NIPS 2018论文解读 | 基于条件对抗网络的领域自适应方法


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
作者丨王晋东
学校丨中国科学院计算技术研究所博士生
研究方向丨迁移学习和机器学习
这篇论文即将发表于 NIPS 2018(现在应该叫 NeurIPS 了),作者是清华大学的龙明盛团队。论文研究的还是领域自适应(Domain Adaptation)这一热点问题,在一些公共的数据集中,本文的方法取得了当前最优的结果。


论文动机
Domain Adaptation 问题一直以来是迁移学习和计算机视觉领域等的研究热点。从传统方法,到深度方法,再到最近的对抗方法,都在尝试解决此问题。作者在本文中提出,现在的对抗方法面临两个挑战:
一是当数据特征具有非常复杂的模态结构时,对抗方法无法捕获多模态的数据结构,容易造成负迁移。通俗点说就是,现有的方法没有抓住深度特征之间的关系,只是把它们一股脑进行对抗适配。
二是当上面的问题存在时,domain classifier 就很容易出错,所以造成迁移效果不好。
论文方法
本文提出了基于条件对抗网络的领域自适应方法,英文名叫做 Conditional Adversarial Domain Adaptation。从题目中不难看出,主要由 Condition + Adversarial + Adaptation 这三部分构成。
进行 condition 的时候,用到了一个叫做 multilinear map 的数学工具,主要是来刻画多个特征和类别之间的关系。下面我们分别进行描述。
对抗网络基本结构
发表于 ICML 2015 的经典文章 Unsupervised domain adaptation by backpropagation [1] 中提出了用对抗的思想进行 Domain Adaptation,该方法名叫 DANN(或 RevGrad)。核心的问题是同时学习分类器 G、特征提取器 F、以及领域判别器 D。通过最小化分类器误差,最大化判别器误差,使得学习到的特征表达具有跨领域不变性。
作者指出,DANN 的方法只是关注了数据特征的整体分布,忽略了和类别之间的相关性。因此,本文首先提出,要将特征和类别一起做自适应。公式如下:
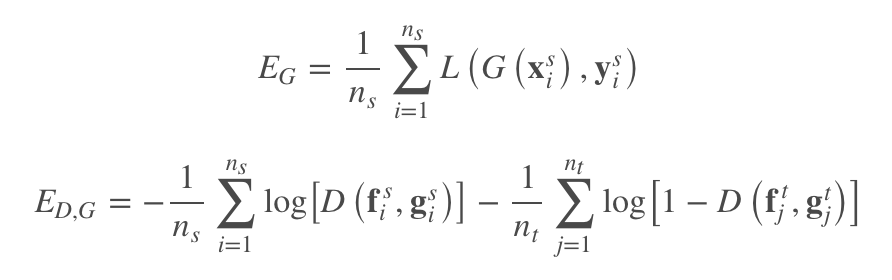
其中,f 和 g 分别是特征和类别。通过类似于 GAN 的最大最小优化方法,就可以进行 Domain Adaptation。
