计算机新硬件技术带来的变革与思考
译者:阿里巴巴资深数据库专家-叶正盛(斗佛)
随着3D XPoint、RDMA等技术的发展,计算机新硬件技术变革正在悄然进行,本文是翻译了2016年初the morning pager的一片文章(见底部原文链接 ),感受到作者对新技术发展变革的期待,也大胆猜测新硬件对软件架构的颠覆。以下是译文,翻译的比较初级,见谅:
当前网络、内存、存储和处理器的巨大变化将会引领我们数据中心的变革,对我们设计和构建分布式系统的方式及思维都会产生巨大的影响。今天我想花一点时间总结一下我们在过去几周和几个月里在这方面的研究进展并分析其影响。
首先,我们来看看数据中心新的硬件,然后我们将尝试搞清楚带来的意义。
网络
从10Gbs网络后,我们正在推出40Gbps和100Gbps以太网(100GbE),甚至有一个IEEE工作组在做400GbE的事情!这给数据中心带来了非常高的通信带宽。
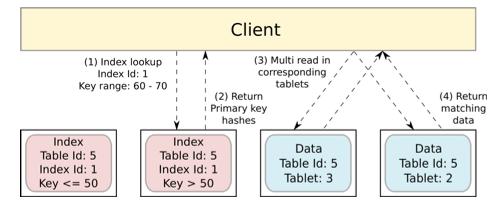
对于许多分布式应用程序,我们也非常关心延迟。本周早些时候,我们研究了正在设计超低延迟的RAMCloud项目。我们找到一个1GbE网络的评估数据,大约在2009年,大数据中心的往返RPC延迟大约在150-400μs。随着2014年普及的10GbE网络,这一数字下降到7-12μs,RAMCloud团队认为大型数据中心的网络往返延迟极限将在2.4μs左右。
除了带宽和延迟的改进之外,还有另一个非常重要的发展是CPU旁路,其中网卡(NIC)可以直接将数据传输到应用程序内存或从应用程序内存接收数据,不需要使用CPU(因此也不需要上下文切换) 。 RPC显然是需要应用服务器做一些工作,但通过CPU旁路直接读/写远程内存的往返可以1.4μs完成!
启用此功能的技术称为RDMA(远程直接内存访问)。 RDMA最初与InfiniBand相关,但是一个称为RoCE(RDMA Over Converged Ethernet)的研究可以支持通过以太网进行远程直接内存访问。 (还有iWARP也支持通过TCP / IP的RDMA,但不能达到相同的性能水平)。
RDMA有三种通讯方式,从最快到最慢的方式分别是:
RDMA(CPU旁路),提供读、写和两个原子操作(fetch_and_add和compare_and_swap)。
具有SEND / RECV的MPI接口
IP模拟模式,可以使用基于套接字的代码,不需要修改
RDMA可以给10GbE网络里RPC往返延时时间两个数量级改进,并大大减少CPU开销。
内存
内存有两个方向,两个都是NVRAM(非易失性RAM),也称为“存储类内存”(SCM)。
第一个方向是将现有的DRAM变为非易失性,然后我们就有了新一代的NVRAM。那么如何使现有的DRAM具备非易失性?如果发生掉电,您只需备份足够的备用电源即可将数据移动到非易失性存储(NAND Flash)上,这可以通过电池(电池备份,BBU)或超级电容器实现。
