澄清误解!对CVPR 2019 LFM论文质疑的回复
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文作者:Yunke Zhang
https://zhuanlan.zhihu.com/p/128146732
本文已由原作者授权,不得擅自二次转载
Amusi:昨天 CVer 推送了一篇原发布在知乎上的论文质疑文章,详见:质疑论文 CVPR 2019 LFM!今天LFM原论文作者对质疑进行了回复,详情内容如下:
正文
感谢质疑者对我们的工作感兴趣,作为论文的第一作者我代表我们的研究小组有以下几件事情需要澄清。
复现结果
我们认为质疑文章中的复现结果较差是由于网络没有在我们的人像数据集上训练导致的,所以我们用论文投稿时人像数据集上训练的model重新验证了质疑文章中提到的两张图片。
该model在服务器上的时间戳如下(2019年6月是向服务器上传论文投稿代码和模型weight的时间。为了清晰起见,今天我们在github公开的代码是repack过的,所以压缩包里的时间戳是2020.04.09。最原始的时间戳是CVPR2019投稿时的,投稿CVPR2019时的模型weight文件也有备份)
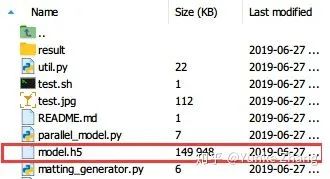
图1是我们论文里面的图,输入网络时IMAGE SHAPE是800*800(已缩放回正常长宽比)
图2是质疑文章中提供的图,直接从知乎的图片中里面crop下来的,输入网络时IMAGE SHAPE是384*384.
结果如下,尽管结果中还存在问题(图2人物的右胳膊不够实),但是在人像数据集上训练过的model还是优于复现结果的。
图1:

图2:

Background Matting (CVPR2020)
这篇CVPR2020文章的作者Soumyadip在2019年11月曾与我们邮件联系过,邮件中问到我们的model是在哪些数据集上训练的。
由于双方沟通过程中存在歧义,导致对方误认为我们的model是在DIM的train+test上训练的,所以才有background matting文章里Section 4.1的陈述。我们已经与他联系纠正了这一错误。
以下为几张邮件截图。
1、2019年11月关于model训练问题Soumyadip的提问及我们的回复,当时对方提到我们的model是在DIM在训练的还是在DIM和Human Matting Dataset训练的,我们的回复是在两个dataset上训练的:
