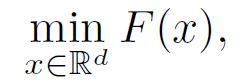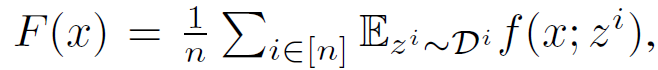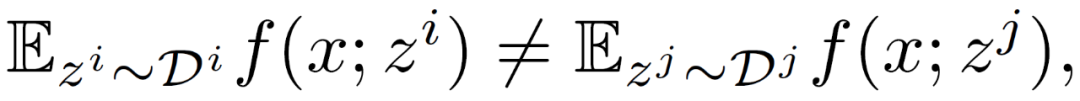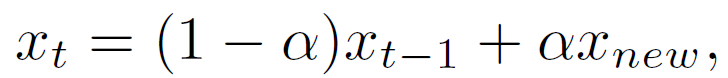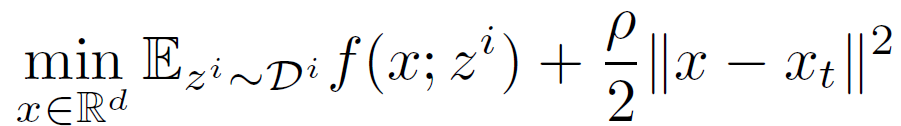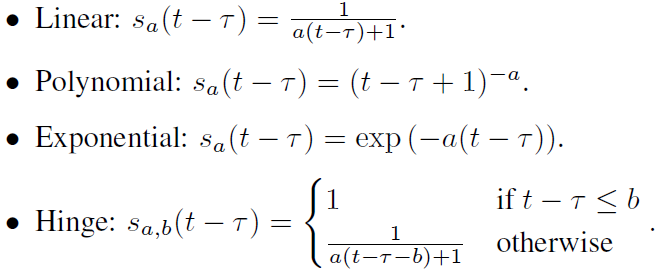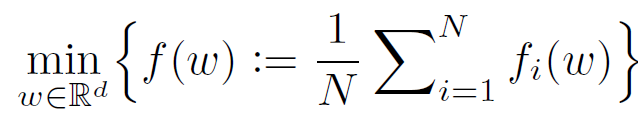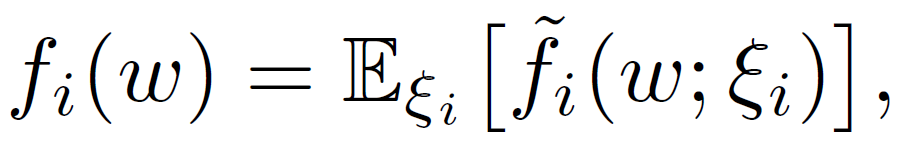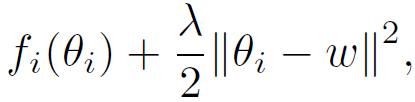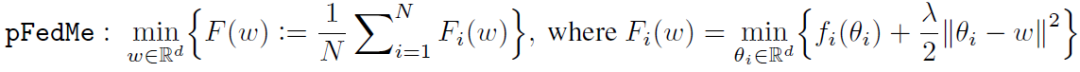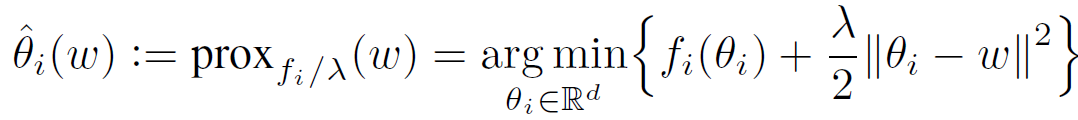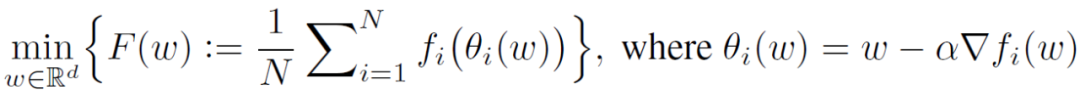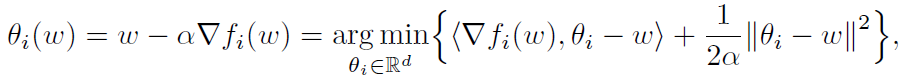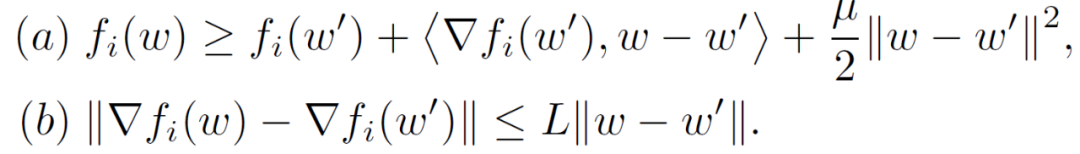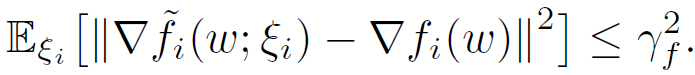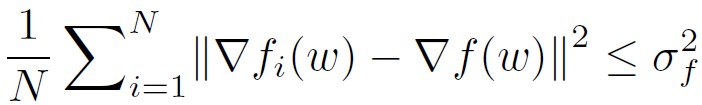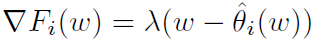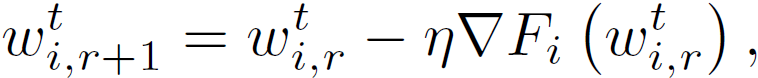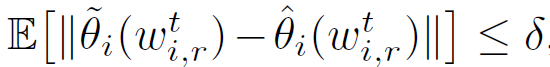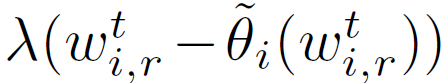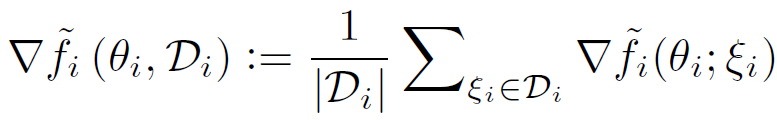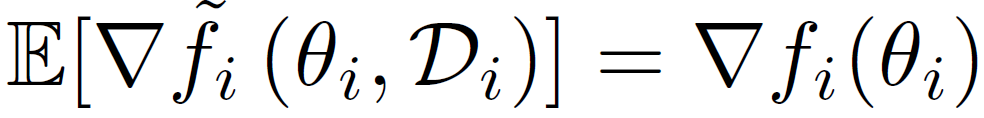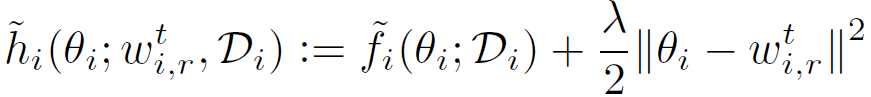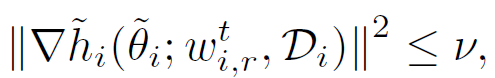本文选择了三篇关于个性化联邦学习的文章进行深入分析。
经典的机器学习方法基于样本数据(库)训练得到适用于不同任务和场景的机器学习模型。这些样本数据(库)一般通过从不同用户、终端、系统中收集并集中存储而得到。在实际应用场景中,这种收集样本数据的方式面临很多问题。一方面,这种方法损害了数据的隐私性和安全性。在一些应用场景中,例如金融行业、政府行业等,受限于数据隐私和安全的要求,根本无法实现对数据的集中存储;另一方面,这种方法会增加通信开销。在物联网等一些大量依赖于移动终端的应用中,这种数据汇聚的通信开销成本是非常巨大的。
联邦学习允许多个用户(称为客户机)协作训练共享的全局模型,而无需分享本地设备中的数据。由中央服务器协调完成多轮联邦学习以得到最终的全局模型。其中,在每一轮开始时,中央服务器将当前的全局模型发送给参与联邦学习的客户机。每个客户机根据其本地数据训练所接收到的全局模型,训练完毕后将更新后的模型返回中央服务器。中央服务器收集到所有客户机返回的更新后,对全局模型进行一次更新,进而结束本轮更新。通过上述多轮学习和通信的方法,联邦学习消除了在单个设备上聚合所有数据的需要,克服了机器学习任务中的隐私和通信挑战,允许机器学习模型学习分散在各个用户(客户机)上存储的数据。
联邦学习自提出以来获得了广泛的关注,并在一些场景中得以应用。联邦学习解决了数据汇聚的问题,使得一些跨机构、跨部门的机器学习模型、算法的设计和训练成为了可能。特别地,对于移动设备中的机器学习模型应用,联邦学习表现出了良好的性能和鲁棒性。此外,对于一些没有足够的私人数据来开发精确的本地模型的用户(客户机)来说,通过联邦学习能够大大改进机器学习模型和算法的性能。但是,由于联邦学习侧重于通过分布式学习所有参与客户机(设备)的本地数据来获得高质量的全局模型,因此它无法捕获每个设备的个人信息,从而导致推理或分类的性能下降。此外,传统的联邦学习需要所有参与设备就协作训练的共同模型达成一致,这在实际复杂的物联网应用中是不现实的。研究人员将联邦学习在实际应用中面临的问题总结如下[2]:(1)各个客户机(设备)在存储、计算和通信能力方面存在异构性;(2) 各个客户机(设备)本地数据的非独立同分布(Non-Idependently and Identically Distributed,Non-IID)所导致的数据异构性问题;(3)各个客户机根据其应用场景所需要的
模型异构性
