NLP之NER:商品标题属性识别探索与实践

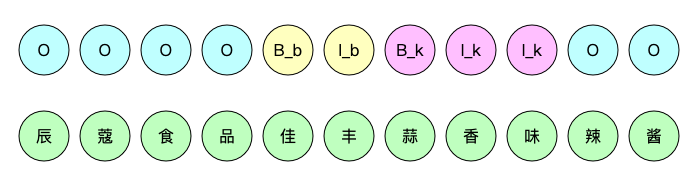
▲ 商品理解示例,品牌:佳丰;口味:蒜香味
本文主要记录下做这个任务上遇到的问题,踩的坑,模型的效果等。
主要内容:
-
怎么构建命名实体识别(NER)任务的标注数据 BertCRF 训练单标签识别过程及踩坑
-
BertCRF 训练超多标签识别过程及踩坑 -
CascadeBertCRF 训练超多标签识别过程及踩坑

NER任务标注数据方法
其实对 NER 任务来说,怎么获取标注数据是比较重要、比较耗时费力的工作。针对商品理解任务来说,想要获取大量的标注数据一般可以分为 3 种途径:
花钱外包,靠外包人肉打标,羡慕有钱的公司。
抓取其他平台的数据,这块也可以分成两种情况,第一种是既抓标题又抓标签-标签值,比如 标题:珍味来(zhenweilai)小黄鱼(烧烤味),品牌:珍味来(zhenweilai),口味:烧烤味,得到的数据直接可以训练模型了;第二种是只抓 标签-标签值,把所有类目下所有常见的标签抓下来,不抓标题,然通过一些手段把标签挂到自己平台的标题上,构造训练数据;第一种抓取得数据准,但很难找到资源给抓,即使找到了也非常容易被风控;第二种因为请求量小,好抓一点,但挂标签这一步的准确度会影响后面模型的效果。
-
用自己平台的商品标题去请求一些开放 NER 的 api,比如阿里云、腾讯云、百度 ai 等,有些平台的 api 是免费的,有些 api 每天可以调用一定次数,可以白嫖,对于电商领域,阿里云的 NER 效果比其他家好一些。

友情提示:抓取需谨慎!

BertCRF单标签NER模型
这部分主要记录 BertCRF 在做单一标签(品牌)识别任务时踩的一些坑。
先把踩的坑列一下:
怎么轻量化构建 NER 标注数据集。
bert tokenizer 标题转 id 时,品牌值的 start idx、end idx 和原始的对不上,巨坑。
-
单一标签很容易过拟合,会把不带品牌的标题里识别出一些品牌,识别出来的品牌也不对。

2.1 轻量化构建标注数据集
上面讲到构建 NER 标注数据的常见 3 种方法,先把第一种就排除,因为没钱打标;对于第三种,我尝试了福报厂的 NER api,分基础版 和 高级版,但评估下来发现不是那么准确,召回率没有达到要求,也排除了;
那就剩第二种方案了,首先尝试了第二种里的第一种情况,既抓标题又抓标签,很快发现就被风控了,不管用自己写的脚本还是公司的采集平台,都绕不过风控,便放弃了;所以就只抓标签-标签值,后面再用规则的方法挂到商品标题上。
只抓标签和标签值相当于构建类目下标签知识库了,有了类目限定之后,通过规则挂靠在商品标题上时,会提高挂靠的准确率。比如“夏季清凉短款连衣裙”,其中包含标签“裙长”:“短款”,如果不做类目限定,就会用规则挂出多个标签“衣长”:“短款”,“裤长”:“短款”,“裙长”:“短款”等等,类目限制就可以把一些非此类目的标签排除掉。
