点击上方,选择星标或置顶,每天给你送干货![]() !
!
阅读大概需要20分钟![]()
跟随小博主,每天进步一丢丢![]()
![]()
作者 | Michael Galkin
编辑 | 晓凡,Camel
本文来自德国Fraunhofer协会IAIS研究所的研究科学家Michael Galkin,他的研究课题主要是把知识图结合到对话AI中。
必须承认,图的机器学习(Machine Learning on Graphs)已经成为各大AI顶会的热门话题,NeurIPS 当然也不会例外。
在NeurIPS 2019上,仅主会场就有 100多个与图相关的论文;
另外,至少有三个workshop的主题与图有关:
-
Graph Representation Learning (大约有100多篇论文);
-
Knowledge Representation & Reasoning Meets Machine Learning (KR2ML)(也有50篇吧);
-
我们希望在接下来的这篇文章里,能够尽可能完整地讨论基于图的机器学习的研究趋势,当然显然不会包括所有。
目录如下:
-
Hyperbolic Graph Embeddings 双曲图嵌入
-
Logics & Knowledge Graph Embeddings 逻辑和知识图嵌入
-
Markov Logic Networks Strike Back 马尔科夫逻辑网络卷土重来
-
Conversational AI & Graphs 对话 AI 和图
-
Pre-training and Understanding Graph Neural Nets 图神经网络的预训练和理解
-
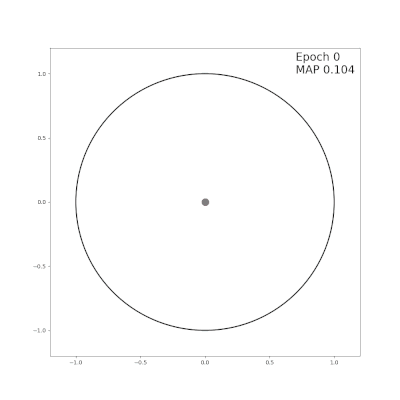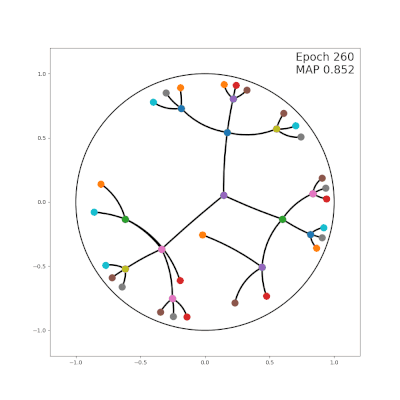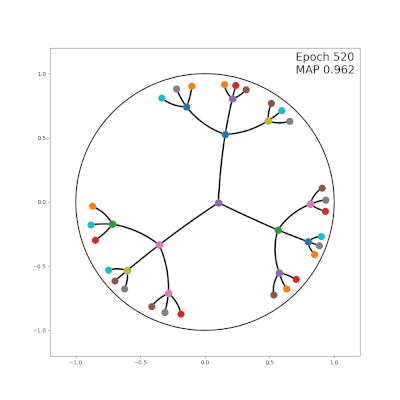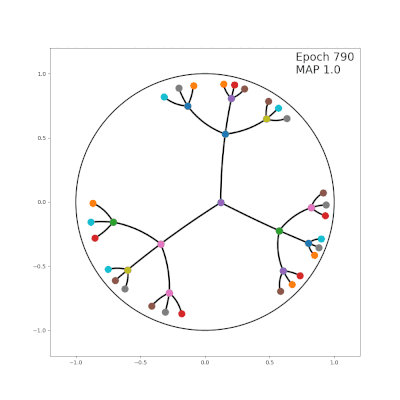
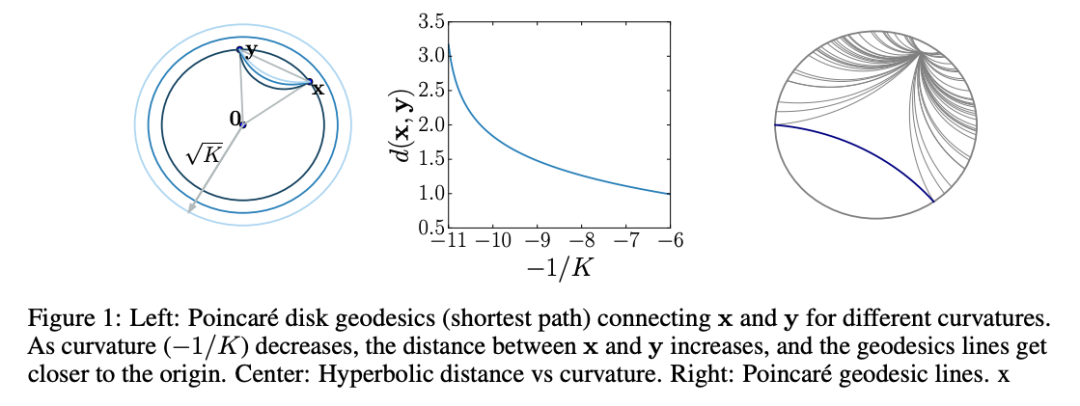
传统的嵌入算法都是在“平坦”的欧氏空间中学习嵌入向量,为了让向量有更高的表示能力,就会选择尽量高的维数(50维到200维),向量之间的距离也是根据欧氏几何来计算。
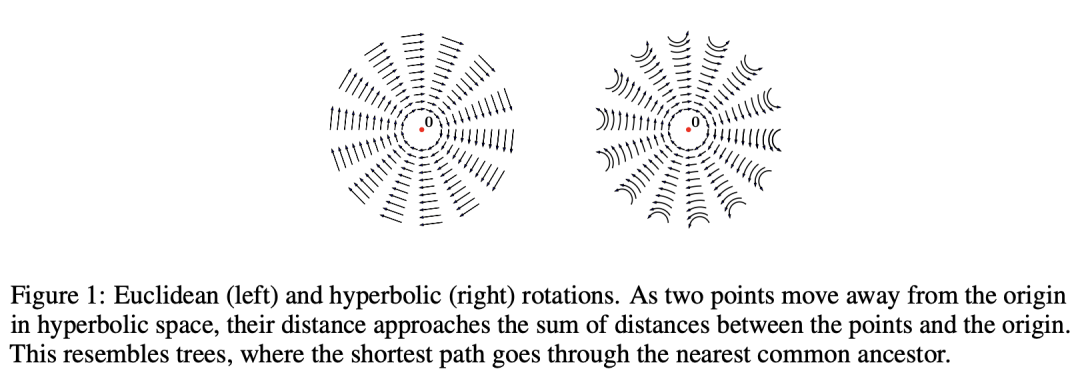
相比之下,双曲算法中用到的是庞加莱(Poincare)球面和双曲空间。
在嵌入向量的使用场景里,可以把庞加莱球面看作一个连续的树结构,树的根节点在球的中心,枝干和叶子更靠近球面一些(如上面的动图)。
这样一来,双曲嵌入表征层级结构的能力就要比欧氏空间嵌入的能力高得多,同时需要的维数却更少。
不过,双曲网络的训练和优化依然是相当难的。
NeurIPS2018中有几篇论文对双曲神经网络的构建做了深入的理论分析,今年在NeurIPS2019上我们终于看到了双曲几何和图结构结合的应用。
论文 1:
Hyperbolic Graph Convolutional Neural Networks
论文地址:https://papers.nips.cc/paper/8733-hyperbolic-graph-convolutional-neural-networks.pdf