问题。
为了解决这些异构性挑战,一种有效的方法是在设备、数据和模型级别上进行个性化处理,以减轻异构性并为每个设备获得高质量的个性化模型,即
个性化联邦学习
(Personalized Federated Learning)
。针对 Non-IID 的联邦学习,机器之心之前有专门的分析文章,感兴趣的读者可以阅读。针对设备异构性的问题,一般可以通过设计新的分布式架构(如 Client-Edge-Cloud[5])或新的联邦学习算法( Asynchronous Fed[6])来解决。
针对模型异构性的问题,作者在文献 [1] 中将不同的个性化联邦学习方法分为以下几类:增加用户上下文(Adding User Context )[8]、迁移学习(Transfer Learning)[9]、多任务学习(Multi-task Learning)[10]、元学习(Meta-Learning)[3]、知识蒸馏(Knowledge Distillation )[11]、基本层 + 个性化层( Base + Personalization Layers)[4]、混合全局和局部模型(Mixture of Global and Local Models )[12] 等。
本文选择了三篇关于个性化联邦学习的文章进行深入分析。其中,第一篇文章关于设备异构性的问题[6],作者提出了一种新的异步联邦优化算法。对于强凸和非强凸问题以及一类受限的非凸问题,该方法能够近似线性收敛到全局最优解。第二篇文章重点解决模型异构性的问题[7],作者提出了一种引入 Moreau Envelopes 作为客户机正则化损失函数的个性化联邦学习算法(pFedMe),该算法有助于将个性化模型优化与全局模型学习分离开来。最后,第三篇文章提出了一个协同云边缘框架 PerFit,用于个性化联邦学习,从整体上缓解物联网应用中固有的设备异构性、数据异构性和模型异构性[2]。
一、Asynchronous Federated Optimization
随着边缘设备 / 物联网(如智能手机、可穿戴设备、传感器以及智能家居 / 建筑)的广泛使用,这些设备在人们日常生活中所产生的大量数据催生了 “联邦学习” 的方法。另一方面,对于人工智能算法中所使用的的样本数据隐私性的考虑,进一步提高了人们对联邦学习的关注度。然而,联邦学习是同步优化(Synchronous)的,即中央服务器将全局模型同步发送给多个客户机,多个客户机基于本地数据训练模型后同步将更新后的模型返回中央服务器。联邦学习的同步特性具有不可扩展、低效和不灵活等问题。这种同步学习的方法在接入大量客户机的情况下,存在同时接收太多设备反馈会导致中央服务器端网络拥塞的问题。此外,由于客户机的计算能力和电池时间有限,任务调度因设备而异,因此很难在每个更新轮次(epoch)结束时精准的同步接入的客户机。传统方法会采取设定超时阈值的方法,删除无法及时同步的客户机。但是,如果可接入同步的客户机数量太少,中央服务器可能不得不放弃整个 epoch,包括所有已经接收到的更新。
为了解决同步联邦学习中出现的这些问题,本文提出了一种新的异步联邦优化算法,其关键思想是使用加权平均值来更新全局模型。可以根据陈旧性函数(A Function of the Staleness)自适应设定混合权重值。作者在文中证明,这些更改结合在一起能够生成有效的异步联邦优化过程。
![]()
![]()
其中,z^i 为第 i 个客户机设备中的数据采样。由于不同的客户机设备之间存在异构性,所存储的数据库也不同,从不同设备中提取的样本具有不同的期望值:
![]()
联邦学习的一次完整的更新过程由 T 个全局 epochs 组成。在第 t 个 epoch 中,中央服务器接收任意一个客户机发回的本地训练的模型 x_new,并通过加权平均来更新全局模型:
![]()
其中,α∈(0,1),α为混合超参数 (mixing hyperparameter)。在任意设备 i 上,在从中央服务器接收到全局模型 x_t(可能已经过时)后,使用 SGD 进行局部优化以解决以下正则化优化问题:
![]()
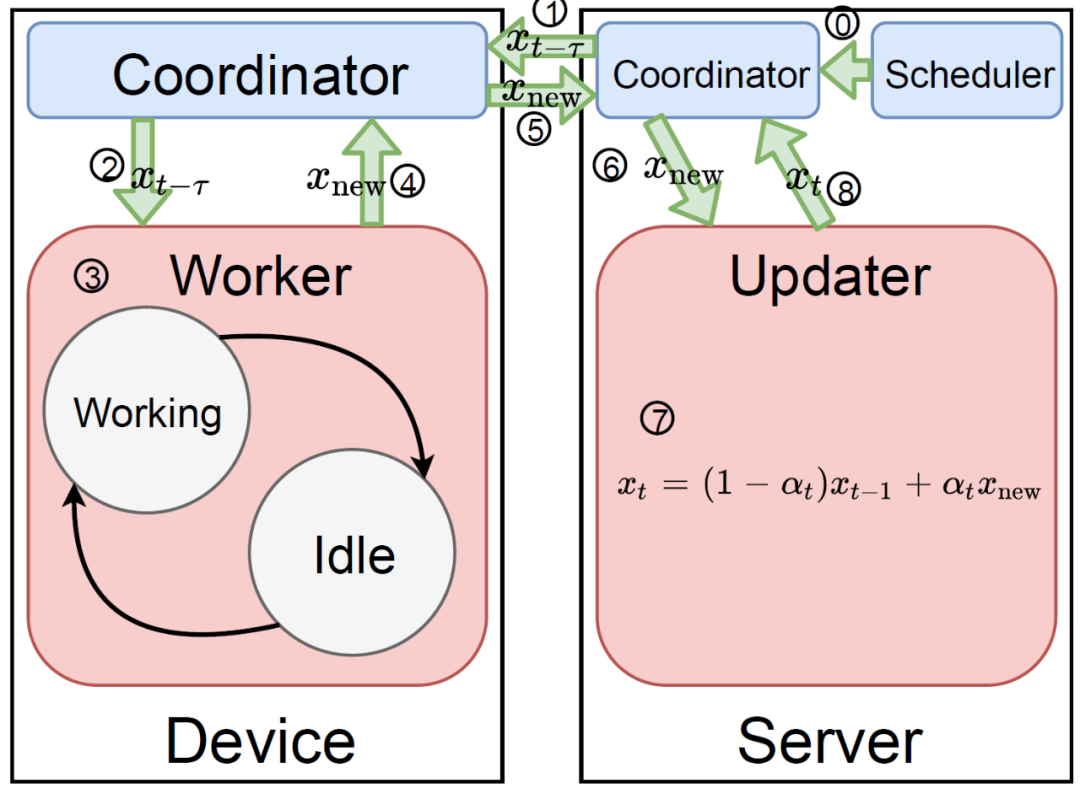
中央服务器和客户机设备的工作线程执行异步更新。当中央服务器接收到本地模型时,会立即更新全局模型。中央服务器和客户机线程之间的通信是非阻塞的。完整算法具体见算法 1。在中央服务器端,有两个线程异步并行运行:调度线程和更新线程。调度器定期触发一些客户机设备的训练任务。更新线程接收到客户机设备本地训练得到的模型后更新全局模型。全局模型通过多个具有读写锁的更新线程来提高吞吐量。调度器随机化训练任务的时间,以避免更新线程过载,同时控制各个训练任务的陈旧性(更新线程中的 t-τ)。更新全局模型时,客户端反馈的陈旧性越大(过时越久),错误就越大。