通过规则挂靠出的数据也会存在一些 bad case,尽管做了类目限制,但也有一定的标错样本;组内其他同学在做大规模对比学习模型,于是用规则挂靠出的结果标题——标签:标签值走一遍对比学习模型,把标题向量和标签值向量相似得分高的样本留下当做优质标注数据。
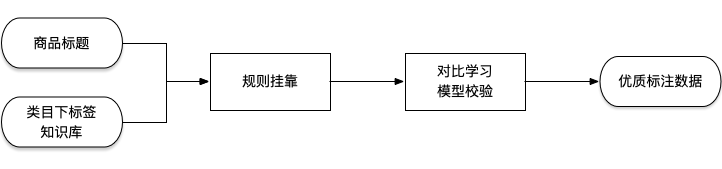
▲ 轻量化构建NER标注数据
通过以上步骤,不需要花费很多人力,自己一人就可以完成整个流程,减少了很多人工标注、验证的工作;得到的数据也足够优质。
2.2 正确打标label index
NER 任务和文本分类任务很像,文本分类任务是句子或整篇粒度,NER 是 token 或者 word 粒度的文本分类。
所以 NER 任务的训练数据和文本分类任务相似,但有一点点不同。对于文本分类任务,一整个标题有 1 个 label。
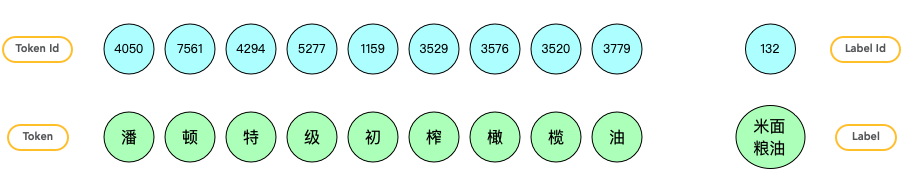
▲ 文本分类任务token和label对应关系
对于 NER 任务,一整个标题有一串 label,每个 tokend 都有一个 label。在做品牌识别时,设定 label 有 3 种取值。
"UNK":0," B_brand":1,"I_brand":2,其中 B_brand 代表品牌的起始位置,I_brand 代表品牌的中间位置。
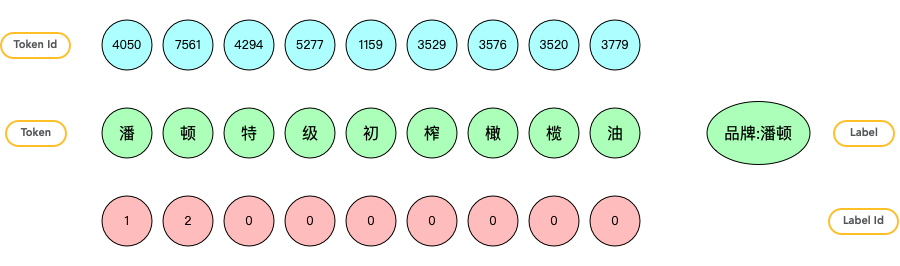
搞清了 NER 任务的 label 形式之后,接下来就是怎么正确的给每个样本打上 label,一般先声明个和 title 长度一样的全 0 列表,遍历,把相应位置置 1 或者 2 就可以得到样本 label,下面是一个基础的例子
a = {
"title": "潘顿特级初榨橄榄油",
"att_name": "品牌",
"att_value": "潘顿",
"start_idx": 0,
"end_idx": 2
}
def set_label(text):
title = text['title']
label = [0]*len(title)
for idx in range(text['start_idx'], text['end_idx']):
if idx == text['start_idx']:
label[idx] = 1
else:
label[idx] = 2
return label
text_label = set_label(a)
print(text_label)
但这里需要把 title 进行 tokenizer id 化,bert tokenizer 之后的 id 长度可能会和原来的标题长度不一致,包含有些英文会拆成词缀,空格也会被丢弃,导致原始的 start_idx 和 end_idx 发生偏移,label 就不对了。
这里先说结论:强烈建议使用 list(title)全拆分标题,再使用 tokenizer.convert_tokens_to_ids 的方式 id 化!!!
