Label Assign:提升目标检测上限
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
最近因为AutoAssign这篇paper的原因,再加上之前对目标检测中label assign问题很感兴趣, 看了几篇label assign相关论文(FreeAnchor、ATSS、AutoAssign),梳理一下几篇论文的关系做个记录~
我用一张图大致梳理出几个label assign相关论文的关系:
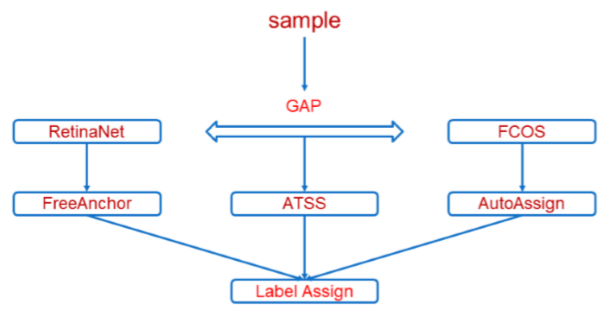
FreeAnchor、ATSS、AutoAssign都是Label Assign方面的改进。ATSS提出RetinaNet和FCOS的gap主要源于采样方式的不同,ATSS提出更好的Label Assign,来缩小RetinaNet和FCOS的差距,FreeAnchor在RetinaNet的基础上提出更好的Label Assign,AutoAssign在FCOS的基础上提出更好的Label Assign。
RetinaNet是Anchor-based经典算法,FCOS是Anchor-Free的经典算法,FCOS在RetinaNet的基础上,去掉anchor先验,转变成point先验,同时增加了center-ness分支来去除低质量的point采样。相关的算法细节可以看我之前的笔记
ReinaNet和FCOS主要有三点不同:
1.每个位置的先验数量不同。RetinaNet每个位置有几个anchor先验,而FCOS每个位置只有一个point先验。
2.正负样本的采样方式不同。RetinaNet通过IOU来选择正负样本,而FCOS通过空间和尺度的约束来选择正负样本。
3.回归的起始点不同。RetinaNet回归的起始点是筛选过的anchor box,而FCOS回归的起始点是筛选过的point box。
Inconsistency Removal
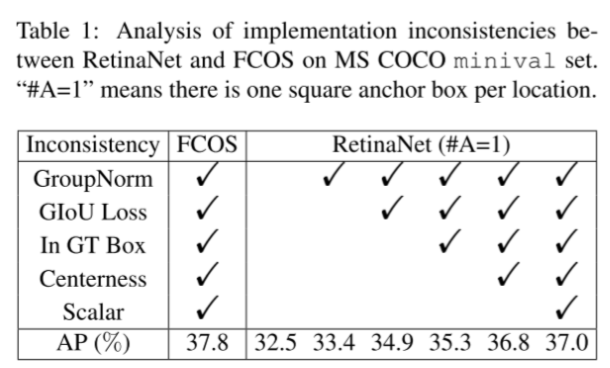
FCOS相比于只设置一个anchor先验的RetinaNet来说,COCO数据集上的mAP高差不多5个点,为了公平的比较RetinaNet和FCOS的精度差异的原因,ATSS的paper中用一致的trick对RetinaNet和FCOS进行实验。如实验所示,相同trick设置下,RetinaNet比FCOS少0.8个点,这时RetinaNet和FCOS的差别仅仅在于采样方式和回归起点的不同。
