![]()
一提起雷军,绝大多数人首先会想到小米,对金山软件却知之甚少。雷军作为金山软件董事长,曾带领金山度过最艰难时期。
1996年,金山软件遭遇前有微软、后有盗版的双重打击跌入谷底:1995年,微软进入中国市场,Windows 95与OFFICE系列抢占了WPS大部分市场份额;与此同时,一张盗版光盘,640兆囊括了市面上几乎所有主流软件,包括金山软件的产品。面对困局,金山何去何从?
雷军苦苦思考六个月,最后决定做WPS的同时,在游戏、工具软件领域发力,开始游击战、以战养战。1997年,金山推出《剑侠情缘I》、《WPS97》、《金山词霸》等等功能强大的产品,在游戏、工具软件与字处理系统领域成功制造了3个市场热点,死里逃生。
![]()
回忆这段往事,雷军曾归纳,自己最可贵的创业品质有两点:
一是目标远大,二是创业激情。
除此之外,雷军系的成功还归因于另一个重要的品质:
聚焦
。
这三个品质不仅续写着雷军本人的传奇创业故事,也在继续引领着他的各派团队创造辉煌的篇章,包括今年5月在纳斯达克上市的金山云,也包括一直低调行事的金山人工智能事业部。
雷军高度重视人工智能的发展,2017年亲自指导成立了金山人工智能事业部。这所实验室隐藏在海淀区小米科技园,集结一众顶尖技术人才,以认知AI为核心,聚焦机器翻译与阅读理解。成立不过三年左右,便已在多个国际大赛中斩获佳绩。
2020年9月6日,金山集团AI Lab的SpiderNet模型在由卡内基梅隆大学、斯坦福大学和蒙特利尔大学联合发起的多步推理阅读理解评测HotpotQA中荣登榜首,结束了长达一年的由美国科技公司包括微软、谷歌等在内的霸榜局面。
HotpotQA杀出一匹黑马
HotpotQA,又称“火锅问答”,是2018年由三名
爱吃火锅的
中国学生发布的一个
多步推理的阅读理解数据集。相较于SQuAD的任务,HotpotQA更考察关联判断能力,需要模型对给定多篇文章的内容进行深度理解,根据佐证篇章中所叙述事物的逻辑关系构建多步推理链,得到一个知识,然后通过问答的形式展示出来。
![]()
毫无疑问,像 SQuAD 这样的大规模问答数据集对利用机器阅读大量文本并回答问题取得了诸多进展。
但由于数据集上的缺陷,用这些数据集训练出来的模型并未学习到非常复杂的语言理解能力,这也正是HotpotQA希望改善的地方。
为此,HotpotQA调整了之前数据集的构建方式,除了必须使用多步推理来回答外,问题本身不会受限于任何预设的知识图谱,
对于每一个问题还收集了回答它所需要的更细粒度的支持推理线索 (supporting fact)
,并且迫使模型在回答问题的同时给出它基于哪些事实进行的推理,不像以前的模型只给出一个答案,知其然而不知其所以然。
而此前在SQuAD上竞相投入的巨头们,也将HotpotQA视为展示自己实力的新竞技场。与一群在此前从SQuAD就“相爱相杀”的巨头不同的是,金山AI Lab并未参加过SQuAD竞赛的角逐,金山此次登顶堪称黑马。
金山夺冠技术SpiderNet分析
本次金山人工智能事业部的SpiderNet模型参加的是干扰项赛道(Distractor Setting),每个问题提供10个备选篇章。
该赛道更侧重于考察模型的文本推理能力,同时也是参赛队伍最多的赛道。
SpiderNet模型采用的是深度神经网络技术,基于预训练语言模型做了改进,更注重节点与节点之间的关联与信息共享,就像一张蜘蛛网一样,专门针对文档内容进行深度理解与多步推理。