刚开始没有使用上面那种方式,用的是 tokenizer(title)进行 id 化再计算偏移量,重新对齐 label,踩了 2 个坑
tokenizer 拆分英文变成词缀,start index 和 end index 会发生偏移,尽管有offset_mapping 可以记录偏移的对应关系,但真正回退偏移时还会遇到问题;
-
使用 tokenizer(title)的方式,预测的时候会遇到没法把 id 变成 token;比如下面这个例子,
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('../bert_pretrain_model')
input_id = tokenizer('呫顿')['input_ids']
token = [tokenizer.convert_ids_to_tokens(w) for w in input_id[1:-1]]
# ['[UNK]', '顿']

'呫顿'变成'[UNK]顿'
因为“呫”是生僻字,使用 convert_ids_to_tokens 是没法知道原始文字是啥的,有人可能会说,预测出 index 之后,直接去标题里拿字不就行了,不用 convert_ids_to_tokens;上面说过,预测出来的 index 和原始标题的文字存在 offset,这样流程就变成
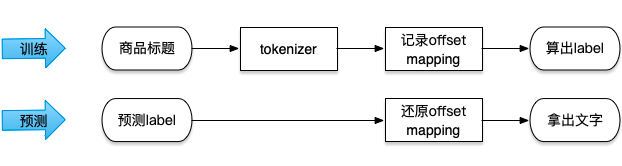
▲ 使用tokenizer id化label对应关系
所以,还是强烈建议使用 list(title)全拆分标题,再使用 tokenizer.convert_tokens_to_ids 的方式 id 化!!!
这样就不存在偏移的问题,start idx 和 end idx 不会变化,预测的时候不需要使用 convert_ids_to_tokens,直接用 index 去列表里 token list 取字
正确打标 label 非常重要,不然训练的模型就会很诡异。建议在代码里加上校验语句,不管使用哪种方法,有考虑不全的地方,就会报错
assert attribute_value == title[text['start_idx']:text['end_idx']]
2.3 BertCRF模型结构
Pytorch 写 BertCRF 很简单,可能会遇到 CRF 包安装问题,可以不安装,直接把 crf.py 文件拷贝到项目里引用。
class BertCRF(nn.Module):
def __init__(self, num_labels):
super(BertCRF, self).__init__()
self.config = BertConfig.from_pretrained('../xxx/config.json')
self.bert = BertModel.from_pretrained('../xxx')
self.dropout = nn.Dropout(self.config.hidden_dropout_prob)
self.classifier = nn.Linear(self.config.hidden_size, num_labels)
self.crf = CRF(num_tags=num_labels, batch_first=True)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
labels=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
outputs = (logits,)
if labels is not None:
loss = self.crf(emissions=logits, tags=labels, mask=attention_mask)
outputs = (-1 * loss, logits)
return outputs
2.4 缓解过拟合问题
只做一个标签(品牌)识别时,训练集是 标题-品牌值 pair 对,每个样本都有品牌值。由于品牌长尾现象严重,这里对热门品牌的数据进行了采样,1 个品牌最少包含 100 个标题,最多包含 300 个标题,数据分布如下

模型关键参数
max_seq_length=50
train_batch_size=256
epochs=3
learning_rate=1e-5
crf_learning_rate=5e-5 第一版模型训练之后,验证集 F1 0.98,通过分析验证数据的 bad case,发现模型对包含品牌的标题预测效果还不错,但是对不包含品牌的标题,几乎全军覆没,都会抽出 1、2 个字出来,模型过拟合了。而且抽出的字一般都是标题前 1、2 个字,这与商品品牌一般都在标题前面有关。
针对过拟合问题及表现的现象,尝试了 2 种方法:
既然对没有品牌的标题一般都抽出前 1、2 个字,那在训练的时候把品牌从前面随机插入到标题中间、尾部等位置,是不是可以缓解。
-
构建训练集的时候加入一些负样本,负样本里 label 都是 0,不包含品牌,正负样本比 1:1。
法 1 训练之后,没有解决问题,而且过拟合问题更加严重了
忍住不哭
法 2 训练之后,过拟合问题解决了,增加了近 1 倍样本,训练时间翻倍。
BertCRF 模型训练完之后,通过分析 bad case,会发现有的数据模型预测是对的,标注时标错了,模型有一定的纠错能力,transformer 强啊!