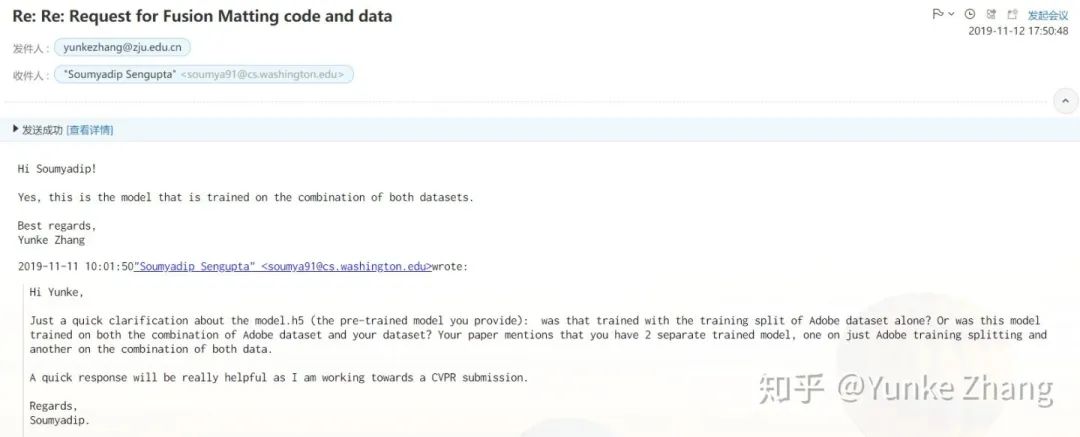
2、这是在质疑提出后,我们与Soumyadip联系的答复。对方承认存在误解并予以修正,并提出周末(2020.4.9这周)会更新arXiv,通知CVPR PC更改camera-ready版本(红线部分):
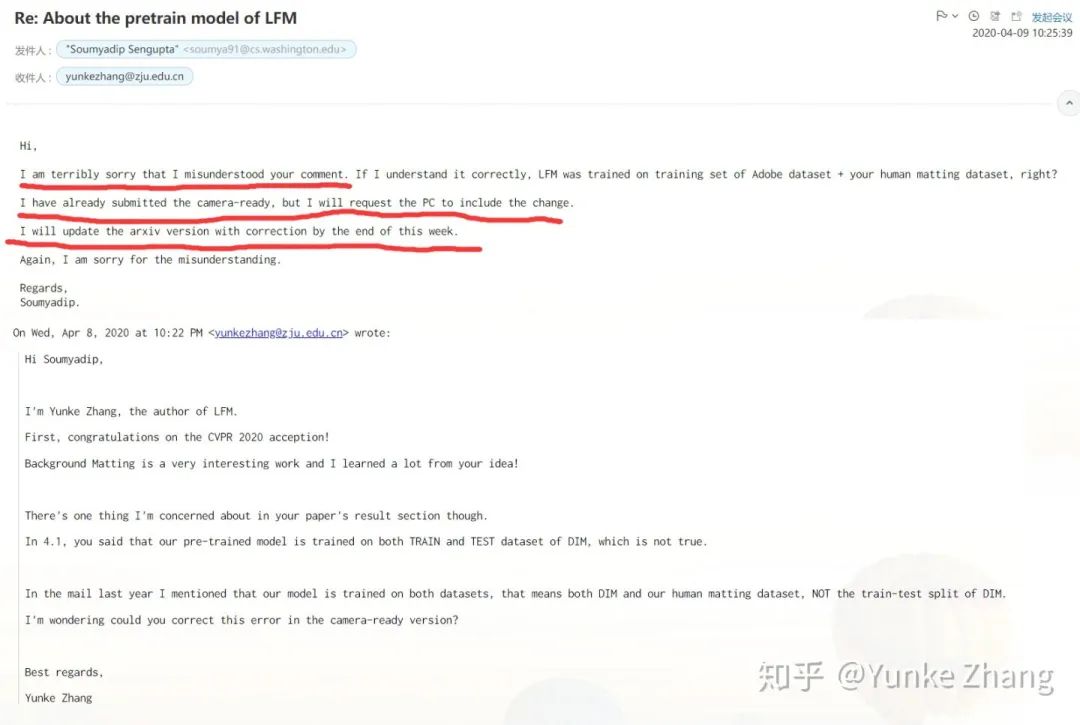
3、我们放出的model是在DIM上pretrain,然后在Human Matting Dataset上finetune的model,关于这点我们也再次联系他进行了说明,并在其中再次重申我们并没有使用DIM的test split来训练(红框部分):
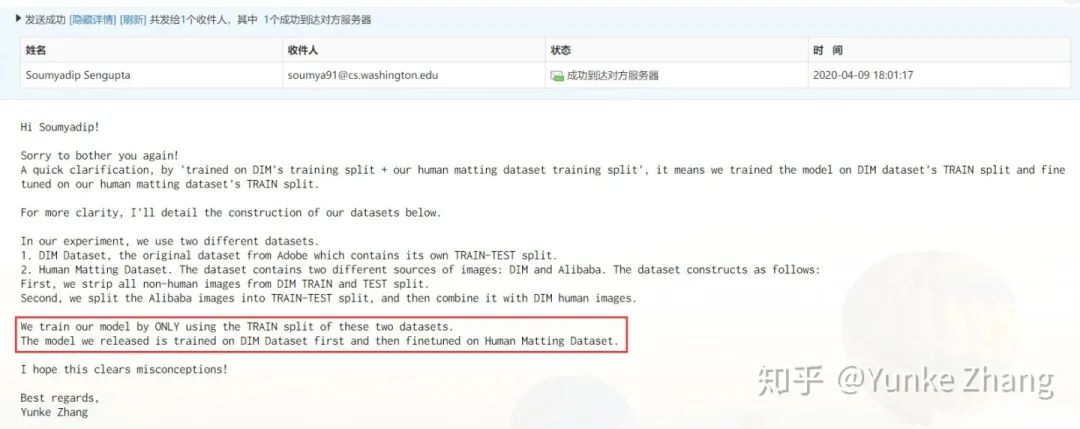
注:Human matting dataset具体组成: training data consists of DIM human image in DIM training data + Our human image training data,与我们的论文是一致的。
从这篇论文里放出的我们论文的结果在他的数据集上质量不好的主要原因应该是Background Matting使用的数据和我们训练使用的数据集差异导致。
不论是DIM还是我们自己构建的Human Matting Dataset都是synthetic数据集,选取和合成的图片都是以高清图片为主,而Background Matting的Fig.6的图片是由手机获取的真实数据。数据集间的差异可能会导致结果变差,这也是为什么Background Matting要采用GAN来bridge gap的原因。我们会向Background Matting的作者获取测试数据,探讨Fig.6中报告的我们模型结果的原因。
同时,论文投稿时的人像训练数据集前景图片可能不足,训练方式(大量crop大分辨率图片,同时对图像尺寸的采样不够充分)有可能会导致网络对图像尺寸等参数敏感,需要进一步完善。
Background Matting (TIP)
我们认为TIP论文中放出的我们模型结果较差的主要原因如下:
