综述 | 浅谈2D人体姿态估计
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:https://zhuanlan.zhihu.com/p/72561165 作者:哇噻
本文来自知乎专栏,仅供学习参考使用,著作权归作者所有。 如有侵权,请私信删除。
浅谈:2D人体姿态估计基本任务、研究问题、意义、应用、研究趋势、未来方向以及个人思考
1. 基本定义
从单张RGB图像中,精确地识别出多个人体的位置以及骨架上的稀疏的关键点位置。
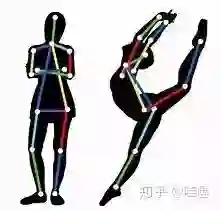
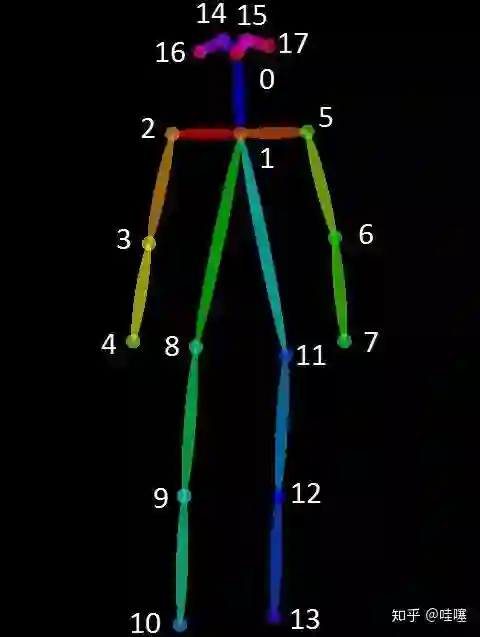
2. 基本任务
给定一张RGB图像,定位图像中人体的关键点位置,并确定其隶属的人体。
按照人的直观视觉理解的话,主要会涉及到以下问题:
关键点及周围的局部特征是什么样的?
关键点之间、人体肢体的空间约束关系是什么样的,以及层级的人体部件关系是什么样的?
不同人体之间的交互关系是什么样的,人体与外界环境之间的交互关系是什么?
基于Deep CNN的方法的试图通过神经网络的拟合能力,建立一种隐式的预测模型来避开上述的显式问题:
基于去显式分析人体姿态问题的方法是有的,传统的Pictorial Structure是其中一个较为经典的算法思路,目前也有少数方法用part-based的层级树结构建立人体姿态模型并利用CNN,来进行学习与预测。
当下多数深度CNN回归的方式, 试图用模型强大的拟合能力去回避以上的显式问题,而从大量的图像数据和标签监督信息中用神经网络去学习图像数据与构建的标签信息之间的映射。
3.当前主流研究的基础问题和难点:
神经网络结构的设计是个永远(当下)都会伴随的问题(假如深度学习的热潮没有退去的话)
Top-down:先检测人体,再做单人姿态估计的两阶段方法。(G-RMI, RMPE, CPN, SimpleBaseline,HRNet,...)
必然受到了目标检测任务的制约。
基于bounding box的单人姿态估计问题,在面对遮挡问题容易受到挫折。
精度虽然髙实时性能较差
小尺寸图像受限
计算资源限制
量化精度问题: G-RMI预测short offset弥补; 最大峰值与次峰的1/4偏移处的经验估计法; 19-arxiv-Distribution-Aware Coordinate Representation for human pose假设高斯分布用泰勒展开来估计真实位置. 量化精度问题实际上是一种工程问题, 它的本质来源在于, 计算机图像像素位置处于离散空间, 但是真实关键点位置位于连续空间,很多数据变换公式只能近似到离散的像素位置, 所以很多估计都是有偏的, 也有论文19-arXiv-The Devil is in the Details: Delving into Unbiased Data Processing for human pose estimation 在讨论姿态估计中数据变换出现的偏差问题.
