清华大学张长水教授:机器学习和图像识别(附视频、PPT下载)

本篇干货整理自清华大学自动化系教授张长水于2018年4月27日在清华大学数据科学研究院第二届“大数据在清华”高峰论坛主论坛所做的题为《机器学习和图像识别》的演讲。
注:后台回复关键词“0427”,下载完整版PPT。
演讲视频:
视频时长约半个小时,建议使用wifi观看
张长水:大家好,我来自清华大学自动化系,主要做机器学习和图像识别的研究。现在人工智能很流行,机器学习也推到风口浪尖上,图像识别已经变成产品,新闻媒体告诉我们AlphaGo、AlphaGo zero已经战胜了人类、皮肤癌的识别超过了大夫、无人车已经上路测试,很快要量产。这些新闻仿佛告诉我们,图像识别的问题已经解决了,然而很多高科技做图像识别公司都还在高薪聘用掌握机器学习的人才。图像识别问题解决了吗?我们看看现在图像识别还有些什么问题。


一、大量数据
现在做图像识别,要求有大量的数据。什么叫大量的数据?比如上图是在业界做图像识别的数据集,包含很多类别的图像,像飞机、鸟、猫、鹿、狗。对于一个物体,需要有不同的表现,需要有不同的外观在不同的环境下的表现,所以我们需要很多照片素材。
尽管在我们领域里有很多大的数据集,但其实这些数据集远远不能满足我们的实用产品的要求。比如说我们看这样一个文字识别的例子。文字识别比一般的图像识别要简单,因为文字不涉及到三维,它只是一个平面的东西。

二、大量的样本
比如我们要识别清华大学的“清”,通常的做法是收集“清”的各种各样的图像,所谓各种各样的图像就是说要包括不同的字体,不同的光照,不同的背景噪声,不同的倾斜等,要想把“清”字识别好,就需要收集上很多这样的样本。那么这么做得困难是什么?
三、困难

1、样本的获取
当我们应用于实际、设计产品的时候,就会发现不是每一种情况下都有那么多数据。所以,怎么获得丰富的数据是首要的问题。

上图给大家展示的这一排图像是一个交通标志的识别任务。我们如果需要去识别路上的交通标志,就要在不同的环境下,不同的光照下,比如说早晨、中午、晚上,逆光还是背光,不同的视角,是否有遮挡,所有的因素都要考虑到,来采集数据。经验上每种标识收集上千张或者更多的图像,才能保证识别率到达实际应用的水平。
我们的问题是什么?看第一张图像。第一张图是有连续急转的标志。这样的标志在城市很难见到,除非到山区。这个例子说明,图像获取本身就不容易。
2、样本的标注
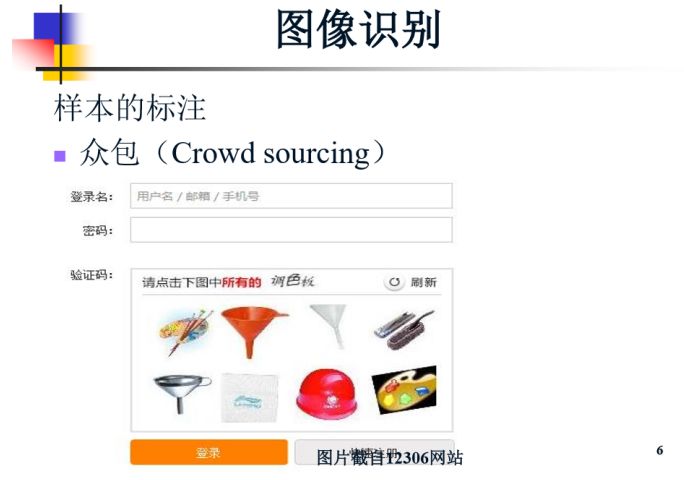
我们现在的图像识别方法是基于标注的数据的,这叫做监督学习。图像标注就意味着把图像一张一张抠出来。如果我们开车穿梭在北京市大街小巷,但是交通标志并不是在视频的每一张图片上出现。如果我们需要把视频中交通标志如果都要标出来,需要花很多钱。做机器学习的人会关心我们能不能通过一些其他更廉价的方法去做数据标注,例如能不能通过一些众包的方式去做。在12306网站购买火车票,每次让我们勾出相对应的图像,这可以看做是在标注数据。但是众包标注数据也存在一些问题,就是每个人标的时候会不一样,有时会有错误。所以在机器学习中,有人关心在众包情况下、标注数据有错的时候,我们如何设计学习算法,使得它对错误的标注不敏感。这个事大概七八年前就开始研究,不断的有新的文章出现。

当数据没有那么多的时候,怎么办?机器学习界遇到了这样的问题,就是小样本的数据学习。当样本不多的时候能不能达到和大数据量类似的识别效果?例如上图中只有几张狗的图片的时候,要识别狗,还能从哪里得到狗的信息?思路是从其他的图片中来,比如上边有有鸟,有猫,有鹿,它们的皮毛很像狗等等。换句话说,他从其他的丰富的图像中获取一些信息,把那些信息迁移到这个少量的数据上,从而能够实现对狗的识别。

另外,图片数量是否能降到只有一张?比如清华大学的“清”,只有一个模板图像,是否能够把文字识别做好。更极端的例子,能不能做到一个样本都没有,也就是说,机器在没有见过狗的情况下,是否能把狗识别出来,这都是研究人员关心的事情。
3、大数据量的训练
有了很多的数据还需要对它进行训练,这通常需要花很长时间,需要配备高端的设备去训练。