美国新安怡(fsoothielp)安抚奶嘴。标注品牌:”soothie“;预测品牌:“新安怡(fsoothielp)”
美羚富奶羊羊羊粉 2 段。标注品牌:“羊羊羊”,预测品牌:“美羚”
针对 BertCRF 在 Finetune 时有 2 种方式,一种是 linear probe,只训练 CRF 和线性层,冻结 Bert 预训练参数,这种方式训练飞快;另一种是不冻结 Bert 参数,模型所有参数都更新,训练很慢。
一般在 Bert 接下游任务时,我都会选择第二种全部训练的方式,不冻结参数,虽然训练慢,但拟合能力强;尤其是用 bert-base 这类预训练模型时,这些模型在电商领域直接适配并不会很好,更新 bert 预训练参数,能让模型向电商标题领域进行迁移。

BertCRF多标签NER模型
这部分主要记录 BertCRF 训练超多标签识别时,遇到的问题,模型的效果等。
先把踩的坑列一下:
爆内存问题,因为要训练多标签,所以训练数据很多,千万级别,dataloader 过程中内存不够。
爆显存问题,CRF 的坑,下面会细说。
-
训练完的模型,预测时召回能力不强,准确率够用。
多标签和单标签时,模型的结构不变,和上面的代码一模一样。
3.1 爆内存问题
和单标签一样,也对每个标签值进行了采样,减少标签值的长尾分布现象。1 个标签值最少包含 100 个标题,最多包含 300 个标题。数据分布如下

一个标签有多个标签值,比如“颜色”:“红”,“黄”,“绿”,...等。一个标签有 2 个 label 值,B 代表起始位置,I 代表终止位置,所以整体有 1212 + 1 个类别,1 代表 UNK。
单类别负采样后训练数据总共 200w 左右,多类别时没负采样训练数据 900 多 w,数据量多了 4 倍,原有的 dataset 没有优化内存,到多标签这里就爆内存了。

把特征处理的模块从__init__里转移到__getitem__函数里,这样就可以减少很多内存使用了
旧版本的 dataset 函数
class MyDataset(Dataset):
def __init__(self, text_list, tokenizer, max_seq_len):
self.input_ids = []
self.token_type_ids = []
self.attention_mask = []
self.labels = []
self.input_lens = []
self.len = len(text_list)
for text in tqdm(text_list):
input_ids, input_mask, token_type_ids, input_len, label_ids = feature_process(text, tokenizer, max_seq_len)
self.input_ids.append(input_ids)
self.token_type_ids.append(token_type_ids)
self.attention_mask.append(input_mask)
self.labels.append(label_ids)
self.input_lens.append(input_len)
def __getitem__(self, index):
tmp_input_ids = torch.tensor(self.input_ids[index]).to(device)
tmp_token_type_ids = torch.tensor(self.token_type_ids[index]).to(device)
tmp_attention_mask = torch.tensor(self.attention_mask[index]).to(device)
tmp_labels = torch.tensor(self.labels[index]).to(device)
