决方案与作战需求相匹配
对政策制定者的主要启示:
- 深入了解反无人机领域态势
- 通过标准化测试方法,更好地理解反无人机系统的能力

技术革命已将人类带入数字时代,新技术在其应用的领域带来了重大进步。全球安全环境在力量极的层面正经历重大变化,势力范围和军事行动随着新兴颠覆性技术的使用而演进。配备最新技术发展的军事能力已在数字或物理战场上取得了重大胜利。因此,军方作为国家实体,已成为人工智能、太空技术、自主与高超音速载具、大数据与高级分析、战场物联网的"测试者",并对民用特定研究和工业产生重大影响。军事环境通过发展其能力并部署新兴颠覆性技术,正在为当今的工业革命做出贡献,这表明军民关系在现代军队中至关重要。本文旨在论证人工智能对军事行动的影响,研究方法包括利用兰彻斯特定律计算所涉部队的军力,从而对军事行动进行数学建模。

人工智能近期的发展史与人类发展和技术进步密切相关,同时也与人们渴望从耗时活动或敌对环境中得到替代的意愿相关。武装力量不断适应国家和区域的安全风险、威胁和脆弱性,而新兴颠覆性技术则彻底改变了军事行动的进行方式,极大地影响了战略、战术甚至战争的性质。国防工业充分利用了技术革命,生产出在体能上比战场部队更强、更快的武器装备。
当前冲突突显了一个新的战争范式,即一个主权国家或非国家行为体的军力与技术变革和科学成就密切相关,科技进步使得国防工业能够发展新的领域,从而确保军事行动规划与实施的成功。此外,技术的指数级发展正在重塑军事行动,新的混合威胁类型被添加到常规战争要素中,这要求在所有作战层面规划与实施军事行动时,必须实现流程精简和适应,以便军队能够履行其宪法和法律使命。人工智能革命将实现"机器的认知化,创造出在特定任务上比人类更聪明、更快速的机器"。将新兴、颠覆性和融合性技术引入现代军事能力,已显著改变了战斗人员与非战斗人员之间的关系。在近期的冲突中,武装力量以最少的人际互动执行军事行动,但对作战环境产生了重大影响。在技术发展的推动下,当代世界至少在中期内,将成为一个相互关联的风险与威胁显现的空间,这将增加全球安全环境的复杂性、不确定性和多变性。除了这些趋势,军事体系的相关性及其对社会的影响也日益增加。在发展和使用配备人工智能的军事能力的背景下,军方组织以及国防、公共秩序和国家安全体系的结构,需要关注将其与技术进步相连接的必要性,以"发展现代化、高度可用的、与盟国和伙伴国部队完全互操作的能力,从而确保完成宪法赋予的使命"。
北约《科学与技术2023-2043——第一卷:概述》提出了人工智能的定义,将其描述为"机器执行通常需要人类智能的任务的能力——例如,识别模式、从经验中学习、得出结论、做出预测或采取行动——无论是在数字领域,还是作为自主物理系统背后的智能软件"。配备人工智能的军事能力将感知作战环境,并在技术帮助下与军事行动交互、推理和学习,最终在作战环境中采取行动以塑造之。在减少人类对人工智能赋能军事能力的控制以及提高战场决策效率和速度的同时,人类控制问题仍有待讨论,至少在那些对国家安全有重大战略影响或为防止军事行动失控升级的关键决策中。文章第一部分概述了人工智能的演进,随后是文献综述,审视了人工智能应用的关键领域,特别强调当前的军事能力。接下来的部分概述了研究方法,其中根据兰彻斯特定律采用了数学建模。最后给出结论,对人工智能融入现代军事能力进行批判性评估,并提出未来研究的潜在方向。