为了证明模型确实利用了原文中的相关证据进行推理并提升模型的可解释性,HotpotQA不仅要求模型给出最终答案,还要求模型给出推理所用到的佐证证据(Supporting Facts)。在评价指标上,HotpotQA评测会根据答案和佐证证据的精确匹配率(EM)和模糊匹配率(F1)求得最终的联合精确匹配率和模糊匹配率(Joint EM / F1)。
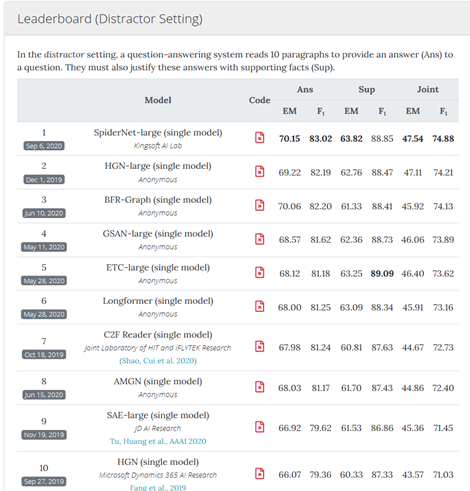
在全部6项测评中,金山SpiderNet模型有5项指标刷新纪录排名第一,1项指标排名第二,全面超越之前的冠军微软。其中,综合模糊准确率(Joint F1)更是达到74.88。
HotpotQA挑战赛(干扰项赛道)最新榜单(截至2020年9月17日)
在AI技术落地的最后一公里“后来居上”
人工智能从诞生起便几经起伏,尤其近十余年来,深度学习已大规模应用于PC互联网和移动互联网,在搜索、电商、社交等领域已经有诸多成功应用,从实验室走出的AI技术,成为产业升级的最佳推手;然而,人工智能技术落地的“最后一公里”仍然是一个难题。
“
以认知为核心的人工智能是未来社会所需要的,是能够推动社会往前进步的,也是未来发展的方向。
”谈到以认知为核心的人工智能技术的未来应用,金山人工智能事业部负责人李长亮博士满怀信心。他表示,金山集团在AI上的投入非常坚定,公司给了人工智能事业部极大的信任和资源支持。
参加HotpotQA比赛的单位不仅有斯坦福大学、华盛顿大学、卡内基梅隆大学、清华大学、北京大学等知名高校,还有来自微软、IBM、阿里达摩院、京东等企业研究机构。同样是关注认知智能技术,每个企业也会有着不同方向的应用。
在李博士看来,以认知为核心的人工智能技术将迎来前所未有的历史发展机遇。像感知智能时代出现的专注于计算机视觉的“AI四小龙”(商汤、旷视、云从、依图)一样,认知智能时代也将会出现一批优秀的企业,将人工智能技术落地惠及社会。
相对于早就涉足认知智能技术的其他巨头,金山算是后来者。但AI赋能场景之繁杂、细分市场需求之细拢,前浪虽强,也难覆盖所有行业;AI技术发展日新月异,后来者与先行者实际是在同一起跑线上。
“金山人工智能事业部成立三年以来,我们一直在坚持以认知为核心的人工智能研究,非常聚焦。”据李博士介绍,自成立以来,金山AI团队便聚焦在机器翻译、知识问答与文档智能这三个方向,目前已开发出AIDA翻译引擎、AIDA知识引擎以及AIDA文档智能处理系统。
除申请发明专利100余项、在ACM等国际顶级期刊会议上发表论文数十余篇,金山AI 团队的NLP研究已在多个国际大赛中斩获佳绩:
2018年,首次参加
创新工场AI Challenger 2018中英翻译竞赛
,凭借对层次注意力机制、高斯搜索等独特算法的创新,在「英中文本机器翻译」赛道上以客观成绩领先于其他对手3个BLEU值、答辩成绩超过其他队伍30分的极大优势在全球800支队伍中脱颖而出,一举夺冠;
2019年,出战全球学术界公认的顶级机器翻译比赛——
WMT( Workshop on Machine Translation)英中翻译竞赛
,凭借神经机器翻译(NMT)模型,击败全球50多支队伍(包括Facebook、微软、百度、剑桥大学等),获得英译中赛道人工评测冠军;同年,金山AI团队还登上
MS COCO Image Captioning
榜首,并获得了
IEEE ISI World Cup大数据竞赛
冠军。这些成绩象征着他们在自然语言理解上不断在努力和突破。
金山集团人工智能事业部的成员是一群理想青年,以“构建以认知为核心的人工智能服务”为目标。团队汇集了一大批国内外高校的优秀人才,他们大多毕业于清华、北大、中科院和剑桥、加州大学等国内外名校,有着扎实的基本功和对未来美好的憧憬(
