如何0代码、快速定制企业级NLP模型?百度工程师详解技术选型与模型调优策略
主讲人 | 龙心尘 百度NLP资深研发工程师
量子位编辑 | 公众号 QbitAI
近几年以预训练为代表的NLP技术取得了爆发式发展,新技术新模型层出不穷。企业与开发者如何将最先进的NLP领域科研成果,高效地应用到业务场景中并解决实际问题?
「百度EasyDL AI开发公开课」中,百度资深研发工程师龙心尘结合世界领先的文心(ERNIE)语义理解技术,通过产业实践案例,深入解析技术选型和模型调优的方法,分享了工程实践中的经验。
讲解分为5个部分:
NLP常见任务
NLP典型应用场景
EasyDL-NLP与文心(ERNIE)简介
文心核心技术解析
NLP定制化实践与经验分享
直播回放见链接:https://www.bilibili.com/video/BV1Zi4y157jd
以下为分享内容整理:
NLP常见任务
自然语言处理(NLP)大致分为4大经典任务:文本分类,文本匹配,序列标注,文本生成。
文本分类
假设输入文本为x,输出标签为y,如果y 表示x属于某一个类别的概率,或者一组类别的概率分布,则可抽象为文本分类问题。
典型的文本分类包含情感分析、新闻主题分类、文本蕴含。

情感分析一般需要判断某句话是积极的或消极的,属于单标签分类。
新闻主题分类相对复杂,一个新闻可能同时具有多个互相独立的属性,可以同时出现,属于多标签分类。
文本蕴含任务输入的是两段文本,需要判断两段文本之间的关系(包含关系、对立关系、中立关系等),属于句对分类。
文本匹配
假设输入文本为x,输出标签为y,如果x是两段文本(x1、x2),Y表示二者的相似度,则可抽象为文本匹配问题。

