【2018展望Top10】GAN应用落地,NLP急需突破

新智元推荐
来源: 人工智能头条
作者:张俊林
责编:何永灿
【新智元导读】2017年人工智能行业延续了2016年蓬勃发展的势头,那么在过去的一年里AI行业从技术发展角度有哪些重要进展?未来又有哪些发展趋势?本文从大家比较关注的若干领域作为代表,来归纳AI领域一些方向的重要技术进展。

人工智能最近三年发展如火如荼,学术界、工业界、投资界各方一起发力,硬件、算法与数据共同发展,不仅仅是大型互联网公司,包括大量创业公司以及传统行业的公司都开始涉足人工智能。
2017年人工智能行业延续了2016年蓬勃发展的势头,那么在过去的一年里AI行业从技术发展角度有哪些重要进展?未来又有哪些发展趋势?本文从大家比较关注的若干领域作为代表,来归纳AI领域一些方向的重要技术进展。
DeepMind携深度增强学习利器总是能够给人带来震撼性的技术创新,2016年横空出世的AlphaGo彻底粉碎了普遍存在的“围棋领域机器无法战败人类最强手”的执念,但是毕竟李世石还是赢了一局,不少人对于人类翻盘大逆转还是抱有希望,紧接着Master通过60连胜诸多顶尖围棋高手彻底浇灭了这种期待。
2017年AlphaGo Zero作为AlphaGo二代做了进一步的技术升级,把AlphaGo一代虐得体无完肤,这时候人类已经没有资格上场对局了。2017年底AlphaGo的棋类游戏通用版本Alpha Zero问世,不仅仅围棋,对于国际象棋、日本将棋等其他棋类游戏,Alpha Zero也以压倒性优势战胜包括AlphaGo Zero在内的目前最强的AI程序。
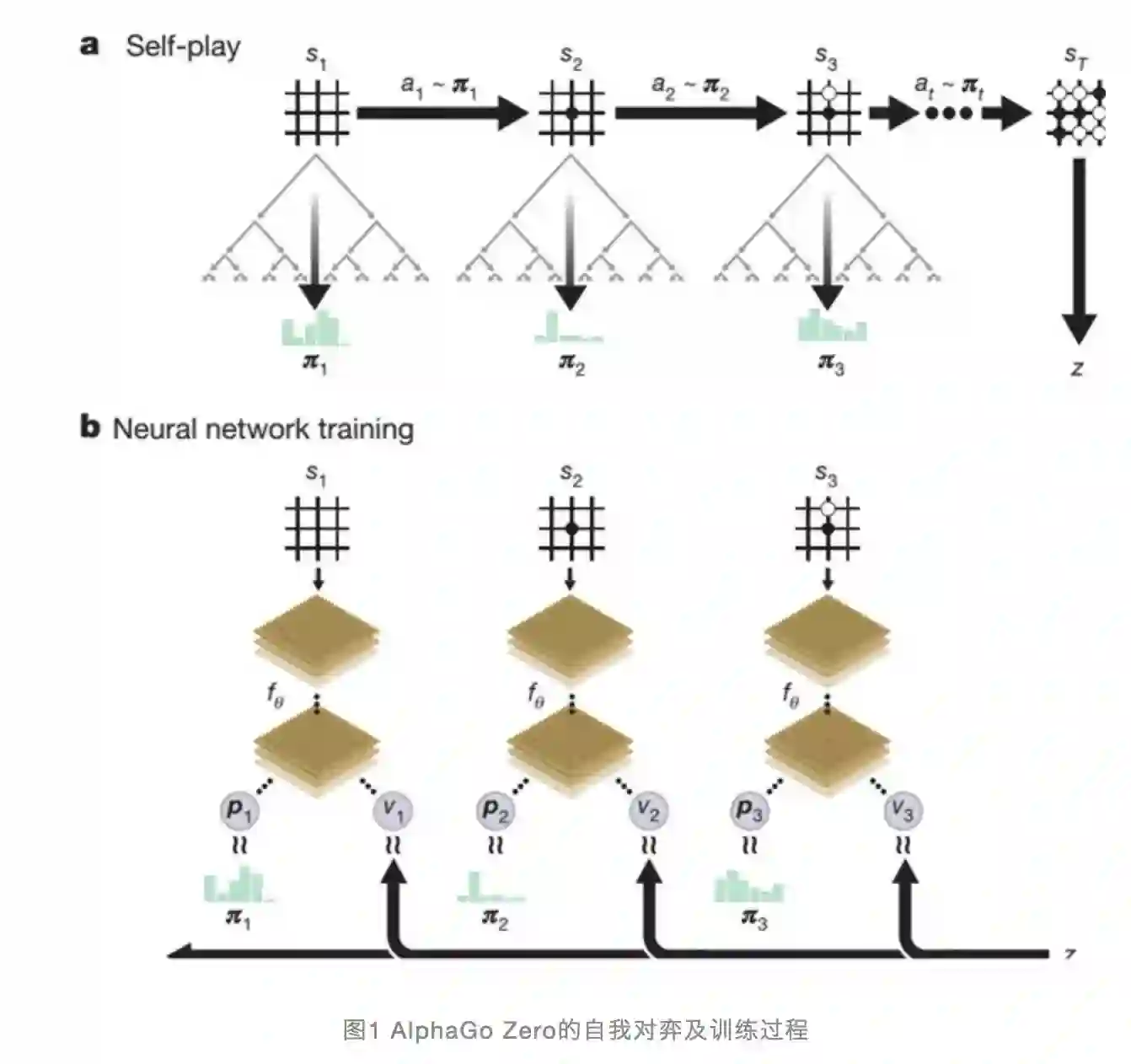
AlphaGo Zero从技术手段上和AlphaGo相比并未有本质上的改进,主体仍然是MCST蒙特卡洛搜索树加神经网络的结构以及深度增强学习训练方法,但是技术实现上简单优雅很多(参考图1)。
主要的改动包含两处:一处是将AlphaGo的两个预测网络(策略网络和价值网络)合并成一个网络,但是同时产生两类所需的输出;第二处是网络结构从CNN结构升级为ResNet。
虽说如此,AlphaGo Zero给人带来的触动和启发丝毫不比AlphaGo少,主要原因是AlphaGo Zero完全放弃了从人类棋局来进行下棋经验的学习,直接从一张白纸开始通过自我对弈的方式进行学习,并仅仅通过三天的自我学习便获得了远超人类千年积累的围棋经验。
这引发了一个之前一般人很期待但是同时又认为很难完成的问题:机器能够不依赖有监督方式的训练数据或者极少的训练数据自我进化与学习吗?如果真的能够做到这一点,那么是否意味着机器会快速进化并淘汰人类?
第二个问题甚至会引起部分人的恐慌。但是其实这个问题本身问的就有问题,因为它做了一个错误的假设:AlphaGo Zero是不需要训练数据的。首先,AlphaGo Zero确实做到了通过自我对弈的方式进行学习,但是仍然需要大量训练数据,无非这些训练数据是通过自我对弈来产生的。
