![]()
来源:智源社区
作者:罗丽
【新智元导读】本文介绍了智能代码理解和生成代码的机理、预训练模型、基准数据集等新的评价指标,及微软的部分场景应用。
11月6日上午,在中国中文信息学会和中国计算机学会联合创办的“语言与智能高峰论坛”上,微软亚洲研究院副院长周明以《从语言智能到代码智能》为题,介绍了
智能代码理解和生成代码的机理、预训练模型
(CodeBERT/CodeGPT)、
基准数据集
(CodeXGLUE)
以及融合了编程语言句法和语义信息的新的评价指标
(CodeBLEU),分享了微软在编程语言知识和上下文进行推理,支持代码检索、补全、翻译、纠错、问答等场景的应用。
自然语言处理在深度学习的支撑下取得了迅猛发展,把自然语言发展的技术迁移到智能代码研究领域,以提升代码能力成为近年来新的研究热点。
代码智能能够让计算机具备理解和生成代码的能力
,利用编程的语言知识和上下文进行推理,支持代码检索、代码翻译等场景应用。
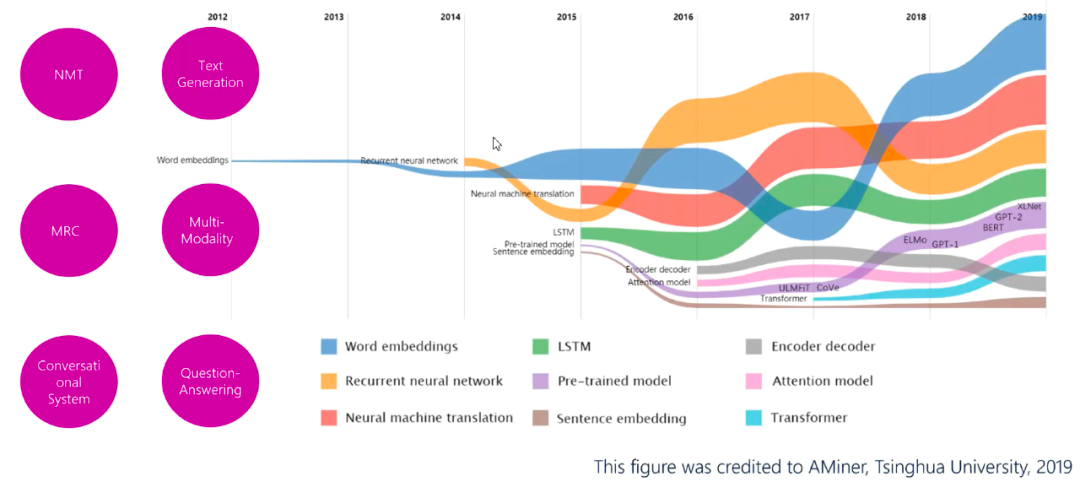
图1:基于神经网络的NLP研究(NN-NLP)
图为清华大学唐杰团队总结的过去5年ACL文章中自然语言发展的主要工作。
包括 Word embeddings、LSTM、Encode decoder、RNN、Pre-trainedmodel 等,这些技术推动了自然语言的应用,包括基于神经网络的机器翻译,预训练模型演化,阅读理解技术等。
基于以上研究,周明总结了过去5年神经网络自然语言处理具有里程碑意义的工作。
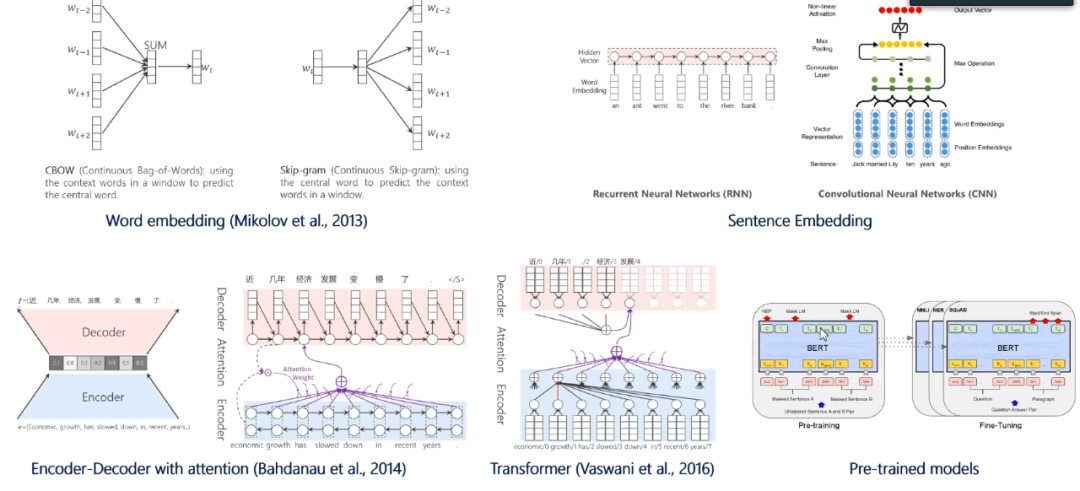
图2:NN-NLP的技术演进
1. Word embedding
。2013年,Mikolov 等提出利用上下文预测中间词或利用中间词来预测上下文。在一个窗口内,根据预测的损失,回传调整 Word embeddings,并通过大规模文本训练,得到了一个相对稳定的 Wordembeddings。
Word embeddings 包含词本身的意义、上下文、句法语义等信息的嵌入,相对来讲,它是一个静态表示。
2. Sentence embedding
。 既然词可以做嵌入,那么句子也应该能做嵌入,对句子进行表示的最初考虑是利用 RNN 或 CNN,从词嵌入出发,得到句子的全局表示。
3. Encoder-decoder
。之后,研究者提出 Encoder decoder,以实现不同语言串的输出,比如机器翻译能够将中文语言串,变为英文语言串。Decoder 在产生某个输出时,需要考虑输入各节点权值的影响。
4.Transformer
。RNN 自左到右的并行能力比较弱,只有一个特征抽取器,