一个选择是将其封装在现有可插拔的DIMM内存条中,您只需将DRAM加上足够的闪存备份到同一个DIMM上即可。
数据中心内的另一个选择是将锂离子电池集成到机架中每个机箱的电源单元(PSU)中,这形成分布式UPS解决方案,在主电源故障的情况下将内存保存到SSD。该解决方案比NVDIMM更具成本效益,使用分布式UPS方案,做到非易失性的,与DRAM的基本成本相比,其成本大约增加15%。
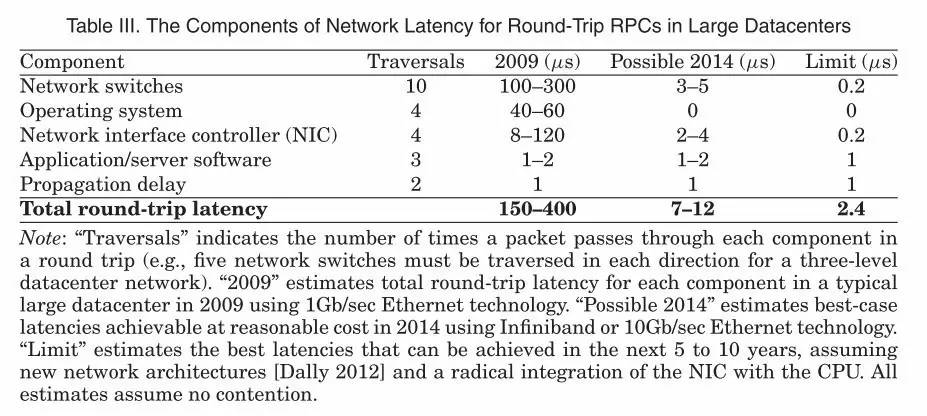
新一代NVRAM技术可用作内存,也可用作内置存储(甚至外部存储器)。下一节将介绍内置存储。这类技术很多正在开发中,包括3D XPoint、MRAM、MeRAM、Memristor、NRAM、STT-RAM、PCM、CBRAM、RRAM、Millipede和Racetrack (Better Memory,CACM Jan 2016)。例如,3D XPoint比NAND闪存(SSD)快1000倍,它不像闪存那样会有磨损(译注:这里可能不对,3D XPoint也有磨损问题,只是耐磨性高1000倍),比传统的内存密度要高10倍。与DRAM相比,它更便宜且有更高的容量,但是会更慢(确切地说,也很难说有多慢,从某些地方看他会介于慢10倍到接近DRAM性能之间)。其他新的NVRAM技术,如忆阻器和MeRAM也具有10-1000倍的能源效率提升。当3D XPoint在DIMM中用作主内存时,目前的推测是,两颗Xeon服务器将能够以大约DRAM一半的成本来寻址高达6TB的持久化内存。
下面这张图来自英特尔(来源:Tom's Hardware),很好地说明了内存和存储能力的层次关系。
存储
NVRAM技术同样也可以用作内置存储或二级存储。
PCI Express(PCIe)接口意味着对I/O设备可以做到高带宽和低延迟访问。 当前PCIe 3.0可以支持16通道插槽,16GB/s传输速率。 即将推出的PCIe 4.0标准将在16通道插槽中提供高达32GB/s的带宽,目前传闻是在2017年可以拿到。
NVMe(NVM Express)是通过PCIe总线访问非易失性存储器的规范。 您可以把它应用到NAND闪存,或新一代快1000倍的NVM,它的设计是考虑到未来技术发展。 NVMe设备可以支持数十万到数百万的IOPS
以下是英特尔分别用NVMe与SAS/SATA接口,3D XPoint和NAND 闪存的对比:
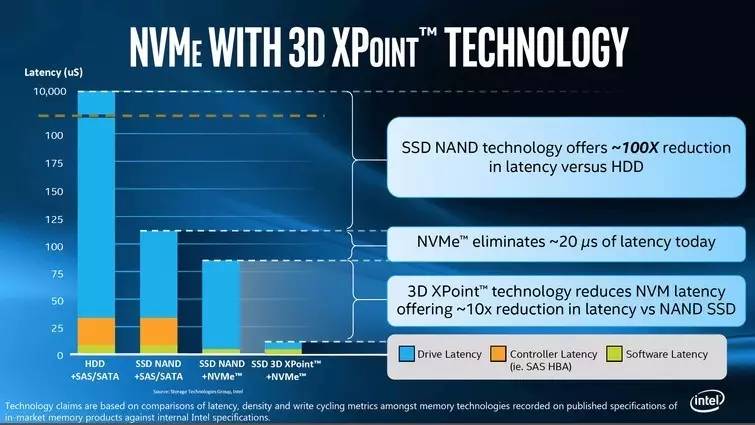
我们可以进一步将NVMe与RDMA结合在一起,叫“NVMe over Fabrics”,从而允许客户端直接访问远程NVRAM,减少延迟和减少CPU开销。与NVMe在PCIe相比,NVMe在RDMA上的吞吐量没有下降,延迟增长也不大(一个测试,4K随机读/写从11/12μs增加到18 /9μs)。
处理器