而且更根本的一点是应该意识到:对于AlphaGo Zero来说,其本质其实还是MCST蒙特卡洛树搜索。围棋之所以看着难度大难以克服,主要是搜索空间实在太大,单纯靠暴力搜索完全不可行。如果我们假设现在有个机器无限强大,能够快速遍历所有搜索空间,那么其实单纯使用MCST树搜索,不依靠机器学习,机器也能达到完美的博弈状态
AlphaGo Zero通过自我对弈以及深度增强学习主要达到了能够更好地评估棋盘状态和落子质量,优先选择走那些赢面大的博弈路径,这样能够舍弃大量的劣质路径,从而极大减少了需要搜索的空间,自我进化主要体现在评估棋面状态越来越准。
而之所以能够通过自我对弈产生大量训练数据,是因为下棋是个规则定义很清晰的任务,到了一定状态就能够赢或者输,无非这种最终的赢或者输来得晚一些,不是每一步落子就能看到的,现实生活中的任务是很难达到这一点的,这是为何很多任务仍然需要人类提供大量训练数据的原因。如果从这个角度考虑,就不会错误地产生以上的疑虑。
Alpha Zero相对AlphaGo Zero则更进一步,将只能让机器下围棋拓展到能够进行规则定义清晰的更多棋类问题,使得这种技术往通用人工智能的路上迈出了重要一步。
其技术手段和AlphaGo Zero基本是相同的,只是去除掉所有跟围棋有关的一些处理措施和技术手段,只告诉机器游戏规则是什么,然后使用MCST树搜索+深度神经网络并结合深度增强学习自我对弈的统一技术方案和训练手段解决一切棋类问题。
从AlphaGo的一步步进化策略可以看出,DeepMind正在考虑这套扩展技术方案的通用性,使得它能够使用一套技术解决更多问题,尤其是那些非游戏类的真实生活中有现实价值的问题。
同时,AlphaGo系列技术也向机器学习从业人员展示了深度增强学习的强大威力,并进一步推动了相关的技术进步,目前也可以看到深度增强学习在更多领域应用的实例。
GAN,全称为Generative Adversarial Nets,直译为“生成式对抗网络”。GAN作为生成模型的代表,自2014年被Ian Goodfellow提出后引起了业界的广泛关注并不断涌现出新的改进模型,深度学习泰斗之一的Yann LeCun高度评价GAN是机器学习界近十年来最有意思的想法。
Ian Goodfellow提出的最初的GAN尽管从理论上证明了生成器和判别器在多轮对抗学习后能够达到均衡态,使得生成器可以产生理想的图像结果。但是实际上,GAN始终存在训练难、稳定性差以及模型崩塌(Model Collapse)等问题。产生这种不匹配的根本原因其实还是对GAN背后产生作用的理论机制没有探索清楚。
过去的一年在如何增加GAN训练的稳定性及解决模型崩塌方面有了可喜的进展。GAN本质上是通过生成器和判别器进行对抗训练,逼迫生成器在不知晓某个数据集合真实分布Pdata的情形下,通过不断调整生成数据的分布Pθ去拟合逼近这个真实数据分布Pdata,所以计算当前训练过程中两个分布Pdata和Pθ的距离度量标准就很关键。