Essential Difference
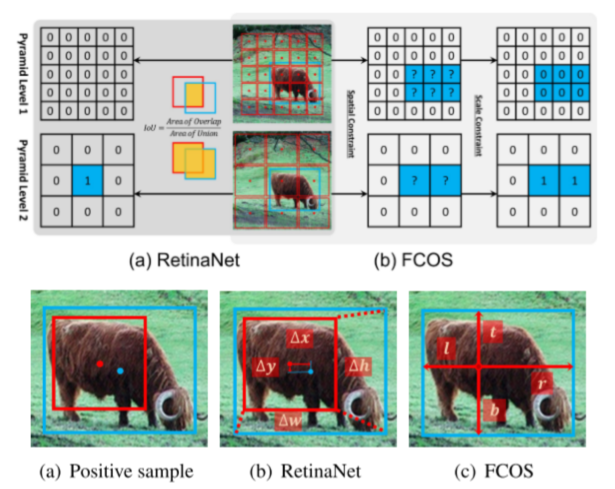
为了进一步探究采样方式和回归起点对于精度的影响,ATSS中对RetinaNet和FCOS排列组合了四种实验进行比较。

ATSS
ATSS的paper中进而提出了一种更加合适的label assign方式,称为ATSS。
ATSS吸收了RetinaNet和FCOS的采样方式的优点,ATSS采样方式如下:
1.基于anchor box和ground-truth的中心点距离选择候选正样本
2.使用候选anchor box的mean和std之和作为IOU阈值自适应的挑选候选正样本
3.通过候选正样本中心是否落在ground-truth内筛选出最终的正样本
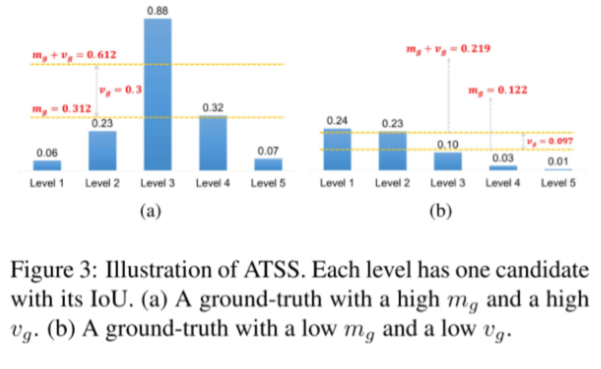
下图中显示出了ATSS对于不同分布的样本可以自适应的调整阈值,挑选到合适尺度下的正样本。
自适应阈值为:
FreeAnchor
将检测训练过程看成一个极大似然估计问题
构造极大似然估计问题的recall和precision似然函数
转变成损失函数
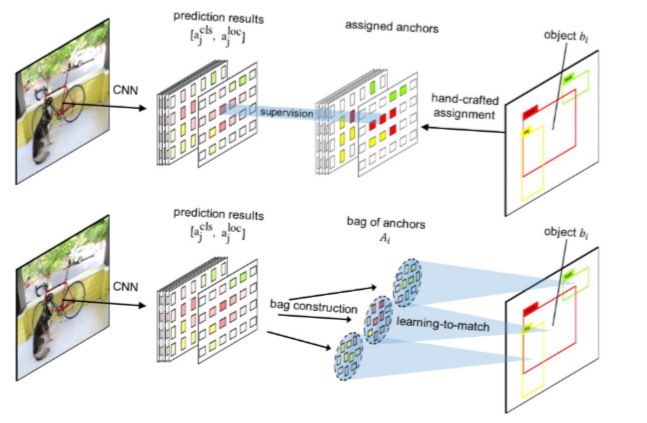
FreeAnchor在RetianNet的基础上,将检测器的训练过程定义成一个极大似然估计问题,通过优化recall和precision似然函数的loss,自适应的将匹配的anchor构建成bag of anchors。
将检测看成一个极大似然估计问题的好处是可以不用平衡分类和定位分支,通过一个loss来监督检测器的训练,并且可以自适应的调整匹配的anchor。
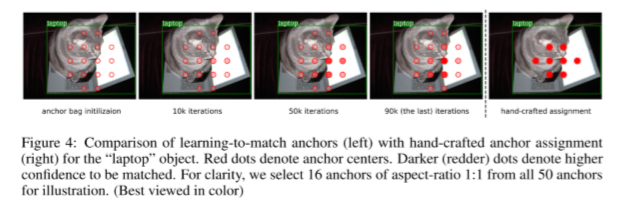
如下图所示,随着训练的进行,检测器挑选出匹配的anchor。
AutoAssign

最近的AutoAssign在FCOS的基础上,通过引入ImpObj、Center Weighting和Confidence Weighting三个分支,将FCOS中根据空间和尺度定义正负样本的方式和center-ness分支都去掉,将label assign做的更加彻底,完完全全通过CNN学习自适应的label assign方式。
