论文浅尝 | 低资源文本风格迁移数据集

来源:AAAI2020
论文链接:https://www.msra.cn/wp-content/uploads/2020/01/A-Dataset-for-Low-Resource-Stylized-Sequence-to-Sequence-Generation.pdf
概述:
低资源样式化的序列到序列(S2S)生成是高需求的。但由于数据集在规模和自动评价方法上的局限性,阻碍了其发展。作者为低资源风格化的S2S构建了两个大规模、多参考数据集:易于评估的机器翻译形式语料库(MTFC)和解决聊天机器人中一个重要问题的Twitter会话形式语料库(TCFC)。这些数据集包含上下文到源样式的并行数据、源样式到目标样式的并行数据以及目标样式中的非并行语句,以实现半监督学习。作者提供了三个基线:基于轴的方法、师生方法和反向翻译方法。作者发现基于轴的方法是最差的,另外两种方法在不同的度量基准上获得了最好的效果。
论文介绍:
S2S框架(Sutskever、Vinyals和Le 2014)近年来取得了巨大成功。然而,大量的任务要求S2S模型在没有大量并行数据的情况下生成特定风格的文本,例如chatbots中的正式响应生成,这是一种需求量很大但性能不太好的方法(Shum、He和Li 2018)。表1显示,正式回复对于聊天机器人非常重要,特别是在客户服务领域。
我们研究了低资源模式化的序列到序列生成问题。通常情况下,上下文到目标样式的句子对是不可用的,但是足够的上下文到源样式的句子对很容易收集。例如,在Twitter上可以很容易地获取非正式会话数据,但是很难找到非正式消息和正式响应文本对(Li等人。2016年b)。通过上下文到源风格的句子对,可以通过群体寻源来构建源风格到目标风格的句子对。在这种方式下,语境和目的语风格的句子是通过源语风格的句子连接起来的,这是与非平行风格转换任务的主要区别(Shen et al。2017年)

在这样的假设下,作者通过扩展Grammarly的Yahoo-Answers形式语料库(GYAFC)(Rao和Tetreault 2018),引入了两个基准数据集:Twitter会话形式语料库(TCFC)和机器翻译形式语料库(MTFC)。这两个数据集都关注于特定的样式、形式,并且包含大量的训练数据以及人工注释的多参考测试数据。具体来说,Twitter会话形式语料库旨在教会一个代理以一种正式的方式回应人类。作者准备了170万条来自Twitter的非正式消息响应对,以及52595条来自GYAFC的非正式到正式的英语文本对用于培训。关于模型验证,作者要求以英语为母语的人将2000个非正式的回答改写成正式的风格。
尽管程式化会话在现实世界中有许多潜在的应用,但很难对其进行评估(Liu et al。2016年)。基于此,作者进一步构建了一个更容易评价的任务,即机器翻译形式语料库。MTFC由1500万个非正式的中文到非正式的英文文本对组成,这些文本对是从OpenSubtitle数据集中仔细筛选出来的(Lison和Tiedemann,2016年)。非正式到正式的英语文本对也是从GYAFC借来的。为了调试和测试,作者要求人工注释者创建3000多个人工注释的非正式汉语到正式英语对。对于这两个数据集,我们进一步准备了大规模的非并行形式语句,以便能够训练半监督方法(Sennrich、Haddow和Birch 2016a)。