从多角度来进行特征抽取时,需要引入自注意力机制
(Self-attention Mechanism),实现一个词与其他词连接强度的同步计算,而 Multi-header 的多角度抽取特征,为Transformer技术带来很多革命性突破。
5. Pre-trained model
。对大型数据库做 Self-supervised learning,针对大规模语料进行训练,可以得到预训练模型。
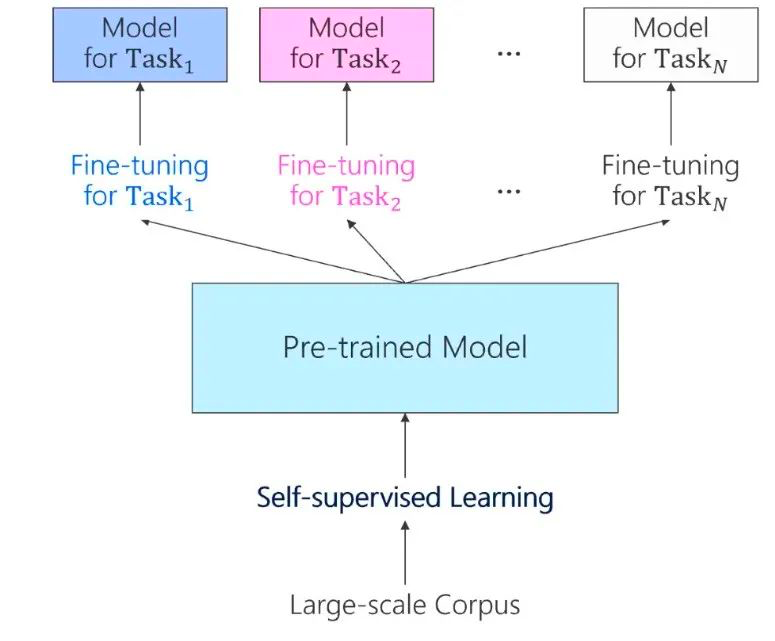
预训练模型是把大规模语料中训练的通用语言知识浓缩在一个模型中,该模型是一个词的上下文相关的语义表示,在该模型中对下游任务做 Fine-tuning。
所谓 Fine-tuning,是在原有神经网络的基础上,根据具体任务来调整参数
,每一个具体任务标注语料,然后针对标注的语料进行训练,训练的损失回传,调整网络,得到一个相对较好的处理器。
图3:预训练模型-自然语言处理的新范式
预训练模型包括预训练和微调(Fine-tuning),可以做纯文本训练,也可以做文本、图像、文本和视频,用成对数据进行处理。
在Pre-trained model中,需要一个自监督学习策略 Autoregressive language model (自回归语言模型)和 Auto encoder (解码自动编码器)做单语言、多语言或多模态,支持多种自然语言任务,包括分类、序列标注、结构预测、序列生成。
Self-supervise learning
可以利用数据的自然特点,
不需要人工进行标注就可以进行训练和学习
。
Auto-encoding
可以对词或者句子进行覆盖或调整,让模型来猜测原来的词或原来的词序,
其错误率可以调整网络
。
图4:自监督学习的预训练
1. 预训练模型嵌入了与任务无关的常识。对语法知识和语义知识进行了隐式编码。
2. 预训练模型将学习到的知识转移到下游任务中,包括低资源注释任务和语言的任务。
3. 预训练模型几乎支持所有的 NLP 任务,且都具有 SOTA 效果。驱使研究者利用自然训练的迁移模型,来支持所有的自然语言任务。
4. 为各种应用程序提供可扩展的解决方案
。只需通过特定任务的标签数据微调支持新任务。
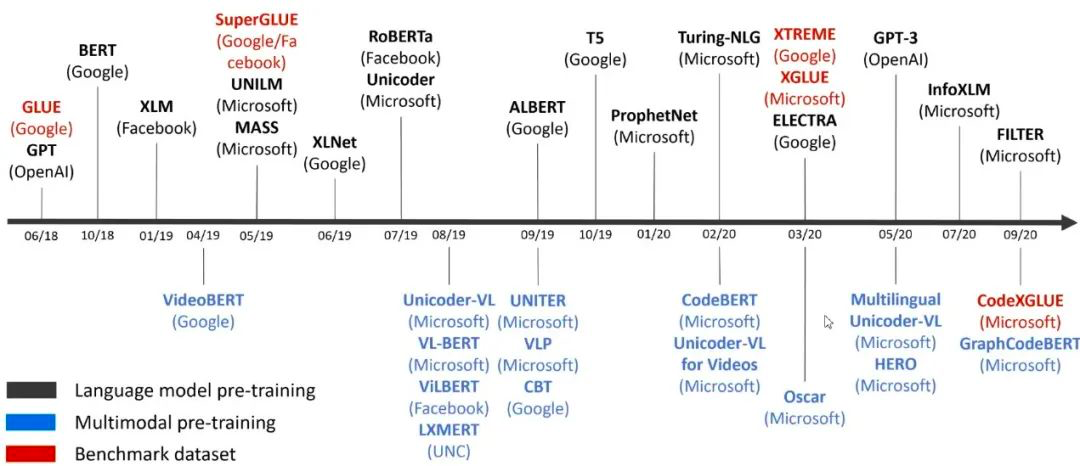
图6:微软预训练模型的主要应用
1. 出现具有 SOTA 性能的大型模型(如Turing 17B;GPT-3 175B;GShard 600B)
2. 预训练的方法和模型不断创新,新的预训练任务、屏蔽策略和网络结构出现。
3. 从单一语言到多语言,到多模式(图像、视频、音频),再到编程语言,不断拓展,把迁移学习的模型更广泛的运用到新的任务中。
4.