开源地址:
https://github.com/HazyResearch/hgcn
论文 2:
Hyperbolic Graph Neural Networks
论文地址:
https://papers.nips.cc/paper/9033-hyperbolic-graph-neural-networks.pdf
开源:
https://github.com/facebookresearch/hgnn
论文 1 和论文 2 两者的思想是相似的,都希望把双曲空间的好处和图神经网络的表达能力结合起来,只不过具体的模型设计有所区别。
前一篇论文主要研究了节点分类和连接预测任务,相比于欧氏空间中的方法大大降低了错误率,在Gromov双曲性分数较低(图和树结构的相似度)的数据集上表现尤其好。
后一篇论文关注的重点是图分类任务。
论文 3:
Multi-relational Poincaré Graph Embeddings
论文地址:
https://papers.nips.cc/paper/8696-multi-relational-poincare-graph-embeddings.pdf
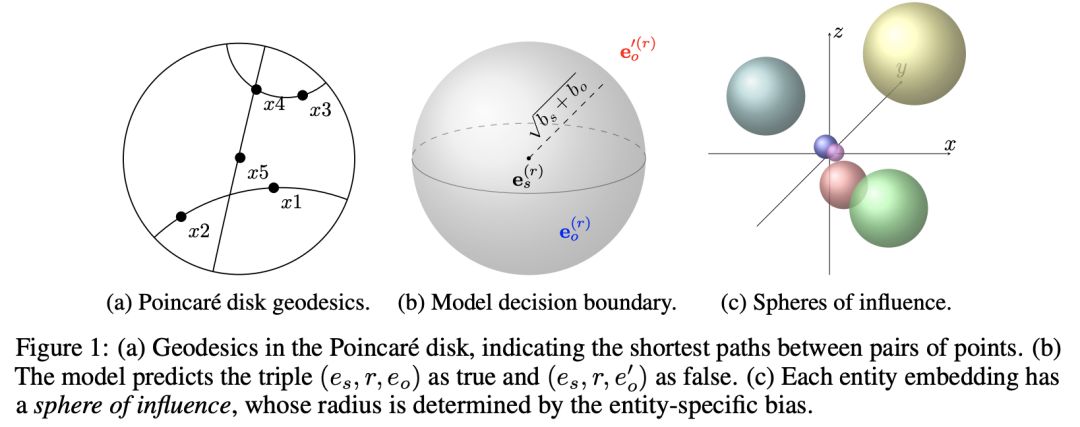
论文 3 在它们的多关系庞加莱模型(MuRP)的知识图嵌入中用上了双曲几何。
直觉上,正确的三元组客体应该落在主体附近的某个超球面中,相关的这些决策边界是由学习到的参数描绘的。
作者用来优化模型的是黎曼几何SGD(大量数学警告)。
在两个标准的评测数据集 WN18RR 和 FB15k-237 上,MuRP 的效果比对比模型更好,因为它“更具备双曲几何”而且也更适用于树结构(如果能像上面的论文一样计算一下Gromov双曲性分数就更好了)。
更有趣的是,MuRP只需要40维,得到的准确率就和欧氏空间模型用100维甚至200维向量的结果差不多!
明显可以看到,双曲空间的模型可以节省空间维度和存储容量,同时还不需要有任何精度的牺牲。
我们还有一个双曲知识图嵌入比赛,获奖方法名为 RotationH,论文见
https://grlearning.github.io/papers/101.pdf
,其实和上面的双曲图卷积神经网络论文的作者是同一个人。
这个模型使用了双曲空间的旋转(思路上和RotatE
https://arxiv.org/abs/1902.10197
模型相似,不过RotatE是复数空间的模型),也使用了可学习的曲率。
RotationH 在WN18RR上刷新了最好成绩,而且在低维的设定下也有很好的表现,比如,32维的RotationH就能得到和500维RotatE差不多的表现。
如果你碰巧在大学学习了sinh(双曲正弦)、庞加莱球面、洛伦兹双曲面之类的高等几何知识但是从来都不知道在哪能用上的话,你的机会来了,做双曲几何+图神经网络吧。
如果你平时就有关注arXiv或者AI会议论文的话,你肯定已经发现,每年都会有一些越来越复杂的知识图嵌入模型,每次都会把最佳表现的记录刷新那么一点点。
那么,知识图的表达能力有没有理论上限呢,或者有没有人研究过模型本身能对哪些建模、对哪些不能建模呢?