此处彩蛋:偏好NLP与数学专业的同学~
)。
目前,金山AI团队在机器翻译模块已积累了十余种语言的双向翻译技术,包括6种联合国语言和数种我国少数民族语言(蒙语、藏语、维吾尔语等),覆盖了文学、军事、政治、财经、医疗、IT、机械等16个领域。除了对世界主流语言的研究,之所以增加对少数民语言的研究,李博士解释是希望为促进民族交流贡献一份力量。
这份责任心不仅体现在对社会的支持,还体现在对用户数据隐私的重视与保护。
依托金山30年的文档处理经验,金山AI团队在NLP研究上的优势无疑得天独厚。
数据隐私令很多用户担忧。李博士表达了保护数据安全的明确的态度:“凡是涉及到用户隐私的数据,无论获取成本多低,我们绝对不碰。”在他看来,这不仅是法律的底线,也是做研究的底线。不仅如此,李博士还提到,金山内部设有专门的数据管理团队,通过技术和制度双保险来保证数据安全问题。
2018年,BERT语言模型出来之后,机器已经能够基于较好的文本理解去解决简单的问题。2020年,GPT-3发布,又在NLP领域掀起一股小高潮。但众所周知,训练一个语言模型对算力、语料等条件的要求很高,成本也很大。如何“高性价比”地实现AI技术的最高价值?金山AI团队选择了一条“接地气”的道路
:“
我们现在也是基于预训练语言模型在开发产品,但我们没有去盲目比拼预训练语言模型,而更多是基于已有成果进行创新,与场景相结合,解决场景里的任务与需求。
”
SpiderNet模型有什么用途?
此次夺冠的SpiderNet模型可以基于对大量文档的阅读理解和深度挖掘来获取知识,满足用户在认知方面的需求。
“假如给AI一本历史书,然后提问:中华人民共和国是哪一年成立的?这种答案从技术角度来讲比较容易获取。但如果提问:中华人民共和国在成立过程中克服了哪些困难?AI在回答问题之前,便需要深入理解大量文档,并进行去推理。这就考察更深层次的智能技术。”李博士介绍道。
SpiderNet模型背后体现的是金山AI团队在机器阅读理解上所取得的突破。目前主要包括四方面的应用:合同管理、简历管理、智能问答、知识图谱一站式解决方案。
相信每个公司的行政人员都曾为合同的收录与管理发愁。如果是人工处理,则需要:
第一步,提取合同上的关键信息,比如甲乙方的身份、合同金额等。这个过程对技术要求不高,但耗时耗力。第二步,对合同进行管理,方便查询。在查询某份合同时,合同管理者往往需要凭借有限的人脑记忆,从成千上万份合同群中挨个打开、检查。这个过程同样耗时耗力。
而金山AI团队阅读理解技术可以将合同内的关键信息进行结构化提取和管理,并支持一键查询结果,做到事半功倍。
简历管理需求源于金山集团每年秋招收到的海量简历。面对上万份五花八门的简历,HR需要在短时间内进行归类整理,提取信息,压力很大。因此,金山AI 团队开发了智能简历管理系统,自动提取简历的重要信息,并对简历内容进行结构化归类和管理。。
简历没有统一规范,求职者个人经历又不尽相同,所以每份简历迥然相异。个人基本信息(毕业院校、出生年月等)提取较简单,但工作与项目经历往往描述不一,这给文档分析增加了难度。HR若想从投递者的描述内容中分析候选人的水平、特长等,就需用到自然语言处理(尤其是认知)技术。而应用阅读理解模型,对简历进行深度理解与分析,可以方便HR查询所需信息,减轻HR的工作量。
谈及如今的信息泛滥现象,李博士认为:“我们一方面被海量信息‘淹死’,一方面又因为无法找到有用信息而‘饿死”。
搜索引擎在很多情况下并不能第一时间满足人的知识获取需求。李博士表示,目前互联网上只有少部分信息可以凝练成真正有用的知识。当你想在网上获取某种知识时,不仅查找费力,查到的结果也无法保证可信度。