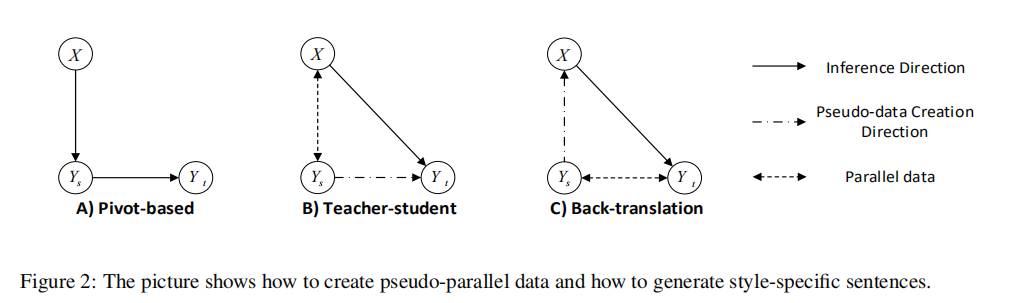
由于这项任务可以被视为一个特定的多语言机器翻译问题,作者采用了三种低资源机器翻译的方法作为基线:1)基于枢轴的方法(Cohn和Lapata 2007),以流水线的方式进行风格化的S2S生成;2)师生模型(Chen等人。2017)通过知识蒸馏解决错误传播;3)能够利用非并行数据的反向转换方法(Sennrich、Haddow和Birch 2016a)。实证结果表明,以轴为基础的模型是最差的,说明采用最先进的序列到序列模型和样式转换模型相结合的方法不能很好地解决这一问题。教师-学生法和后向翻译法在不同的度量指标上获得了最高的分数,说明知识提取和数据扩充可以减轻任务的一些挑战。
本文的主要贡献如下:1)建立了一个具有挑战性的会话风格转换数据集,该数据集在业界有着广泛的应用前景;2)引入了一个易于评估、由大量并行和非并行数据组成的机器翻译形式语料库;3)借鉴了机器翻译的典型方法对数据集进行了翻译测试。
数据集建立过程:
作者创建了两个用于样式化S2S生成的数据集,称为Twitter会话形式语料库(TCFC)和机器翻译形式语料库(MTFC)。在这一部分中,作者详细阐述了如何构造一个平行语料库D={(xi,yi,s)}N i=0,它由上下文到源风格的句子对组成,一个平行语料库s={(yj,s,yj,t)}M j=0由源风格到目标风格的句子对组成,以及一个包含形式句子的非平行语料库Mt。x、 ys和yt分别指一个上下文、一个源风格句子和一个目标风格句子。
背景:GYAFC数据集
由于S和Mt的构建是基于GYAFC的,所以作者首先对数据集进行了简要介绍。GYAFC是最大的人类非正式的↔ 正式数据集。首先,作者使用内部分类器从Yahoo Answers L6 corpus1的娱乐与音乐(E&M)和家庭与关系(F&R)域中提取非正式句子。如果句子是疑问句,包含url,并且短于5个单词或长于25个单词,则会被删除。众包努力构建培训、验证和测试集,要求员工将非正式句子改写为正式句子,并提供详细说明。最后,每个域大约有5万个文本对用于训练,3千个文本对用于验证,1.5千个文本对用于测试。
本文利用E&M领域的数据集作为S,在Rao和Tetreaultis中作为内部形式分类器,将正式句作为正实例,非正式句作为负实例,在人类标注的50k个文本对上训练一个形式分类器。该分类器对GYAFC数据的识别率达到92%。作者还测试了它在域外数据(Tweets和字幕)上的性能。微博和字幕的准确率分别为83%和78%。然后将该分类器应用于Yahoo-Answer L6语料库中E&M域的句子,选取1007999个高置信度的句子作为形式句构建机器翻译。
Twitter会话形式语料库
对于TCFC,我们通过从Twitter抓取消息-响应对来构造数据集D。为了最小化噪音,作者删除短于5个字或长于25个字的消息或响应。在预处理过程中,作者删除了标签、表情符号和@提及。最后得到了1727251个消息响应对。消息-响应对、从GYAFC中借用的并行数据、从Yahoo-Answers中挖掘的非平行语料都是该任务的训练数据,其统计如表3所示。