Wasserstein GAN的作者敏锐地指出了:原始GAN在计算两个分布的距离时采用的是Jensen-Shannon Divergence(JSD),它本质上是KL Divergence(KLD)的一个变种。
JSD或者KLD存在一个问题:当两个分布交集很少时或者在低维流形空间下,判别器很容易找到一个判别面将生成的数据和真实数据区分开,这样判别器就不能提供有效的梯度信息并反向传导给生成器,生成器就很难训练下去,因为缺乏来自判别器指导的优化目标。
Wasserstein GAN提出了使用Earth-Mover距离来代替JSD标准,这很大程度上改进了GAN的训练稳定性。后续的Fisher GAN等模型又对Wasserstein GAN进行了进一步的改进,这些技术陆续改善了GAN的训练稳定性。
模型崩塌也是严重制约GAN效果的问题,它指的是生成器在训练好之后,只能产生固定几个模式的图片,而真实的数据分布空间其实是很大的,但是模型崩塌到这个空间的若干个点上。最近一年针对这个问题也提出了比如标签平滑、Mini-Batch判别器等启发式方法来解决生成器模型崩塌的问题并取得了一定效果。
尽管在理论层面,针对GAN存在的问题,业界在2017年提出了不少改进方法,对于GAN的内在工作机制也有了更深入的了解,但是很明显目前仍然没有理解其本质工作机制,这块还需要未来更有洞察力的工作来增进我们对GAN的理解。

GAN具备非常广泛的应用场景,比如图像风格转换、超分辨率图像构建、自动黑白图片上色、图片实体属性编辑(例如自动给人像增加胡子、切换头发颜色等属性变换),不同领域图片之间的转换(例如同一个场景春天的图片自动转换为秋天的图片,或者白天景色自动转换为夜间的景色),甚至是图像实体的动态替换,比如把一幅图片或者视频中出现的猫换成狗(参考图2)。
在推动GAN应用方面,2017年有两项技术是非常值得关注的。其中一个是CycleGAN,其本质是利用对偶学习并结合GAN机制来优化生成图片的效果的,采取类似思想的包括DualGAN以及DiscoGAN等,包括后续的很多改进模型例如StarGAN等。
CycleGAN的重要性主要在于使得GAN系列的模型不再局限于监督学习,它引入了无监督学习的方式,只要准备两个不同领域的图片集合即可,不需要训练模型所需的两个领域的图片一一对应,这样极大扩展了它的使用范围并降低了应用的普及难度。
另外一项值得关注的技术是英伟达采取“渐进式生成”技术路线的GAN方案,这项方案的引人之处在于使得计算机可以生成1024*1024大小的高清图片,它是目前无论图像清晰度还是图片生成质量都达到最好效果的技术,其生成的明星图片几乎可以达到以假乱真的效果(参考图3)。
英伟达这项由粗到细,首先生成图像的模糊轮廓,再逐步添加细节的思想其实并非特别新颖的思路,在之前的StackGAN等很多方案都采用了类似思想,它的独特之处在于这种由粗到细的网络结构是动态生成的而非事先固定的静态网络,更关键的是产生的图片效果特别好。

