如何利用 Google 开源的 TFCO 构建机器学习模型?

在机器学习模型中引入公平性远非易事,本文就利用Google AI研究院开源的Tensor Flow Constrained Optimization Library(TFCO),来优化机器学习模型的各种目标,包括公平性。

以下为译文:

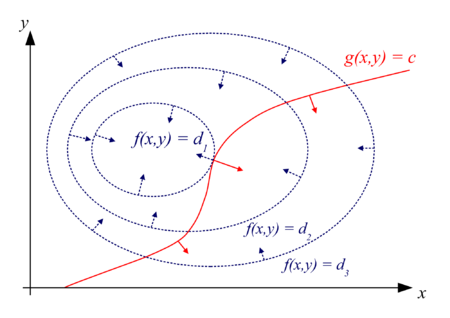

TFCO原理演示
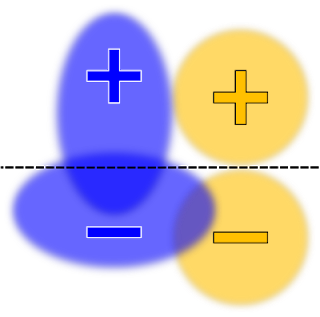
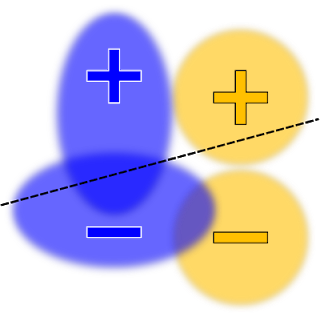
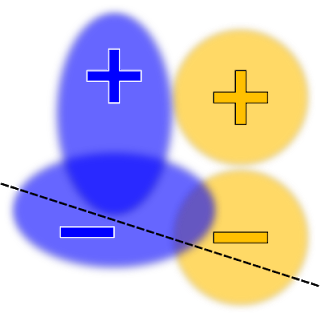

开发者该如何使用?
import tensorflow as tfimport tensorflow_constrained_optimization as tfco
# Create variables containing the model parameters.weights = tf.Variable(tf.zeros(dimension), dtype=tf.float32, name="weights")threshold = tf.Variable(0.0, dtype=tf.float32, name="threshold")# Create the optimization problem.constant_labels = tf.constant(labels, dtype=tf.float32)constant_features = tf.constant(features, dtype=tf.float32)def predictions():return tf.tensordot(constant_features, weights, axes=(1, 0)) - threshold
# Like the predictions, in eager mode, the labels should be a nullary function# returning a Tensor. In graph mode, you can drop the lambda.context = tfco.rate_context(predictions, labels=lambda: constant_labels)problem = tfco.RateMinimizationProblem(tfco.error_rate(context), [tfco.recall(context) >= recall_lower_bound])
扫下方二维码或点击阅读原文免费报名直播+抽取奖品+与大牛交流


登录查看更多
相关内容
专知会员服务
78+阅读 · 2019年11月15日
Arxiv
4+阅读 · 2018年9月23日
Arxiv
5+阅读 · 2018年4月5日
Arxiv
9+阅读 · 2018年3月14日
Arxiv
10+阅读 · 2018年1月29日
Arxiv
4+阅读 · 2017年12月19日




相关VIP内容
专知会员服务
78+阅读 · 2019年11月15日
相关资讯