![]()
针对模型中的α混合超参,对于具有大滞后性的局部模型(t-τ)可以通过减小α来减小由陈旧性引起的误差。作者引入一个函数 s(t-τ)来控制α的值。具体的,可选函数格式如下:
![]()
本文提出的异步联邦优化方法的完整结构见图 1。其中,0:调度进程通过协调器触发训练任务。1、2:客户机设备接收中央服务器发来的延迟的全局模型 x_(t-τ)。3:客户机设备按照算法 1 中的描述进行本地更新。工作进程可以根据客户机设备的可用性在两种状态之间切换:工作状态和空闲状态。4、5、6:客户机设备通过协调器将本地更新的模型推送到中央服务器。调度程序对 5 中接收到的模型进行排队,并在 6、7、8 中按顺序将它们提供给更新进程:中央服务器更新全局模型并使其准备好在协调器中读取。在该系统中,1 和 5 异步并行运行,中央服务器可以随时触发客户机设备上的训练任务,而客户机设备也可以随时将本地更新的模型推送到中央服务器。
![]()
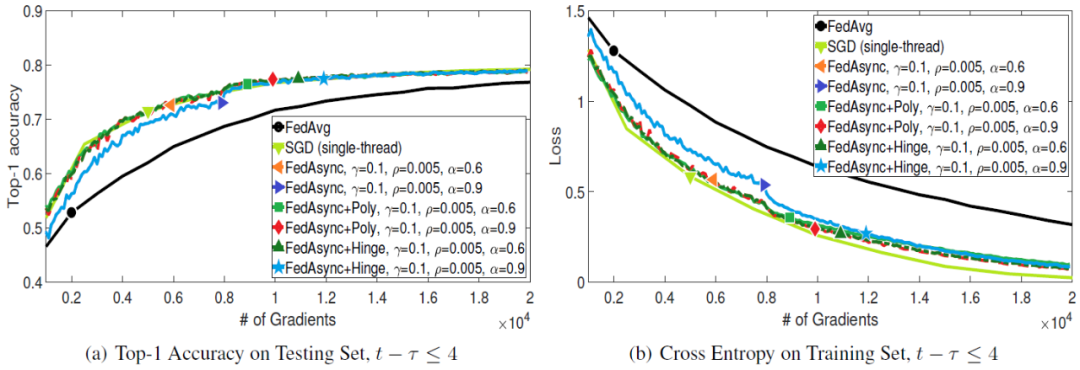
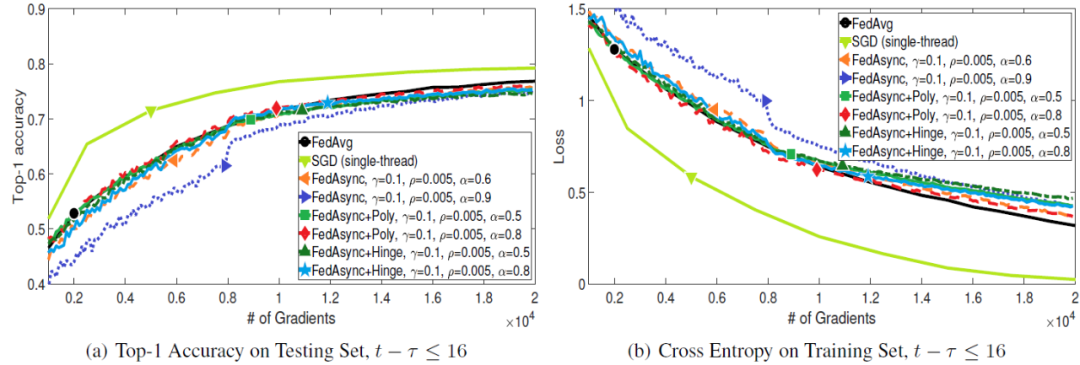
本文在基准 CIFAR-10 图像分类数据集上进行了实验,该数据集由 50k 个训练图像和 10k 个测试图像组成。调整每个图像的大小并将其裁剪为(24, 24, 3)的形状。使用 4 层卷积层 + 1 层全连接层结构的卷积神经网络(CNN)。实验中,将训练集划分到 n=100 个客户机设备上。其中,n=100 的每个分区中有 500 个图像。对于任何客户机设备,SGD 处理的小批量大小是 50。使用经典 FedAvg 联邦学习方法和单线程 SGD 作为基准方法。本文所提出的异步联邦优化方法记作 FedAsync。其中,根据α定义方式的不同,将选择多项式自适应α的方法定义为 FedAsync+Poly,将采用 Hinge 自适应α的方法记作 FedAsync+Hinge。
![]()
![]()
图 2 和图 3 给出了梯度值增加时 FedAsync 如何收敛。可以看到,当整体陈旧性较小时,FedAsync 收敛速度与 SGD 一样快,比 FedAvg 快。当陈旧性较大时,FedAsync 收敛速度较慢。在最坏的情况下,FedAsync 的收敛速度与 FedAvg 相似。当 α值非常大时,收敛可能不稳定。使用自适应 α,收敛性对较大的 α 是鲁棒的。当最大陈旧性状态为 4 时,FedAsync 和 FedAsync+Hinge (b=4)是相同的。
与经典联邦学习相比,本文提出的异步联邦优化方法具有下述优点:
效率:中央服务器可以随时接收客户机设备的更新。与 FedAvg 不同,陈旧性(延时反馈)的更新不会被删除。当陈旧性很小时,FedAsync 比 FedAvg 收敛的快得多。在最坏的情况下,当陈旧性很大时(延时严重),FedAsync 仍然具有与 FedAvg 相似的性能。
灵活性:如果某些设备不再能够执行训练任务(设备不再空闲、充电中或连接到不可用的网络),可以将其暂时挂起,等待继续训练或稍后将训练模型推送到中央服务器。这也为中央服务器上的进程调度提供了很大的灵活性。与 FedAvg 不同,FedAsync 可以自行安排训练任务,即使设备当前不合格 / 不能够工作,因为中央服务器无需一直等待设备响应,也可以做到令当前不合格 / 不能工作的客户机设备稍后开始训练任务。
可伸缩性:与 FedAvg 相比,FedAsync 可以处理更多并行运行的客户机设备,因为中央服务器和这些设备上的所有更新都是非阻塞的。服务器只需随机化各个客户机设备的响应时间即可避免网络拥塞。
作者在文章中通过理论分析和实验验证的方式证明了 FedAsync 的收敛性。对于强凸问题和非强凸问题,以及一类受限制的非凸问题,FedAsync 具有近似线性收敛到全局最优解的能力。在未来的工作中,作者计划进一步研究如何设计策略来更好的调整混合超参数。
二、Personalized Federated Learning with Moreau Envelopes
![]()
随着手持设备、移动终端的快速发展和推广应用,这些手持设备 / 移动终端产生的大量数据推动了联邦学习的发展。联邦学习以一种保护隐私和高效通信的方式通过分散在客户端(客户机设备)中的数据构建一个精确的全局模型。在实际应用中,经典联邦学习面临了这样一个问题:* 如何利用联邦学习中的全局模型来找到一个针对每个客户端数据进行个性化适配处理的“个性化模型”*?