可满足实际需要的小型经济模型
(例如模型压缩,知识提炼等)。
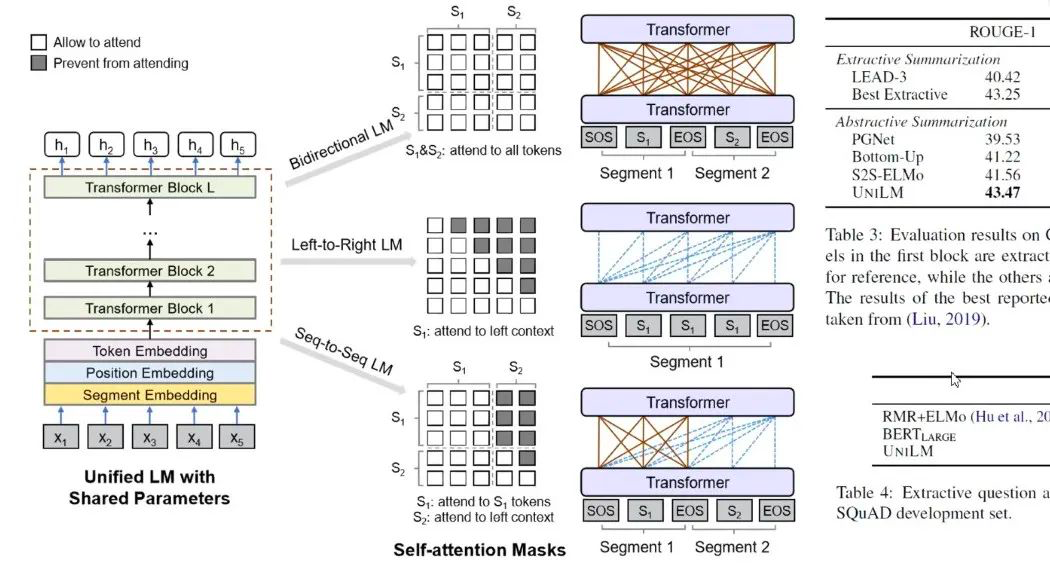
BERT 和GPT 都是从左到右的语言模型,GPT 适合做生成,BERT 适合做理解,而UniLM 可以把两个任务同时融入,
通过引入 Sequence to Sequence 的语言模型,在预测词时做多任务学习
,通过Mask矩阵来控制词和词的连接,用一个统一架构,通过多任务学习得到UniLM,该模型兼具分析生成和Encoder decoder 工作。
图7:UniLM
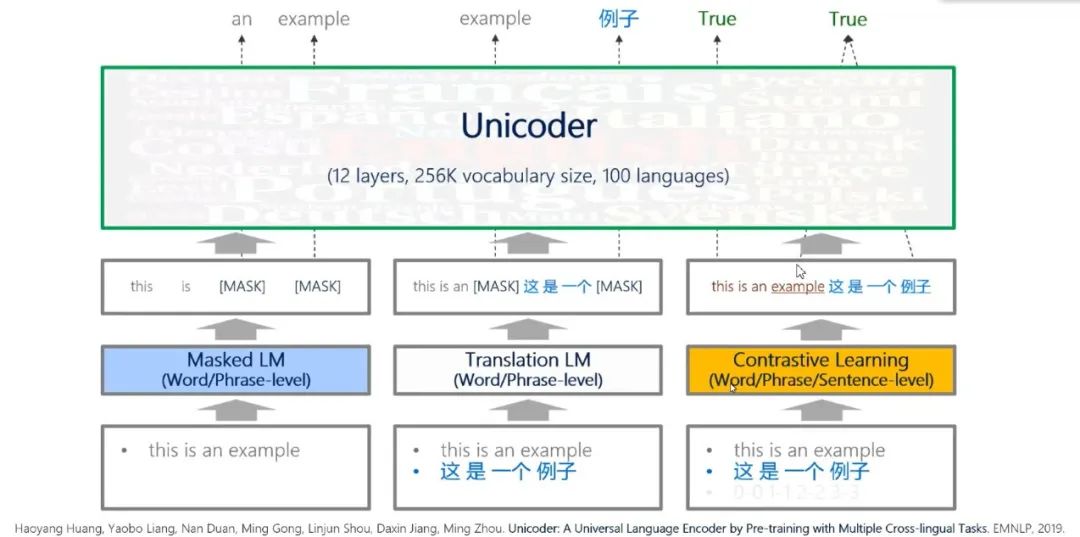
与经典的多元预训练模型相比,
Unicoder 通过引入新任务 Constructive Learning (构造性学习)来预测
两个词之间是否构成互译或者两个短语或句子之间是否构成互译,比如中英文句子的互译,该任务使预训练水平有所提高。
图8:Unicoder
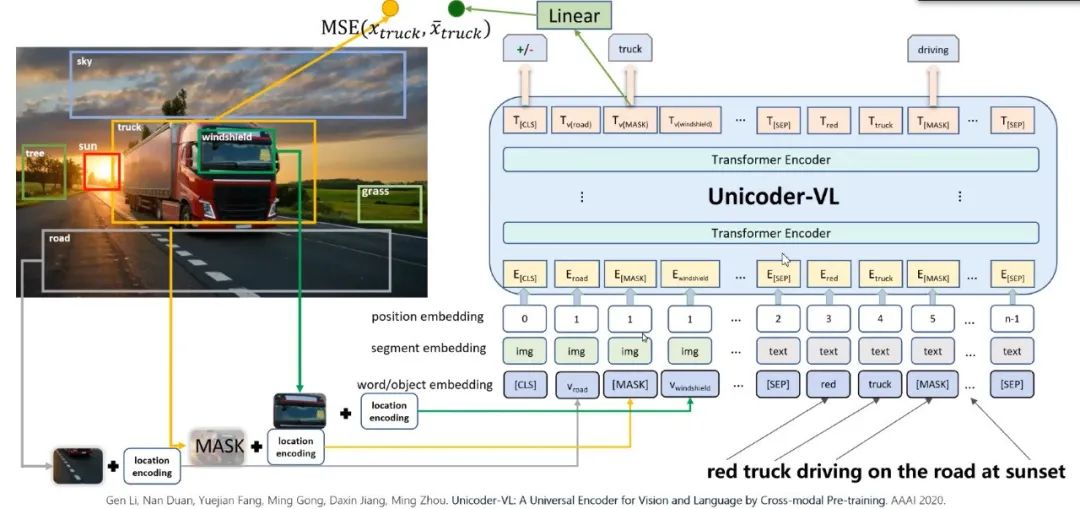
针对 Unicoder 只能做分析或理解,研究者引入了 Unicoder-VL 进行生成,利用对输入句子加入噪声,比如颠倒词序,或加、减词做Encode,并在Decode时试图恢复所破坏的部分,测试模型的整体能力。
之后,
研究者将预训练模型继续扩展到图像和视频任务中
,并构建模型 Unicoder-VLfor Images 和 Unicoder-VL for Videos。
图9:Unicoder-VL for Images
图10:Unicoder-VL for Videos
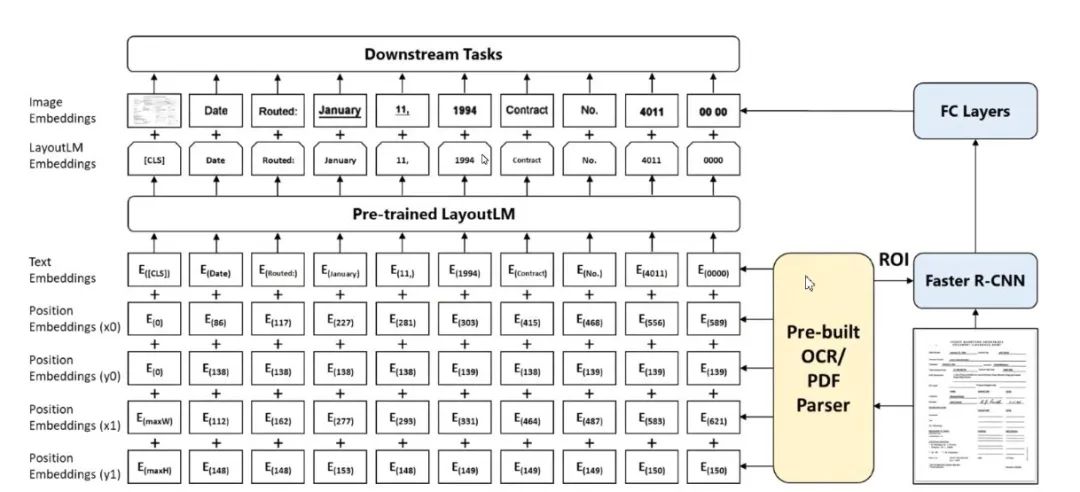