记忆已成为并将继续成为基于基础模型的智能体的核心能力。它支撑着长程推理、持续适应以及与复杂环境的有效交互。随着智能体记忆研究的快速扩张并吸引空前关注,该领域也日益呈现碎片化。当前统称为"智能体记忆"的研究工作,在动机、实现、假设和评估方案上往往存在巨大差异,而定义松散的记忆术语的激增进一步模糊了概念上的清晰度。诸如长/短期记忆之类的传统分类法已被证明不足以捕捉当代智能体记忆系统的多样性和动态性。 本综述旨在提供当前智能体记忆研究最新且全面的图景。我们首先清晰地界定智能体记忆的范围,并将其与大型语言模型记忆、检索增强生成和上下文工程等相关概念区分开来。然后,我们通过形式、功能和动态三个统一的视角来审视智能体记忆。 * 从形式视角,我们识别了智能体记忆的三种主要实现方式,即标记级记忆、参数化记忆和潜在记忆。 * 从功能视角,我们超越了粗略的时间分类,提出了一个更细粒度的分类法,区分了事实性记忆、经验性记忆和工作记忆。 * 从动态视角,我们分析了在智能体与环境交互的过程中,记忆如何随时间被形成、演化和检索。
为支持实证研究和实际开发,我们汇编了一份关于代表性基准测试和开源记忆框架的全面总结。在整合梳理之外,我们阐明了对于新兴研究前沿的前瞻性视角,包括面向自动化的记忆设计、强化学习与记忆系统的深度融合、多模态记忆、多智能体系统的共享记忆以及可信度问题。 我们希望本综述不仅能作为现有工作的参考,更能作为一个概念基础,促使人们将记忆重新思考为设计未来智能体智能时的一等原语。
1 引言
过去两年,我们看到性能日益强大的大语言模型(LLM)已势不可挡地进化为强大的AI智能体(Matarazzo and Torlone, 2025; Minaee et al., 2025; Luo et al., 2025)。这些基于基础模型的智能体在多个领域——如深度研究(Xu and Peng, 2025; Zhang et al., 2025o)、软件工程(Wang et al., 2024i)和科学发现(Wei et al., 2025c)——取得了显著进展,持续推动着通往通用人工智能(AGI)的进程(Fang et al., 2025a; Durante et al., 2024)。尽管早期的"智能体"概念高度异构,但学界已逐渐达成共识:除了纯粹的大语言模型骨干外,一个智能体通常还需具备推理、规划、感知、记忆和使用工具等能力。其中一些能力,如推理和工具使用,已通过强化学习在很大程度上内化于模型参数之中(Wang et al., 2025l; Qu et al., 2025b),而另一些则仍然高度依赖于外部的智能体框架。这些组件共同作用,将大语言模型从静态的条件生成器转变为可学习的策略,使其能够与多样的外部环境交互并随时间自适应地演化(Zhang et al., 2025f)。 在这些智能体的核心能力中,记忆 尤为关键,它明确地促成了从静态大语言模型(其参数无法快速更新)到自适应智能体的转变,使其能够通过环境交互持续适应(Zhang et al., 2025r; Wu et al., 2025g)。从应用角度看,许多领域都要求智能体具备主动的记忆管理能力,而非短暂、易忘的行为:个性化聊天机器人(Chhikara et al., 2025; Li et al., 2025b)、推荐系统(Liu et al., 2025b)、社会模拟(Park et al., 2023; Yang et al., 2025)以及金融调查(Zhang et al., 2024)都依赖于智能体处理、存储和管理历史信息的能力。