Bottom-up:针对整副图像的多人关键点检测,检测所有关键点候选位置的同时,一般会用一定的算法关联或匹配到相关人体(openpose的动态规划, associative embedding的tag匹配, personlab的贪婪算法等等)。
(Deepcut,OpenPose,Aassociative Embedding, PersonLab)。个人认为Bottom-Up方法才是更值得研究的思路,是走向实时姿态估计的主要途径。今年ICCV-19, 也提出了single-stage multi-person pose machine, 其实也是可以看成一种bottom-up的方法, 它类似于19-arxiv-objects as points 的思路, 因为有中心点的参考, 就弱化了对设计多人人体匹配算法的需求,类似的还有19-arxiv-DirectPose: Direct End-to-End Multi-Person Pose Estimation 工作。
精度不如Top-down的更加精准,但实时性能较好
bounding box free
面对拥挤问题、遮挡问题仍然容易受到挫折
图像上的人体的尺度大小,未经归一化,分布很不均匀,关键点特征的提取难大于Top-down的方法 (19-arxiv-Bottom-up Higher Resolution Network 在尝试不使用多尺度test来克服这个问题)
小尺寸图像的量化精度问题 (PersonLab, Pifpaf的offset预测)
4. 方法分类:
标准1 PipeLine:Top-Down和Bottom-up的方法。
标准2 全局关系-部分关系:全局的长距离关系的隐式学习问题(大多数)和基于part的中短距离关系学习问题(ECCV-18 PersonLab,ECCV-18 Deeply learned compositional models)的学习问题
标准3 输出表示:heatmap回归(大多数),直接坐标回归方法(CVPR-14-DeepPose,ECCV-18的Integral Pose),向量场嵌入(CVPR-17 G-RMI、OpenPose,ECCV-18 PersonLab,CVPR-19 PIFPAF)的方法等等
5. 近几年的代表作
发迹于2014年, CVPR: Google的DeepPose,同年出现了MPII数据集(Max-Planck )以及MS-COCO数据集。NeurIPS还出现了纽约大学LeCun等人将CNN和Graphical Model联合训练,并使用了heatmap的表示方法。
16年: CVPR:CMU的Convolutional Pose Machine (CPM)和德国的马克斯普朗克研究所Deepcut以及Stacked Hourglass 网络结构设计的出现。
17年: CVPR:Google的G-RMI开启基于目标检测的人体姿态估计方法。CMU的OpenPose系统出现,致力于打造实时姿态估计系统。Deepcut的改进版DeeperCut出现。同年ICCV上,Mask RCNN、上海交通大学的RMPE以及随后的AlphaPose崭露头角, NeurIPS17也出现了 Associative Embedding 以新的端到端的方式来避免人体姿态估计多阶段不连续学习的问题。
18年:CVPR上出现了旷世的CPN拿下了17年COCO挑战赛的冠军, ECCV上微软亚洲研究院的SimpleBaseline用自上而下的方法为姿态估计打造最简单的baseline,并刷新了COCO数据集的新高。ECCV上还出现了来自中东技术大学的Muhammed Kocabas提出了MultiPoseNet,以及Google的自下而上多任务的新作PersonLab, 值得一提的是还有一些开辟新的研究角度的方法如ECCV上美国西北大学part-based的姿态估计方法Deeply learned compositional models 。18年的另外一个趋势就是,新问题新任务的出现,比如CVPR18的DensePose标志着密集关键点人体姿态估计任务的出现, 2D pose track 任务(CVPR18 PoseTrack数据集)的提出, 以及3D 姿态估计问题的兴起......
19年CVPR, 姿态估计再次呈现一个小爆发. HRNet的出现, 成为了姿态估计任务中更强的baseline模型, 其结构本身也具备较强的泛化性, 可以作为backbone的候选. 19 CVPR上还有 PIFPAF,针对小尺度的姿态, Enhanced Channel-Wise and Spatial Information Pose加入了attention的模块到神经网络结构中 ,Related Parts Help 探讨了将人体部件划分为多个group进行学习的好处,Crowded Pose 针对拥挤场景, Fast Human Pose 使用大模型的知识蒸馏,Pose2Seg 引入像素分割等等, ICCV19 上也有了 single-stage multi person pose machines, 大量的研究在探讨姿态估计的问题, 并且3D 姿态估计即将成为主流。当然, 2D姿态估计任务仍然是值得去深入探讨的问题, 因为一些本质上的难题目前还没有完全的洞察和有效的解决方案, 比如严重遮挡,多人重叠问题等等。另外, 数据集MPII, COCO数据集上的"刷性能" 也依然是大家孜孜不倦的追求,性能再次来到了新高。
可以看出来几条结论,
1. 引领姿态估计潮流的有几伙子人
2.美国 德国 的研究机构是 姿态估计的 “始作俑者”,亚洲人后来者居上
3. 欧美国家喜欢方法创新,以及新问题的提出,中国研究机构更擅长占据性能的榜首
6. 研究意义:
3D人体姿态估计的铺垫、3维人体重建的必备技术
人体关键点的视频追踪问题的基础(从静态到动态)
动作识别的信息来源(从关键点的时序空间特征映射到动作语义问题)
7.应用:
自动驾驶行业:自动驾驶道路街景中行人的检测以及姿态估计、动作预测等问题
娱乐产业:动作特效的增加。快手、抖音、微视等视频软件,但娱乐是一种锦上添花的需求,而非必要,人工智能不应该满足于”娱乐至上“的精神。
安全领域:行人再识别问题,以及特殊场景的特定动作监控,婴儿、老人的照顾。
影视产业:拍电影特效(复仇者联盟拍摄主要靠动作捕捉衣,是不是可以应用视觉技术?)