总而言之,以GAN为代表的生成模型在2017年无论是理论基础还是应用实践都产生了很大的技术进展,可以预计的是它会以越来越快的速度获得研发人员的推动,并在不远的将来在各个需要创造性的领域获得广泛应用。
Capsule今年才以论文的形式被人称“深度学习教父”的Hinton老先生发表出来,而且论文一出来就成为研究人员关注的焦点,但是其实这个思想Hinton已经深入思考了很久并且之前在各种场合宣传过这种思路。
Hinton一直对CNN中的Pooling操作意见很大,他曾经吐槽说:“CNN中使用的Pooling操作是个大错误,事实上它在实际使用中效果还不错,但这其实更是一场灾难”。那么,MaxPooling有什么问题值得Hinton对此深恶痛绝呢?参照图4所示的例子可以看出其原因。
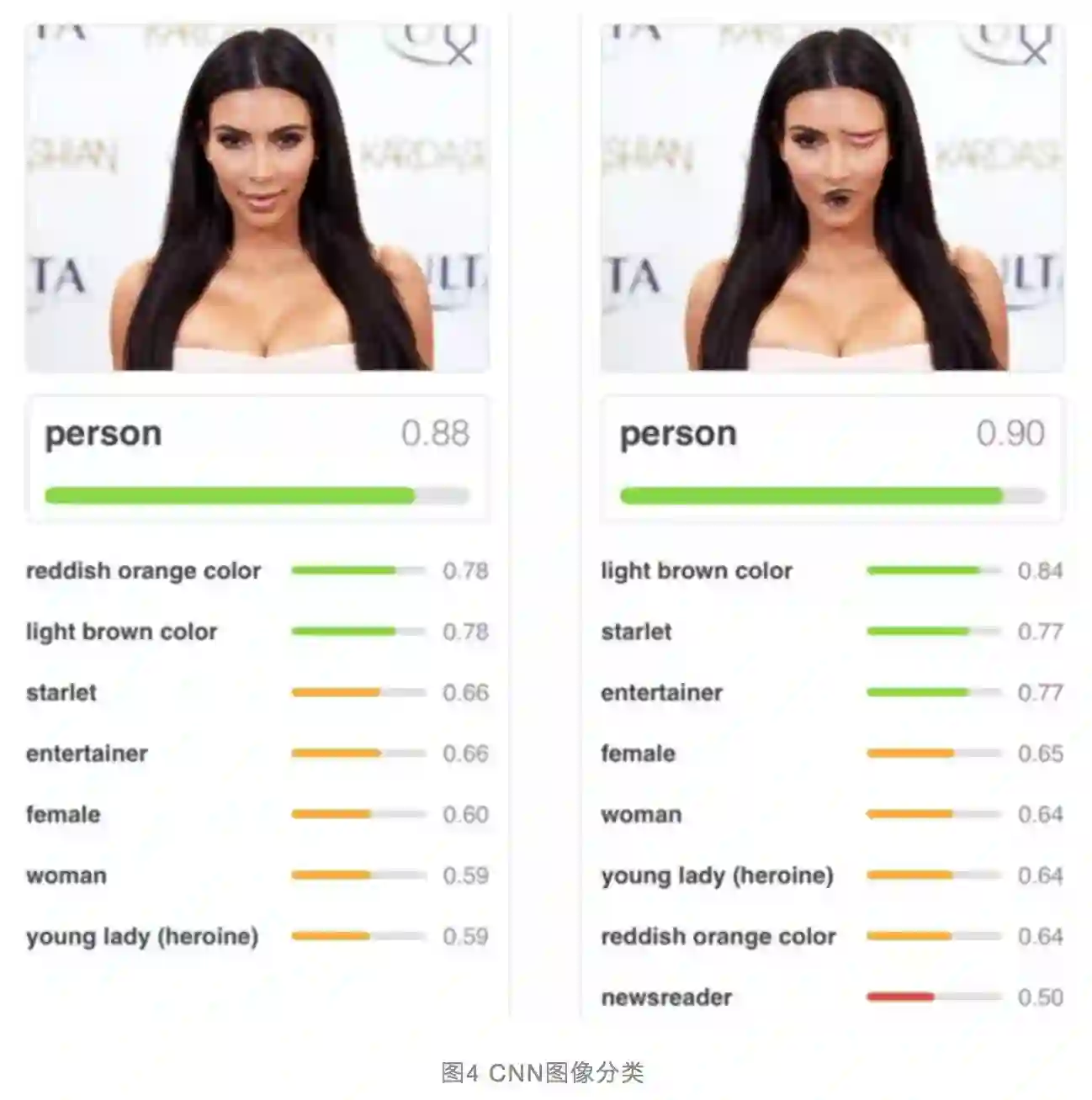
在上面这张图中,给出两张人像照片,通过CNN给出照片所属类别及其对应的概率。第一张照片是一张正常的人脸照片,CNN能够正确识别出是“人类”的类别并给出归属概率值0.88。第二张图片把人脸中的嘴巴和眼睛对调了下位置,对于人来说不会认为这是一张正常人的脸,但是CNN仍然识别为人类而且置信度不降反增为0.90。
为什么会发生这种和人的直觉不符的现象?这个锅还得MaxPooling来背,因为MaxPooling只对某个最强特征做出反应,至于这个特征出现在哪里以及特征之间应该维持什么样的合理组合关系它并不关心,总而言之,它给CNN的“位置不变性”太大自由度,所以造成了以上不符合人类认知的判断结果。
在Capsule的方案中,CNN的卷积层保留,MaxPooling层被拿掉。这里需要强调的是,Capsule本身是一种技术框架,并不单单是具体的某项技术,Hinton论文给出的是最简单的一种实现方法,完全可以在遵循其技术思路情况下创造全新的具体实现方法。
要理解Capsule的思路或者对其做一个新的技术实现其实也不困难,只要理解其中的几个关键环节就能实现此目的。如果用一句话来说明其中的关键点的话,可以用“一个中心,两个基本点”来概括。
这里的一个中心,指的是Capsule的核心目的是希望将“视角不变性”能力引入图像处理系统中。所谓“视角不变性”,指的是当我们给3D物体拍照片的时候,镜头所对的一定是物体的某个角度看上去的样子,也就是2D照片反映3D物体一定是体现出了镜头和3D物体的某个视角角度,而不是360度的物体全貌。
那么,要达到视角不变性,就是希望给定某个物体某个角度的2D照片,当看到另外一张同一物体不同视角的2D照片时,希望CNN也能识别出其实这仍然是那个物体。这就是所谓的“视角不变性”(参照图5,上下对应的图片代表同一物体的不同视角),这是传统的CNN模型很难做好的事情。