我们已经习惯称为GPU和CPU。今年,英特尔将使用集成的现场可编程门阵列(FPGA)到Xeon芯片。 FPGA可以高效的加速机器学习和数据分析等任务。FPGA可以通过PCIe连接到处理器,将其放在双芯片封装上,意味着CPU和FPGA可以通过英特尔的QPI互连进行通讯,甚至允许直接访问Xeon片上缓存和主内存,从而减少延时。这些将在AWS EC2上上线,比如“C4”规格的实例。
接下来,我想强调硬件事务内存(HTM)指令支持,可用于Haswell作为“事务同步扩展”的x86指令集体系结构。它具有两种方式,即向后兼容的Hardware Lock Elison(HLE)指令集和更灵活的前瞻性限制性事务内存(RTM)指令集。
最后,正如我们昨天看到的那样,新的持久性内存支持正在使更多的数据从易失性缓存刷新到持久存储器。
需要知道的新数字
这个在不久的将来在数据中心看来是可以实现的。我研究的越多,所有各种报告(特别是与3D XPoint相关)似乎越来越混乱,其中许多报告似乎与之相冲突。这些是我最好的预估,来源在下面的备注中。表中的“NVRAM”表示3D XPoint所代表的下一代NVRAM。 SSD表示NAND闪存。我非常感谢那些更关注硬件开发的人来更正!记住,NVRAM刚刚处于开始发展阶段,所以我们应该期望它能够快速的发展。

备注(上表数字对应的备注)
假设为4GHz Skylake CPU
英特尔至强E7
3D XPoint将具有8-10倍的DRAM密度,但只有4倍的容量。 NVDIMM DDR4格式的初始版本将在双插槽机器中支持高达6TB的内存(这是每个插槽的E7线的两倍)。我猜测,4倍的容量会存在比较久。延迟数假设为10x DRAM(其他报告有说是2.5x - 来自英特尔!)。带宽是DRAM的60%。
大型数据中心的极限可能性,来自RAMCloud论文。
延时数据来自英特尔NVMe与3D XPoint技术图表(通过汤姆的硬件)。容量与NAND闪存相同(见(8))。初始发布3D XPoint SSD的带宽为6GB,PCIe 3 x16理论上可达16GB。IOPS数据是通过SSD DDC P3700 x5计算,这是我基于英特尔IDF数字的猜测。
Microsemi闪存峰会演示。 NVMf的带宽将被网络限制,而不是PCIe3 x16,大约为12GB(初始版本为6GB)。 IOPS被网络绑定吗?
带宽和IOPS来自英特尔SSD DC P3608
三星去年推出了16TB SSD,我认为SSD的容量会很快达到这个大小。
我通过向NVMe 数据添加额外的10μs延迟来得出这个延迟数据。
来自英特尔NVMe的延迟与3D XPoint技术图表(通过汤姆的硬件)。维基百科的IOPS(SSD在~1000x HDD)。带宽档位在~1.5Gbs。(译注:HDD的带宽应该没有1.5GB/s,目前比较高的应该小于300MB/s,容量反而有32TB)
当然,您可以将多个磁盘放到存储阵列中,以增加容量和IOPS ...