条件对抗机制
联合优化 (f,g) 的方法很多,将它们的特征向量连接起来是最直接的方法。但是这会造成它们彼此之间还是相互无关。达不到控制条件的目的。
作者借鉴了数学上的多线性映射(Multilinear Map)概念,来表征特征和分类器彼此之间的关系。什么是多线性映射?通俗点说就是,f(x)→y 是单映射,f(x,y)→z 是双映射,以此类推。线性呢?当固定其他自变量时,f 对未固定的那个自变量满足线性性(就是可加性、数乘不变),维基百科上对多线性映射的解释太抽象了。
那么,如何进行多线性映射?用 f⊗g。这里的 ⊗ 表示张量乘法,就是很多维的矩阵的乘法。
由于在深度网络中,特征维度往往很高。为了解决维度高导致的计算复杂度增加的问题,作者引入了相应的计算方法:
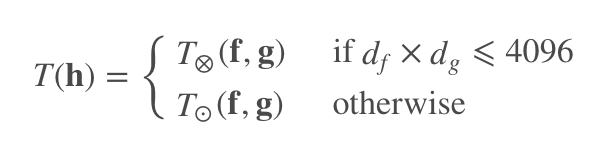
就是说,当数据维度太高时,直接从特征里随机采样一些向量做乘法。否则,用作者提出的方法做映射。
条件对抗网络
为了应对那些对迁移有负面影响的样本,作者用熵来控制它们的重要性,把熵操作加到了对抗网络中。
整个网络的优化目标如下:
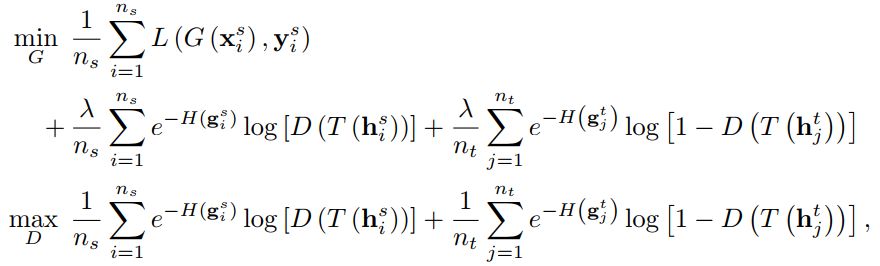
作者还在文章中分析了方法的理论误差上界。
实验
实验部分与传统的 Domain Adaptation 相同,在 Office-31,ImageCLEF-DA,Office-Home,MNIST,USPS,以及 SVHN 这些公开数据集上都进行了实验。
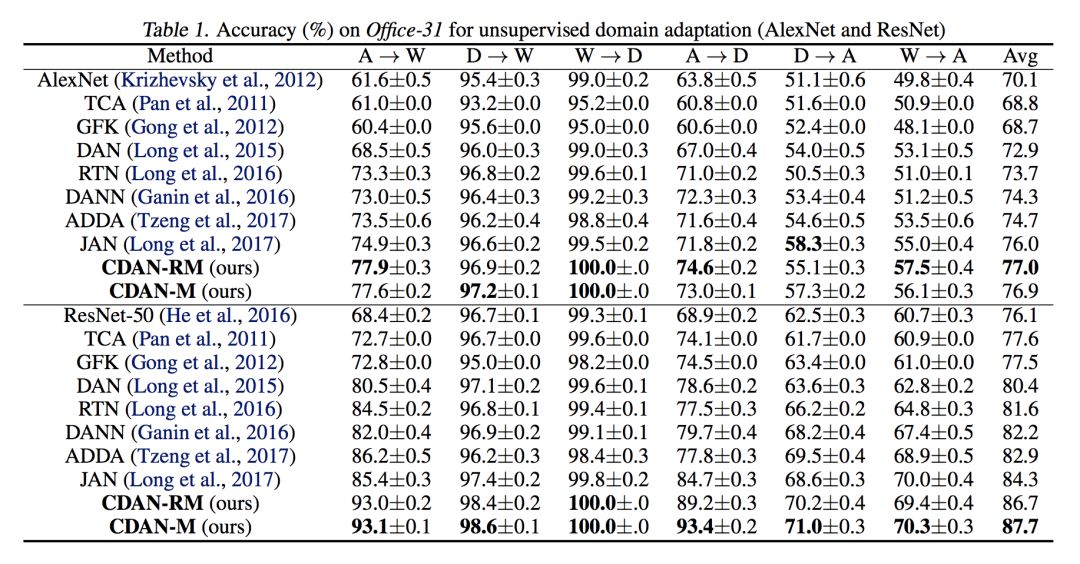
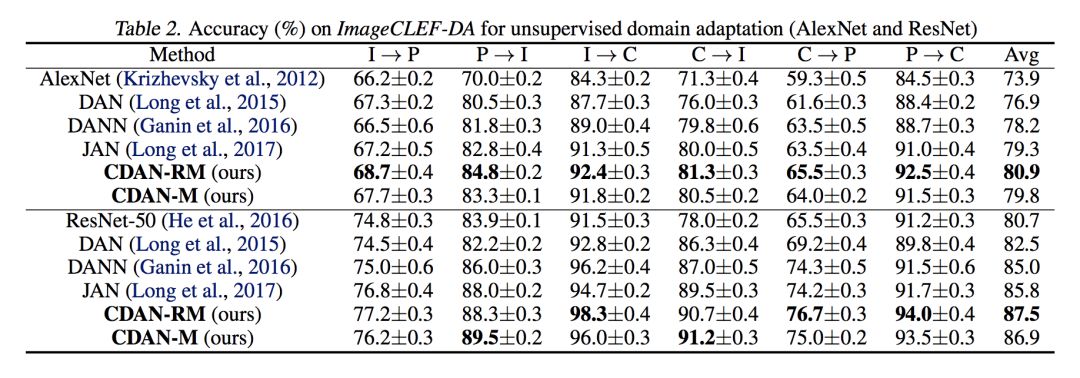
实验比较充分,详细结果可以看原文。从结果上来说,取得了比作者之前的 JAN 更好的结果,不过提升幅度有限,这可能是深度网络"挤牙膏"式的增长。
参考文献
[1] Ganin, Y. and Lempitsky, V. Unsupervised domain adaptation by backpropagation. In International Conference on Machine Learning (ICML), 2015.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看往期内容推荐:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文