至于说两个基本点,首先第一个基本点是:用一维向量或者二维数组来表征一个物体或者物体的某个部件。传统的CNN尽管也能用特征来表征物体或者物体的构成部件,但是往往是通过不同层级的卷积层或者Pooling层的某个神经元是否被激活来体现图像中是否具备某个特征。
Capsule则考虑用更多维的信息来记载并表征特征级别的物体,类似于自然语言处理中使用Word Embedding表征一个单词的语义。这样做的好处是描述物体的属性可以更加细致,比如可以将物体的纹理、速度、方向等作为描述某个物体的具体属性。
第二个基本点是:Capsule不同层间神经元之间的动态路由机制,具体而言是低层神经元向高层神经元传递信息时的动态路由机制。低层特征向高层神经元进行动态路由本质上是要体现如下思想:构成一个物体的组成部件之间会通过协同地相互加强的方式来体现这种“整体-组成部分”的关系,比如尽管图片的视角发生了变换,但是对一个人脸来说,嘴和鼻子等构成人脸的构件会协同地发生类似的视角变换,它们仍然组合在一起构成了从另外一个视角看过去的人脸。
如果从本质上来说,动态路由机制其实是组成一个物体的构件之间的特征聚类,通过聚类的方式把属于某个物体的组成部分动态地自动找出来,并建立特征的“整体-部分”的层级构成关系(比如人脸是由鼻子、嘴、眼睛等部件构成)。
以上所述的三个方面是深入理解Capsule的关键。Capsule的论文发出来后引发了大量的关注和讨论,目前关于Capsule计算框架,大部分人持赞赏的态度,当然也有一些研究人员提出了质疑,比如论文中采用的MINST数据集规模小不够复杂、Capsule的性能优势不明显、消耗较多内存计算速度慢等。
但是无论这项新计算框架能否在未来取代CNN标准模型,抑或它很快会被人抛弃并遗忘,Hinton老先生这种老而弥坚的求真治学态度,以及勇于推翻自己构建的技术体系的勇气,这些是值得所有人敬佩和学习的。
CTR预估:向深度学习进行技术升级
CTR预估作为一个偏应用的技术方向,对于互联网公司而言应该是最重要也最关注的方向之一。道理很简单,目前大型互联网公司绝大多数利润都来源于此,因为这是计算广告方向最主要的技术手段。
从计算广告的角度讲,所谓CTR预估就是对于给定的用户User,在特定的上下文Context下,如果展示给这个用户某个广告或者产品Product,估算用户是否会点击这个广告或者是否会购买某个产品,即求点击概率P (Click|User,Product,Context)。可以看到,这是个适用范围很广的技术,很多推荐场景以及包括目前比较火的信息流排序等场景都可以转换为CTR预估问题。
CTR预估常用的技术手段包括演进路线一般是按照:“LR→GBDT等树模型→FM因子分解机模型→深度学习”这个路径来发展的。深度学习在图像视频、语音、自然语言处理等领域最近几年获得了飞速的进展,但是最近一两年学术界才开始比较频繁地陆续出现深度学习如何和CTR预估相结合的文章。
Google最早在几年前就开始研究这方面的内容,之后国内的大型互联网公司也开始跟进。
