不同于谷歌,京东选择从应用场景出发迭代对话式AI技术 | Q推荐

1966 年,一个由 MAD-SLIP 程式语言编写,在 36 位元架构的 IBM 7094 大型电脑上运作,所有程式编码仅有 200 行左右的聊天机器人,被 MIT 的德裔电脑科学家 Joseph Weizenbaum 发明出来,名叫“Eliza”。
“Eliza”和机器学习同期出现,早于经典教材的出版,甚至早于多层神经网络和半监督学习的发明。可以说,在“Eliza”的身上,集中反映了我们对人工智能最初的诉求:在某些场景或工作中,替换人类的角色。于是,关于对话机器人的研发尝试,几乎贯穿了整个人工智能的发展史。
20 世纪是个筑梦的世纪,进入 21 世纪后,人们发现,要推动 AI 发展,不仅要有强悍的学术资源,也要有充沛的产业基础。于是关于对话机器人的探索进入了新的阶段,即由如何通过图灵测试打造类人 AI ,转为如何进入企业生产环节,以最直观的方式实现降本增效。
有报告将这种应用描述为:“将智能对话系统加载在服务场景的对话机器人中,以文本、语音和多模态数字人等产品形式与终端用户交互,应用在客户服务、元宇宙、智能决策、泛交互等服务场景。”
因此,京东、百度、阿里、亚马逊云科技、谷歌等企业纷纷高速推进对话机器人的研发。从 2012 到 2022 的十年间,据统计,已经有 103 家企业(去重)获得投资;2022 年 4 月,法国对话式 AI 公司 Mindsay 被收购,也是这一趋势的集中体现。
但人们也很快发现,要使对话式 AI 具备工业级的服务能力,只像 56 年前它的先辈 Eliza 一样写 200 行代码,是根本不可能的。今天的对话式 AI 要攻克大量技术性问题,尤其是在语音对话方面,技术壁垒可以总结为口语不流利(磕巴、语句断断续续)问题、话语权决策问题、鲁棒性问题。
相较于在线机器人,语音对话系统会出现一个特有现象:口语化的表述,通常是不流利的。因为现有的语义理解模型都是基于书面用语等常规文本,而现实生活中,很少有人能一板一眼地与机器人聊天。用户在自然的口语对话中,往往会夹杂着重复、停顿、自我修正等表述特点,例如:
重复:下礼拜下礼拜二三吧好吗。 停顿:呃,就是说,我暂时不感兴趣。 自我修正:可以明天,不是,后天给我送货吧。
以上这种口语中的不流利、磕巴现象,通常会对下游的语义理解造成很大的干扰。而在此类问题的表象之下,是语言作为文化的载体,其本身蕴含的巨大的复杂性。重复、停顿、修正,在不同文化背景、不同地区,都因方言习惯而存在截然不同的呈现方式。甚至,时间也是口语演变的变量之一 —— 在网络时代,几乎每年都会诞生很多俚语,给 AI 识别造成了困难。
正确理解不流利的口语,还只是交流的一个方面。于对话机器人来说,更重要的是做出回复。我们平时聊天,很容易判断应该在什么时候接话,而对于智能对话系统来说,判断在合适的时机接过话语权,并且在听者和说话者之间流畅、自然地转换,显然是一件“超纲”的事情。
当前,市面上的常规解决方案是采用 VAD 检测用户静默时长,当用户静默时长超过阈值(比如 0.8s~1s)时,系统就会接过话语权。但是,这种固定静默时长的方式存在一些问题:如用户并未讲完且在思考中,但是静默时长超过阈值,这时系统响应就会过于迅速敏感;而有时用户的交互迅速简明,这时系统仍然等待静默时长达到设定阈值才接过话语权,这时系统响应迟钝,可能造成用户重复回答。
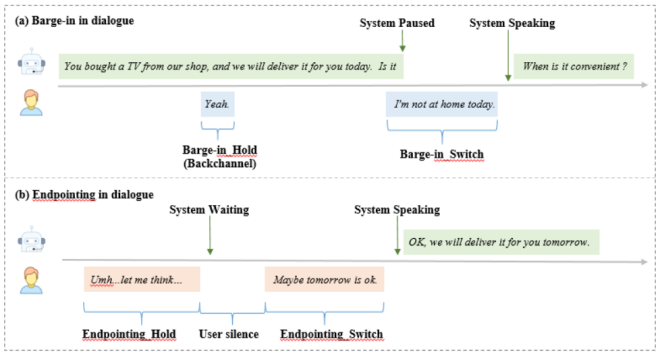
因此,如果想要人机交互更为自然,就不能仅凭声学信号来做判断,还必须要考虑语义是否完整,如果机器能够学会“合理打断”,用户体验会明显提升,但遗憾的是,大多数研究语音识别厂商都不太重视这一点。
除了口语不流利、话语决策权问题,鲁棒性也值得特别关注。
对于高可用系统来说,围绕鲁棒性的设计是必要的、合理的。但对于对话式 AI 而言,这里的鲁棒性所关注的问题,则显得有些“强人所难”。