看到这篇文章的你可太幸运了,下面这些答案送给你。
论文4:
Group Representation Theory for Knowledge Graph Embedding
链接:
https://grlearning.github.io/papers/15.pdf
论文 4 从群论的角度来研究KG嵌入。
结果表明,在复空间中可以对阿贝尔群进行建模,且证明了RotatE(在复空间中进行旋转)可以表示任何有限阿贝尔群。
有没有被“群论”、“阿贝尔群”这些数学名词吓到?
不过没关系,这篇文章里有对相关的群论知识做简要介绍。
不过这个工作在如何将这个工作拓展到1-N或N-N的关系上,还有很大的gap。
作者提出一个假设,即或许我们可以用四元数域H来代替复数空间C……
论文5:
Quaternion Knowledge Graph Embeddings
链接:
https://papers.nips.cc/paper/8541-quaternion-knowledge-graph-embeddings.pdf
……在这次NeurIPS' 19上,这个问题被 Zhang et al. 解决了。
他们提出了QuatE,一个四元数KG嵌入模型。
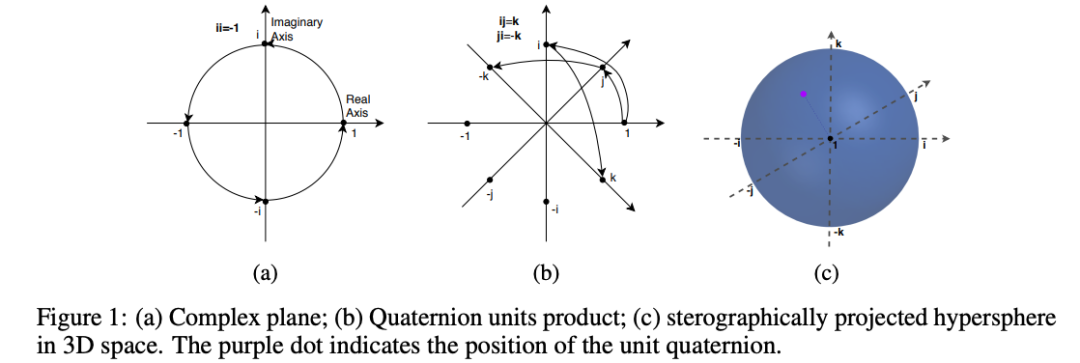
什么是四元数?
这个需要说清楚。
简单来说,复数有一个实部,一个虚部,例如a+ib;
而四元数,有三个虚部,例如 a+ib+jc+kd。
相比复数会多出两个自由度,且在计算上更为稳定。
QuatE将关系建模为4维空间(hypercomplex space)上的旋转,从而将complEx 和 RotatE统一起来。
在RotatE中,你有一个旋转平面;
而在QuatE中,你会有两个。
此外,对称、反对称和逆的功能都保留了下来。
与RotatE相比,QuatE在 FB15k-237上训练所需的自由参数减少了 80%。
我上面并没有从群的角度来分析这篇文章,不过若感兴趣,你可以尝试去读原文:
![]() 四元数域的旋转
四元数域的旋转
论文 6:
Quantum Embedding of Knowledge for Reasoning
链接:
https://papers.nips.cc/paper/8797-quantum-embedding-of-knowledge-for-reasoning.pdf
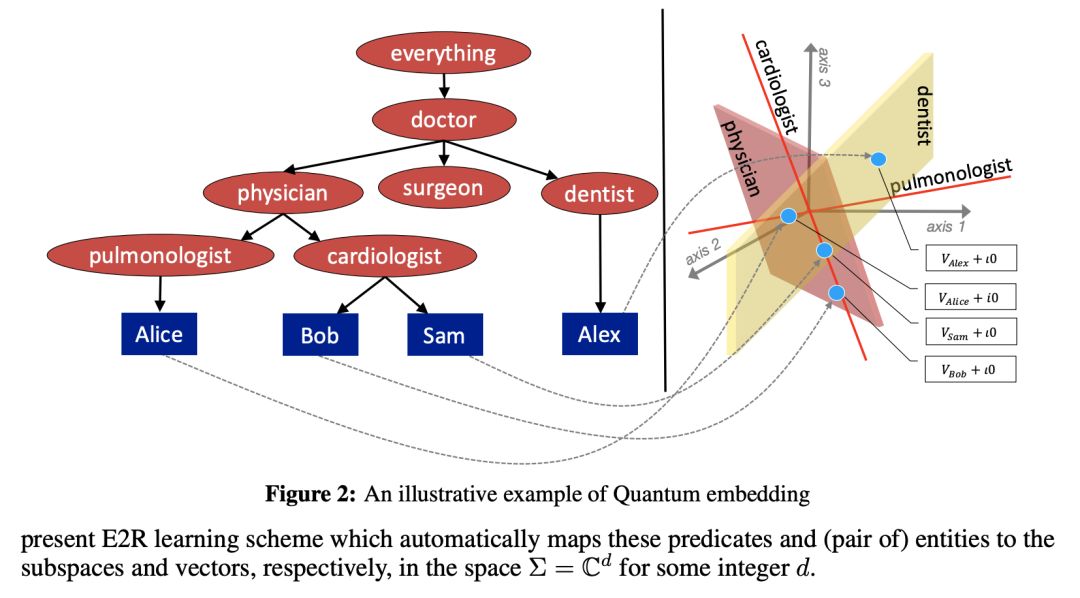
论文 6 提出了 Embed2Reason(E2R)的模型,这是一种受量子逻辑启发的量子KG嵌入方法。
该方法可以嵌入类(概念)、关系和实例。
不要激动,这里面没有量子计算。
量子逻辑理论(QL)最初是由伯克霍夫和冯诺依曼于1936年提出,用于描述亚原子过程。
E2R的作者把它借用过来保存KG的逻辑结构。
在QL中(因此也是E2R中),所有一元、二元以及复合谓词实际上都是某些复杂向量空间的子空间,因此,实体及其按某种关系的组合都落在了特定的子空间内。
本来,分布定律a AND(b OR c)=(a AND b)OR(a AND c)在QL中是不起作用的。
但作者用了一个巧妙的技巧绕开了这个问题。
作者在论文中还介绍了如何使用QL对来自描述逻辑(DL)的术语(例如包含、否定和量词)进行建模!