借鉴了作者的理解:https://zhuanlan.zhihu.com/p/158907507
From VanillaDet to AutoAssign
VanillaDet 是指:对于一个 gt box,所有在这个 gt box 内的位置(所有 FPN 层都包含在内),都是这个 gt 的正样本;反之,所有不落在 gt 框内部的位置都是负样本。可以理解为label assign的下限。
从实验结果可知,更好的label assign方式可以大幅度提升检测器的精度。
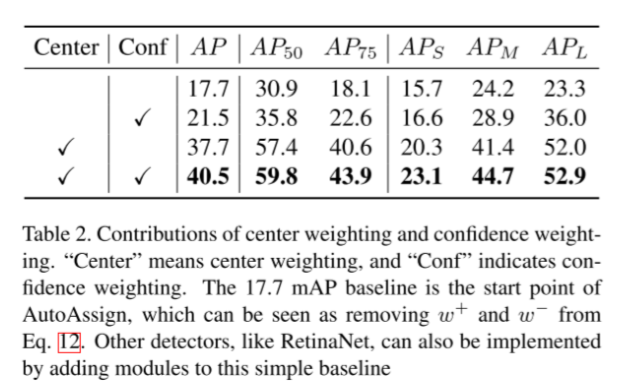
Center Weighting
引入高斯中心先验,通过与gt中心点的距离学习出不同类别自适应的中心先验
Confidence Weighting
通过ImpObj分支来避免引入大量背景位置
与FreeAnchor相似,将分类和定位联合看成极大似然估计问题,学习出样本的置信度
Positive Weights
通过Center Weighting和Confidence Weighting得到Positive weights
Neative Weights
通过最大IOU得到Negative weights
对于前景和背景的 weighting function,有一个共同的特点是 “单调递增”;也就是说,一个位置预测 pos / neg 的置信度越高,那么他们当多前景 / 背景的权重就越大。
Loss Function
Positive weights和Negative weights在训练过程中动态调整达到平衡,像是在学一个正负样本的决策边界,而根据IOU阈值来定义正负样本的决策边界是人为定义的。
Ablation Studies
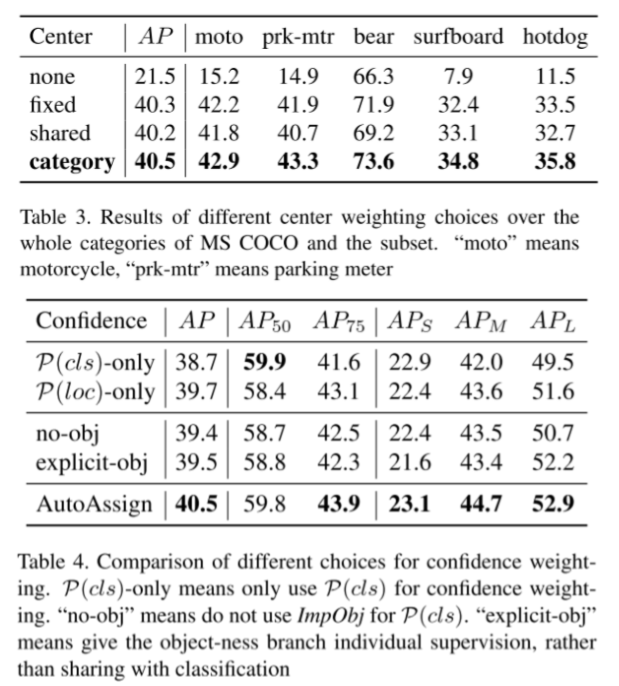
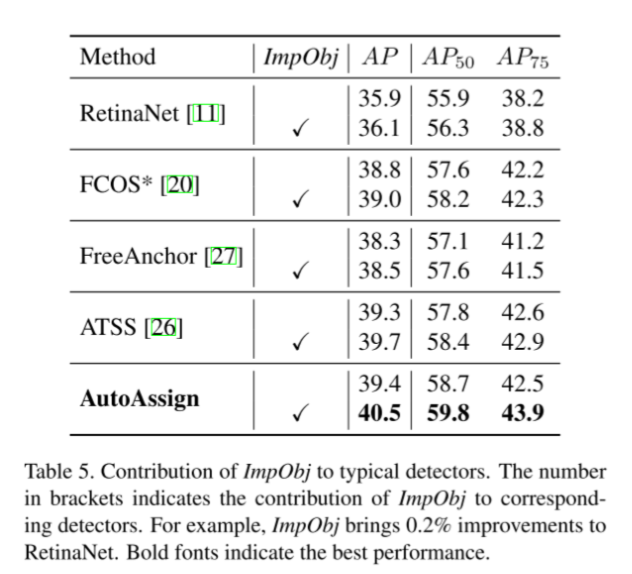
通过消融实验可以看出,引入的3个分支对检测器都有提升。
Visualization

一些想法
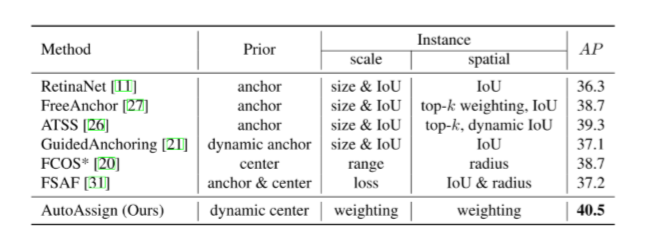