LayoutLM 是 Document 的训练模型,
该模型考虑了分布信息
。
用 OCR 扫描文档,扫描结果加每一个识别对象的位置信息作为输入,得到 OCR 的结果,每个结果的位置信息和对应文档的预训练模型,使用时,将预训练模型加图像的部分融入,做各项文档识别和信息抽取的任务。
图11:LayoutLM: Text Layout Pre-training
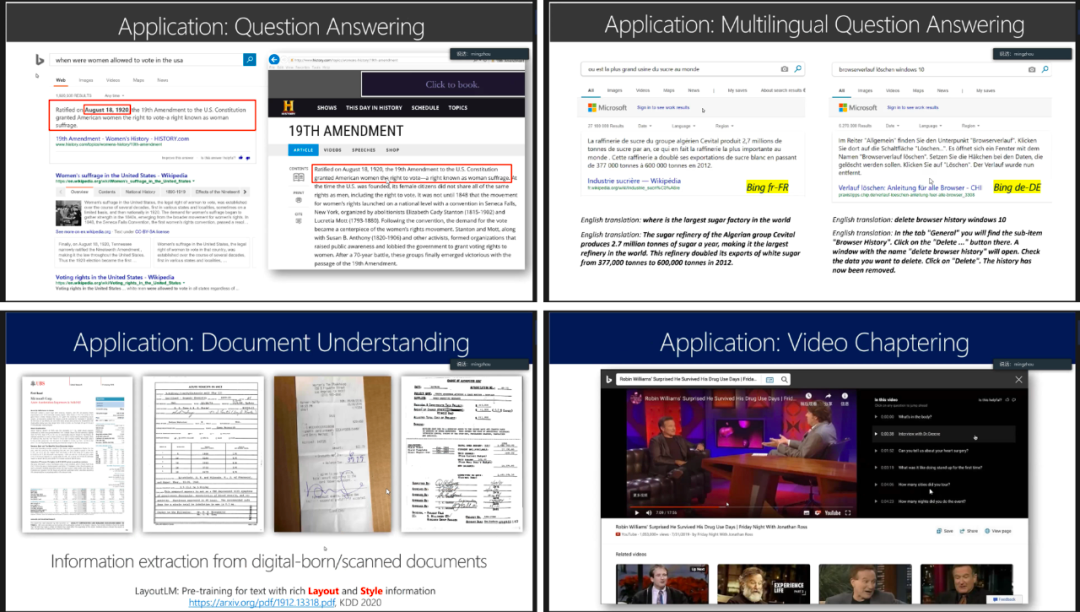
预训练模型的应用包括问答、多语言问答、文本理解和视频章节提取等。
图12:预训练模型的应用
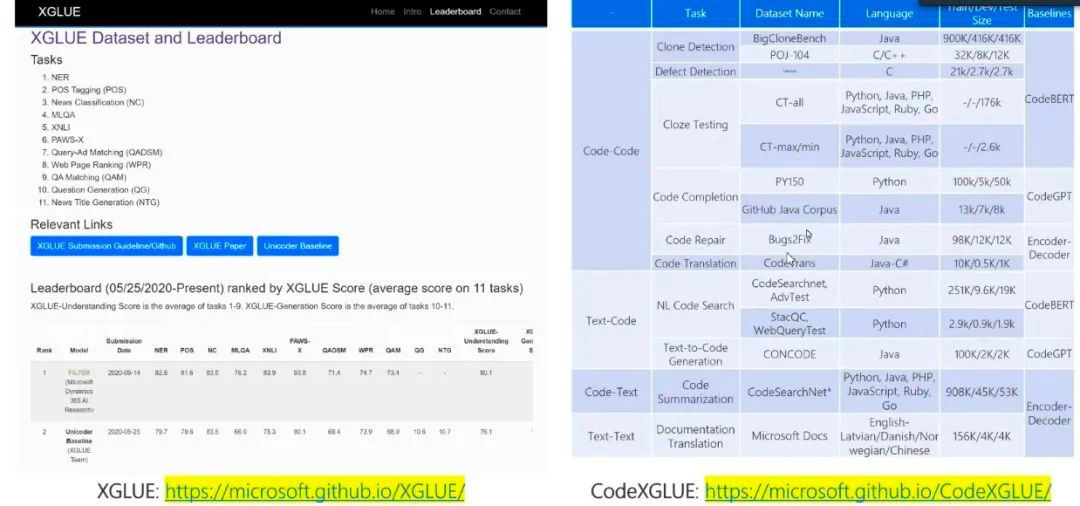
为促进预训练模型发展,微软发布数据集 XGLUE,该数据集覆盖十几种语言,包含几十个任务。
从Excel的智能化操作,到自然语言查询转换为 SQL 的数据库操作,再到 GPT-3 自动生成代码,代码智能的实际应用在不断革新和扩大。那么,用预训练模型如何做代码智能?
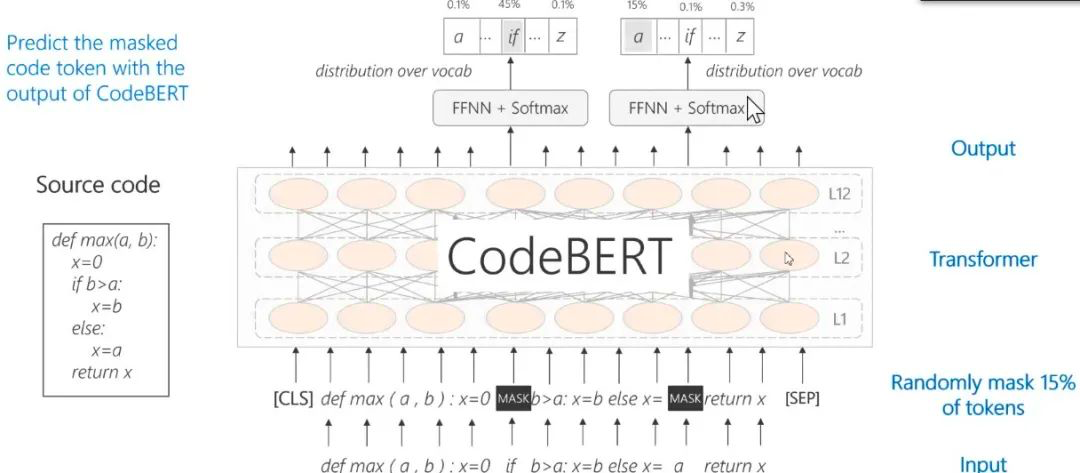
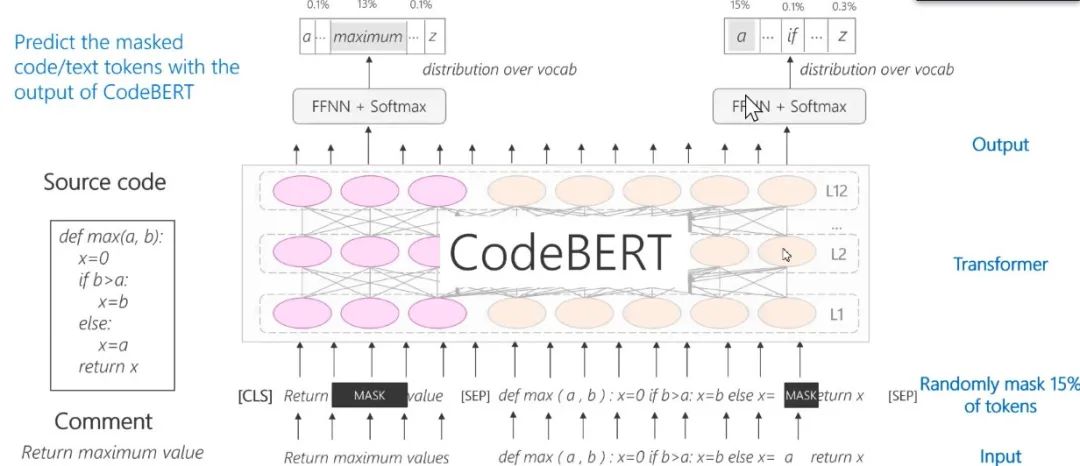
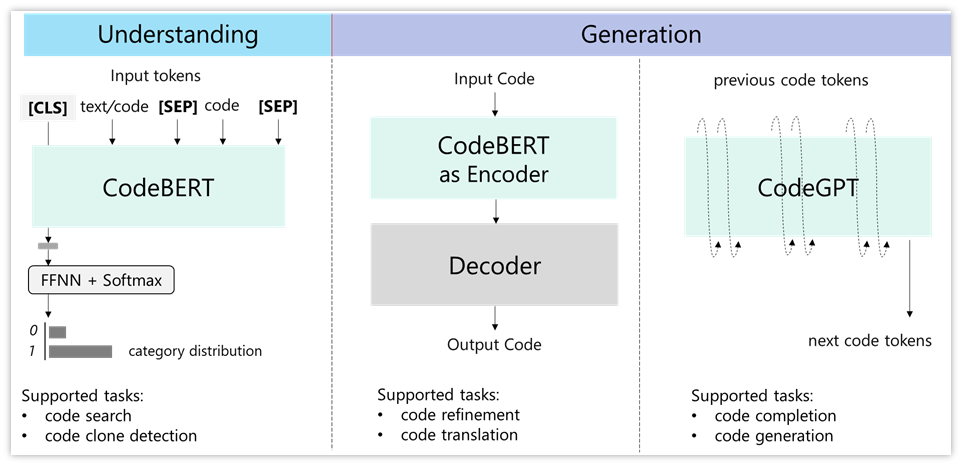
通过将代码融入预训练模型,用代码训练 BERT,得到包含代码的预训练模型;通过融入有文本注释的代码进一步训练模型,可以得到具有代码和文本的 CodeBERT。
此外,
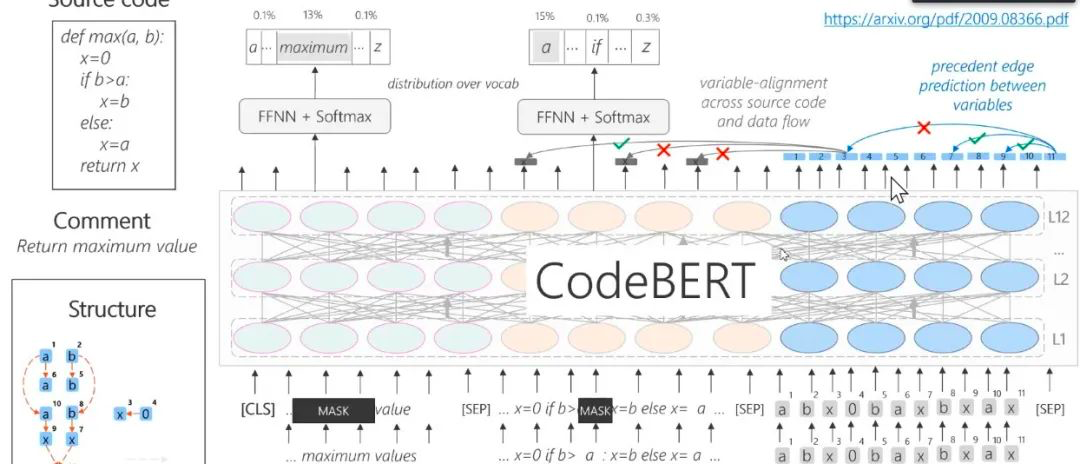
代码具有结构,代码之间的变量有顺序关系,需要抽取变量之间的依赖关系或相同关系来构建模型