参考个性化模型在医疗保健、金融和人工智能服务等领域中应用的模式,本文提出了一种个性化联邦学习方案,该方案引入了基于客户端损失函数的 Moreau envelopes 优化。通过该方案,客户端不仅可以像经典联邦学习一样构建全局模型,而且可以利用全局模型来优化其个性化模型。从几何的角度分析,该方案中的全局模型可以看作是所有客户端一致同意的“中心点”,而个性化模型是客户端根据其异构数据分布来构建的遵循不同方向的点。
![]() (1)
(1)
其中,ω 表示全局模型,函数 f_i 表示客户端 i 中数据分布的预期损失。
![]()
其中,ξ_i 为根据客户端 i 的分布随机抽取数据样本,f_i(ω;ξ _i)表示对应于该样本和ω的损失函数。在联邦学习中,由于客户端的数据可能来自不同的环境、上下文和应用程序,因此客户端具有 Non-IID 数据分布,不同客户端的ξ_i 不同。
不同于经典联邦学习,本文对每个客户端使用 L_2 范数的正则化损失函数,如下所示:
![]() (2)
(2)
其中,θ_i 表示客户端 i 的个性化模型,λ表示控制个性化模型的ω强度的正则化参数。虽然较大的λ可以从丰富的数据聚合中受益于不可靠的数据,但是较小的λ可以帮助拥有足够多有用数据的客户端优先进行个性化设置。总之,本文方法的目的是 * 允许客户端沿不同的方向更新本地模型,同时不会偏离每个客户端都贡献所得到的“参考点”ω*。个性化联邦学习可以表述为一个双层问题:
![]()
通过在外部层(outer level)利用来自多个客户端的数据聚合来确定ω,在内部层(inner level)针对客户端 i 的数据分布优化θ_i,并使其与ω保持一定距离。F_i(ω)定义为 Moreau envelope。最优个性化模型是解决 pFedMe 内部层问题的唯一解决方案,在文献中也被称为邻近算子(proximal operator),其定义如下:
![]() (3)
(3)
为了进行比较,作者讨论了 Per-FedAvg[13],它可以说是最接近 pFedMe 的公式:
![]() (4)
(4)
Per-FedAvg 是一个元学习方法,基于经典元学习的与模型无关的元学习(MAML)框架,Per-FedAvg 的目标是找到一个全局模型ω,可以用它作为初始化全局模型,进一步对损失函数执行梯度更新(步长为 α)来得到它的个性化模型θ_i(ω)。
与 Per-FedAvg 相比,本文的问题具有类似于 “元模型” 的考虑,但是没有使用ω作为初始化,而是通过解决一个双层问题来并行地求得个性化和全局模型,这种方式有几个好处:首先,虽然 Per-FedAvg 针对其个性化模型进行了一步梯度更新的优化,但 pFedMe 对内部优化器是不可知的,这意味着公式(3)可以使用任何具有多步更新的迭代方法来求解。其次,可以将 Per-FedAvg 的个性化模型更新重写为:
![]() (5)
(5)
使用 < x,y > 作为两个向量 x 和 y 的内积,可以看到除了相似的正则化项外,Per-FedAvg 只优化了 f_i 的一阶近似,而 pFedMe 直接最小化了公式(3)中的 f_i。第三,Per-FedAvg(或通常基于 MAML 的方法)需要计算或估计 Hessian 矩阵,而 pFedMe 只需要使用一阶方法计算梯度。
此外,作者还给出了 Moreau envelope 的一些数学特性证明,这些数学特性能够保证引入 Moreau envelope 的联邦学习方法的收敛性。
假设 1(强凸性和光滑性):f_i 分别是(a)μ- 强凸或(b)非凸和 L - 光滑的(即 L-Lipschitz 梯度),如下所示:
![]()
假设 2(有界方差):每个客户端的随机梯度方差是有界的:
![]()
假设 3(有界多样性):局部梯度对全局梯度的方差是有界的
![]()
最后,作者回顾了 Moreau envelope 的一些有用的性质,例如平滑和保持凸性。
命题 1:如果 f_i 与 L-Lipschitz-▽f_i 是凸的或非凸的,那么▽f_i 是 L_F - 光滑的,L_F=λ(对于非凸 L - 光滑 f_i,条件是λ>2L),并且有:
![]()
此外,如果 f_i 是μ强凸的,那么 f_i 是 F_i - 强凸的μ_F=λ_μ/(λ+μ)。
最后,作者介绍本文提出的 pFedMe 完整流程如下:
![]()
首先,在内部层,每个客户端 i 求解公式(3)以获得其个性化模型,其中 w^t_(i,r)表示客户端 i 在全局轮次 t 和局部轮次 r 的局部模型。与 FedAvg 类似,本地模型的目的是帮助构建全局模型,减少客户端和服务器之间的通信轮数。其次,在外部层面,使用随机梯度下降的客户端 i 的局部更新是关于 F_i(而不是 f_i)的,如下所示
![]()
其中,η表示学习速率,使用当前个性化模型和公式 (6) 计算▽F_i。
此外,作者还提出在实际场景中应用时,一般采用满足下面约束的δ近似的个性化模型:
![]()
![]()
这样处理的原因有两个:第一,使用公式(3)计算个性化模型需要计算▽F_i(θ_i),这种计算依赖于ξ_i 的分布。实际上,可以通过对 D_i 的小样本采样来计算▽F_i(θ_i)的无偏估计:
![]()
![]()
第二,获取封闭形式的个性化模型是很困难的,相反,通常使用迭代一阶方法来获得高精度的近似值:
![]()
选择λ,令 h_i 是条件数为 k 的强凸,然后可以应用梯度下降(例如,奈斯特罗夫加速梯度下降(Nesterov’s accelerated
gradient descent)))以获得个性化模型:
![]()
pFedMe 中每个客户端的计算复杂度是 FedAvg 的 K 倍。
本文实验考虑了一个使用真实(MNIST)和合成数据集的分类问题。MNIST 是一个手写数字数据集,包含 10 个标签和 70000 个实例。由于 MNIST 数据量的限制,作者将完整的 MNIST 数据集分发给 N=20 个客户端。为了根据本地数据大小和类别对异构设置进行建模,每个客户端都被分配了一个不同的本地数据大小,范围为 [1165;3834],并且只有 10 个标签中的 2 个。对于合成数据,作者采用数据生成和分布过程,使用两个参数 α=0.5 和β=0.5 来控制每个客户端的本地模型和数据集的差异。具体来说,数据集使用 60 维实值数据为 10 类分类器提供服务。每个客户端的数据大小在[250;25810] 范围内。最后,将数据分发给 N=100 个客户端。
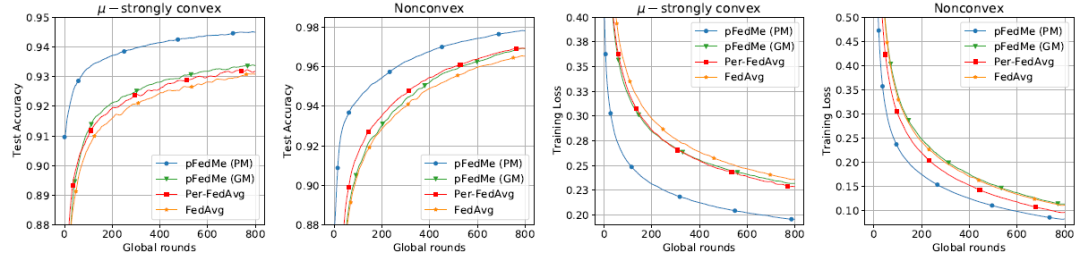