实验结果非常有趣:
在FB15K上,E2R产生的Hits @ 1高达96.4%(因此H@10也能达到);
不过在WN18上效果不佳。
事实证明,E2R会将正确的事实排在首位或排在top10以下,这就是为什么在所有实验中H @ 1等于H @ 10的原因。
补充一点,作者使用LUBM作为演绎推理的基准,该演绎推理包含了具有类及其层次结构的本体。
实际上,这也是我关注的焦点之一,因为标准基准数据集FB15K(-237)和WN18(RR)仅包含实例和关系,而没有任何类归因。
显然,大型知识图谱具有数千种类型,处理该信息可以潜在地改善链接预测和推理性能。
我还是很高兴看到有越来越多的方法(如E2R)提倡将符号信息包含在嵌入中。
论文 7:
Logical Expressiveness of Graph Neural Networks
链接:
https://grlearning.github.io/papers/92.pdf
论文 7 中对哪些GNN架构能够捕获哪个逻辑级别进行了大量的研究。
目前为止,这个研究还仅限于一阶逻辑的两变量片段FOC_2,因为FOC_2连接到用于检查图同构的Weisfeiler-Lehman(WL)测试上。
作者证明,聚合组合神经网络(AC-GNN)的表达方式对应于描述逻辑ALCQ,它是FOC_2的子集。
作者还进一步证明,如果我们添加一个独处成分,将GNN转换为聚合组合读出GNN(ACR-GNN),则FOC_2中的每个公式都可以由ACR-GNN分类器捕获。
论文 8:
Embedding Symbolic Knowledge into Deep Networks
链接:
https://papers.nips.cc/paper/8676-embedding-symbolic-knowledge-into-deep-networks.pdf
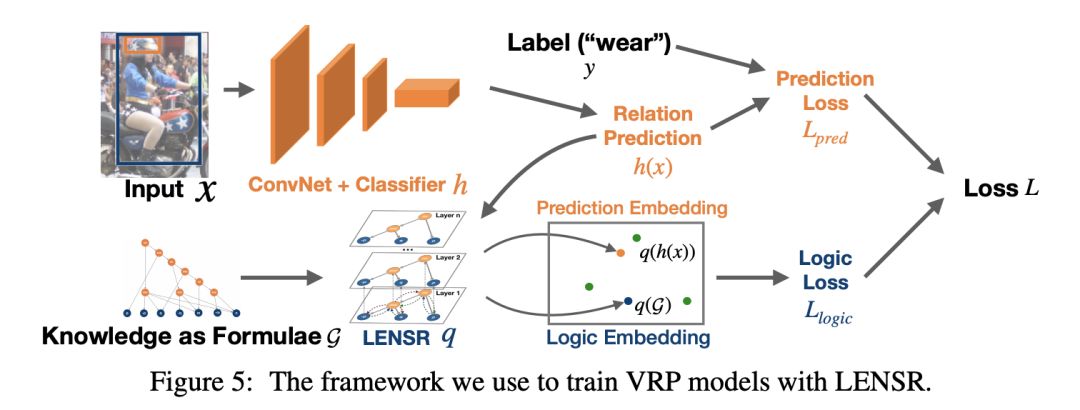
论文 8 提出了模型LENSR,这是一个具有语义正则化的逻辑嵌入网络,它可以通过图卷积网(GCN)将逻辑规则嵌入到d-DNNF(决策确定性否定范式)当中。
在这篇文章中,作者专注于命题逻辑(与上述论文中更具表现力的描述逻辑相反),并且表明将AND和OR的两个正则化组件添加到损失函数就足够了,而不用嵌入此类规则。
这个框架可以应用在视觉关系预测任务中,当给定一张图片,你需要去预测两个objects之间的正确关系。
在这篇文章中,Top-5的精确性直接将原有84.3#的SOTA提升到92.77%。
![]() Source: Xie et al
Source: Xie et al
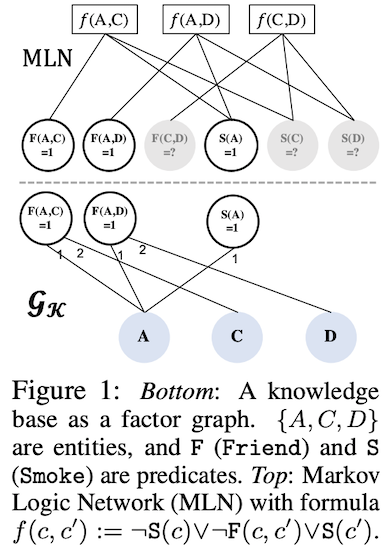
马尔科夫逻辑网络(Markov Logic Network)的目标是把一阶逻辑规则和概率图模型结合起来。
然而,直接使用马尔科夫逻辑网络不仅有拓展性问题,推理过程的计算复杂度也过高。
近几年来,用神经网络改进马尔科夫逻辑网络的做法越来越多,今年我们能看到很多有潜力的网络架构,它们把符号规则和概率模型结合到了一起。
论文9:
Probabilistic Logic Neural Networks for Reasoning
链接:
https://papers.nips.cc/paper/8987-probabilistic-logic-neural-networks-for-reasoning.pdf
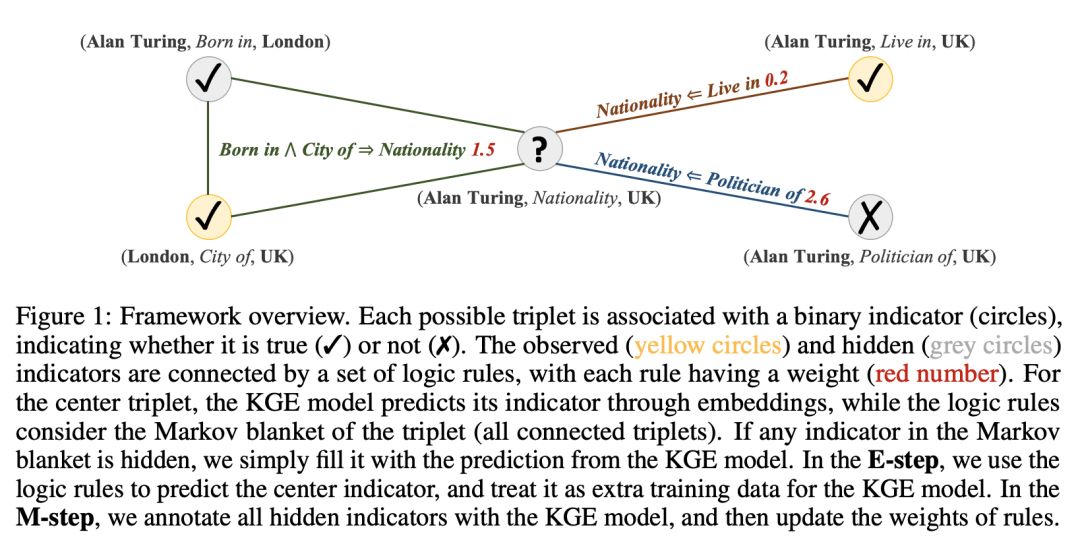
论文 9 提出了 pLogicNet,这个模型是用来做知识图推理的,而且知识图嵌入和逻辑规则相结合。
模型通过变差EM算法训练(实际上,这几年用EM做训练&模型优化的论文也有增加的趋势,这事可以之后单独开一篇文章细说)。