,对于给定的代码,可以用程序包得到代码对应的抽象语法树(AST),将抓取的代码特点融入模型,训练建立新的具有代码结构的 CodeBERT。
CodeBERT是一个可处理双模态数据的新预训练模型,使用了 Transformer 作为基本网络结构,采用混合目标函数:掩码语言模型和替换 Token 检测。
![]()
图14:CodeBERT——Pre-Train with Code
图15:CodeBERT:Pre-Train with code + Text
图16:CodeBERT——Pre-Train with Code + Text + Structure
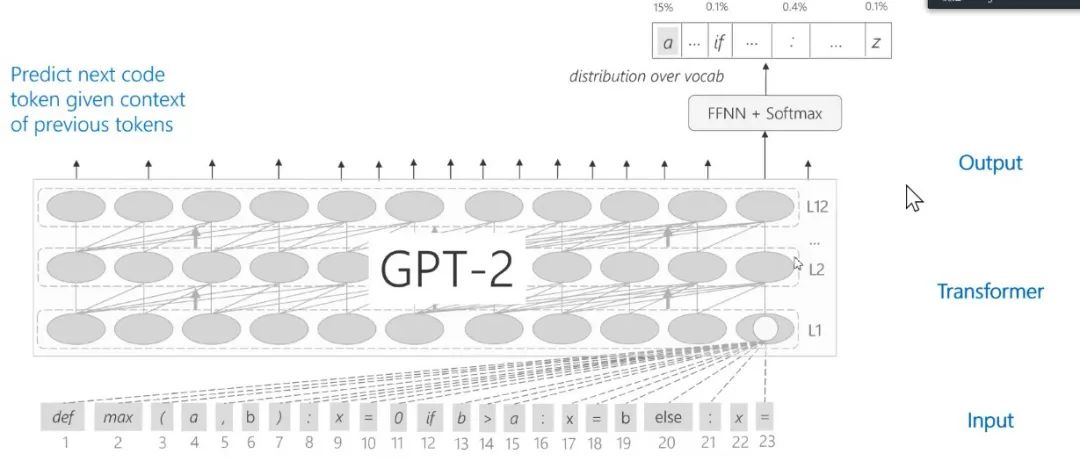
同样,可以通过已有的GPT模型训练得到 CodeGPT。
图17:CodeGPT
基于以上模型,进行代码智能的实验,构建Fine-tuning框架。
该框架中,
CodeBERT主要用于分析,而codeGPT用于生成,Encoder Decoder 用于实现不同语言串之间的转
化
,其中Encoder部分可以利用CodeBERT进行初始化。
代码智能的下游任务包括代码搜索(Code Search)、代码完成(Code Completion)、代码修复(Code Repair)和代码翻译(Code Translation)等,
实验发现,代码智能在自然语言代码检索、修复,文档生成、翻译等任务上均取得了 SOTA 效果。
![]()
图18:Fine-tuning框架
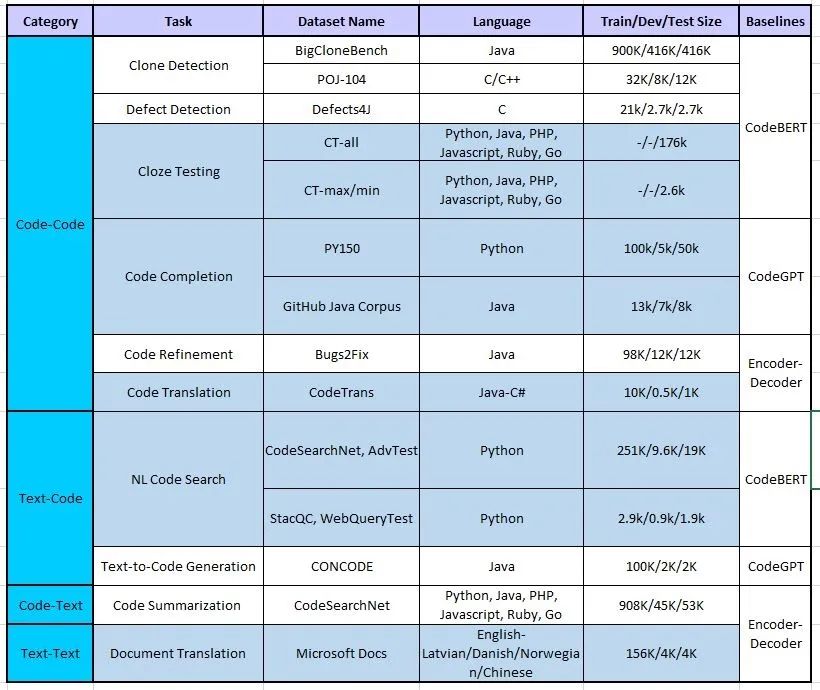