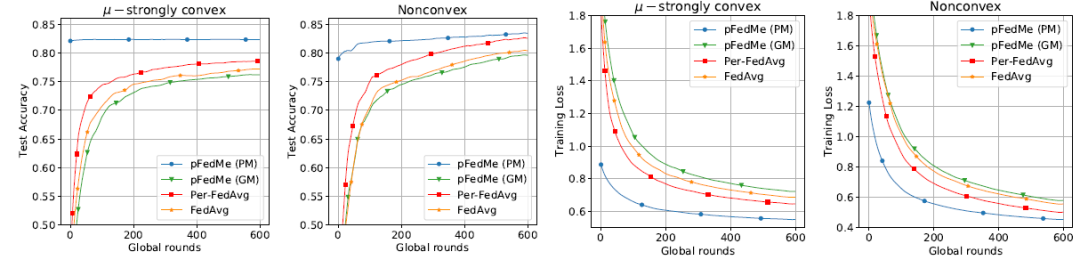
作者对 pFedMe、FedAvg 和 Per-FedAvg 进行了比较。MNIST 数据集中的实验结果见图 4。pFedMe 的个性化模型在强凸设置下的准确率分别比其全局模型 Per-FedAvg 和 FedAvg 高 1.1%、1.3% 和 1.5%。非凸设置下的相应数据为 0.9%、0.9% 和 1.3%。
![]()
图 4. 使用 MNIST 的 pFedMe、FedAvg 和 Per-FedAvg 在μ- 强凸和非凸设置下的性能比较
对于合成数据集,利用相同参数和微调参数的比较结果见图 5。在图 5 中,尽管 pFedMe 的全局模型在测试准确率和训练损失方面表现不如其他模型,但 pFedMe 的个性化模型仍然显示出它的优势,因为它获得了最高的测试准确率和最小的训练损失。图 5 显示,pFedMe 的个性化模型比其全局模型 Per-FedAvg 和 FedAvg 的准确率分别高出 6.1%、3.8% 和 5.2%。
![]()
图 5. 使用合成数据集的 pFedMe、FedAvg 和 Per-FedAvg 在μ- 强凸和非凸设置下的性能比较
从实验结果来看,当客户端之间的数据是非独立同分布(Non-IID)时,pFedMe 和 Per-FedAvg 都获得了比 FedAvg 更高的测试准确度,因为这两种方法允许全局模型针对特定客户端进行个性化处理。通过多次梯度更新近似优化个性化模型从而避免计算 Hessian 矩阵,pFedMe 的个性化模型在收敛速度和计算复杂度方面比 Per-FedAvg 更具优势。
本文提出了一种个性化联邦学习方法 pFedMe。pFedMe 利用了 Moreau envelope 函数,该函数有助于将个性化模型优化从全局模型学习中分解出来,从而使得 pFedMe 可以类似于 FedAvg 更新全局模型,但又能根据 t 每个客户端的本地数据分布并行优化个性化模型。理论结果表明,pFedMe 可以达到最快的收敛加速率。实验结果表明,在凸和非凸环境下,使用真实和合成数据集,pFedMe 的性能都优于经典 FedAvg 和基于元学习的个性化联邦学习算法 Per-FedAvg。
三、Personalized Federated Learning for Intelligent IoT Applications: A Cloud-Edge based Framework
![]()
复杂物联网环境中固有的设备、统计和模型的异构性给传统的联邦学习带来了巨大挑战,使其无法直接部署应用。为了解决物联网环境中的异构性问题,本文重点研究个性化联邦学习方法,这种方法能够减轻异质性带来的负面影响。此外,借助边缘计算的能力,个性化联邦学习能够满足智能物联网应用对快速处理能力和低延迟的要求。
边缘计算的提出主要是为了解决设备异构性中的高通信和计算成本问题,从而为物联网设备提供了按需计算的能力。因此,每个物联网设备可以选择将其计算密集型学习任务卸载到边缘,以满足快速处理能力和低延迟的要求。此外,边缘计算可以通过在本地就近存储数据的方式(例如,在智能家庭应用的智能边缘网关中)解决隐私问题,而无需将数据上传到远程云。还可以采用差分隐私和同态加密等隐私和安全保护技术来提高隐私保护水平。
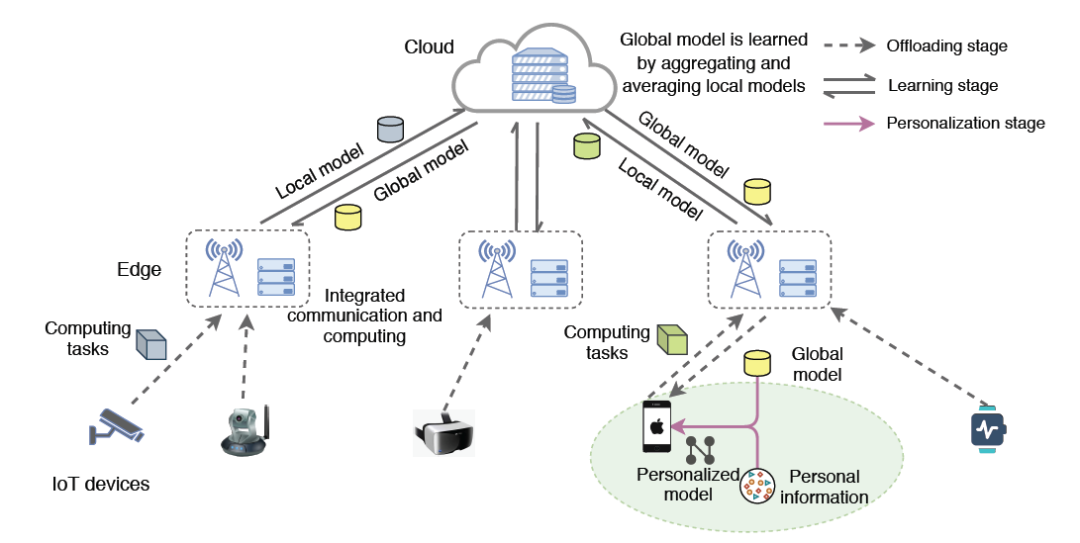
本文提出了一个用于个性化联邦学习的协同云边缘框架 PerFit,该框架能够从整体上缓解物联网应用中固有的设备异构性、统计异构性和模型异构性问题。对于统计和模型的异构性,该框架还允许终端设备和边缘服务器在云边缘范例中的中心云服务器的协调下共同训练一个全局模型。在对全局模型进行学习训练后,在客户端设备中可以采用不同的个性化联邦学习方法,根据不同设备的应用需求对其进行个性化模型部署。
本文提出了一个针对智能物联网应用的个性化联邦学习框架,以整体的方式应对设备异构性、数据异构性和模型异构性挑战。如图 6 所示,本文提出的 PerFit 框架采用云边缘架构,为物联网设备提供必要的按需边缘计算能力。每个物联网设备可以选择通过无线连接将其密集的计算任务转移到边缘设备中(即家中的边缘网关、办公室的边缘服务器或室外的 5G MEC 服务器),从而满足物联网应用的高处理效率和低延迟的要求。
![]()
图 6. 智能物联网应用的个性化联邦学习框架,支持灵活选择个性化的联邦学习方法
具体来说,PerFit 中的协作学习过程主要包括以下三个阶段,如图 6 中所述:
卸载阶段(Offloading stage)。当边缘设备是可信的(例如,家中的边缘网关),物联网设备用户可以将其整个学习模型和数据样本卸载到边缘设备中以进行快速计算。否则,设备用户将通过将输入层及其数据样本本地保存在其设备上并将剩余的模型层卸载到边缘设备中以进行设备边缘协作计算来执行模型划分。
学习阶段(Learning stage)。边缘设备根据个人数据样本协同计算本地模型,然后将本地模型信息传输到云服务器。云服务器将各个边缘设备所提交的本地模型信息聚合起来,并将它们平均化为一个全局模型,然后发送回各个边缘设备中。这样的模型信息交换过程不断重复,直到经过一定次数的迭代后收敛为止。因此,可以实现一个高质量的全局模型,然后传输到边缘设备以进行进一步的个性化设置。
个性化阶段(Personalization stage)。为了捕捉特定的个人特征和需求,每个边缘设备都基于全局模型信息和自身的个人信息(即本地数据)训练一个个性化模型。这一阶段的具体学习操作取决于采用的个性化联邦学习机制。例如,迁移学习、多任务学习、元学习、知识蒸馏、混合模型等。
进一步,在边缘设备上进行本地模型聚合,也有助于避免大量设备通过昂贵的主干网带宽与云服务器直接通信,从而降低通信开销。通过执行个性化处理,可以在一些资源有限的设备上部署轻量级的个性化模型(例如,通过模型修剪或传输学习)。这将有助于减轻设备在通信和计算资源方面的异构性。此外,也可以很好的支持统计异构性和模型异构性,因为该框架可以根据不同边缘设备的本地数据特性、应用程序需求和部署环境利用个性化的模型和机制。
PerFit 通过在边缘设备和云服务器之间交换不同类型的模型信息,能够灵活地集成多种个性化的联邦学习方法,包括我们在这篇文章中分析的两种个性化联邦学习方法。通过解决复杂物联网环境中固有的异构性问题并在默认情况下确保用户隐私,PerFit 可以成为大规模实际部署的理想选择。
作者在文章中回顾并简述了几个个性化联合学习机制,这些机制可以与 PerFit 框架集成用于智能物联网应用程序。文中重点分析了以下几种类型:联邦迁移学习,联邦元学习,联邦多任务学习、联邦蒸馏和数据增强。