人机交互:AR,VR,以及未来的人机交互方式
产业界应该探索更多潜在的应用
8.研究趋势的变化以及扩展:
3D (甚至 4D,5D, 6D,...)人体姿态估计的流行, 大量的论文出现...
稀疏关键点到密集关键点(CVPR-18 FaceBook DensePose)
静态图像到视频追踪 (CVPR-18 PoseTrack)
从关键点定位到肢体的像素分割预测 (pose parsing,CVPR-19 pose2reg)
从监督学习到弱监督 、自监督,甚至无监督有可能(如, ICLR-2019 unsupervised discovery, parts, structure and dynamics,NeurIPS-2019 Learning Temporal PoseEstimation from Sparsely-Labeled Videos)
当然:神经网络结构的设计也是一个必不可少的环节:从CVPR-16-CPM, ECCV-16-Stacked Hourglass, ECCV-18 SimpleBaseline,CVPR-18 CPN, CVPR-19 HRNet,CVPR-19 Enhanced Channel-wise and Spatial Information,ICCV FPN-POSE, arXiv-19-MSPN-Rethinking Multi-stage Networks for Human Pose Estimation,多尺度融合、多阶段级联、堆叠等等等等,用于姿态估计神经网络的结构层出不穷 , 甚至NAS for human pose estimation也是有可能,比如19-arXiv-Pose Neural Fabrics Search 引入先验知识引导神经网络搜索。如深度学习的热潮没有退去的话,神经网络结构的设计会是一个永远都会伴随的问题,只是其重要程度和切入的视角在不断地发生变化。
个人思考
当前所有的姿态估计方法几乎都使用了深度卷积神经网络的强大功能,但个人认为神经网络设计绝不是解决该问题的核心,用力搔靴和脱掉鞋子,哪个才是更好的止痒手段呢?
关于应用与产品
人体姿态估计是一个综合的问题,有很多的切入点和难题值得去研究,并且它是一个尚未实际落地的计算机视觉技术。在这个层面上,AI的产品经理们和投机者们应该想想这项技术怎么能更好地服务大众,并带来市场和利润。
作为科学研究者,赚钱的考虑或应该暂时放到明天。我想讨论的是: 当我们面对一项任务和难题, 我们是应该忽略固有的困难和问题,提出新的问题,给出问题方案,去探索新的研究趋势呢?还是强行深入当前的固有问题,解决当下的难题呢?是不是有一些的问题是超前式的,也许放到以后才会有更加合适的方案和角度来解决?
关于研究方向
或者说,我们还可以用另一种粗暴的方案:把这一问题黑箱化或者半黑箱化,然后从神经网络结构设计、数据处理、增强以及其他机器学习数学方法去暴力式的解决。这样的解决方式实际上是,摒弃了人类本身做姿态估计的直观思路(上面所述),而是从更加“机器学习”的角度去处理这个问题。假如,我们寻找到一个“完美”结构的神经网络,让它去达到100%或者近似100%的准确率!这样以来,似乎预测问题被完完全全地解决了,但是问题是,我们不知道能不能找到这样的结构或者技术,或者说一旦找到了以后能不能解释性地理解这一技术? 这就又引出了大家探讨争论许久的可解释性问题、显式推理问题。也许PersonLab和PifPaf的工作值得去思考,继续引入复合场(Composite Field)的概念,预测人为设计好的高维度向量来处理人体姿态预测问题,让模型预测更加巧妙的监督信息, 并且能降低量化误差,设计保持期望的一致性的关联肢体得分公式,再加之快速贪心算法,利用人体的连通特性就能得到多人姿态。这样的设计与算法,尽管性能比那些注重网络结构设计的差一些,但却遵循合理的直觉,有可解释性, 这是不是需要我们更多的关注?
另外,今年ICLR2019上,有学者甚至提出了无监督的方式处理人体部件。我认为这是一种可以去探讨的问题, 因为人体姿态本身其实可以看成图像中的特征簇, 其视觉上的连通特性本身就具备了高维空间上的独特性. 那么生成模型, 无监督学习在直觉上是可行的吗? 如果再加上视频,光流等辅助信息, 是不是就可以从大量无标签的图像数据中, 准确构建人体部件的特征、部件到整体的结构特征以及人体姿态的运动时序特征? 这可能又会是一个新的思路和解决人体姿态估计任务的新手段吗?
-END-
点击 阅读原文,可跳转浏览本文内所有网址链接
*延伸阅读
PS:新年假期,极市将为大家分享计算机视觉顶会 ICCV 2019 大会现场报告系列视频,欢迎前往B站【极市平台】观看,春节也学习,极市不断更,快来打卡点赞吧~
https://www.bilibili.com/video/av83518299
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