在常规的语音对话系统中,语义理解模块是基于 ASR(Automatic Speech Recognition,自动语音识别技术)的识别结果进行的。然而由于噪声、背景人声等因素,往往会对 ASR 识别造成干扰,通常表现为出现一些发音相似的识别错误。如何解决噪声的干扰,实现高准确度的识别,就是此处的“鲁棒性”所描述的问题。下方表格是个具体参照:
正确文本/音素 |
ASR错误文本/音素 |
嗯鎏金瓶精华成分是什么呢 ee en2 l iu2 j ing1 p ing2 j ing1 h ua2 ch eng2 f en4 sh ix4 sh en2 m e5 n i2 |
嗯刘精品精华成分是什么呢 ee en2 l iu2 j ing1 p in3 j ing1 h ua2 ch eng2 f en4 sh ix4 sh en2 m e5 n i2 |
不方便往后约 b u4 f ang1 b ian4 uu uang3 h ou4 vv ve1 |
不方便完后约 b u4 f ang1 b ian4 uu uan2 h ou4 vv ve1 |
声音是一系列信息的集合,所以人耳鉴别杂音不完全靠听,也靠语义联系、经验分析、背景知识。对于机器而言,这无疑是个艰巨的任务。
关于上述技术挑战,业内也在寻求新的破解路径,其中有两家企业取得了非常不错的进展,足可为业内参考,一家在美国名叫 Google,一家在中国名叫京东。
前段时间,谷歌在 I/O 大会上宣布将 AI 语音助手 Google Assistant 进行全面升级:在开放式处理方面进一步优化了神经网络模型,使其甚至可以理解非连续的、比较口语化的句子。除此之外,谷歌还发布了专为对话应用程序构建的人工智能系统 LaMDA 2 的一些 demo,展示了其在想象力方面、开放且不跑题以及理解复杂任务等方面的特性。
以零售业起家的京东则探索出了与谷歌不同的发展路径,首先在应用场景上,谷歌的闲聊机器人主要针对 To C 业务,以一问一答式的交互场景为主;而京东的智能对话系统以 To B 为主,往往是来自真实场景的具体问题或任务驱动型的对话,其对垂直领域知识的专业度和回答精确度有着更高的要求。
在孵化场景方面,京东也走出了与大部分科技企业不同的路,其主要是从大规模实践中孵化技术,研发更加易用的 AI 技术。

由于京东每天有千万级的对话量,通过和用户间的不断沟通、测试最佳应答方式,依托于京东云的技术能力,推出了业界首个大规模商用的智能对话与交互系统“京东言犀”。此外,模型满意验证、对抗模型改进等核心技术,都需要在真实场景中才能得以验证,上文提到的口语不流利、话语决策权等问题,京东也早在谷歌发布之前从实际场景中洞察到了需求,并加以优化和改进。
而针对这些问题,言犀给出的解决方案是基于语音 + 语义的联合建模技术。
在语音识别的训练过程中,输入的原始框就含有很多不流畅的句子,随后对每个字进行标注分类,并决定这个字保留还是去除。即采用序列标注模型对句子中的每个字进行分类,从而识别句子中需要删除的冗余成分,达到口语顺滑的目的。
为了缓解模型对于标注数据的过度依赖,京东言犀采用自监督学习的方式,通过对大规模的书面流畅文本进行插入、删除等操作,从而生成大量的不流畅文本。同时,还联合语法判别任务,对于输入的文本,从整个句子层面判断是否语法正确(这里认为原来的流畅文本是语法正确的,而构造的非流畅文本则含有语法错误)。
我们可以把它理解成一本言犀专属的“口语词典”,比如“就是说,我暂时不感兴趣”,“就是说”是可去除的口语词,可以将其收集到口语词典中。最后,再将完整流畅的句子“我暂时不感兴趣”,输入下一道模型进行后续的语义理解。
简单来说,多模态技术就是不再单凭语音信号来判断是否接过话语权,而是分别使用语音、语义以及时间三种不同纬度的特征来判断是否切换话语权。