论文的重点是,用一个马尔科夫逻辑网络定义知识图中的三元组上的联合分布(当然了,这种做法要对未观察到的三元组做一些限制,因为枚举出所有实体和关系上的所有三元组是做不到的),并给逻辑规则设定一个权重;
你可以再自己选择一个预训练知识图嵌入(可以选TransE或者ComplEx,实际上随便选一个都行)。
在推理步骤中只能怪,模型会根据规则和知识图嵌入找到缺失的三元组,然后在学习步骤中,规则的权重会根据已见到的、已推理的三元组进行更新。
pLogicNet 在标准的连接预测测试中展现出了强有力的表现。
我很好奇如果你在模型里选用了 GNN 之类的很厉害的知识图嵌入会发生什么。
论文 10:
Neural Markov Logic Networks
链接:
https://kr2ml.github.io/2019/papers/KR2ML_2019_paper_18.pdf
论文 10 介绍了一个神经马尔科夫逻辑网络的超类,它不需要显式的一阶逻辑规则,但它带有一个神经势能函数,可以在向量空间中编码固有的规则。
作者还用最大最小熵方法来优化模型,这招很聪明(但是很少见到有人用)。
但缺点就是拓展性不好,作者只在很小的数据集上做了实验,然后他表示后续研究要解决的一大挑战就是拓展性问题。
论文11:
Can Graph Neural Networks Help Logic Reasoning?
链接:
https://kr2ml.github.io/2019/papers/KR2ML_2019_paper_22.pdf
最后,论文 11 研究了GNN和马尔科夫逻辑网络在逻辑推理、概率推理方面的表现孰强孰弱。
作者们的分析表明,原始的GNN嵌入就有能力编码知识图中的隐含信息,但是无法建模谓词之间的依赖关系,也就是无法处理马尔科夫逻辑网络的后向参数化。
为了解决这个问题,作者们设计了ExpressGNN架构,其中有额外的几层可调节的嵌入,作用是对知识图中的实体做层次化的编码。
好了,硬核的机器学习算法讲得差不多了,下面我们看点轻松的,比如NLP应用。
和NeurIPS正会一起开的workshop里有很多有趣的对话AI+图的论文。
论文12:
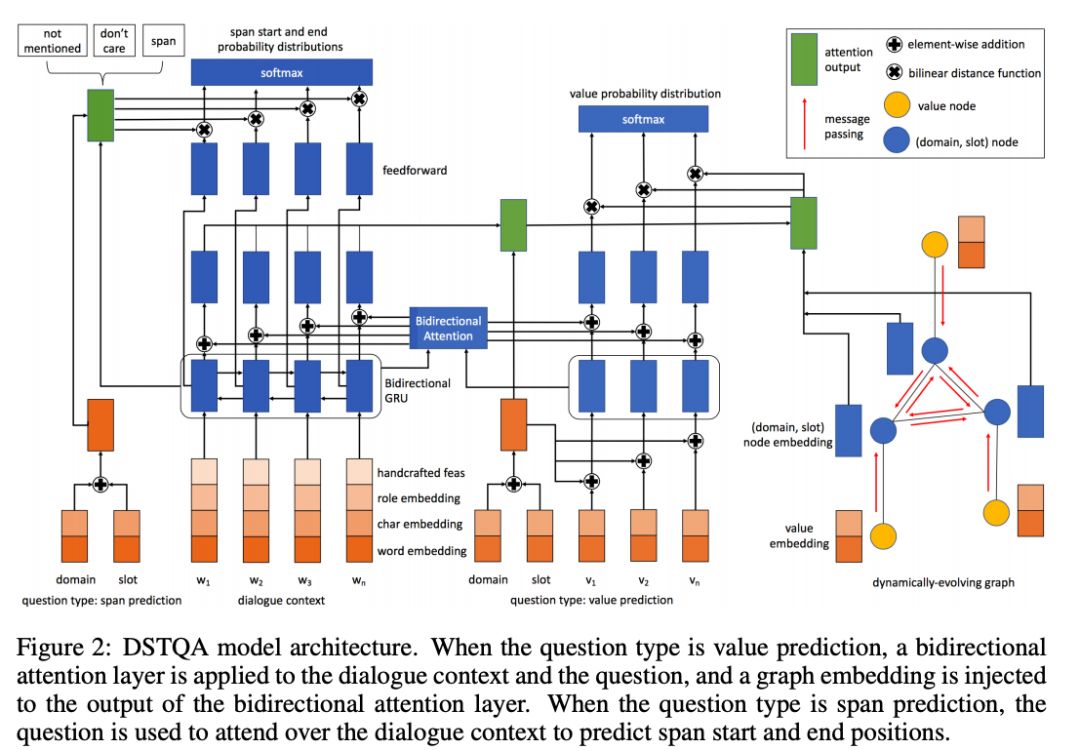
Multi-domain Dialogue State Tracking as Dynamic Knowledge Graph Enhanced Question Answering
链接:
http://alborz-geramifard.com/workshops/neurips19-Conversational-AI/Papers/51.pdf
这篇论文提出了一个通过问答追踪对话进度(Dialogue State Tracking via Question Answering (DSTQA))的模型,用来在MultiWOZ环境中实现任务导向的对话系统,更具体地,就是通过对话帮助用户完成某个任务,任务一共分为5个大类、30个模版和超过4500个值。
它基于的是问答(Question Answering )这个大的框架,系统问的每个问题都要先有一个预设模版和一组预设的值,用户通过回答问题确认或者更改模版中的预设值。
有个相关的假说提出,同一段对话中的多个模版、多组值之间并不是完全独立的,比如,你刚刚订好五星级酒店的房间,然后你紧接着问附近有什么餐馆,那很有可能你想找的餐馆也是中高档的。
论文中设计的整个架构流程很繁琐,我们就只讲讲他们的核心创新点吧:
-
首先,作者们把对话状态建模为一个根据对话内容逐渐扩充的动态知识图。
图中的节点由大类、模版和值构成,建立节点之间关系的过程也利用了上面那个假说,就是因为不同的模版之间有一些值可以是相同的、部分重叠或者是有关联的。