tmp_input_lens = torch.tensor(self.input_lens[index]).to(device)
return tmp_input_ids, tmp_attention_mask, tmp_token_type_ids, tmp_input_lens, tmp_labels
def __len__(self):
return self.len
新版本的 dataset 函数
class MyDataset(Dataset):
def __init__(self, text_list, tokenizer, max_seq_len):
self.text_list = text_list
self.len = len(text_list)
self.tokenizer = tokenizer
self.max_seq_len = max_seq_len
def __getitem__(self, index):
raw_text = self.text_list[index]
input_ids, input_mask, token_type_ids, input_len, label_ids = feature_process(raw_text,
self.tokenizer,
self.max_seq_len)
tmp_input_ids = torch.tensor(input_ids).to(device)
tmp_token_type_ids = torch.tensor(token_type_ids).to(device)
tmp_attention_mask = torch.tensor(input_mask).to(device)
tmp_labels = torch.tensor(label_ids).to(device)
tmp_input_lens = torch.tensor(input_len).to(device)
return tmp_input_ids, tmp_attention_mask, tmp_token_type_ids, tmp_input_lens, tmp_labels
def __len__(self):
return self.len
可以看到新版本比旧版本减少了 5 个超大的 list,爆内存的问题就解决了,虽然这块会有一定的速度损失。
3.2 爆显存问题
当标签个数少时,BertCRF 模型最大 tensor 是 bert 的 input,包含 input_ids,attention_mask,token_type_ids三个tensor,维度是(batch size,sequence length,hidden_size=768),对于商品标题数据 sequence length=50,显存占用大小取决于 batch size,仅做品牌识别,16G 显存 batch size=300,32G 显存 batch size=700。
但当标签个数多时,BertCRF 模型最大 tensor 来自 CRF 这货了,这货具体原理不展开,后面会单独写一期,只讲下这货代码里的超大 tensor。

CRF 在做 forward 时,函数_compute_normalizer 里的 next_score shape 是(batch_size, num_tags, num_tags),当做多标签时,num_tags=1212,(batch_size, 1212, 1212)>>(batch_size, 50, 768),这个 tensor 远远大于 bert 的输入了,多标签时,16G 显存 batch size=32,32G 显存 batch size=80