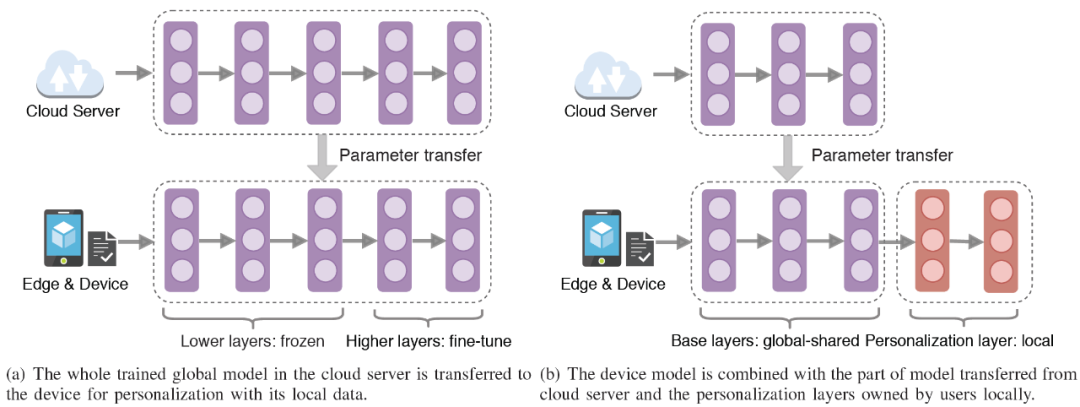
联邦迁移学习的基本思想是将全局共享模型迁移到分布式物联网设备上(客户端设备),通过针对各个物联网设备实现个性化处理,以减轻联邦学习中固有的数据异构性问题(Non-IID 数据分布)。考虑到深度神经网络的结构和通信过载问题,通过联邦转移学习实现个性化的方法主要有两种。具体可见图 7。
图 7(a)中为 Chen 在文献 [14] 中提出的联邦迁移学习方法。首先通过经典的联邦学习训练一个全局模型,然后将全局模型发送至每个客户端设备。每个设备都能够通过使用其本地数据来改进、细化全局模型从而构建个性化模型。为了减少训练开销,只对指定层的模型参数进行微调,而不是对整个模型进行再训练。由图 7(a)可见,由于深度网络的底层侧重于学习全局(公共的)和底层特征,因此,在全局模型中的这些底层参数可以传输到局部模型中后直接复用。而传入的更高层的全局模型参数则应该根据本地数据进行微调,以便学习到针对当前设备定制的更具体的个性化特性。
Arivazhagan 等在文献 [15] 中提出了另一类联邦迁移学习方法 FedPer。FedPer 主张将深度学习模型视为基础 + 个性化层,如图 7(b)所示。其中,将基本层作为共享层,使用现有的联邦学习方法(即 FedAvg 方法)以协作方式进行训练。而个人化层在本地进行训练,从而能够捕获物联网设备的个人信息。在联邦学习一个阶段的训练过程之后,可以将全局共享的基础层转移到参与的物联网设备上,以其独特的个性化层构建自己的个性化深度学习模型。因此,FedPer 能够捕捉到特定设备上的细粒度信息,以进行更好的个性化推理或分类,并在一定程度上解决数据异构性问题。此外,由于只需要上传和聚合部分模型,FedPer 需要较少的计算和通信开销,这在物联网环境中是至关重要的。
![]()
在元学习中,模型是由一个能够学习大量相似任务的元学习者(a Meta-Learner)来训练的,训练模型的目标是从少量的新数据中快速适应新的相似任务。联邦元学习是指将元学习中的相似任务作为设备的个性化模型,将联邦学习与元学习相结合,通过协作学习实现个性化处理。Jiang 等在文献 [16] 中提出了一种改进的个性化 FedAvg。该方法通过引入一个精细化调整阶段,该精细化调整阶段使用模型不可知的元学习算法(model agnostic meta learning,MAML)。通过联邦学习训练得到的全局模型可以个性化地捕捉单个设备中的细粒度信息,从而提高每个物联网设备的性能。MAML 可以灵活地与任何模型表示相结合,以适应基于梯度的训练。此外,它只需少量的数据样本就可以快速学习和个性化适应处理。
由于联邦元学习方法通常使用复杂的训练算法,因此,与联邦迁移学习方法相比,联邦元学习方法实现的复杂度较高。不过,联邦元学习方法的学习模型更健壮,这一特性对于数据样本很少的设备是非常有用的。
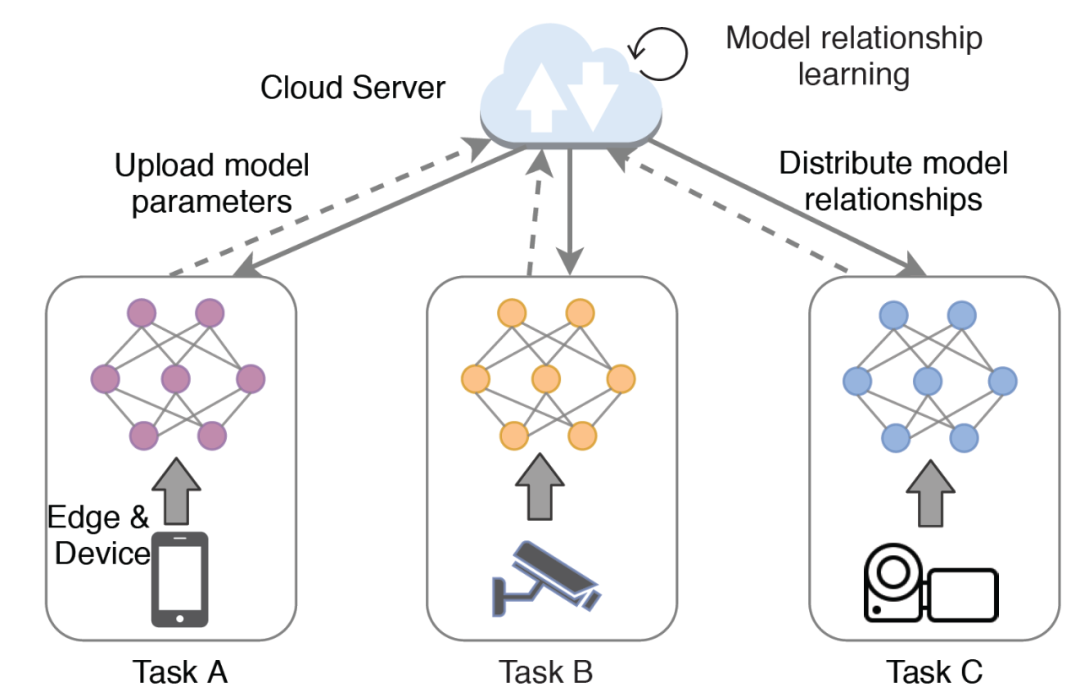
由前两节的分析可知,联邦迁移学习和联邦元学习的目的是通过个性化微调处理,在物联网设备上学习相同或相似任务的共享模型。与这种思路不同的是,联邦多任务学习的目标是同时学习不同设备的不同任务,并试图在没有隐私风险的情况下捕捉它们之间的模型关系(Model Relationships)。利用这种模型关系,每个设备的模型可以获取其他设备的信息。此外,为每个设备学习的模型总是个性化的。
由图 8 所示,在联邦多任务学习训练过程中,云服务器根据物联网设备上传的模型参数,学习多个学习任务之间的模型关系。然后,每个设备可以用其本地数据和当前模型关系更新自己的模型参数。联邦多任务学习通过交替优化云服务器中的模型关系和每个任务的模型参数,使参与其中的物联网设备能够协同训练其本地模型,从而减轻数据异构性,获得高质量的个性化模型。
文献 [17] 中提出了一种分布式优化方法 MOCHA。为了应对高通信成本的问题,MOCHA 具有一定的计算灵活性,从而通过执行额外的本地计算的方式造成在联邦环境下的通信轮次更少。为了减少最终结果的离散程度,作者建议在计算资源有限的情况下近似计算设备的本地更新。此外,异步更新方案也是避免离散问题的一种替代方法。此外,通过允许参与设备周期性地退出,MOCHA 具有健壮的容错性。由于复杂物联网环境中固有的设备异构性对联邦学习的性能至关重要,联邦多任务学习对于智能物联网应用具有重要意义。
![]()
在经典联邦学习框架中,所有的客户机(例如参与的边缘设备)都必须同意在全局服务器和本地客户机上训练得到的模型的特定体系结构。然而,在一些现实的商业环境中,如医疗保健领域和金融领域等,每个参与者都有能力和意愿设计自己独特的模型,并且可能出于隐私和知识产权的考虑而不愿意分享模型细节。这种模型异构性对传统的联邦学习提出了新的挑战。
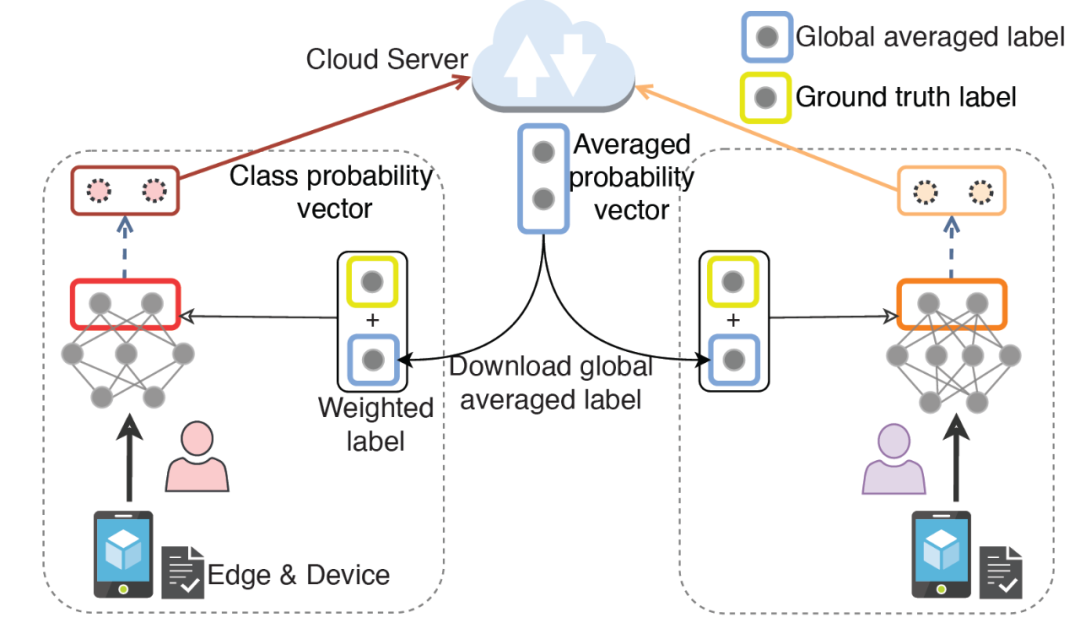
Li 等在文献 [18] 中提出了一个新的联邦学习框架 FedMD,使参与者能够利用知识蒸馏的方法独立地设计自己的模型。在 FedMD 中,每个客户机独立的将所学知识转化为标准格式,在不共享数据和模型体系结构的情况下确保其他人可以理解该格式。中央服务器收集这些知识来计算全局模型,并将其进一步分发给参与的客户机。知识转换步骤可以通过知识蒸馏来实现,例如,使用客户模型产生的类概率作为标准格式,如图 9 所示。通过这种方式,云服务器聚合并平均每个数据样本的类概率,然后分发到客户机以指导其更新。
Jeong 等在文献 [19] 中提出一种联邦蒸馏方法,其中每个客户机将自己视为学生,并将所有其他客户机的平均模型输出视为其教师的输出。教师与学生的产出差异为学生提供了学习的方向。这里值得注意的是,为了在联邦学习中进行知识提炼,需要一个公共数据集,因为教师和学生的输出应该使用相同的训练数据样本进行评估。
![]()
Zhao 等提出了一种数据共享策略,将一些均匀分布的全局数据从云端(中央服务器)分发到边缘客户端[20],从而在一定程度上缓解客户数据高度不平衡的分布状况,从而提高个性化模型的性能。然而,直接将全局数据分发到边缘客户端会带来很大的隐私泄露风险,这种方法需要在数据隐私保护和性能改进之间进行权衡。此外,全局共享数据与用户本地数据的分布差异也会导致性能下降。