-
其次,用一个图注意力网络(Graph Attention Net)学习为图中的节点分配权重,网络的输出也会被送入一个门机制,用来决定要在问题文本中表现出图的多大的一部分。
-
作者们也使用了角色嵌入,这样模型可以由系统的话语和用户的话语共同训练
-
最后,作者们同时使用了CharCNN和ELMO嵌入来做对话文本内容的编码
DSTQA 在 MultiWOZ 2.0 和 MultiWOZ 2.0 上都刷新了最好成绩,在 WOZ 2.0 上也和当前的最好方法不相上下。
根据作者们的误差分析,主要的丢分点来自于真实值的标注有一些不准确的 —— 大规模众包数据集中就是经常会发生这种情况,没什么办法,摊手
论文 13:
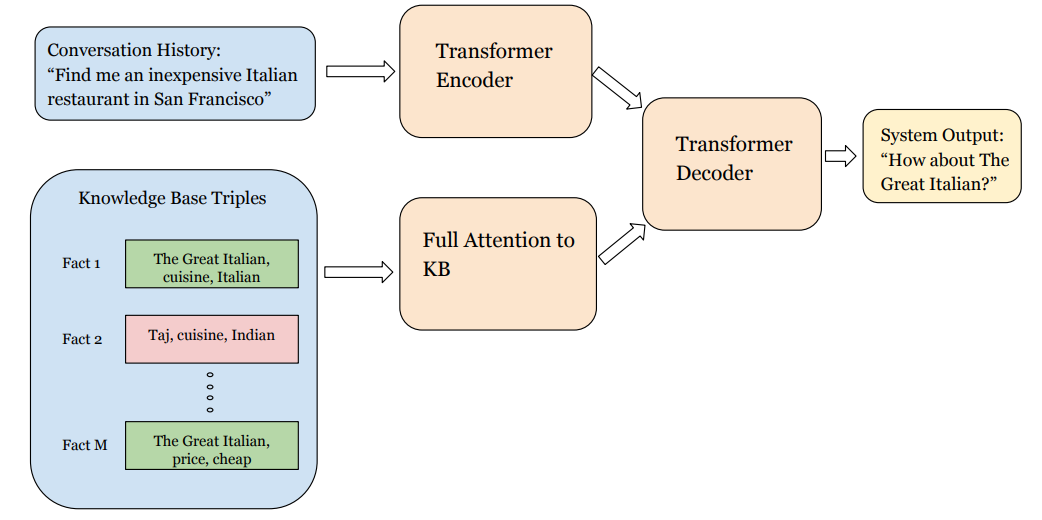
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
链接:
http://alborz-geramifard.com/workshops/neurips19-Conversational-AI/Papers/32.pdf
论文13 介绍了一个神经网络助理模型,这个对话系统架构不仅能考虑到对话历史,也能利用到知识库中的事实信息。
系统架构可以看作是Transformer架构的拓展,它会编码对话历史中的文本;
知识库中的内容是简单的单词三元组比如(餐馆A,价格,便宜)(没有 Wikidata 那种花哨的知识图模式),这些三元组也会被Transformer编码。
最后,解码器会同时处理历史文本编码和知识图编码,用来生成输出语句,以及决定是否要进行下一步动作。
之前的论文中有很多人在所有的知识库三元组上计算softmax(只要知识库稍微大一点,这种做法就非常低效),这篇论文就没这么做,他们根据知识库中的实体是否在真实值回答中出现的情况做弱监督学习。
他们的架构在 MultiWOZ 设置下比原本的Transformer架构得到更好的表现,预测动作以及实体出现的F1分数超过90%。
不过,他们的进一步分析显示出,知识库中的条目超过一万条之后准确率就会开始快速下降。
所以,嗯,如果你有心思把整个Wikidata的70亿条三元组都搬过来的话,目前还是不行的。
论文 14:
A Comprehensive Exploration on WikiSQL with Table-Aware Word Contextualization
链接:
https://kr2ml.github.io/2019/papers/KR2ML_2019_paper_8.pdf
当你设计面向任务的系统的时候,往往有很多内容是无法长期留在内存里的,你需要把它们存在外部存储中,然后需要的时候去检索。
如果是图数据,你可以用SPARQL或者Cypher建立图数据库来操作;
或者用经典的SQL数据库也行。
对于后一种情况,最近出现了很多新任务(
https://medium.com/@mgalkin/knowledge-graphs-nlp-emnlp-2019-part-i-e4e69fd7957c
),其中WikiSQL 是第一批引起了学术研究人员兴趣的。
如今,只经过了不到两年的时间,我们就已经可以说这个数据集已经基本被解决了,基于神经网络的方法也获得了超过人类的表现。
这篇论文中提出了语义解析模型 SQLova ,它通过BERT编码问题和表头、用基于注意力的编码器生成SQL查询(比如 SELECT 命令、WHERE 条件、聚合函数等等) 、然后还能对生成的查询语句进行排序和评价。
作者们在论文中指出,不使用语义解析、只使用BERT的暴力编码的话,效果要差得多,所以语言模型还是不能乱用。
模型的测试准确率达到了90%(顺便说一句,还有一个叫 X-SQL 的模型拿到了接近92%的准确率,
