联邦学习简介

谷歌于2017年提出联邦学习的训练方法,发表了相关博客链接[1],从[1]这篇文章的标题《Federated Learning: Collaborative Machine Learning without Centralized Training Data》可以看出来谷歌对于联邦学习的基本定义是,无需通过中心化的数据,即可训练一个机器学习模型。
即假设训练数据分布在>1台不同的计算机(终端、服务器、移动设备等都可以)上,这个时候如果按照非联邦学习的方法,需要先把数据收集到同一的单一服务器(或服务器集群)中,然后统一训练,这带来的主要问题就是这种数据收集可能涉及隐私泄漏、许可协议等问题,于是提出来一种,不需要上传数据到单一服务器的训练方法。
总结起来就是:部分模型、部分模型参数(或梯度)可共享,数据不可共享。因为共享的是模型而不是数据,可以最大限度避免数据泄漏,相比数据脱敏的相关算法(如K-annoymity),保密性更强。
谷歌提出的联邦学习思想中,可以参考另一个介绍文章[2],给出的例子是toC的训练,例子中数据保存在个人移动设备中(手机),不需要数据上传,大体的思路是:

(图片引用自谷歌博客)
A节点为用户设备,数据保存其中,并且不上传到其他节点
B节点是来自不同用户设备的模型参数聚合
C节点可以认为是一个统一的中央服务器(或集群),用来统一更新模型
大体流程是:
首先C初始化一个空模型
C将当前的模型参数传输到A
A设备中根据数据,计算模型参数(或梯度等)
A设备将更新后的模型参数(或梯度)上传
B对来自不同设备的模型参数(或梯度)聚合,例如简单取平均值
C更新根据B聚合后的结果,更新模型
回到第2.步,循环往复
从来自wiki的图片也可以看出来,大体过程:
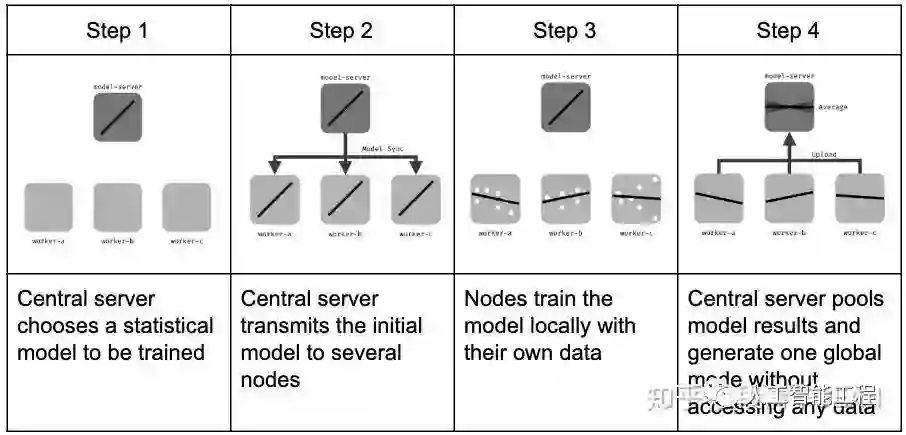
(图片引用自维基百科)
引申发展
在谷歌提出联邦学习问题之后,结合其他如隐私数据等研究,一部分人,如微众银行与后续他们组织的fedai等组织,以及相关提出的白皮书[3][4],给出了提出了一些新的应用场景。
主要区别是谷歌提出了主要面向C端用户的方法,而部分人希望能将之扩展到B端机构,例如多个拥有不同程度重叠数据方。
谷歌提出的toC应用中,每个训练终端相当于有且只有一个用户(因为是手机嘛),但是用户特征高度重叠(例如都是搜索引擎点击记录),这种情况下被[4]称为横向联邦学习。
例如某城市内的银行拥有这个城市很多商户的贷款、违约等信息,这个城市内运营的电商公司有这个城市的这些商户的销量、差评等数据,但是银行和电商公司都不能直接互联数据,但是希望能共享同一个信用评级模型。即用户重叠,但用户特征不重叠。这种情况下被文献[4]称为纵向联邦学习。
Reference
[1]https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[2]https://blog.tensorflow.org/2019/03/introducing-tensorflow-federated.html
[3]https://www.fedai.org/
[4]https://aisp-1251170195.cos.ap-hongkong.myqcloud.com/wp-content/uploads/pdf/%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E7%99%BD%E7%9A%AE%E4%B9%A6_v2.0.pdf
https://blog.csdn.net/cao812755156/article/details/89598410
https://www.tensorflow.org/federated/
https://github.com/WeBankFinTech/FATE
https://en.wikipedia.org/wiki/Federated_learning
https://blog.csdn.net/Mr_Zing/article/details/100051535
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




