自监督学习的发展趋势:事半功倍的模型训练和数据效能

©作者 | 唐工
这些趋势之所以令人兴奋,是因为它们可以大大减少为某一特定任务使用机器学习所需的努力,也因为它们使得在更具代表性的数据上训练模型变得更加容易(尽管绝非微不足道),这些模型更好地反映了不同的亚种群、区域、语言或其他重要的表示维度。

...It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference... ...它只消耗 GPT-3训练所需能耗的1/3,并且只需要一半的浮点运算进行推理...
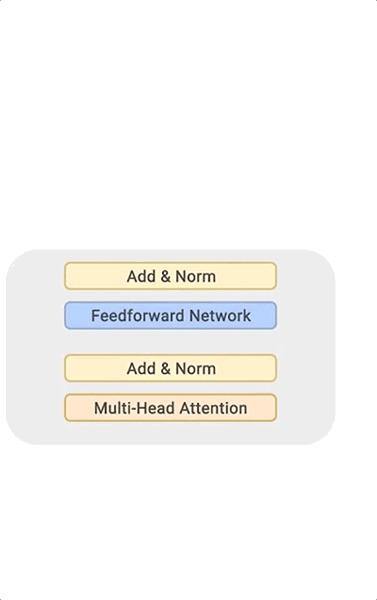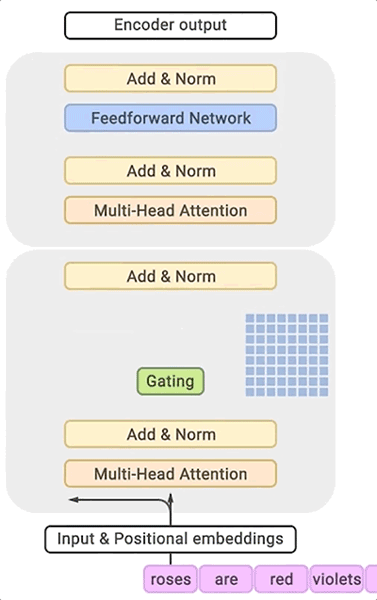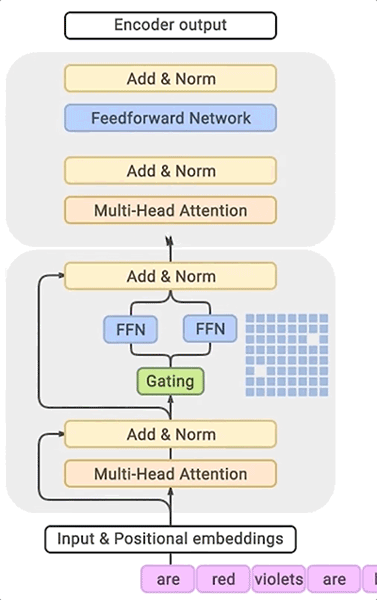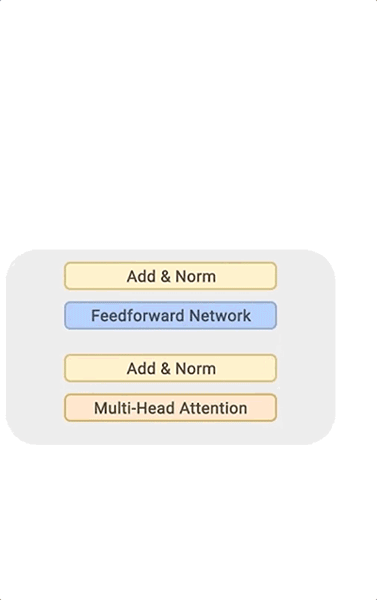

BigSSL 模型:探索用于自动语音识别的大规模半监督学习的前沿
SSL + Large Models = Labeled Data Efficiency
半监督学习 + 大型模型 = 标记数据的效能
Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. Transformer 模型擅长捕获基于内容的全局交互,而 CNN 则有效地利用局部特征。
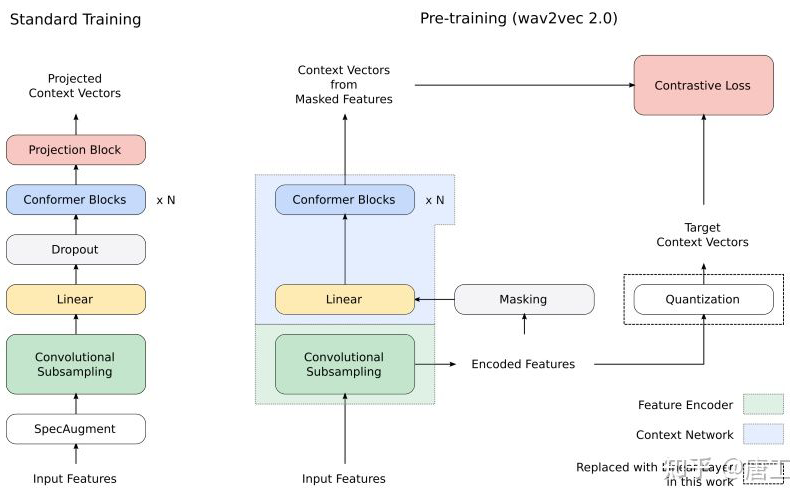

SimCLR 模型:提高自监督和半监督学习
当前的图像数据自监督技术过于复杂;
-
需要对架构或训练过程进行重大修改。


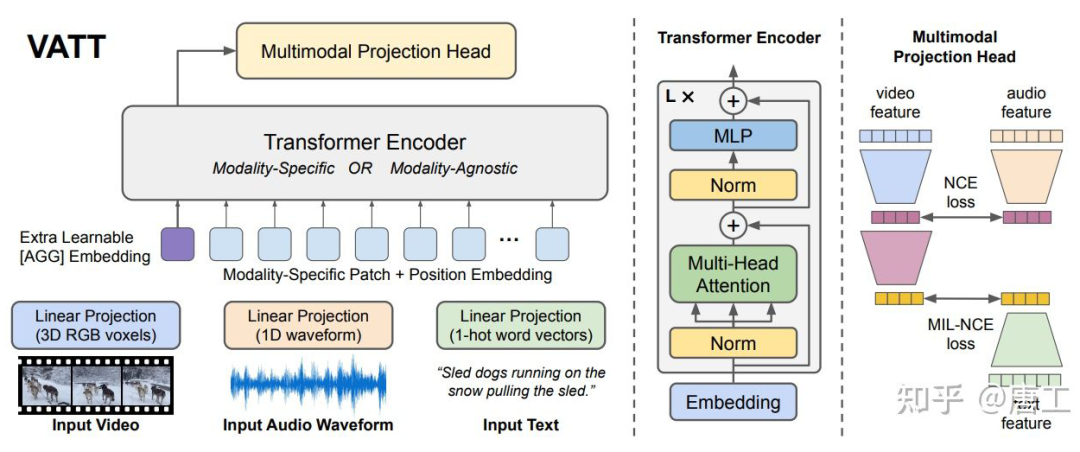
VATT 模型:从原始视频、音频和文本的多模态自监督学习 Transformer

参考文献
[2112.06905] GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (arxiv.org):https://arxiv.org/abs/2112.06905
[2109.13226] BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition (arxiv.org):https://arxiv.org/abs/2109.13226
[2002.05709] A Simple Framework for Contrastive Learning of Visual Representations (arxiv.org):https://arxiv.org/abs/2002.05709
[2104.11178] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text (arxiv.org):https://arxiv.org/abs/2104.11178
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