https://arxiv.org/pdf/1908.08113.pdf
),而人类的准确率只有88%;
根据错误分析来看,系统表现的最大瓶颈基本就是数据标注错误了(和上面那个MulitWOZ的例子类似)。
-
Relational Graph Representation Learning for Open-Domain Question Answering
-
-
https://grlearning.github.io/papers/123.pdf
-
这篇论文提出了一个带有注意力的关系GNN,能够解决基于普通文本的以及把WebQuestionsSP外挂数据集作为知识图的问答任务。
-
Populating Web Scale Knowledge Graphs using Distantly Supervised Relation Extraction and Validation
-
通过远距离有监督关系提取和验证,制作大规模网络知识图
-
https://kr2ml.github.io/2019/papers/KR2ML_2019_paper_11.pdf
-
这篇论文解决了如何同时提取文本中的关系并立即通过预训练的知识图嵌入对候选的知识图做实事检查。
这个方法可以拓展到包含百万级三元组的知识图上(比如 Common Crawl — DBpedia 语料库有超过六百万个三元组)
-
Incorporating rules into end-to-end dialog systems
-
-
http://alborz-geramifard.com/workshops/neurips19-Conversational-AI/Papers/43.pdf
-
作者们研究了如何把规则集成到端到端的对话系统以及上下文中,目的是让生成的文本更多样化,比如,如果用户已经要求查询某个数据了,系统就不会重新和用户打招呼、重新让用户选任务模版。
其中表现最好的一种配置会把对话上下文和规则编码到一起。
他们的方法通用性很好,可以和各种生成回答的网络架构共同使用。
在这一节,我会介绍一些从更通用的角度研究GNN的论文,包括一些研究GNN模型的可解释性的论文。
论文 15:
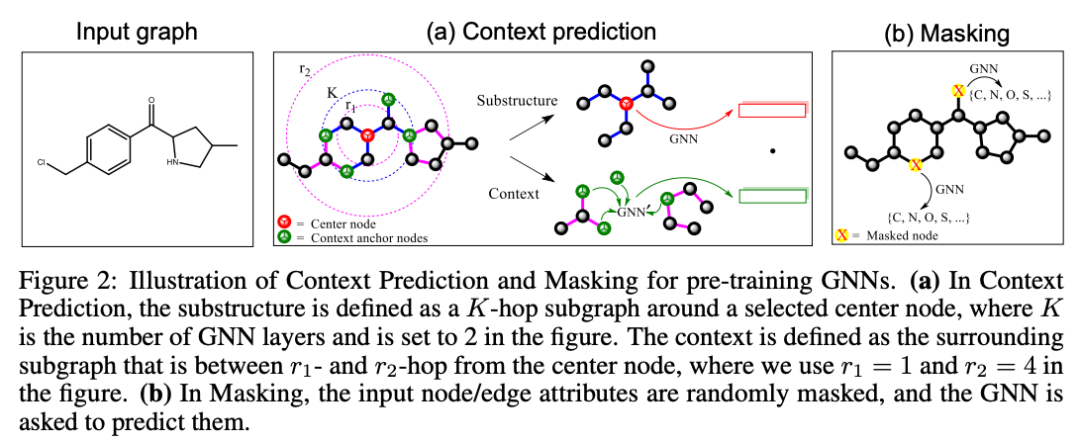
Pre-training Graph Neural Networks
链接:
https://arxiv.org/abs/1905.12265
这篇论文挺火的,这是提出并解释预训练图神经网络框架的首批论文之一。
我们都很熟悉预训练语言模型了,就是先在海量文本上预训练一个语言模型,然后在某个具体任务上做精细调节。
从思路上来说,预训练图神经网络和预训练语言模型很像,问题重点在于这种做法在图上能不能行得通。
简单的答案就是:
可以!
不过使用它的时候还是要小心谨慎。
对于用预训练模型在节点级别(比如节点分类)和图级别(比如图分类)捕捉结构和领域知识,作者们都在论文中提出了有价值的见解,那就是,对于在节点级别学习结构属性来说,内容预测任务的重点是在负采样的帮助下根据嵌入预测一个节点周边的节点(仿佛很像word2vec的训练对不对),其中通过掩蔽的方式,随机遮住一些节点/边的属性,然后让网络预测它们。
作者们也说明了为什么聚合-合并-读出的GNN结构(Aggregate-Combine-Readout GNN)的网络更适合这类任务,是因为它们支持用一个置换不变的池化函数获取一个图的全部表征。
实验表明,只使用图级别的有监督预训练时,向下游任务迁移会造成表现下降,所以需要同时结合节点级别和图级别的表征。
把特征这样组合之后能在40种不同的预测任务中带来6%到11%的ROC-AUC提升。
所以,这代表图上的迁移学习时代已经正式来到我们面前了吗?