作者要求两个以英语为母语的人2将2000个回答3转换为正式的测试回答(1000个用于调谐,1000个用于测试),其中消息也可见。我们教注释者从GYAFC数据集中抽取详细的指令和示例,以确保重写质量。如果她不能清楚地理解对话,注释者可以放弃样本。最后,我们获得了980和978条用于调整和测试的消息。

原始非正式响应和正式重写响应之间的平均字符级编辑距离为27.33,编辑距离的分布如图1所示,表明如果只进行一个小的更改,则无法完成正式传输。根据我们对100对样本的统计,我们发现句子级释义(33%)、短语释义(42%)、标点符号编辑(50%)、收缩扩展(22%)、大写(53%)和规范化(9%)的具体百分比。定义和示例如表4所示。这些数字表明,通过首先生成非正式的响应,然后重写规则的方法是无法解决任务的。不同风格的句子结构是不同的。在实验中,我们讨论了基于轴的方法和端到端方法的性能。
机器翻译形式语料库
MTFC的目标是将一个非正式的汉语句子翻译成正式的英语句子,这样便于评价,有利于口语翻译的发展。理想情况下,D应该通过收集人类标记的中文来构建↔ 来自雅虎答案的英语平行数据。然而,为了训练而注释数百万个并行数据是非常困难的。我们选择双语字幕平行数据来建立数据集D。我们收集了大量的中文↔ 通过从OpenSubtitle中挖掘双字幕来配对英语。为了保证数据质量,我们按照(Zhang,Ling,and Dyer 2014)中的方法仔细检测并提取了双汉英对。根据快速对齐工具kit4获得的对齐分数筛选出错误的句子。此外,采用形式分类器对非正式字幕进行高置信度的选择。D中的所有字幕都有70%以上的概率被量词预测为非正式句。我们移除短于5个字或长于25个字的字幕,以控制数据长度分布。我们最终有1400万对中英文对子。
我们扩展了GYAFC数据集来创建验证和测试集。GYAFC在娱乐和音乐领域提供2877和1416个非正式的英语正式句子对,用于调整和测试,其中每一对包含一个非正式句子和四个正式句子作为参考。对于每一个文本对,我们要求一个中文注释员将非正式英语句子翻译成非正式汉语,因为一个中国人能够用汉语写出流利的句子。注释者可以丢弃他不清楚的实例。通过这种方式,我们可以得到2865和1412个<非正式汉语,非正式英语,正式英语>句子三元组用于调整和测试。在评估中,我们使用<非正式汉语,正式英语>文本对来测试性能。
方法:
基于轴的方法
解决这个问题的最直接的方法是基于管道的方法,也被称为基于枢轴的方法(Cohn和Lapata 2007),其中ys被用作“桥接”x和yt的枢轴语言。形式上,生成模型(x→y t)可以分解为两个子模型,其中yˆt由下式定义:
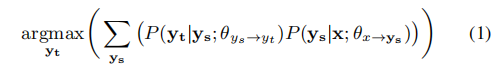
其中θys→yt和θx→ys是在D和S上通过极大似然估计得到的两个参数,由于存在指数搜索空间,译码过程通常用两步近似。第一步是根据上下文x生成ys,公式如下:
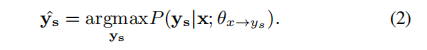
在这之后,目标风格句子由以下式子得到:
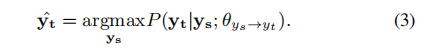