CTR预估场景有自己独特的应用特点,而想要用深度学习解决CTR预估问题,必须考虑如何融入和体现这些特点。我们知道,DNN模型便于处理连续数值型特征,而图像语音等天然满足这一条件,但是CTR预估场景会包含大量的离散特征,比如一个人的性别、毕业学校等都属于离散特征。
所以用深度学习做CTR预估首先要解决的问题是如何表征离散特征,一种常见的方法是把离散特征转换为Onehot表示,但是在大型互联网公司应用场景下,特征维度都是百亿以上级别的,如果采用Onehot表征方式,意味着网络模型会包含太多参数需要学习。
所以目前主流的深度学习解决方案都采用将Onehot特征表示转换为低维度实数向量(Dense Vector,类似于NLP中的Word Embedding)的思路,这样可以大量降低参数规模。
另外一个CTR关注的重心是如何进行自动特征组合的问题,因为好的特征组合对于性能影响非常关键,而深度学习天然具有端对端的优势,所以这是神经网络模型能够自然发挥作用的地方,能够无需人工介入自动找到好的特征组合,这一般体现在深度CTR模型的Deep网络部分。
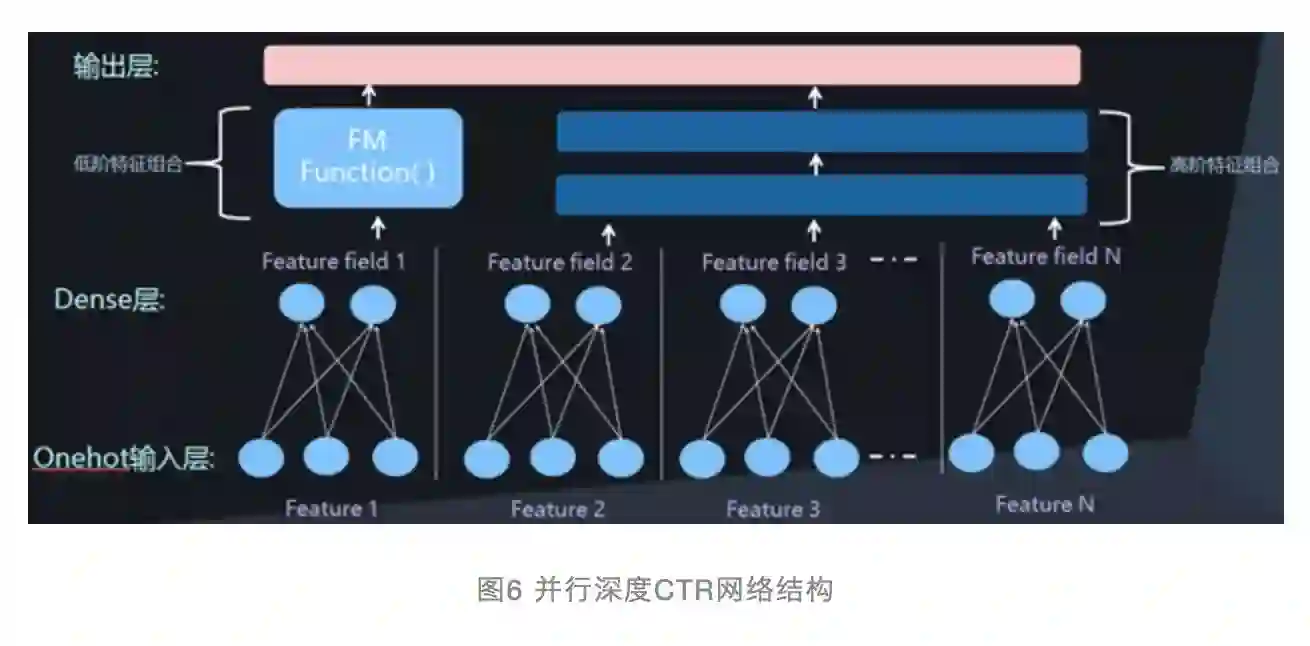
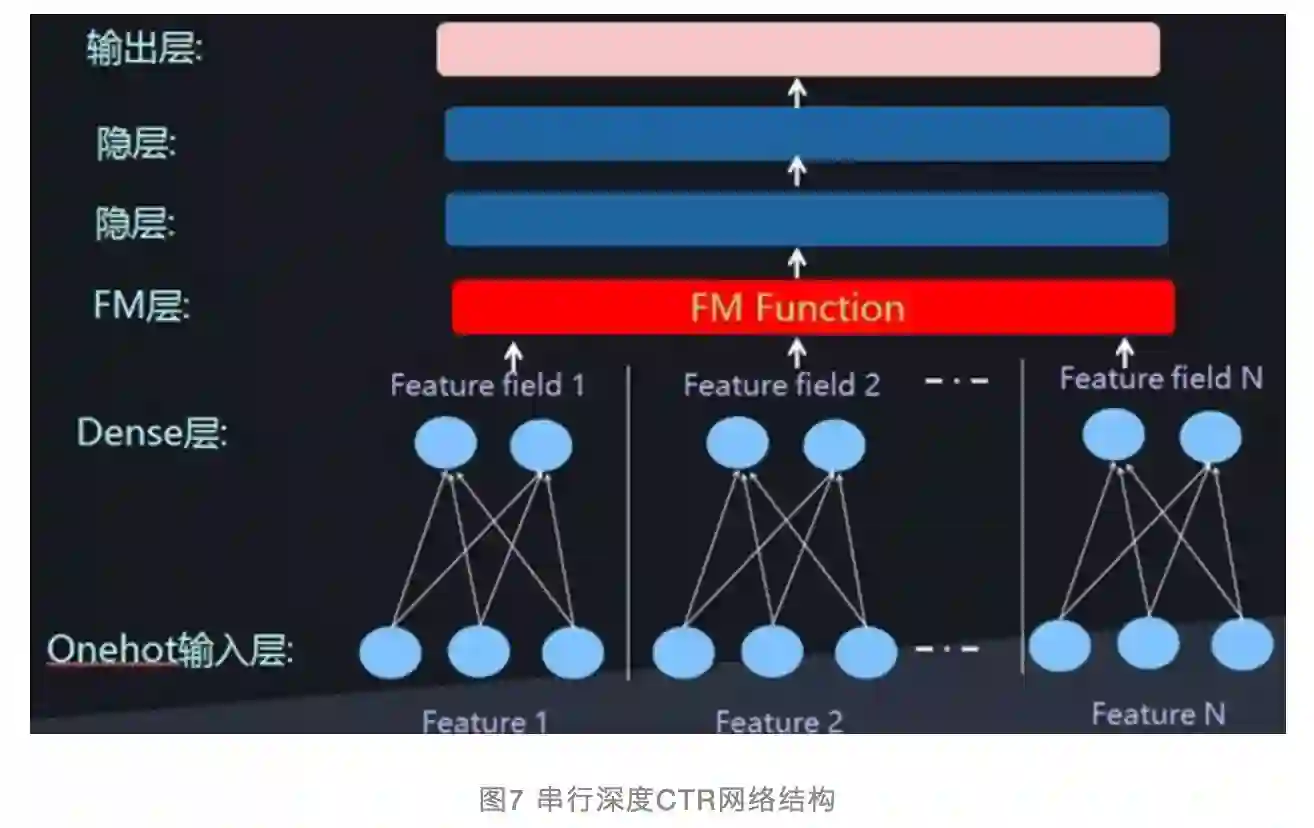
除了更早一些的流传甚广的Wide&Deep模型,最近一年出现了一些新的深度CTR模型,比如DeepFM、DeepCross、NFM模型等。这些模型其实如果仔细进行分析,会发现它们在网络结构上存在极大的相似性。
除了在网络结构上体现上述的两个特点:一个是Dense Vector表示离散特征,另外一个是利用Deep网络对特征组合进行自动建模外。另外一个主流的特点是将低维特征组合和高维特征组合在网络结构上进行分离,Deep网络体现高维度特征组合,而引入神经网络版本的FM模型来对两两特征组合进行建模。
这三个网络结构特点基本囊括了目前所有深度CTR模型。图6和图7是两种常见的深度CTR网络结构,目前所有模型基本都采用了其中之一种结构。
计算机视觉是AI领域最重要的研究方向之一,它本身又包含了诸多的研究子领域,包括物体分类与识别、目标检测与追踪、语义分割、3D重建等一些基础方向,也有超分辨率、图片视频描述、图片着色、风格迁移等偏应用的方向。目前计算机视觉处理的主流技术中,深度学习已经占据了绝对优势地位。
对于物体识别、目标检测与语义分割等基础研究领域来说,Faster R-CNN、SSD、YOLO等技术仍然是业界最先进最主流的技术手段。
在2017年新出现的重要技术中,Facebook的何恺明等提出的Mask R-CNN获得ICCV2017的最佳论文,它通过对Faster R-CNN增加分支网络的改进方式,同时完成了物体识别、目标检测与语义分割等基础任务,这展示了使用同一套技术同时解决多个基础领域问题的可能性,并会促进后续相关研究的继续深入探索;