会有更多优秀的研究人员为预训练GNN模型编写优秀的库,让大家都可以更方便地使用预训练GNN吗?
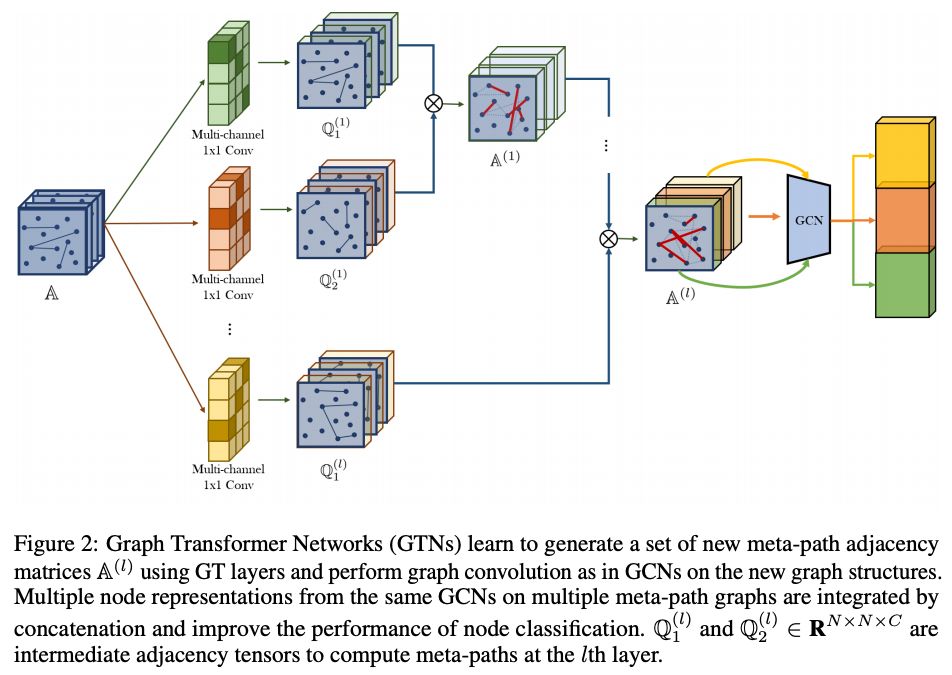
论文 16:
Graph Transformer Networks
链接:
https://papers.nips.cc/paper/9367-graph-transformer-networks.pdf
这篇论文为异质图设计了图Transformer(Graph Transformer)架构。
异质图是指,图中含有多种类型的节点和边。
图Transformer网络(GTN)中通过1x1卷积来获取元路径(边组成的链)的表征。
接着,他们思路的关键在于,在此基础上再生成一系列任意长度的新的元路径(元-元路径?
),长度可以由Transformer层的数量指定,这些元路径理论上可以为下游任务编码更多有有价值的信号。
作者们的实验中,GTN凭借和图注意力网络(Graph Attention Nets)相近的参数数量刷新了节点任务分类的最好成绩。
论文 17:
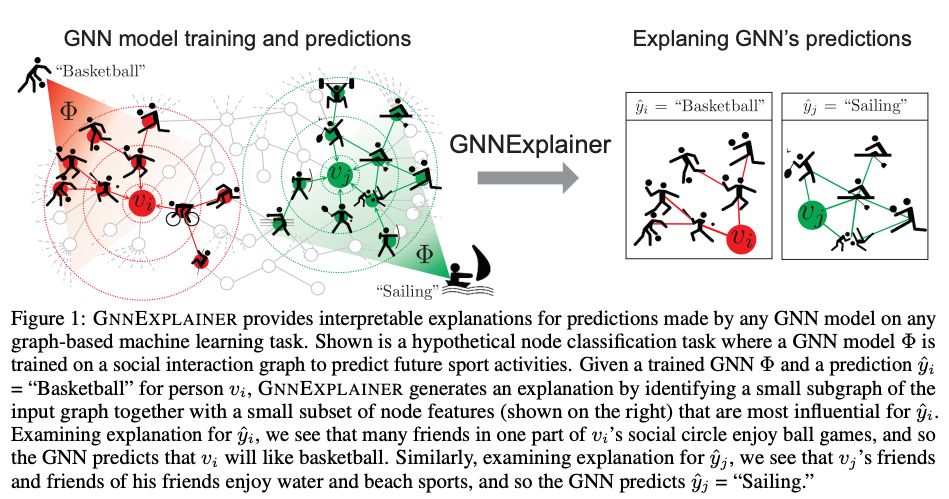
GNNExplainer: Generating Explanations for Graph Neural Networks
链接:
https://papers.nips.cc/paper/9123-gnnexplainer-generating-explanations-for-graph-neural-networks.pdf
这里要介绍的最后一篇论文瞄准的是“图神经网络的可解释性”这个重要任务,论文中提出了用来解释图神经网络的输出的GNN Explainer,这是一个模型无关的框架,它能为任意任务上的、任意一个基于图的模型的预测结果做出解释。
比如说,你在用图注意力网络做节点分类/图分类任务,然后你想看看你的问题的可解释的结果,那你直接用GNN Explainer就好了。
他们的设计思路是,GNN Explainer会让模型预测和结合图、节点特征形成的子图结构之间的共同信息最大化(当然了,生成子图的过程需要一些优化技巧,毕竟检测所有可能的子图是办不到的)。
这个框架给出的解释的形式是,它会返回一个带有最重要的通路和特征的子图,这就很容易被人类解读了。
论文里有一些很清晰的示例图(如下方)。
很棒的论文,鼓掌!
在图上做机器学习是完全可行的!
而且不管是CV、NLP、强化学习都能做。
按照NeurIPS这样的规模,我们可以期待看到更多有趣的评审意见和给人启发的见解。
顺便,我觉得有不少NeurIPS的workshop论文都可以在明年的ICLR2020再次看到。
方便交流学习,备注:
昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:
机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。





 四元数域的旋转
四元数域的旋转
 Source: Xie et al
Source: Xie et al