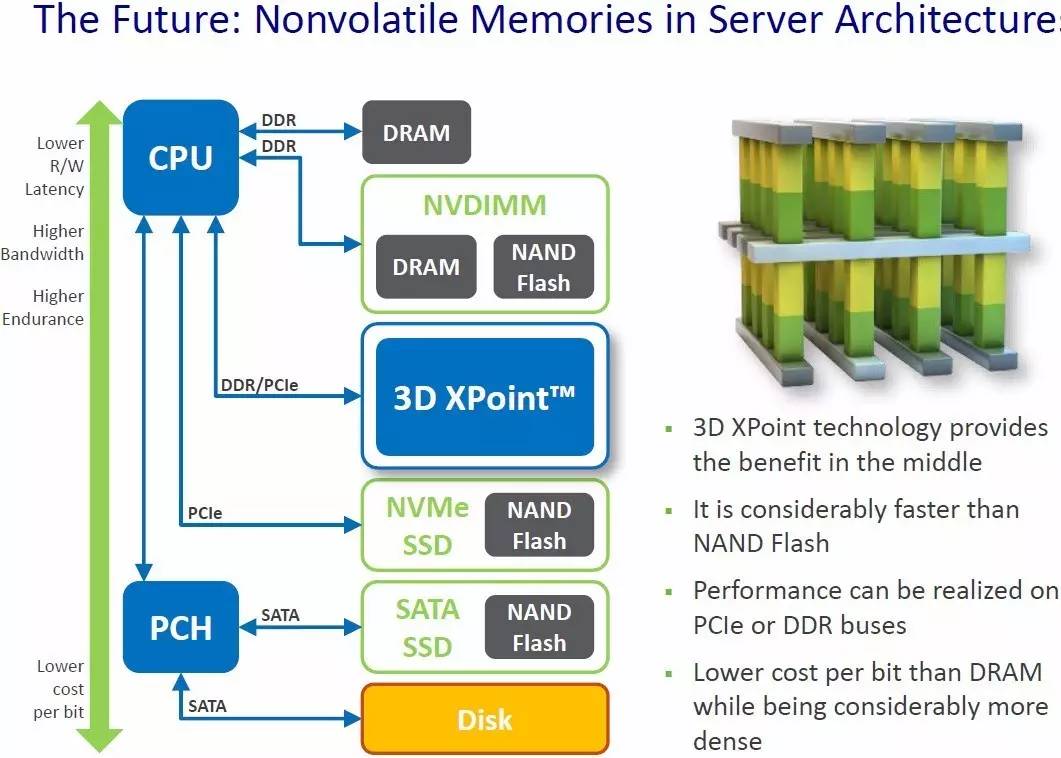
以下是非易失性存储器在服务器体系架构(来自KitGuru)的示意图:
分布式系统和数据存储的启发
以下是一个形象的类比,用人工作中的场景来类比计算机各个组件的性能。
回想起数字计算机之前的时候,那时计算还是人类做的工作。考虑这样的计算人员(可以说是人肉计算机)坐在他们的桌子前做计算。他们桌上的任何文件(正好在他们面前或在面前的一堆文档中)平均可以在大约10秒内被获取到。 (在这个类比中,桌面上的文件相当于通过L3缓存到寄存器中的数据)。
如果在桌上没有计算人员他们需要的文件,那么要获取文件,最好的结果就是可以从他们所在办公室的一个文件柜中找到。从文件柜获取效率也非常高,人们大概花1分钟就可以检索到本地文件柜中的任何文件。 (这相当于计算机从内存中取出数据)。
如果文件没有在文件柜内,那么需要从仓库中检索。一趟仓库回来约116天。更糟糕的是,一些客户在把文件安全地存储在仓库中之前没有考虑过会来提取,所以不得不等待116天的确认。这些计算人员会尽可能高效地完成从仓库提取文件,但在不是必须的情况下,但他们会愿意更多做本地计算,因为这可以减少仓库行程。(从仓库中获取文件,这相当于计算机从磁盘读取数据)
以下是几个方式花费时间的数据:
文件在桌子上(CPU L3缓存):10s
文件在本地文件柜(内存):1分钟
文件在仓库(磁盘):116天
这是世界上第一代设计的数据库系统。
随着新一代“内存”技术的发展:更智能的文件柜可以存储四倍的信息,并且仍然让计算人员在2-10分钟内获得所需的内容。更好的是,这些改进的文件柜是防火的,所以现在客户一旦成果放到本地办公室的文件柜中,就被认为是可以安全地完成提取。 2分钟vs 116天是他们的业务变革。这对您办公室的生产力产生了巨大的影响。
新一代仓库更有影响力:SSD仓库将文件检索时间从116天缩短到约30小时,新的NVMe 3D XPoint仓库进一步减少到约3.3小时。为了充分发挥所有这些先进的技术发展,利用新的仓库充分发挥作用,我们必须聘请更多的计算人员。
办公室也安装了电话,以便他们可以互相交谈。这样,如果只是从远程办公室简单的获取一个文件,大约23分钟之内可以搞定,如果还需要远程办公室做更多的一些处理,大约需要40分钟。
当你想要的文件不超过3.3小时,与116天对比,要平衡资源和相关工作,肯定也会不一样。
文件在桌子上(CPU L3缓存) 10秒钟
本地文件柜(内存)1分钟
打电话另一个办公室(RDMA)23-40分钟
仓库(NVMe)3小时20分钟
(在这个规模上,基于SSD的仓库大约需要30个小时)。
研究成果