我们当时放出的是在Human Matting Dataset上finetuning之后的model,而TIP论文直接在DIM数据集上使用这个人像数据集上训练的mode,导致结果较差。我们在给对方model的时候只给了链接,没有在邮件明确说明模型的使用方式,导致了沟通上的误解。
这是2019年7月我给作者Hossein提供源码和model时的截图(由于人像数据集的开放需要批准,图中链接已失效):
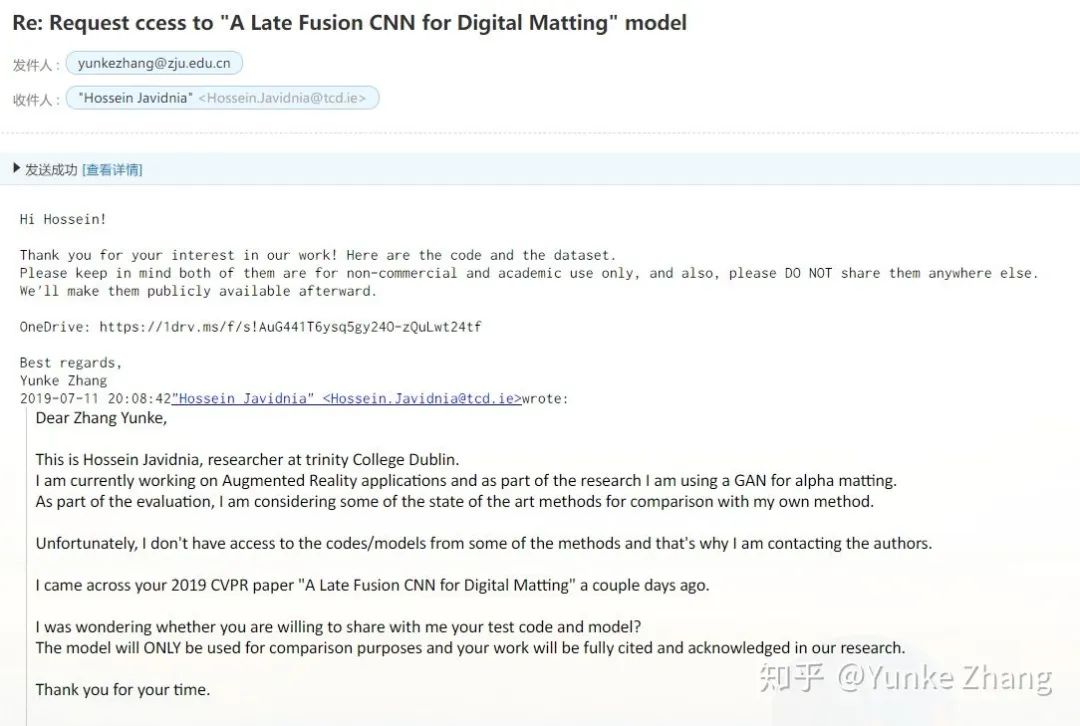
我们会再和TIP文章作者进行核实并更正TIP文章中的错误数字。
总结
正如原始质疑文章的评论中提到的,我们的工作也并不是trimap-free matting的第一篇工作,阿里的Semantic Human Matting,Google的Portrait Matting都是这一领域的开拓者,只是这些文章都受限于某一类物体或某一种类型的图片。我们的工作与前人最大的不同点在于说明了trimap-free matting在比较复杂的自然图像抠图任务场景中也有一定的可行性,而且网络也不需要跟SHM一样需要先训练trimap分割网络。这里我们要说明的是,我们并没有拿到Semantic Human Matting的数据和代码,论文中报出的SHM数字是我们自己重现的结果。
再次重申,我们放出的model是在DIM的train set上pretrain,然后在Human Matting Dataset的train set上finetune的model,并没有在DIM的test set上训练。这一点我们在回复邮件的时候没有明确指出,是导致沟通出错的原因。感谢质疑者的意见,让我们发现了相关论文的问题,有了更正机会。
论文投稿时的数据集本身不够大,数据增强方式有可能覆盖不全面,所以,目前得到的模型有可能受到图像尺寸、背景、前景物体占比的影响,相信继续增加高质量数据会大大缓解该问题。针对LFM的泛化能力我们依然需要在数据集和算法上进行改进。同时,我们会继续做一些实验,对论文数据训练模型的limitation做进一步说明。
注:个人邮箱比较庞杂,而且有时邮件会在垃圾邮箱可能无法一一回复。敬请谅解。
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1200+人,旨在交流顶会(CVPR/ICCV/ECCV等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
麻烦给我一个在看!