如图,x1与x2的意思是非常相似的,所以标签y是1。如果x1与x2的含义不相似,那么输出的y就是0。如果需要判断两者相似的概率,标签y在0-1之间。
文本匹配任务在搜索引擎、推荐、FAQ等判断两句话相似的场景中应用非常广泛。
除此之外,文本聚类问题也可以通过文本相似度问题进行处理。机器学习的聚类算法的核心步骤是计算两个样本之间的距离,而相似度就是两个文本之间距离的度量,可以很好地判断文本间语义层面上的距离。
序列标注
假设输入文本为x,输出标签为y,如果x是一段文本,y是一段与x等长的文本,且x与y的每个字符一一对应,则可抽象为序列标注问题。

如上图是一个命名实体识别任务,需要要判断一句话里的一些关键词语,是否属于地址、人名等实体。这句话里面,“厦门”和“金门”是两个地址实体。
同时,这个句子中的每一个字,我们都会给出判断,将不需要关注的字标记为O,因此输出的判断标签Y与X是等长的。
除此之外,分词、词性标注、组块分析、语义角色标注、词槽挖掘等,都是典型的序列标注任务。某些人将阅读理解也理解成一种特殊的序列标注,X是2段文本,分别表示正文篇章和问题,Y是篇章中的一小段文本,表示对应问题的答案。
文本生成
假设输入文本为x,输出标签为y,如果x是一段文本,y是一段不定长的文本,则可抽象为文本生成问题。

最典型的文本生成问题是机器翻译,比如输入一段英文,输出一段其他语言的文字。这两段文字的字、词的顺序不一定一一对应,因此输出的是一个不定长的文本。
另外,文本摘要、标题生成、闲聊等都是典型的文本生成任务。
NLP典型应用场景
上述介绍了四大经典NLP任务,核心是希望大家注意不同任务的输出X与输出Y。这样就可以在真实的NLP应用场景中,能把不同任务拆分成简单的典型任务。