其实早期也有很多探索label assign相关的paper,比如RPN、FPN、cascade-RCNN、IoU-Net等等,但是这些文章基本上还是在anchor先验的框架下,hand-craft的采样方式设置空间和尺度,最近出现了很多通过CNN自适应学习出适合样本的采样方式,比如GuidedAnchor、MetaAnchor、FSAF、PISA等等,但是都没有很好的解决label assign问题,还是存在一些敏感参数的设置。AutoAssign整体的设置感官上还是略显复杂,但是避免了大量超参数的设置,使得检测器更加鲁棒。
目标检测任务是介于分类和分割之间,比起分类可以进一步定位出位置,比起分割标注更为简单,但是会不可避免的引入无关的背景信息,这就导致了目标检测器对于正负样本采样格外敏感,anchor机制的引入正是为了更好的定位目标但是不可避免的引入了label assign问题,如何定义正负样本显的格外重要,单纯的通过IOU阈值来区分正负样本过于hard,直觉上来讲,目标检测任务的label assign应该是一种连续问题,没有真正意义上的正负样本之分,简单的根据IOU阈值定义正负样本,这样会将一个连续的label assign问题变成了一个离散的label assign问题,无法根本性解决目标检测的label assign问题。最新的几种label assign方法本质上是将目标检测的label assign设计成连续的自适应label assign。如何更好的学习正负样本的决策边界是关键。期待出现比AutoAssign更加简洁的label assign的方法!
参考资料
poodar.chu:From VanillaDet to AutoAssign,https://zhuanlan.zhihu.com/p/158907507
RetinaNet,https://arxiv.org/abs/1708.02002
FCOS,https://arxiv.org/abs/1904.01355
FreeAnchor,http://arxiv.org/abs/1912.02424
ATSS,http://arxiv.org/abs/2006.07733
AutoAssign,http://arxiv.org/abs/2007.03496