为了支持代码智能的研究,研究人员发布了数据集 CodeXGLUE。该数据集包括14个子数据集,用于10个多样化的代码智能任务,包括 Code-Code、Text-Code、Code-Text 和Text-Text 四大类。
![]()
图19:CodeXGLUE
![]()
图20:GitHub链接
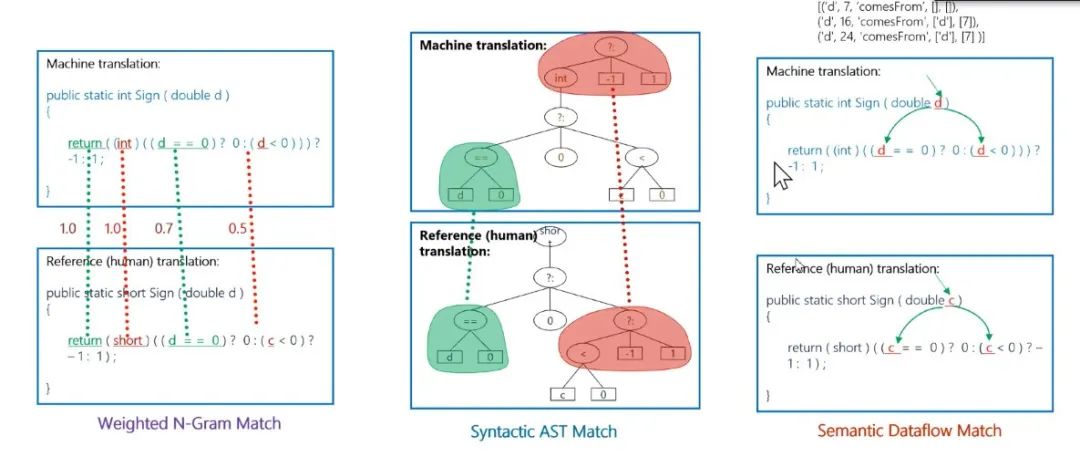
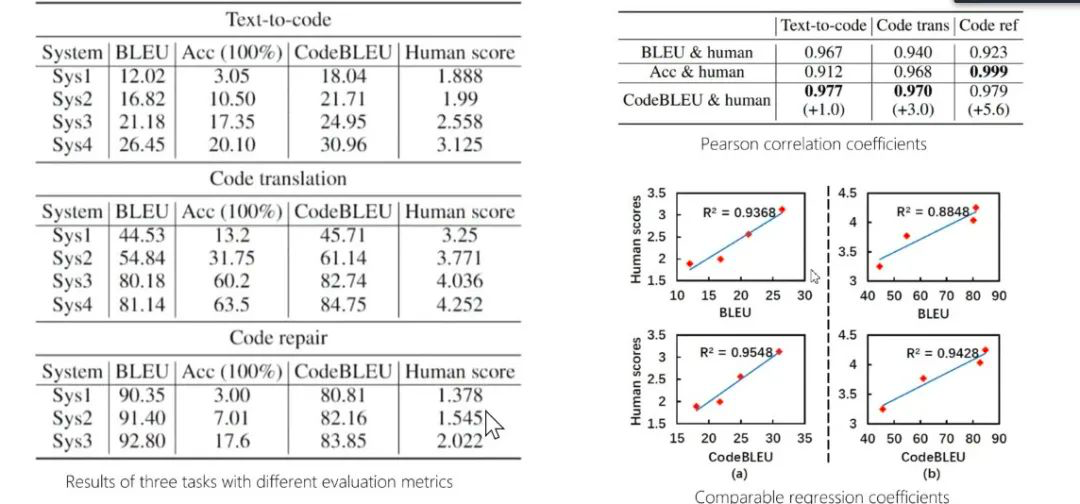
代码的评测需要考虑语法和语义问题,周明表示,CodeBLEU 评估机制融合了 N-Gram AST 和 Semantic Dataflow 及其不同权值组合进行评估,相关度测试表明,
CodeBLEU性能更好
。
图21:CodeBLEU
图22:CodeBLEU实验
周明表示,代码智能的研究更需要考虑代码语言上的特点,需要具有对全局内容进行建模的能力,
代码翻译中编码的逻辑特点和代码搜索中复杂、多意图的自然语言理解等目前仍需要进一步改进
。
1. 引入新的训练任务,以更好地表示代码的特征并考虑全局上下文。
2. 通过考虑逻辑、语义、效率、安全性、执行力等提升评估方法(CodeBlue++,更好的模拟代码质量)。
3. 探索类似于 NLP 任务之外的其他代码智能的任务(测试用例生成,用于算法设计的 AI,bNg 检测和修复等)。
4. 呼吁软件工程领域和 NLP 领域之间进行更多的跨学科研究。
周明: 应
从研究的角度探究其方法论
,比如知识、领域知识常识、知识图谱等如何融入,在领域知识表达方面,研究能否用小模型做更好的工作,比如模型压缩、知识萃取等。
在Fine-tuning方面也有很多工作可以去做。
另外,
可以进行扩展应用领域的研究