而YOLO9000以及同样是何恺明团队在论文“Learning to Segment Every Thing”提出的MaskX R-CNN则体现了基础领域的另外一个重要发展趋势:尝试通过技术手段自动识别出更多种类的物品,终极目标是能够识别任何物体。
目前MaskX R-CNN能够识别超过3000种类别物体,而YOLO9000则能够识别超过9000种物体类别。很明显,目标检测要在各种现实领域大规模获得使用,除了速度快、识别精准外,能够大量识别各种现实生活中各种各样的物体类别也是至关重要的,而最近一年的研究在这方面产生了重要的进展。
从网络模型结构来说,2017年并未产生类似之前ResNet这种产生巨大影响的新模型,ResNet因为其明显的性能优势已经广泛使用在视觉处理的各个子领域中。虽说DenseNet获得了CVPR2017最佳论文,但它本质上是对ResNet的改进模型,并非全新思路的新模型。
除了上述所说的视觉处理的基础研究领域,如果对2017年的新技术进行归纳的话,在很多其他应用领域也可以看到如下的一些明显发展趋势:
首先,增强学习与GAN等新技术开始被尝试用来解决很多其它的图像处理领域的问题并取得了一定进展,比如Image-Caption、超分辨率、3D重建等领域,开始尝试引入这些新技术。
另外,深度学习与传统方法如何集成各自的优点并深度融合也是最近一年来视觉处理的方向,深度学习技术具有性能优异等优点,但也存在黑箱不可解释以及理论基础薄弱等缺点,而传统方法具备理论完备等优势,结合两者来充分发挥各自优势克服自身缺点是很重要的。
再次,弱监督、自监督或者无监督的方法在各个领域也越来越重要,这是有现实需求的,深度学习虽然效果好,但是对于大量标注训练数据是有要求的,而这又需要大量的标注成本,在现实中往往不可行。而探索弱监督、自监督甚至无监督的方法有助于更快促进各个领域研究的快速发展。
自然语言处理也是人工智能的重要方向之一,最近两年深度学习也已经基本渗透到了自然语言处理的各个子领域并取得了一定进展,但是与深度学习在图像、视频、音频、语音识别等领域取得的强势进展相比,深度学习带给自然语言处理的技术红利相对有限,相比传统方法而言,其效果并未取得压倒性的优势。
至于产生这种现象的原因其实是个值得深入探讨的问题,关于其原因目前众说纷纭,但并未有特别有说服力的解释能够被大多数人所接受。
与一年甚至两年前相比,目前在自然语言处理领域应用的最主流深度学习基本技术工具并未发生巨大变化,最主流的技术手段仍然是以下技术组合大礼包:Word Embedding、LSTM(包括GRU、双向LSTM等)、Sequence to Sequence框架以及Attention注意力机制。
可以在大量自然语言处理子领域看到这些技术构件的组合及其改进的变体模型。CNN在图像领域占据压倒性优势,但是自然语言处理领域仍然是RNN主导的局面,尽管Facebook一直大力倡导基于CNN模型来处理自然语言处理,除了在大规模分布式快速计算方面CNN确实相对RNN具备天然优势外,目前看不出其具备取代RNN主导地位的其它独特优势。