从发展角度看,AGI研究的一个核心目标是赋予智能体通过环境交互实现持续演化的能力(Hendrycks et al., 2025),而这根本上立足于智能体的记忆能力。 智能体记忆需要新的分类法 鉴于智能体记忆系统日益增长的重要性和学界关注,为当代智能体记忆研究提供一个更新的视角既恰逢其时,也十分必要。提出新分类法和综述的动机有两点:❶ 现有分类法的局限:尽管近期已有几篇综述对智能体记忆提供了宝贵且全面的概述(Zhang et al., 2025r; Wu et al., 2025g),但其分类体系是在一系列方法快速进展之前建立的,未能完全反映当前研究图景的广度和复杂性。例如,2025年出现的新方向,如从过往经验中提炼可复用工具的记忆框架(Qiu et al., 2025a,c; Zhao et al., 2025c),或基于记忆增强的测试时缩放方法(Zhang et al., 2025g; Suzgun et al., 2025),在早期的分类方案中尚未得到充分体现。❷ 概念碎片化:随着记忆相关研究的爆炸式增长,"记忆"这一概念本身正变得日益宽泛和碎片化。研究者们常常发现,标榜研究"智能体记忆"的论文在实现方式、目标和基本假设上差异巨大。各类术语(陈述性、情景性、语义性、参数化记忆等)的扩散进一步模糊了概念的清晰度,这凸显了建立一个能够统一这些新兴概念的、连贯的分类法的迫切需求。 因此,本文旨在建立一个系统性的框架,以调和现有定义、衔接新兴趋势,并阐明智能体系统中记忆的基础原理。具体而言,本综述旨在回答以下关键问题: 关键问题
智能体记忆如何定义?它与大语言模型记忆、检索增强生成(RAG)和上下文工程等相关概念有何关联? 1. 形式:智能体记忆可以采取哪些架构或表示形式? 1. 功能:为何需要智能体记忆?它服务于哪些角色或目的? 1. 动态性:智能体记忆如何随时间操作、适应和演化? 1. 推动智能体记忆研究的前沿方向有哪些?
为解答问题❶,我们首先在第2节为基于大语言的智能体及智能体记忆系统提供形式化定义,并详细比较智能体记忆与大语言模型记忆、检索增强生成(RAG)和上下文工程等相关概念的异同。遵循"形式-功能-动态"三角框架,我们对智能体记忆进行了结构化概述。问题❷探讨记忆的架构形式,我们在第3节讨论并重点介绍了三种主流实现方式:标记级记忆、参数化记忆和潜在记忆。问题❸关注记忆的功能角色,在第4节中,我们区分了三种功能类型:事实性记忆(记录智能体与用户及环境交互中获得的知识)、经验性记忆(通过执行任务逐步增强智能体解决问题的能力)和工作记忆(在单个任务实例中管理工作区信息)。问题❹聚焦于智能体记忆的生命周期与运作动态,我们将按记忆形成、检索和演化的顺序进行阐述。 在通过"形式-功能-动态"视角梳理现有研究后,我们进一步提出了对智能体记忆研究的观点与见解。为促进知识共享与未来发展,我们首先在第6节总结了关键基准测试和框架资源。在此基础上,我们通过第7节探讨数个新兴但尚未充分发展的研究前沿来解答问题❺,这些方向包括面向自动化的记忆设计、强化学习(RL)的融合、多模态记忆、多智能体系统的共享记忆以及可信度问题。 