# shape: (batch_size, num_tags, num_tags)
next_score = broadcast_score + self.transitions + broadcast_emissions排查到爆显存的原因之后,也没找到好的优化办法,CRF 这货在多标签时太慢了,又占显存。
3.3 模型效果
经过近 4 天的显卡火力全开之后,1k+ 类别的模型训练完成了。使用测试数据对模型进行验证,得到 3 个结论
模型没有过拟合,尽管训练数据没有负样本
模型预测准确率高,但召回能力不强
-
模型对单标签样本预测效果好,多标签样本预测不全,仅能预测 1~2 个,和 2 类似
先说一下模型为什么没有出现单标签时的过拟合问题,因为在近 1k 个标签模型训练时,学习难度直接上去了,模型不会很快的收敛,单标签时任务过于简单,容易出现过拟合。
验证模型效果时,先定义怎么算正确:假设一个标题包含 3 个标签,预测时要把这 3 个标签都识别出来,并且标签值也要对的上,才算正确;怎么算错误:识别的标签个数少于真实的标签个数,识别的标签值和真实的对不上都算错误。
使用 105w 验证数据,整体准确率 803388/1049268=76.5%,如果把预测不全,但预测对的样本也算进来的话,准确率(803388+76589)/1049268=83.9%。
对 bad case 进行分析,模型对于 1 个标题中含有多个标签时,识别效果不好,表现现象是识别不全,一般只识别出 1 个标签,统计验证数据里标签个数和样本个数的关系,这个指标算是标签个数维度的召回率
多标签样本是指一个标题中包含多个标签,比如下面这个商品包含 5 个标签。
标题:“吊带潮流优雅纯色气质收腰高腰五分袖喇叭袖连体裤 2018 年夏季”。
标签:袖长:五分袖;上市时间:2018年夏季;风格:优雅;图案:纯色;腰型:高腰。
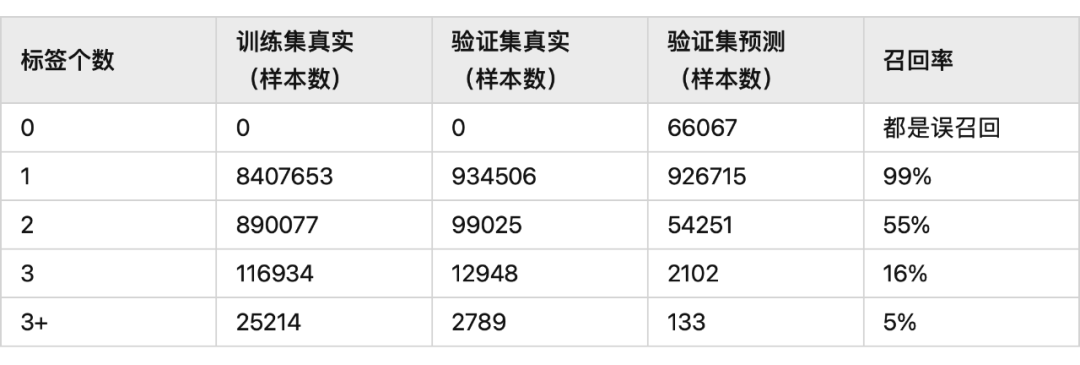
可以看到对于标签数越多的标题,模型的识别效果越不好,然后我分析了训练数据的标签个数个样本数的关系,可以看到在训练数据里,近 90% 的样本仅只有一个标签,模型对多标签识别效果不好主要和这个有关系。
所以在构建数据集时,可以平衡一下样本数,多加一些多标签的样本到训练集,这样对多标签样本的适配能力也会增强。
但多标签样本本身收集起来会遇到困难,于是我又发现了一个新的骚操作

没法获得更多的多标签样本提升模型的召回能力咋办呢?模型不是对单标签样本很牛 b 嘛,那在预测的时候,每次如果有标签提取出来,就从标题里把已经预测出的标签值删掉,继续预测,循环预测,直到预测是空终止。
第一次预测
input title:吊带潮流优雅纯色气质收腰高腰五分袖喇叭袖连体裤2018年夏季
predict label:袖长:五分袖
input title:吊带潮流优雅纯色气质收腰高腰喇叭袖连体裤2018年夏季
predict label:上市时间:2018年夏季
input title:吊带潮流优雅纯色气质收腰高腰喇叭袖连体裤
predict label:风格:优雅
input title:吊带潮流纯色气质收腰高腰喇叭袖连体裤
predict label:图案:纯色
吊带潮流气质收腰高腰喇叭袖连体裤
predict label:腰型:高腰
把高腰从标题里删除,进行第六次预测
input title:吊带潮流气质收腰喇叭袖连体裤
predict label:预测为空
可以看到,标签被一个接一个的准确预测出,这种循环预测是比较耗时的,离线可以,在线吃不消;能找到更多 多标签数据补充到训练集里是正确的方向。
多标签 CRF 爆显存,只能设定小 batch size 慢慢跑的问题不能解决嘛?当然可以,卷友们提出了一种多任务学习的方法,CRF 只学习 token 是不是标签实体,通过另一个任务区分 token 属于哪个标签类别。

CascadeBertCRF多标签模型
4.1 模型结构
在标签数目过多时,BertCRF 由于 CRF 这货的问题,导致模型很耗显存,训练也很慢,这种方式不太科学,也会影响效果。