虽然基于轴的方法是解决这一问题的一种合理方法,但它存在两个问题:误差传播和模型差异。在实际应用中,我们无法得到一个完美的模型来将x转换为ys,因此,第一步中的错误会传播到第二步,这可能会影响输出的质量。更严重的是,D和S的主题和词汇量关系松散,降低了方法的性能。
师生框架
为了解决错误传播问题,师生框架首先利用S学习一个教师模型P(yt | ys,θys→yt),然后通过最小化KL散度来学习学生模型P(yt | x;θx→yt)。
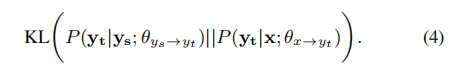
因为θys→yt在教学过程中是固定的,等式4可以重写为:
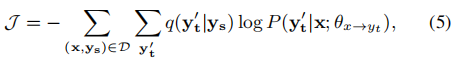
其中q(y’t | ys)表示教师在所有可能序列的样本空间上的序列分布。由于指数搜索空间的存在,我们将教师分布q替换为:
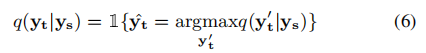
其中1(*)是指示函数,yˆt是通过波束搜索获得的。最后,目标函数表示为:
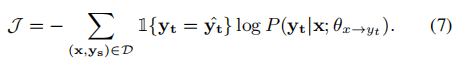
等式7给出了一个简单的训练过程,在这个过程中,学生网络根据教师网络生成的数据进行训练。该方法允许在一个模型中进行参数估计,避免了误差传播问题。
反译方法
反向翻译(Sennrich、Haddow和Birch 2016a)在数据增强方面被证明是有效的。它被广泛应用于各种任务,如无监督机器翻译(Lample等人)。2018)和文本风格转换(Rao和Tetreault 2018)。我们还测试了在风格化的S2S生成上的反向翻译性能。
具体来说,我们首先训练两个反向模型,包括由 P(ys|yt, θyt→ys)参数化的目标样式到源样式模型,以及由P(x|ys, θys→x)参数化的源样式到上下文模型。伪并行数据通过两种方式生成,分别使用有限的并行语料库和大规模的非并行语料库Mt。S、 我们用下式表示:

形成一个伪文本对(ˆx, yt).,∀¯y ∈ Mt,我们通过下式将¯y翻译为ˆx:

其中,解码过程也被分解为两个离散步骤,如等式2和3所述,形成伪并行数据(ˆx,∏yt)。通过合并由等式8和9生成的数据,得到了一个大型伪并行数据集P={(ˆxl,y’t,l)}。最后,我们使用P通过最大化对数似然来训练生成模型:
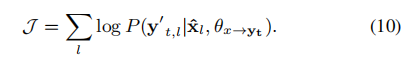
师生翻译法和反译法都为模型训练创建了伪并行数据,不同的是反译生成数据的目标端是人工编写的,而师生翻译生成数据的模型端是人工编写的。
数据扩充
由于50k文本对对于NMT模型来说不够大,我们对上述三种方法采用了数据增强技术,提高了P(yt | ys;θys→yt)和P(ys | yt,θyt→ys)的估计精度。灵感来源于(Lample等人。2018年),我们采用PBMT模型来训练一个正式→非正式的模型,其中PBMT的语言模型是在Yahoo Answers L6的E&M和F&R域上训练的。然后利用PBMT将机器翻译中的句子翻译成非正式文体。在去除质量差的反向翻译结果(单词重复或太长)后,我们将反向翻译结果与S中的原始文本对合并。应注意,S中的文本对重复了10次,以确保最终伪并行数据的质量。
实验