而金山AI 团队的AIDA知识问答引擎就致力于解决这个痛点。输入问题,一键生成问题的高可信答案。
就目前的技术而言,收集世上所有知识来建立一个通用的知识问答系统是不可能的,因此,李博士及其团队决定,先聚焦在某个特定领域来研究知识问答。目前,AIDA知识问答引擎主要围绕政经领域的智能文档挖掘和知识问答。
IDC发布的《2025 年中国将拥有全球最大的数据圈》中提到:
全球数据领域(创建、捕获、复制和使用的数字数据)将从2018年的约33 ZB增长到2025年的175 ZB(其中1ZB等于1万亿GB)。
如此庞大的数据量,对于组织与机构来讲,如不能实现有效治理与知识运用,将会成为一场信息爆炸的灾难。
信息爆炸的时代特征加之认知技术的不断发展,李博士提出了“数据熵减,知识宏加”的数据治理与知识运用愿景,并最终带领团队基于数据治理、知识构建、知识运用三个维度开发出了AIDA知识图谱一站式解决方案。
该套解决方案聚焦于数据治理、知识价值挖掘、知识应用三个维度;具备知识建模、知识抽取、知识存储、实时更新、知识应用的一站式技术服务能力。AIDA宏识知识建模可视化系统,可实现一键自动建模,支持任意领域的知识图谱节点、关系、属性的定义;AIDA宏图图谱构建可视化系统,可实现基于结构化数据与非结构化数据的知识图谱初始化构建;AIDA宏聆知识实时更新系统,支持基于结构化、非结构化数据的知识自更新,确保知识图谱的实时性,大大降低人工成本的支出;AIDA宏知知识应用解决方案,支持智能问答、智能搜索、知识库建设、循证辅助决策等多维度知识应用,支持企业定制化开发,同时具备良好的自适应能力,领域迁移成本极低。
展望未来
今年5月金山云成功上市时,各界再次将目光投向雷军系的“游击战”商业战略。
面对国内其他大厂如阿里云、腾讯云、百度云甚至华为云的激烈竞争与较劲,雷军曾公开表态:“我们的态度很低,大的巨头吃肉我们喝汤,我们甘愿当小弟。只要3-5家里面有我们,我们就一定能成功。”
同样的“低姿势、高聚焦”态度,也体现在不卑不亢的金山AI团队上。
尽管金山人工智能事业部在多个国际大赛中连连夺冠,但一直处事低调,专注于以认知为核心的人工智能研究,到默默尝试场景落地。
在如“神仙打架”般的AI角逐场上,“愣头青”一样从0开始铺垫的长线战略也许并不是明智的决定。面对各方拉架势力,站在对的巨人肩膀上,精准定位、结合实际、谋求技术应用,才是后AI时代的发展真理。
而金山AI团队的研究与努力,便一直在践行这一理念。
有远大目标,保持研究的热情,聚焦在特定的领域,相信在不久的将来,这个团队将给我们带来新的喜讯!
在10月1日头条《秋天的第一本AI书:周志华亲作森林书&贾扬清力荐天池书 | 赠书》留言区留言,谈一谈你对这两本书的看法或有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,送出《阿里云天池大赛赛题解析——机器学习篇》10本,《集成学习:基础与算法》5本,每人最多获得其中一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书,活动结束后,中奖读者将按照点赞排名由高到低的顺序优先挑选两本书中的其中一本,获得赠书的读者请添加AI科技评论官方微信(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月1日 - 2020年10月8日(23:00),活动推送内仅允许中奖一次。
![]()
点击阅读原文,直达NeurIPS小组~