本综述的贡献 总结如下:(1) 我们从一个"形式-功能-动态"的视角,提出了一个最新且多维度的智能体记忆分类法,为理解该领域的当前发展提供了一个结构化的视角。(2) 我们深入探讨了不同记忆形式与功能目的的适用性及相互作用,为如何将各类记忆类型有效地与不同的智能体目标对齐提供了见解。(3) 我们探讨了智能体记忆中新兴且有前景的研究方向,从而勾勒出未来的发展机遇与推进路径。(4) 我们汇编了包括基准测试和开源框架在内的综合资源集,以支持研究人员和从业者进一步探索智能体记忆系统。 综述结构 本综述余下部分结构如下。第2节形式化定义了基于大语言的智能体与智能体记忆系统,并厘清了它们与相关概念的关系。第3、4、5节分别审视了智能体记忆的形式、功能和动态性。第6节总结了代表性的基准测试和框架资源。第7节讨论了新兴的研究前沿和未来方向。最后,我们在第8节总结关键见解,结束本综述。

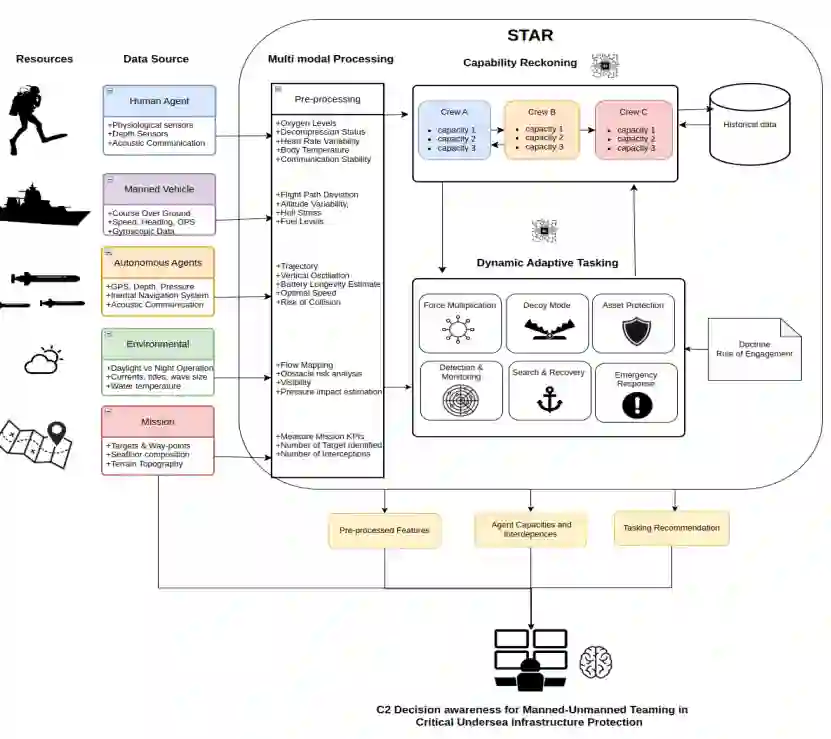
无人系统在各领域的日益融合正在重塑军事行动,从规划到任务执行。北约在训练演习中展示出兴趣,其中混合有人-无人团队的同步至关重要。STAR是一个人工智能驱动的任务工具,旨在在有人和无人系统间分配任务,支持协调多域作战的规划、任务分配、协调和执行。STAR集成了多模态数据,执行能力评估,并向具有人工监督的指挥控制系统提供基于人工智能的任务分配建议。通过如Unreal Engine、Cesium三维地理空间建模和JSBSim飞行动力学等建模与仿真环境,STAR能够实现高保真度的任务执行,包括模拟代表性有人和无人载具及其适当的资产和基于人工智能的能力,应用于诸如水下保护、海陆空作战或搜救等逼真场景。STAR实现了人机交互,同时允许C2操作员验证或否决任务分配建议。STAR通过使用机器学习模型实现了高达89%的任务分配准确率,显示出提高任务准备状态,并增强联合多域作战中的协调、互操作性和效果同步的潜力。
多域作战中的有人-无人协同
有人-无人协同是指自主无人系统与人类协同进行的协调行动。它通过新的角色、权限、结构、学习、协调和任务分配流程,重新定义了团队动态。它允许将具有不同类型能力、知识和相互依赖性的多智能体团队跨领域结合,以执行多样化任务。MUM-T可以增强团队能力,创造力量倍增器,最大限度地降低作战中的人员风险和部署成本,同时实现协同学习能力。在下一节中,我们将讨论使MUM-T具有挑战性的一些要素,以及人工智能和建模与仿真如何帮助解决这些问题。
自主与无人智能体
美国国家标准与技术研究院将无人系统的自主性定义为其感知、认知、分析、通信、规划、决策和执行任务以实现特定目标的能力,通常只需很少或无需人工干预。自主性通过“人类独立性”和“情境自主能力”来分类,后者考虑了任务类型、环境以及允许的人类参与程度[3]。在实践中,自主操作使无人系统能够执行人类操作员或其他系统分配的任务,集成了导航、目标锁定和避障等能力。然而,重要的是要注意,认为无人系统能完全取代人类——无论是在达成相同任务成果还是减少伤亡方面——的想法过于简单化了。与人类不同,无人系统缺乏动态和不可预测的战斗场景所需的灵活性和适应性[3]。广义上讲,无人系统被定义为无随车操作员的动力平台,其依靠外部控制单元、计算机和通信系统来接收命令、收集数据和执行任务[3]。