揭开YouTube深度推荐系统模型Serving之谜
揭开YouTube深度推荐系统模型
Serving之谜
这里是「王喆的机器学习笔记」的第十二篇文章,今天我们着手来彻底解决一个许久以来悬而未决的问题,也至少有十几位专栏读者通过留言和私信的方式询问我这个问题,这个问题就是YouTube深度学习推荐系统中模型serving的问题。

不了解YouTube深度学习推荐系统的同学可以回顾一下我之前的两篇专栏文章,以及YouTube的论文原文:
1.王喆:重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文
2.王喆:YouTube深度学习推荐系统的十大工程问题
3.[Youtube] Deep Neural Networks for YouTube Recommendations (Youtube 2016)
这里我们再详细陈述一下这个问题:
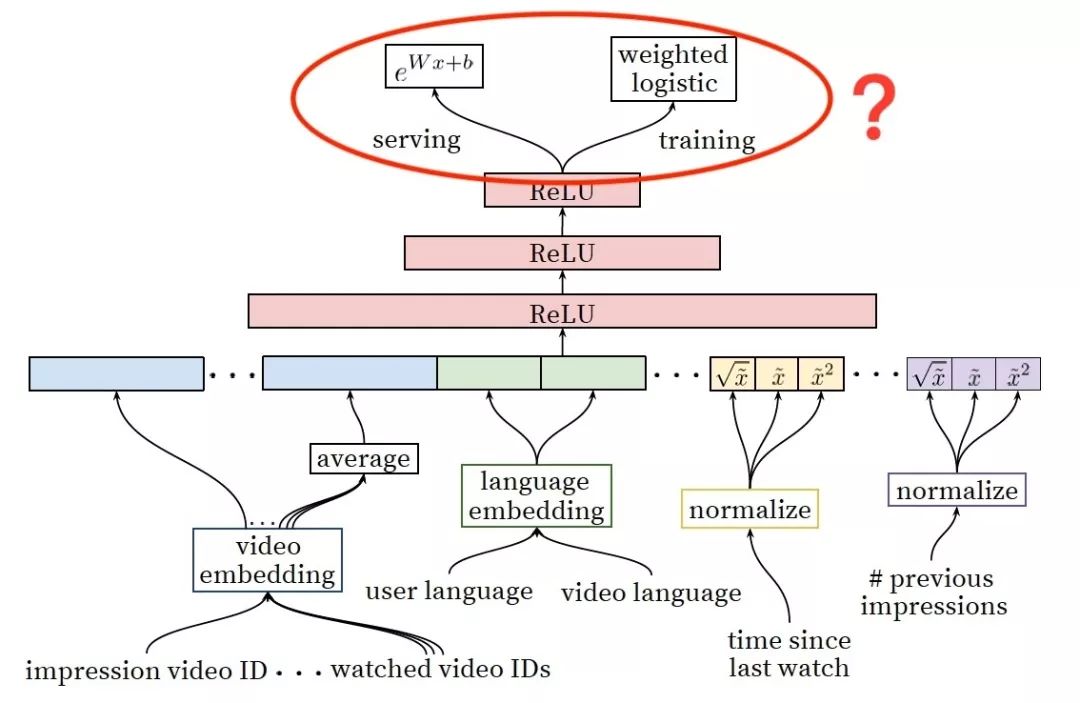
YouTube深度学习推荐系统中Ranking Model的架构图
上图是YouTube推荐系统排序模型(Ranking Model)的架构图,我们不再重复讲解模型的细节,而是把关注的焦点放在最后的输出层:

对于传统的深度学习架构,输出层往往采用LR或者Softmax,在线上预测过程中,也是原封不动的照搬LR或者softmax的经典形式来计算点击率(广义地说,应该是正样本概率)。


搞清楚这件事情并不是一件容易的事情,我们要从逻辑回归的本质意义上开始。
几乎所有算法工程师的第一堂课就是逻辑回归,也肯定知道逻辑回归的数学形式就是一个线性回归套sigmoid函数:
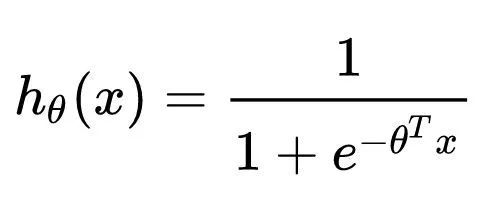
逻辑回归的数学形式
但为什么选择sigmoid函数?难道仅仅是sigmoid函数能把值域映射到0-1之间,符合概率的物理意义这么简单吗?
答案显然不会这么肤浅。
为解释这个问题,首先我们需要定义一个新的变量——Odds,中文可以叫发生比或者机会比。
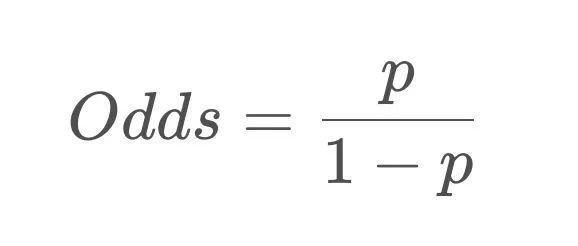
Odds的定义
假设一件事情发生的概率是p,那么Odds就是一件事情发生和不发生的比值。
如果对Odds取自然对数,再让ln(Odds)等于一个线性回归函数,那么就得到了下面的等式。
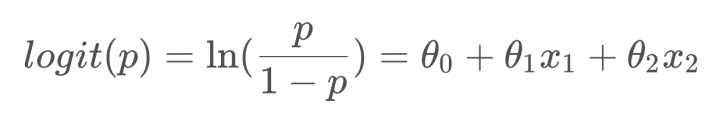
其中ln(p/(1-p))就是大名鼎鼎的logit函数,logistics regression又名logit regression,上面的式子就是逻辑回归的由来。我们再做进一步运算,就可以转变成我们熟悉的逻辑回归的形式:
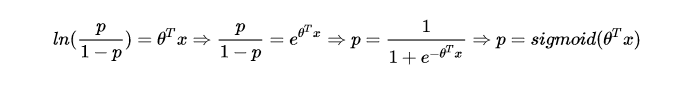
到这里大家应该已经完全明白了LR的推导过程了。

但我们还没有到达终点,因为Youtube要预测的明明是用户观看时长,怎么就成了Odds了?
这就要提到YouTube采用的独特的训练方式Weighted LR,这里的Weight,对于正样本i来说就是观看时长Ti,对于负样本来说,则指定了单位权重1。
Weighted LR的特点是,正样本权重w的加入会让正样本发生的几率变成原来的w倍,也就是说样本i的Odds变成了下面的式子:

由于在视频推荐场景中,用户打开一个视频的概率p往往是一个很小的值,因此上式可以继续简化:
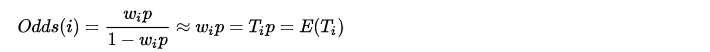
而且由于YouTube采用了用户观看时长Ti作为权重,因此式子进一步等于Ti*p,这里真相就大白了,由于p就是用户打开视频的概率,Ti是观看时长,因此Ti*p就是用户观看某视频的期望时长!

最后,再简要总结一下YouTube Ranking Model的Serving过程要点。

希望这篇文章能够终结大家对于YouTube模型Serving问题的疑惑,如果有不明白的同学,欢迎大家在知乎专栏或者我的微信公众号 “王喆的机器学习笔记”(wangzhenotes)留言讨论,想进一步交流的同学也可以通过我的公众号加我的个人微信一同探讨,谢谢。
本文转自公众号“王喆的机器学习笔记”,作者王喆