作者描述了MTFC的实现细节,TCFC的情况与此类似。在基于轴的模型中,变压器模型(Vaswani等人。采用2017)近似条件序列生成概率P(ys | x,θx→ys)。变压器模型由6层编码器和解码器组成,其模型大小为512。多头注意量为8。所有模型均在4台特斯拉泰坦X GPU上进行训练,使用Adam算法(Kingma和Ba 2014),β1=0.9,β2=0.98,共200K步。我们使用字节对编码(BPE)方法(Sennrich、Haddow和Birch 2016b)来处理大小为25000的开放词汇表问题。初始学习率设置为0.2,并根据中的计划衰减(Vaswani等人。2017年)。在训练过程中,批大小为4096字,每5000个批创建一个检查点。用序列到序列(S2S)模型估计P(yt | ys,θys→yt)的生成概率,其中编解码器为512个单元的单层GRU。
在师生模式方面,我们采用了支点模式中的GRU作为教师模式,将非正式英语句子翻译成正式英语。使用一个转换器作为学生模型,使用等式7从头开始训练这些文本对。在后向平移方面,我们使用后向平移生成的伪并行数据对基于轴的模型中使用的转换器进行微调。对于所有模型,光束大小为4,长度惩罚为1.2。我们将进一步报告基本模型和数据透视规则的结果。基本模型意味着我们直接计算数据透视模型生成的ys。Pivotrule表示我们用几个有效的规则重写生成结果ys。
评价结果
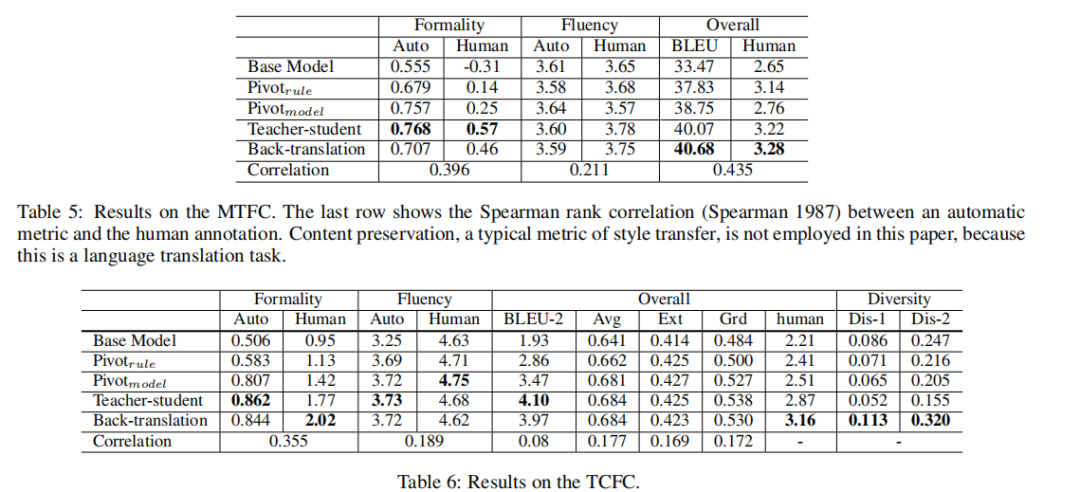
表5和表6显示了评估结果。
人因评价:在MTFC方面,反译法和师生法在整体质量上排名第二,因为它们都通过端到端的模型来完成这项任务,从而避免错误传播。教师-学生法在形式上得分最高,因为1)教师模型给出的形式模式对于神经模型更容易学习,2)反向翻译的伪数据可能含有噪声。正如预期的那样,数据透视模型不能很好地处理任务,在整体质量上甚至比数据透视规则还要差。在观察输出后,pivotmodel有时会漏掉一些重要的词,从而增加风格转换中的输出形式,严重影响翻译质量。BLEU分数不好的另一个可能原因是D(即数据透视模型的训练数据)的主题可能与数据集S的主题略有不同。所有模型在流畅性方面都显示出可比较的结果,因为它们的解码器都基于能够生成可信句子的神经模型。TCFC的趋势与MTFC相似。TCFC数据集上的正式程度和流利程度得分略高于MTFC。一个可能的解释是,会话中的输出语句更短,更通用,因此更容易转换。
自动评估:对于MTFC,形式和BLEU的自动测量与人类的相关性较好,而流畅度评分与人类的相关性较差。这主要是因为统计模型是在论文上训练的,这些论文可能与雅虎答案的句子略有不同。在TCFC上,所有总体指标与人类判断的相关性都很弱,这与中的结论一致(Liu et al。2016年)。相比之下,MTFC是自动评价的较好选择。反译法产生的反应更为多样。这主要是因为从Yahoo Answers中抽取的Mt中的非平行句子比对话中的句子更加多样化以及信息量更大。
结论和今后的工作
本文重点研究了低资源模式化序列到序列的生成,并构造了两个大规模的数据集。MTFC易于评估,TCFC有利于对话系统。作者进一步测试了三种方法的性能,发现现有的模型不能很好地学习释义。在将来,作者将研究如何在有限的并行数据中解决这个问题。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