为了在不损害用户隐私的前提下纠正不平衡的 Non-IID 局部数据集问题,研究人员采用了一些具有生成能力的过采样技术和深度学习方法。Jeong 等提出了一种联邦扩充方法(Federated Augmentation,FAug)[21],其中每个客户机共同训练一个生成模型,从而扩充其本地数据以生成 IID 数据集。具体地说,每个边缘客户机识别其数据样本中缺少的标签(称为目标标签),然后将这些目标标签的少数种子数据样本上载到服务器。服务器对上传的种子数据样本进行过采样,然后训练一个生成性对抗网络(Generative Atterial Network,GAN)。最后,每个设备可以下载经过训练的 GAN 发生器来补充其目标标签,直到得到一个平衡的数据集。通过数据扩充,每个客户机可以根据生成的数据集训练出一个更加个性化和精确的用于分类或推理任务的模型。值得注意的是,FAug 的服务器应该是可信的,这样用户才愿意上传他们的个人数据。
本文实验基于一个名为 MobiAct 的可公开访问的数据集完成,该数据集重点研究人类活动识别任务。每个参与构建 MobiAct 数据集的志愿者都戴着三星 Galaxy S3 智能手机,带有加速计和陀螺仪传感器。志愿者在进行预定活动时,三轴线性加速度计和角速度信号由嵌入式传感器记录。使用 1 秒的滑动窗口进行特征提取,因为一秒钟就足够执行一个活动。MobiAct 中记录了 10 种活动,如步行、上下楼梯、摔倒、跳跃、慢跑、踏车等。为了实际模拟联邦学习的环境,本文实验随机选择了 30 名志愿者,并将他们视为不同的客户端。对于每个客户端,为每个活动随机抽取若干个样本,最后,每个客户端有 480 个样本用于模型训练。这样,不同客户端的个人数据可能呈现出 Non-IID 分布(统计异质性)。每个客户端的测试数据由分布均衡的 160 个样本组成。
使用两种模型进行客户端中的个性化学习。1) 多层感知器网络由三个完全连接的层组成,有 400 个、100 个和 10 个神经单元(总参数 521510 个),记作 3NN。2) 卷积神经网络(CNN),有三个 3×3 的卷积层(第一层有 32 个通道,第二个有 16 个通道,最后一个有 8 个通道,前两层每个都有一个 2×2 最大池化层),一个有 128 个单元和 ReLu 激活的全连接层,以及一个最终的 Softmax 输出层(总参数为 33698)。采用交叉熵损失和随机梯度下降(SGD)优化算法训练 3NN 和 CNN,学习率为 0.01。
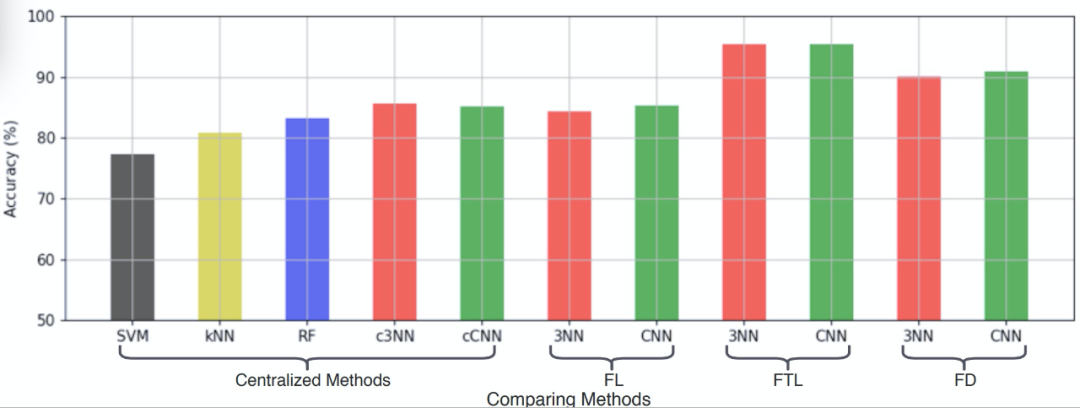
作者选择集中式学习、经典联邦学习方法作为基准方法。对于集中式方法,采用了支持向量机(SVM)、k - 最近邻(kNN)和随机森林(RF)等常用的机器学习方法。此外,还采用了集中式 3NN(c3NN)和集中式 CNN(cCNN)进行比较。对于个性化联邦学习,作者选择了两种被广泛采用的方法:联邦迁移学习(Federated Transfer Learning ,FTL)和联邦蒸馏(Federated Distillation,FD)。对于 FTL,每个客户端设备将使用其个人数据对从云服务器下载的模型进行微调。而在 FD 中,每个客户端可以根据自己的需求定制自己的模型。
图 10 给出了 30 个客户端在不同学习方法下的测试准确度。对于集中式方法,基于深度学习的方法(c3NN、cCNN)可以比传统的基于机器学习的方法(SVM、kNN 和 RF)获得更高的准确度。经典联邦学习(FL-CNN)中的边缘客户端在中央云服务器的协调下,能够在不损害数据隐私的前提下改进识别性能,并达到与 cCNN 类似的 85.22% 的识别率。FL-3NN 和 FL-CNN 与集中式模式相比性能略有下降,这是由于联邦学习环境中固有的统计异质性造成的。通过个性化的联邦学习,FTL 和 FD 都可以捕捉到用户细粒度的个人信息,并为每个参与者获得个性化的模型,从而获得更高的测试准确度。例如,FTL-3NN 识别率可达 95.37%,比 FL3NN 高 11.12%。
![]()
图 10. 不同学习方法在人体活动识别中的准确性研究
本文提出了一个云边缘架构中的个性化联邦学习框架 PerFit,用于具有数据隐私保护的智能物联网应用。PerFit 能够通过聚合来自分布式物联网设备的本地更新并利用边缘计算的优点来学习全局共享模型。为了解决物联网环境中的设备、统计和模型的异构性,PerFit 可以自然地集成各种个性化联邦学习方法,从而实现物联网应用中设备的个性化处理并增强性能。通过一个人类活动识别任务的案例研究,作者证明了 PerFit 的有效性。
在这篇文章中,我们聚焦了个性化联邦学习的问题。联邦学习是一个有效的处理分布式数据训练的解决方案,它能够通过聚集和平均本地计算的更新来协作训练高质量的共享全局模型。此外,联邦学习能够在不损害用户数据隐私的情况下学习得到令人满意的全局模型。然而,由于分布式处理方式的固有弊端,联邦学习面临设备异构性、数据异构性和模型异构性等问题,在实际推广应用中存在无法直接部署的风险。
个性化联邦学习的目的是根据不同设备的应用需求对其进行个性化模型部署,以解决各类异构性问题。本文选择了专门针对于设备异构性和模型异构性问题的两篇文章进行详细分析,最后还选择了一篇文章介绍在物联网应用的云边缘架构中使用的个性化联邦学习框架。由我们选择的几篇论文中作者进行的理论分析和实验给出的结果可以看出,个性化联邦学习确实可以改进经典联邦学习方法的效果,能够有效应对客户端设备中的各种异构性情况,甚至能够处理一些设备宕机 / 存储空间已满等临时性失效的问题。联邦学习在各类实际场景中都有着巨大的应用需求,我们会继续关注个性化联邦学习的技术发展和部署应用方法。
[1] Kulkarni, Viraj,Kulkarni, Milind,Pant, Aniruddha, Survey of personalization techniques for federated learning, http://arxiv.org/abs/2003.08673?context=cs.LG
[2] Q. Wu, K. He, and X. Chen, “Personalized federated learning for intelligent iot applications: A cloud-edge based framework,” arXiv preprint arXiv:2002.10671, 2020.
[3] Y. Jiang, J. Konecny, K. Rush, and S. Kannan, “Improving federated learning personalization via model agnostic meta learning,” arXiv preprint arXiv:1909.12488, 2019.