,包括单语言到多语言,甚至到语音、图像、视频、文档等新领域的扩展和跨学科的研究。
Q2: 自动生成的代码的语法规则是硬约束还是自动学习的?怎么保证这种正确性?
周明: 这是做自然语言的人的弱项,我们只知道串对串,串生成完之后用 BLEU 算N-Gram匹配程度。这里存在
一个非常重要的问题,就是如何衡量代码生成的能力和质量。
比如,逻辑上是否正确,语义上是否正确,效率是否高,安全性和可执行是否可以,这些目前还没有一个很好的办法来衡量,但在逻辑性、语义、效率等方面,可以进行一些模拟工作。
期待今后有更多的人做自动评价生成的代码的逻辑语义和效率问题的研究工作。
Q3: 自然语言处理与语音、图像结合的未来工作前景如何?
周明: 自然语言从语音、图像领域借鉴了很多方法,比如,深度学习。自然语言处理研究者提出Transformer和更好的预训练模型,但我们不应固于自己的思路,
应该把一切可序列化的问题,包括单序列化建模、多序列化的互相映射和比较都看作是一种自然语言任务
,用自然语言的方法来帮助提高相关领域的技术发展,共同推动人工智能的发展。
Q4: 与语言智能相比,代码智能有什么独特的技术挑战?
周明: 和自然语言相比,代码的书写需要遵循特定的语法规则。自然语言通常本身不可执行,但代码在编译环境下可以执行并返回结果。
因此,和语言智能相比,
代码智能无论在数据、建模、评测、应用上都需要更关注代码的语法规则和可执行性
。
周明: 近十年,人工智能的蓬勃发展主要得益于大数据、数据驱动的大模型和强算力,但其建模人类本体知识的能力很有限,因此
如何结合数据驱动模型(如深度学习)和以知识图谱为代表的本体知识是一个非常有前景的方向
。
Q6: 如何保证生成的 code 的正确性,如何测试?