在企业实际应用和产业实践中,业务需求千变万化,往往需要对NLP模型进行定制化的训练。
定制过程中,企业要考虑三个要点:效率问题、效果问题、效能问题。

为了帮助中小企业更高效的实现NLP模型训练、优化、部署应用,百度面向企业提供了的零门槛、一站式AI开发平台—EasyDL提供全流程服务支持,和业界领先的语义理解技术平台—文心(ERNIE)为企业降低NLP定制成本,下文为大家详细介绍其优势与核心技术。
EasyDL:全流程企业级定制化服务支持
EasyDL为大家提供一站式定制化NLP开发平台,低门槛、简单易用。面向企业客户和开发者提供全流程技术服务配套,包括业务问题分析、技术选型指导、模型优化指导、开发者使用培训等。
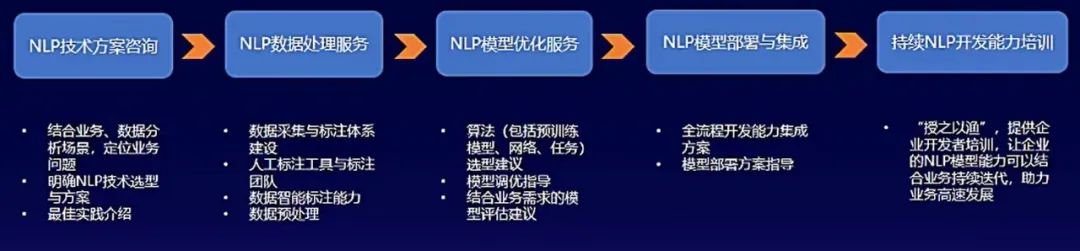
EasyDL不仅为企业客户提供全流程方案与技术支持,在解决企业业务问题的同时,也让企业能更好地沉淀自身技术实力,真正做到“授之以渔”。
文心:降低NLP定制成本
文心(ERNIE)是依托百度深度学习平台飞桨打造的语义理解技术与平台,集先进的预训练模型、全面的NLP算法集、端到端开发套件和平台化服务于一体,为企业和开发者提供一整套NLP定制与应用能力。
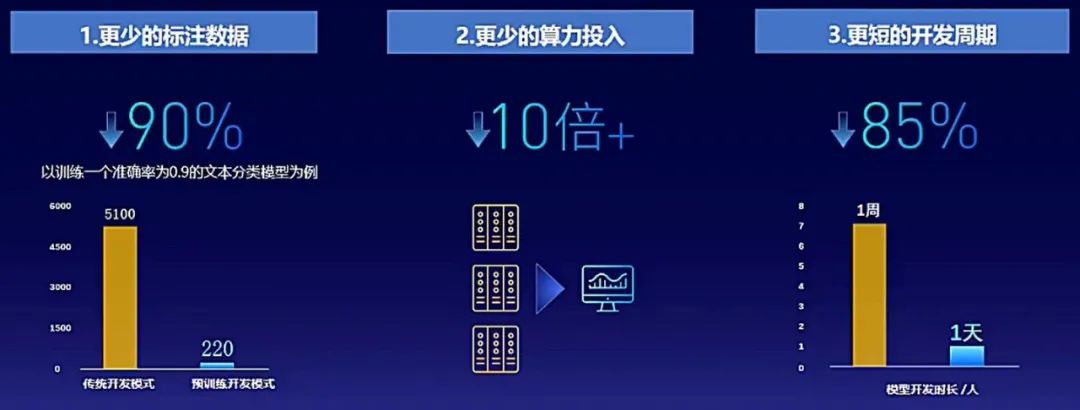
文心基于最新一代预训练范式的技术优势,能够大幅降低NLP定制成本。
对于企业来说,文心的低成本定制能力意味着什么呢?更少的标注数据、更少的算力投入、更短的开发周期。
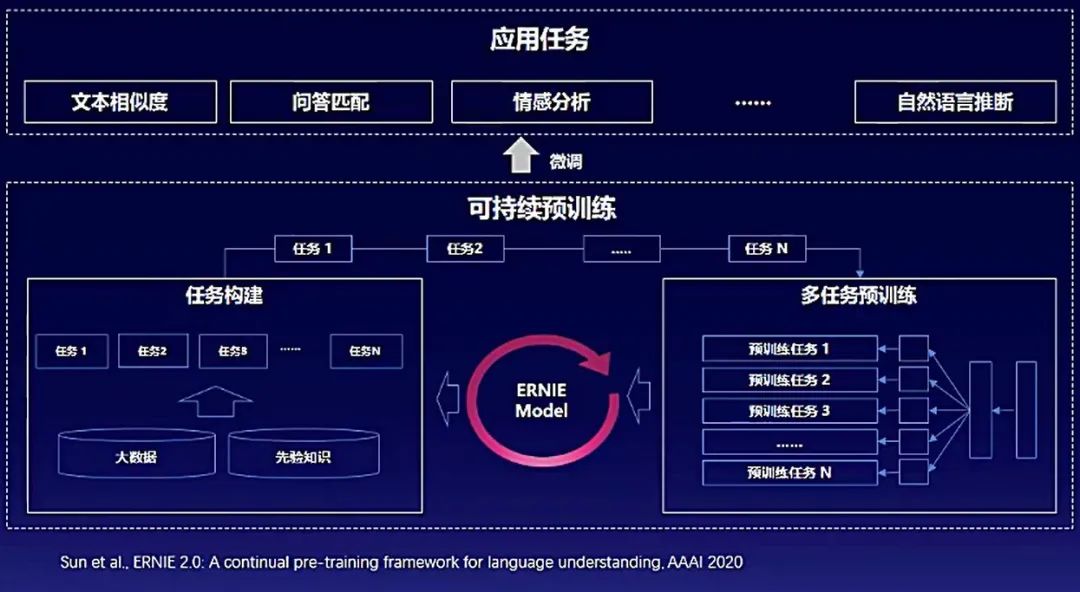
文心核心技术:ERNIE 2.0(持续学习语义理解框架)