例子包括无人地面车辆、无人驾驶航空器、无人水面艇、无人水下航行器、无人值守弹药和无人值守地面传感器。这些正日益成为从军事行动到环境监测等各种应用中不可或缺的组成部分。这些系统通常配备了广泛的复杂自主能力,使其能够执行诸如目标识别、探测和跟踪等复杂任务。实现这些功能的一项关键技术是计算机视觉,其中YOLO和卷积神经网络等算法被广泛用于实时物体识别和场景理解。除了视觉处理,这些系统还依赖自主导航、路径规划和任务执行,通常采用深度强化学习或优化算法等先进技术。这些方法使系统能够从动态环境中学习,在不确定或不可预测的场景中做出决策,并通过与周围环境的互动不断改进。然而,这些能力需要大量的数据用于训练和验证,以及大量的计算资源来处理和分析数据。为了缓解现实世界测试的挑战并提高团队战备水平,这些系统通常在模拟环境中进行初步训练和评估。
MUM-T中用于决策支持的人工智能
人工智能在战术层面的战场上应用日益受到关注。在军事行动的战役和战略层面,人工智能极大地支持了数据分析和规划工作。其处理海量信息的能力使人工智能能够协助决策,例如兵力部署和选择最能有效推进战略目标的计划。这表明人工智能未来在高层军事决策中有潜力发挥更大作用。虽然人工智能尚未在此能力上广泛部署,但某些系统在战术层面已展现出优于人类军事人员的性能,这表明人工智能未来在战略军事决策中的参与有巨大潜力。人工智能能够在短时间内综合大量数据,这可能有助于应对人类生理局限。这些系统采用人工智能驱动的目标锁定和控制机制,能够在几分之一秒内处理信息和执行行动。在应对快速出现的威胁(例如高超音速导弹,其响应窗口极为有限)时,人工智能同样可以应用于决策支持,尽管目前尚不知晓存在此类防御系统。战场上自主武器的日益增多突显了人工智能的战术意义,因为其在动态战斗场景中的速度和响应能力可以提供相对于传统系统的决定性优势。在包括战役和战略规划在内的更高层级的战争中,人工智能对数据分析和决策支持贡献巨大。其处理大量信息的能力使其能够为诸如兵力部署和选择最能推进战略目标的计划等决策提供依据。它可以帮助解决诸如“何处投入兵力、何种计划最接近战略目标”等难题。因此,这可以在任务期间协助支持军事决策流程,以便根据持续的数据流、MUM-T能力的动态变化以及态势感知来重新调整行动方案。

与自主资源共享任务(STAR)
STAR旨在促进任务三个阶段的决策制定OODA循环:i) 任务预操作阶段——通过支持兵棋推演仿真,并根据“如果-那么”想定确定最佳行动方案;ii) 任务执行阶段——由于任务前给出的计划和命令常因事态变化而改变,它可以帮助支持围绕动态任务分配的决策;iii) STAR也可帮助支持事后分析,以更好地准备和支持未来任务,帮助评估每个智能体执行其任务和职责的能力现状,并可用于通过建模与仿真来校准人类和自主智能体的训练/表现。STAR能够提供一个可接入仿真器的系统,从而促进部队战备状态,该系统有助于生成并部署任务行动、启动团队,并在接收关于有人-无人协同任务分配的人工智能建议的同时,测试和评估不同策略。STAR由多个组件构成,其描述见2.1节。介绍的三个主要模块是:i) 多模态管道;ii) 能力评估;iii) 动态任务分配模块。这三个模块中的每一个都可以接收来自仿真和建模数据的输入,这使得系统能够在感兴趣的特定用例上进行测试,并有助于收集数据以及了解每个有人或无人智能体在任务中可能行为的潜在洞察。