周明: 测试 code 的正确性一直是代码生成的一大难点。对于比较独立的、不依赖其它函数或者环境的代码,
测试其正确性可以采用人工设计的 Test Case 来实现
,但也不能保证通过了这些测试的代码就是正确的。
对于依赖比较多的函数,使用 Test Case 测试比较困难,所以只能通过其它的自动评价的方法,比如跟参考答案完全匹配的准确率,或者N元文法的准确率。
我们提出了
CodeBLEU 的评价方法,使用句法树
匹配信息和变量依赖关系的匹配信息来逼近生成代码的语义的正确性。
Q7: 程序自身的算法逻辑思想怎么体现?同样的功能,不同的人写的code会不一样,这种自动生成能体现这种特点吗?
周明: 目前的代码理解方法很难直接体现算法的逻辑,已有一些方法在代码理解和生成任务中考虑代码的语法结构(AST)和代码的语义结构(Data Flow)。
目前的代码生成系统多是基于大规模数据训练的数据驱动模型,并没有考虑个性化代码生成。
Q8: 代码翻译成不同的语言,框架层面怎么翻译呢?
周明: 框架结构方面的信息对代码翻译是很重要的。CodeBERT 在预训练的过程中考虑了句法(AST)和语义(Data Flow)等结构相关的信息,
使用 CodeBERT 初始化的序列到序列转换模型能够对这些结构信息进行建模
,从而可以生成框架结构一致的目标语言代码。在代码翻译的研究领域也存在显式的基于代码树和逻辑图进行建模的方法。
周明: 一种解决标识量作用域的方式是使用数据流分析,该技术也被我们用来做 CodeBERT 模型和 CodeBLEU 指标。
数据流分析中,当一个变量离开它的作用域,这个变量就会被标记为 dead,这一定程度上反映了标识量的作用域。
![]()