你真的懂对抗样本吗?一文重新思考对抗样本背后的含义
选自towardsdatascience
作者:Alex Adam
机器之心编译
参与:Luo Sainan、一鸣
很多人都大概了解对抗样本是什么: 在数据中加入人眼不可察觉的扰动,使得模型对数据的标签预测发生混淆和错误。 但是,这句话背后的技术细节是什么? 怎样才能确保生成的对抗样本符合这样的定义? 本文深入解析了对抗样本背后的数学定义,并帮助读者重新理解对抗样本的定义。

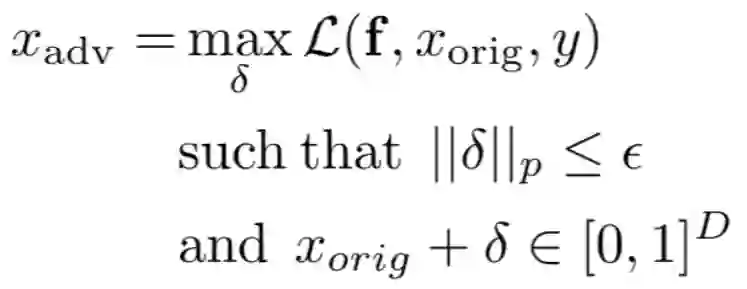
MNIST 图像距离分析

我们希望所允许的扰动对于人类而言是不可感知的,哪怕当原始图像 x 和扰动版本 x' 进行并排比较时,扰动也难以发现。
我们希望扰动不会导致相同数字的图像之间的篡改。否则这会混淆对抗攻击中的鲁棒性和泛化性。对于一个给定的数字,测试集图像 x_correct 和 x_false 分别被我们的模型正确和错误分类,一个普通的对抗攻击将把 x_correct 转换为 x_false。
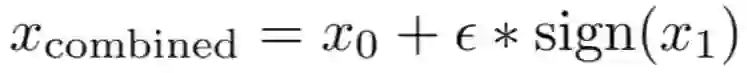

登录查看更多
相关内容

对抗样本由Christian Szegedy等人提出,是指在数据集中通过故意添加细微的干扰所形成的输入样本,导致模型以高置信度给出一个错误的输出。在正则化背景下,通过对抗训练减少原有独立同分布的测试集的错误率——在对抗扰动的训练集样本上训练网络。
对抗样本是指通过在数据中故意添加细微的扰动生成的一种输入样本,能够导致神经网络模型给出一个错误的预测结果。
实质:对抗样本是通过向输入中加入人类难以察觉的扰动生成,能够改变人工智能模型的行为。其基本目标有两个,一是改变模型的预测结果;二是加入到输入中的扰动在人类看起来不足以引起模型预测结果的改变,具有表面上的无害性。对抗样本的相关研究对自动驾驶、智能家居等应用场景具有非常重要的意义。
Arxiv
4+阅读 · 2018年2月12日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年2月12日