我们有了大量的数据怎么去做训练?可以采用GPU去做训练,这样可以达到特别快的速度。在这大的数据量上进行训练和学习的问题,叫做big learning。
Big learning 关心是否有更快速的方法训练呢,需要一个月才能训练出来的问题,能不能在一天就训练出来;能不能用并行训练?如果数据不能一次存到硬盘里,这个时候怎么学习呢?这些就是企业和机器学习界都关心的事。

除此之外,我们发现深度学习模型很容易被攻击。如上图左边是一只熊猫,我们已经训练好网络能够识别出这是一只熊猫。如果我在这张图像上加了一点点噪声,这个噪声在右图你几乎看不出来,我再把这个叠加后的图像给网络,它识别出来的不是熊猫,是别的东西。而且它以99.3%的信心说这不是熊猫,甚至你可以指定他是任何一个东西。这件事情的风险在什么地方?如果只是娱乐一下,也没什么大关系。但是如果把它用于军事或者金融后果就比较严重了。因此我们一直在关心这个问题怎么解决,就是希望算法能够抗攻击性强一点,但目前只是缓解而没有彻底解决。
而且研究中会发现这个问题,相当于去研究分类器的泛化性能。泛化性能这件事在机器学习里是理论性很强的问题,是机器学习圈子里面非常少的一些人做的事情。换句话说,这个问题看起来很应用,其实它涉及了背后的一些很深理论。为什么会出现这样的情况?因为我们对深度学习这件事没有太好的理论去解释它,我们没有那么好的方法去把所有的问题解决。

我们再说风险,图像识别中我们会把一个学习问题往往形式化一个优化问题,然后去优化这个函数,使这个函数最小。我们把这个函数叫做目标函数。有的时候我们会把这样的函数叫做损失函数,物体识别有错就带来损失。就是说在整个过程我们希望不要有太多的损失。其实,风险函数可能是更合适的词。因为你识别错了,其实是有风险的。一般来说目标函数对应于错误率,把狗识别成猫错了一张,把猫识别成狗又错了一张,都影响错误率,而错误率足以反映算法的性能。

但是在不同的问题里,识别错误的风险是不一样的。比如我们做一个医学上的诊断,本来是正常人,你判别说他有癌症,这种错误就导致虚惊一场。还有一种情况是他患有恶性肿瘤,算法没有识别出来而导致了延误治疗。这样的错误风险就很大。因此我们在优化的时候,这个目标函数其实是应该把这样的决策错误和风险放到里面去,我的目标是优化这个风险。但是这件事往往是和应用、和我们的产品设计相关。所以不同的产品设计,它的决策风险不一样。所以我们在设计产品的时候,是要考虑。

苹果宣称他们的人脸识别错误率是百万分之一,如果别人来冒充你去用这个手机是百万分之一的可能性,就是说,别人冒充你是很难的;但是人脸识别还有一种错误,就是:我自己用我的手机,没有识别出是我,这个错误率是10%。换句话说,你用十次就会有一次不过。在用手机这个问题上不明显,但是如果用于金融,这个事就有风险。我们设计产品的时候,你就要考虑风险在哪,我们怎么样使得整个风险最小,而不是只考虑其中一边的错误率。

有公司会宣传说错误率可以降到百万分之一,让人误以为人脸识别的问题已经解决了,然而我们在CAPR、ICCA这样的学术会议上仍然能看到怎么去做文字的检测,怎么去做人脸识别的研究。换句话说这件事还没有到那么容易使用的地步。所以我们做图像识别的产品有风险,产品设计要考虑风险,我们做这件事就要考虑用技术的时候,用对地方很重要,用错地方就会很大的风险。
机器学习是一个和应用紧密结合的学科,虽然有很多高大上的公式,其实都是面向应用,希望能解决实际问题。实际应用给我们提出很多需求,图像识别遇到的问题给我们提出了挑战。最后,感谢各位的聆听。
注:后台回复关键词“0427”,下载完整版PPT。
张长水教授简介

张长水,清华-青岛数据科学研究院二维码安全技术研究中心主任,智能技术与系统国家重点实验室学术委员会委员,清华大学自动化系教授、博士生导师,IEEE Fellow 。主要从事机器学习与人工智能、计算机视觉等研究工作。
清华-青岛数据科学研究院二维码安全技术研究中心:
中心成立于2017年4月25日,由张长水教授担任中心主任。中心致力于以核心技术研发为基础,为移动互联、移动支付和社会治理等领域提供二维码技术相关标准和应用解决方案。中心依托清华大学雄厚的科研实力和银河联动十余年研发积淀的二维码专利技术,目前在全球二维码技术研发领域具有领先地位。此次校企联合成立二维码安全技术研究中心,将进一步巩固和扩大清华在二维码技术上的领先优势,服务于产业发展、社会治理和国家安全。
更多信息可了解数据科学研究院官网:
http://www.ids.tsinghua.edu.cn/
数据派曾独家发布过张老师的更多演讲干货,感兴趣的读者可以回顾了解:
2017年10月14日的阿里云栖大会机器学习峰会专场上,张长水教授为大家带来“神经网络模型结构优化”的主题演讲,分享了神经网络模型结构优化的新办法,并解析实验过程、效果及应用案例。
2015年11月26日张老师在RONGv2.0---图形图像处理与大数据技术论坛上所做的题为《机器学习与图像识别》的演讲,分享了关于机器学习和图像识别的研究及进展。
校对:李君
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。