[4] M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary, “Federated learning with personalization layers,” arXiv preprint arXiv:1912.00818, 2019.
[5] Liu L , Zhang J , Song S H , et al. Client-Edge-Cloud Hierarchical Federated Learning. 2019. https://arxiv.org/pdf/1905.06641.pdf.
[6] Xie C , Koyejo S , Gupta I . Asynchronous Federated Optimization. 2019. https://arxiv.org/pdf/1903.03934.pdf.
[7] Dinh, Canh T.,Tran, Nguyen H.,Nguyen, Tuan Dung, Personalized federated learning with moreau envelopes.http://arxiv.org/abs/2006.08848?context=stat
[8] Y. Mansour, M. Mohri, J. Ro, and A. T. Suresh, “Three approaches for personalization with applications to federated learning,” arXiv preprint arXiv:2002.10619, 2020.
[9] J. Schneider and M. Vlachos, “Mass personalization of deep learning,” arXiv preprint arXiv:1909.02803, 2019.
[10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Advances in Neural Information Processing Systems, pp. 4424– 4434, 2017.
[11] D. Li and J. Wang, “Fedmd: Heterogenous federated learning via model distillation,” arXiv preprint arXiv:1910.03581, 2019
[12] F. Hanzely and P. Richt´arik, “Federated learning of a mixture of global and local models,” arXiv preprint arXiv:2002.05516, 2020.
[13] A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized Federated Learning: A Meta-Learning Approach,”
arXiv:2002.07948 [cs, math, stat], Feb. 2020. [Online]. Available: http://arxiv.org/abs/2002.07948
[14] Yiqiang Chen, Jindong Wang, Chaohui Yu, Wen Gao, and Xin Qin. Fedhealth: A federated transfer learning framework for wearable healthcare. arXiv preprint arXiv:1907.09173, 2019.
[15] Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818, 2019.
[16] Yihan Jiang, Jakub Koneˇcn`y, Keith Rush, and Sreeram Kannan. Improving federated learning personalization via model agnostic meta learning. arXiv preprint arXiv:1909.12488, 2019.
[17] Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet S Talwalkar. Federated multi-task learning. In Advances in Neural Information Processing Systems, pages 4424–4434, 2017.
[18] Daliang Li and Junpu Wang. Fedmd: Heterogenous federated learning via model distillation. arXiv preprint arXiv:1910.03581, 2019.
[19] Eunjeong Jeong, Seungeun Oh, Hyesung Kim, Jihong Park, Mehdi Bennis, and Seong-Lyun Kim. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv preprint arXiv:1811.11479, 2018.
[20] Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. Federated learning with non-iid data. arXiv preprint arXiv:1806.00582, 2018.
[21] Eunjeong Jeong, Seungeun Oh, Hyesung Kim, Jihong Park, Mehdi Bennis, and Seong-Lyun Kim. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv preprint arXiv:1811.11479, 2018.
本文作者为仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。