文心开创性地将大数据预训练与多源丰富知识相结合,持续学习海量数据中的知识,避免灾难性遗忘,将机器语义理解水平提升到一个新的高度。
以中文模型为例,目前ERNIE已经学习了1500万篇百科语料和词语、实体知识,700万个人类对话,3亿的文章的因果结构关系,以及10亿次的搜索查询与结果的对应关系,以及2000万的语言逻辑关系知识。
模型还在持续不断地建模新的海量数据与知识,不断地提升下游的应用效果。ERNIE在中英文的16个任务上已经超越了业界最好模型,全面适用于各类NLP应用场景。
文心的技术创新:ERNIE-GEN
为了解决文本生成任务中的问题,ERNIE提出了ERNIE-GEN技术范式。
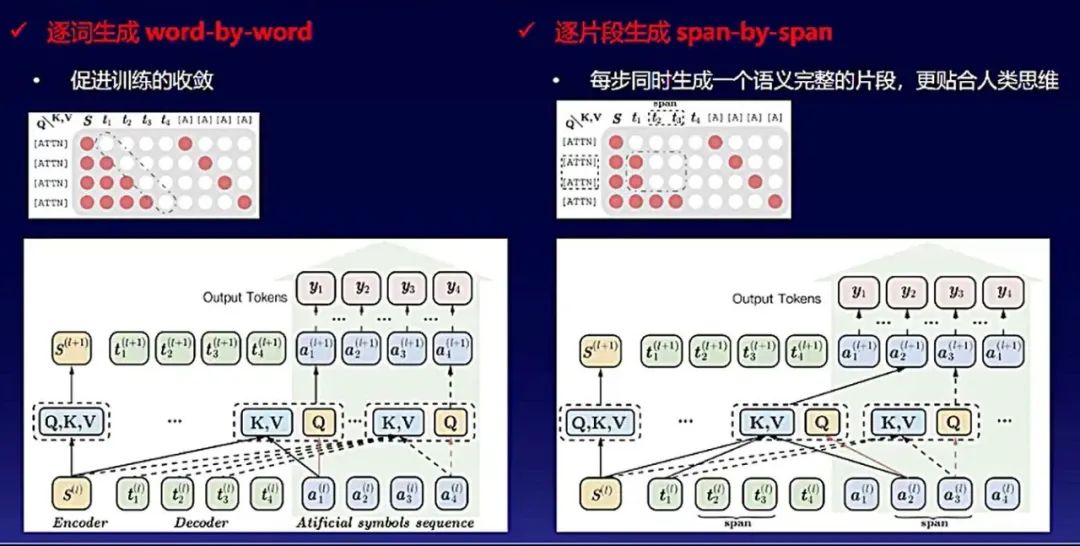
首先,ERNIE-GEN主要关注文本生成任务中的“曝光偏置”问题。ERNIE-GEN采用了填充式生成技术,在训练和解码中,插入人工符号(ATTN)和位置编码来汇聚上文向量表示,用于每一步的预测。
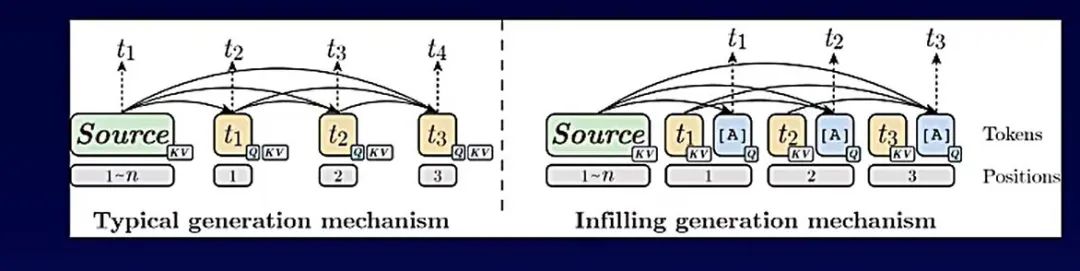
即将模型的注意力从上一个生成字符转移到更全局的上文表示,以缓解上一个字符预测错误对后续生成的负面影响,缓解曝光偏置问题,增强生成鲁棒性。
其次,ERNIE-GEN采取了多流注意力机制,能够同时实现逐词生成任务和逐片段生成任务。
文心的技术创新:ERNIE-ViL
我们知道,人类的认知不仅通过阅读文字产生,还通过观察大量的事物、查看大量图片、动画片、图文相结合等方式,是多模态的形式。
那么,如何让模型学习文本、图像、语音等不同形式的信息,从而在认知理解层面取得更好的效果?