从标签过多这个角度出发,卷友们提出把 NER 任务拆分成多任务学习,一个任务负责识别 token 是不是实体,另一个任务判断实体属于哪个类别。
这样 NER 任务的 lable 字典就只有"B"、"I"、"UNK"三个值了,速度嗖嗖的;而判断实体属于哪个类别用线性层就可,速度也很快,模型显存占用很少。
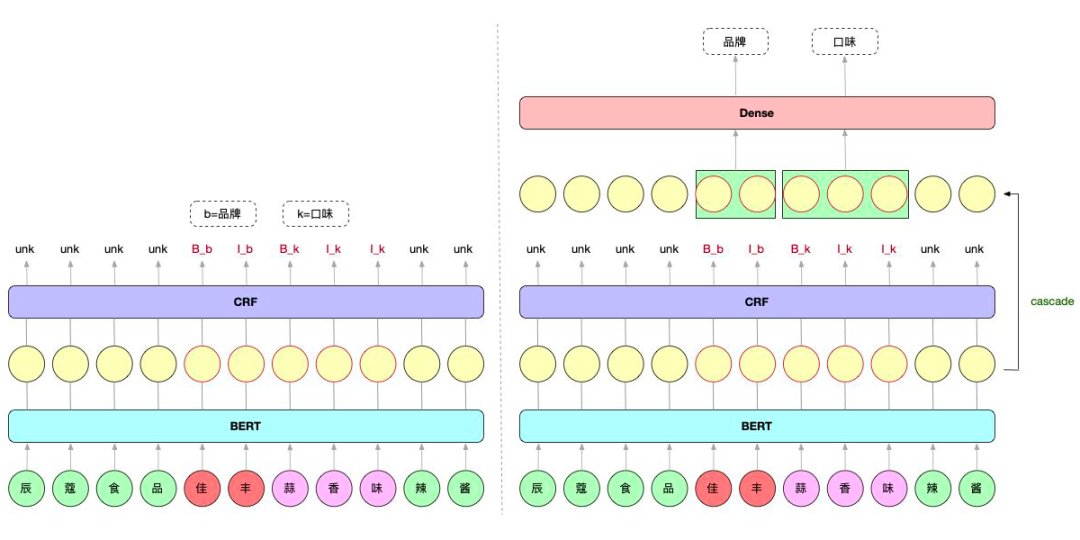
▲ 左单任务NER模型;右多任务NER模型
Cascade 的意思是级联。就是把 BERT 的 token 向量过一遍 CRF 之后,再过一遍 Dense 层分类。但这里面有一些细节。

训练时,BERT 的 tokenx 向量过一遍 Dense 层分类,但不是所有 token 都计算 loss,是把 CRF 预测是实体的 token 拿出来算 loss,CRF 预测不是实体的不计算 loss,一个实体有多个 token,每个 token 都计算 loss;预测时,把实体的每个 token 分类结果拿出来,设计了三种类别获取方式。
比如“蒜香味”在模型的 CRF 分支预测出是实体,标签对应 "B"、"I"、"I";接下要解析这个实体属于哪个类别,在 Dense 分支预测的结果可能会有四种
“蒜香味”对应的 Dense 结果是 “unk”、“unk”、“unk”,没识别出实体类别
“蒜香味”对应的 Dense 结果是 “口味”、“口味”、“口味”,每个 token 都对
“蒜香味”对应的 Dense 结果是 “unk”、"口味"、"口味",有的 token 对,有的token 没识别出
-
“蒜香味”对应的 Dense 结果是 “unk”、“品牌”、“口味”,有的 token 对了,有的 token 没识别出,有的 token 错了
针对上面 4 中结果,可以看到 4、3、2 越来越严谨。在评估模型效果时,采用 2 是最严的,就是预测的 CRF 结果要对,Dense 结果中每个 token 都要对,才算完全正确;3 和 4 越来越宽松。
4.2 模型代码
import torch
from crf import CRF
from torch import nn
from torch.nn import CrossEntropyLoss
from transformers import BertModel, BertConfig
class CascadeBertCRF(nn.Module):
def __init__(self, bio_num_labels, att_num_labels):
super(CascadeBertCRF, self).__init__()
self.config = BertConfig.from_pretrained('../bert_pretrain_model/config.json')
self.bert = BertModel.from_pretrained('../bert_pretrain_model')
self.dropout = nn.Dropout(self.config.hidden_dropout_prob)
self.bio_classifier = nn.Linear(self.config.hidden_size, bio_num_labels) # crf预测字是不是标签
self.att_classifier = nn.Linear(self.config.hidden_size, att_num_labels) # 预测标签属于哪个类别
self.crf = CRF(num_tags=bio_num_labels, batch_first=True)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
bio_labels=None,
att_labels=None,
):