最近一年深度学习在自然语言处理领域应用有以下几个值得关注的发展趋势。
首先,无监督模型与Sequence to Sequence任务的融合是个很重要的进展和发展方向,比如ICLR 2018提交的论文“Unsupervised Machine Translation Using Monolingual Corpora Only”作为代表的技术思路,它使用非对齐的双语训练语料集合训练机器翻译系统并达到了较好的效果。这种技术思路本质上是和CycleGAN非常类似的,相信这种无监督模型的思路在2018年会有大量的跟进研究。
其次,增强学习以及GAN等最近两年比较热门的技术如何和NLP进行结合并真正发挥作用是个比较有前景的方向,最近一年开始出现这方面的探索并取得了一定进展,但是很明显这条路还没有走通,这块值得继续进行深入探索。
再次,Attention注意力机制进一步广泛使用并引入更多变体,比如Self Attention以及层级Attention等,从Google做机器翻译的新论文“Attention is all you need”的技术思路可以明显体会这个趋势。另外,如何将一些先验知识或者语言学相关的领域知识和神经网络进行融合是个比较流行的研究趋势,比如将句子的句法结构等信息明确引入Sequence to Sequence框架中等。
除此外,神经网络的可解释性也是一个研究热点,不过这一点不仅仅局限在NLP领域,在整个深度学习领域范围也是非常关注的研究趋势。
本文选择了若干具有较高关注度的AI技术领域来阐述最近一年来该领域的重要技术进展,受作者能力以及平常主要关注领域的限制,难免挂一漏万,很多方面的重要技术进展并未列在文中,比如Google在力推的TPU为代表的AI芯片技术的快速发展,让机器自动学习设计神经网络结构为代表的“学习一切”以及解决神经网络黑箱问题的可解释性等很多重要领域的进展都未能在文中提及或展开,这些都是非常值得关注的AI技术发展方向。
过去的一年AI很多领域发生了重大的技术进展,也有不少领域前进步伐缓慢,但是不论如何,本文作者相信AI在未来的若干年内会在很多领域产生颠覆目前人类想象力的技术进步,让我们期待这一天早日到来!
作者简介:
张俊林,中科院软件所博士,曾担任阿里巴巴、百度、用友等公司资深技术专家及技术总监职位,目前在新浪微博AI实验室担任资深算法专家,关注深度学习在自然语言处理方面的应用。
本文经授权转载自人工智能头条
作者张俊林,责编何永灿
点击阅读原文查看更多
新智元编辑:弗朗西斯

加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信aiera2015入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享AI+开放平台