所有这些变化的组合,产生了许多有趣的新系统。大型数据中心中的10,000个节点的集群可能具有大约100PB的持久内存数据。当使用RDMA时,RAMCloud Key-Value存储显示读取延迟为5μs,写入延迟为13.5μs。使用其Reusable Infrastructure for Linearizability,RAMCloud团队在RAMCloud之上构建了一个多实体分布式事务机制,约27μs完成了5个对象的事务,简单的分布式事务执行约20μs。在这个非常低的延迟下,RAMCloud在10节点集群中的TPC-C基准测试中每分钟约有2M个事务(33Ktps)。
FaRM利用持久性内存和RDMA,并在90个节点集群的TPC-C基准测试中做到了4.5M tps,99%的延迟小于1.9ms。 FaRM Key-Value存储每台机器每秒钟执行630万次操作,峰值吞吐量的延迟为41μs。
面前的一个问题是掌握何时使用RDMA,何时使用RPC。在延迟方面,如果您需要两个或多个RDMA请求,则换成一次RPC调用会更快。但RDMA可以绕过远程CPU,而RPC不能。
DrTm系统支持结合HTM和RDMA的分布式事务。在6节点集群中,DrTM在TPC-C基准测试中实现了5.5M tps。当然,如果您的内存不会丢失,内存中的事务会更有意思。
正如“From ARIES to MARS”作者所声称的,新一代快速NVM与长顺序读取设计比较,当快速随机访问是完全可以接受的时候,给出了一个很好的重新思考事物和恢复协议的例子 。比如,update-in-place会取代 append-only技术吗?海量持久性内存会改变持久化格式吗?
昨天在Blurred Persistence中,我们了解到CPU缓存和主内存之间的易失性/稳定存储边界的新影响(当L3缓存可以容纳40 + MB数据时,这仍然是大量易失性数据),新的指令可以帮助我们管理这个。
在非易失性存储中,我们了解到需要重新平衡系统,确保足够的处理能力可以用完全发挥的存储级内存设备。
当然,成本还将是一个很大的因素,我们需要对5分钟规则进行一些更新,以考虑新一代NVRAM比DRAM便宜,但比NAND更昂贵。由于一些新一代NVRAM的能源效率更高,所以功耗也将降低成本。
大多数这些研究项目结合了一个或两个新的发展。当快速RDMA网络与足够的持久性内存,硬件事务,增强的缓存管理支持和超快速存储阵列相结合时,会发生什么?这是一整套设计权衡,将影响操作系统,文件系统,数据存储,流处理,图形处理,深度学习等。此前,我们甚至引入了与板载FPGA的集成,以及GPU的发展...
从开发人员的角度来看,我希望为今天的许多场景提供更简单、更安全的编程模型(例如分布式事务的返回)。但是,您可以确定,随着所有这些新的能力的出现,将出现一整套新的场景,以继续推动可能的边界。