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
bio_logits = self.bio_classifier(sequence_output) # (batch size, sequence length, bio_num_labels)
num_bio = bio_logits.shape[-1]
reshape_bio_logits = bio_logits.view(-1, num_bio) # (batch size * sequence length, bio_num_labels)
pred_bio = torch.argmax(reshape_bio_logits, dim=1) # ner 预测的bio结果
no_zero_pred_bio_index = torch.nonzero(pred_bio) # 取出ner结果非0的token
att_logits = self.att_classifier(sequence_output) # (batch size, sequence length, att_num_labels)
num_att = att_logits.shape[-1] # att_num_labels
att_logits = att_logits.view(-1, num_att) # (batch size * sequence length, att_num_labels)
outputs = (bio_logits, att_logits)
if bio_labels is not None and att_labels is not None:
select_att_logits = torch.index_select(att_logits, 0, no_zero_pred_bio_index.view(-1))
select_att_labels = torch.index_select(att_labels.contiguous().view(-1), 0, no_zero_pred_bio_index.view(-1))
loss_fct = CrossEntropyLoss()
select_att_loss = loss_fct(select_att_logits, select_att_labels)
bio_loss = self.crf(emissions=bio_logits, tags=bio_labels, mask=attention_mask)
loss = -1 * bio_loss + select_att_loss
outputs = (loss, -1 * bio_loss, bio_logits, select_att_loss, att_logits)
return outputs4.3 模型效果
上面提到评估 Dense 的结果会遇到 4 种情况,使用第 4 种方式进行指标评估;NER 的识别效果和上面一致。
使用 105w 验证数据,整体准确率 792386/1049268=75.5%,比 BertCRF 低 1 个点;把预测不全,但预测对的样本也算进来的话,准确率(147297+792386)/1049268=89.6%,比 BertCRF 高 5 个点;
标签个数和预测标签个数的对照关系:
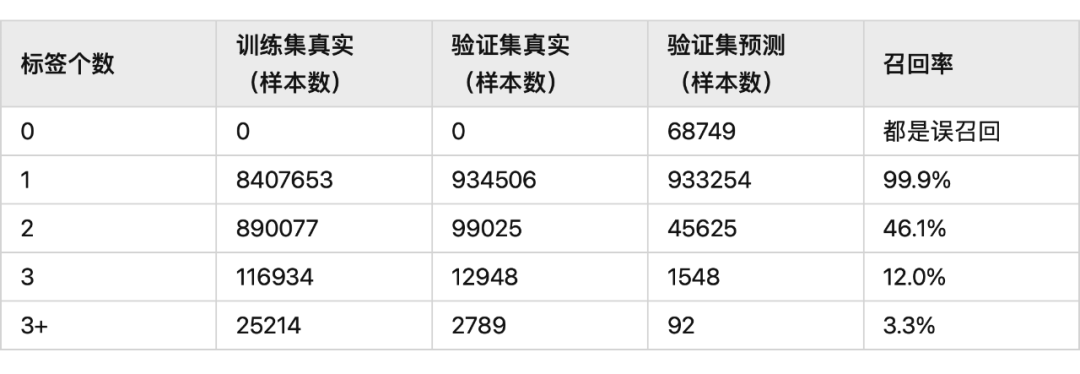
CascadeBertCRF 模型的召回率比 BertCRF 要低,但模型的准确率会高一些。CascadeBertCRF 相比 BertCRF,主要是提供了一种超多实体识别的训练思路,且模型的效果没有损失,训练速度和推理速度有大幅提高。
把实体从标题里删掉训练预测的方法也同样适用 CascadeBertCRF。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