对于语义特征,言犀会采用 transformer 等各种语言模型,根据上下文来判断当前语句是否完整;对于语音特征,言犀会将音频片段分桢,提取每一帧的特征向量,再将其输入到一个深层的 ResNet 网络,提取其特征表示。如果提取的特征有音调偏低、语速变慢等特点,则代表可能是结尾的最后一个字;此外,还会基于语音片段的时长、语速、声调等时间维度进一步判断,最后通过融合三种不同模态的特征,来判断是否接过话语权。
值得一提的是,针对多模态技术,除了刚才提到的语音 + 语义外,言犀目前还融入了视觉、图像等技术,以虚拟数字人等方式实现更自然的交互。比如,春节期间推出的客服数字人客服芊言,便是语音识别、自然语言理解、视频驱动等多模态技术融合的成果。

关于多模态技术的研究在近几年逐步流行了起来,具体的落地场景各大厂也仍在摸索阶段。京东对于多模态技术的快速突破得益于何晓冬博士,作为多模态技术的开拓者之一,早在 2015 年的时候,何晓冬就提出了语言 - 视觉深度多模态语义模型(DMSM),以及在 2018 年进一步提出了现在业界广为采用的 Bottom-Up and Top-Down attention(BUTD)跨模态注意力机制,并一直推动和见证了多模态技术的实用化,例如在客户服务、多模态数字人方向均已形成规模化落地。同时也带领团队在 NeurIPS、CVPR、AAAI、ACL 等国际 AI 顶级会议上发表了近 130 多篇相关论文,对比业界通常的研发周期,无疑是非常快的速度。
结合音素的鲁棒语义理解模型 CASLU,指的是即使文字识别错误(如上文例子,鎏金瓶—>刘精品),但是其对应的音素基本是正确的(l iu2 j ing1 p),系统就可以作出正确的语义理解。
具体来说,先将音素序列与文本序列分别进行编码,再通过 cross attention 机制,将文本的表征和音素的表征实现有效的融合,利用音素信息来结合它的文本信息做一个文本的增强表示,最后再通过全连接层进行意图分类,最后达到修正错误字的目的。
除此之外,在训练过程中,京东言犀还采用数万小时含有不同噪音、方言的真实场景数据进行迭代;再把正常语境下的句子通过加噪、变速、同混响等方式,变成一种含有噪声或方言的数据再输入到模型里,从而进一步提升模型的抗干扰能力。
当然,技术方案只是一部分,京东言犀的迭代思路是:从场景中来,回到场景中去。
比如,传统的政务热线,一直被吐槽“打不通、说不清、办不了”,这就对智能对话系统提出了要求:要响应快,能准确识别方言浓厚、断断续续的句子,以及在力所能及的范围内减轻人工客服的压力。为了提高用户满意度、实现降本增效,大同 12345 政务热线与言犀合作,经过运营人员一段时间的数据追踪发现:呼入电话接起率达到了 100%。同时,言犀也自动完成了工单创建、智能匹配至对应委办局、跟踪工单执行情况、自动对市民回访等全闭环流程。
在疫情反复的当下,如何促使全市人民进行健康排查、核酸检测是首要任务之一。北京市通州区政府联合京东言犀,针对近 3 日未做核酸检测的市民进行了超过 50 万人的智能外呼排查,在 5 个小时内,通知、提醒了近 40 万人参与核酸检测,为疫情防控大大减轻了压力。其中,针对北京来自全国各地,口音皆不相同、电话端还存在高噪音等复杂环境问题,言犀利用其深度语音识别引擎以及口语顺滑、话语权决策等前沿技术进行优化,保证通话流畅自然,用科技助力疫情防控。
除此之外,在养老行业,言犀联合天津市河西区的智慧养老服务平台,每天早上 9 点自动给近 5000 名独居老人拨打问候电话,避免其突发疾病或无人照顾等情况。
数字客服、语音助手、智能外呼... 基于智能对话系统的应用逐渐拓展到了零售、金融、政务、物流、交通等多个行业。
作为人工智能领域的关键技术,对话式 AI 将会成为未来最有价值的领域。中国也正在以场景驱动人工智能技术的迭代与发展,相信在整个产业的共同探索下,中国的人工智能将不断朝着“个性化”进阶,可以针对不同的人都有不同的对应方案,真正做到千人千面。
点个在看少个 bug 👇