在多模态领域,我们的ERNIE-ViL(知识增强的视觉语言表示学习)更加强调的是在引入图像信息的同时,融合了更多知识。即细粒度语义信息抽取,区分普通词与语义次,构建了物体预测、属性预测、关系预测三个预训练任务,聚焦细粒度的语义对齐知识。
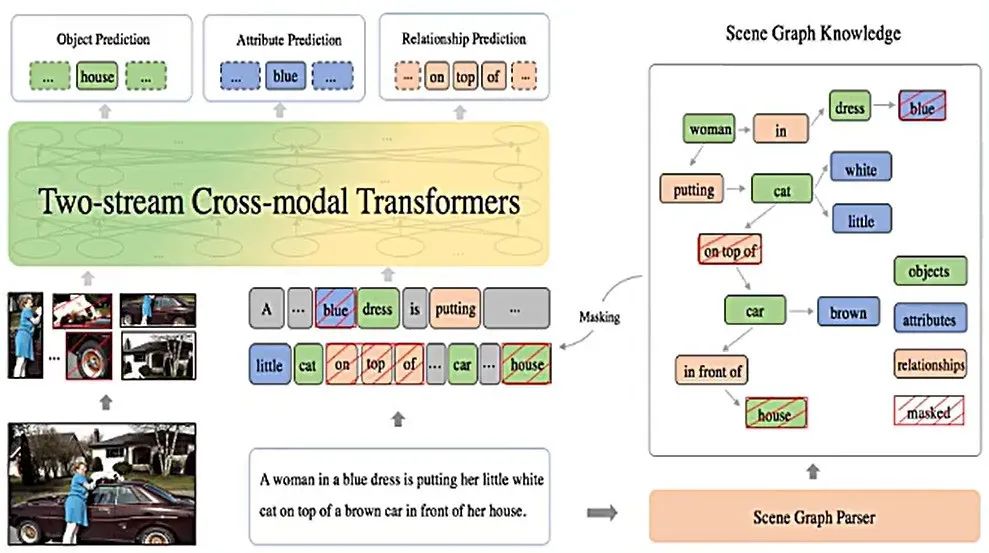
正是因为结合了多模态与知识,ERNIE-ViL在视觉问答、视觉常识推理、引用表达式理解、图像检索、标题检索等5项多模态任务集合上取得世界最好的效果。并且在视觉常识推理任务榜单中取得第一名。
案例实践分享
实际应用中,NLP定制化训练任务可拆分成7个步骤,并不断循环、迭代优化:
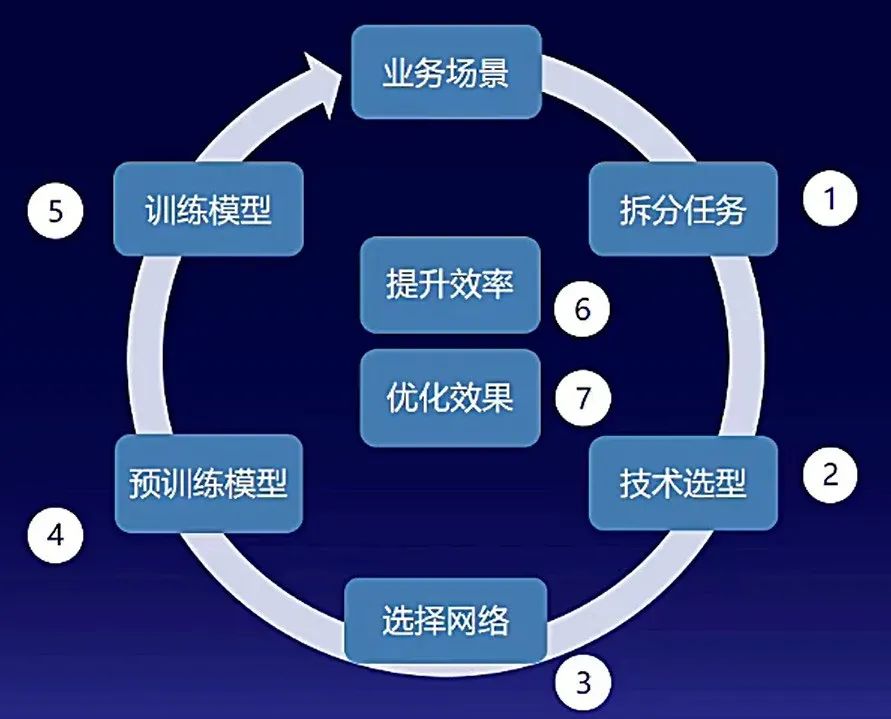
因此,提升NLP模型训练效果,一方面要提升循环迭代的速度和效率,另一方面则需要考虑如何提升优化效果。
1.任务拆分
首先,遇到任何文本场景的任务问题,都可以拆分成上述的典型任务。接下来,明确任务本身的输入与输出是什么,明确子任务的输入与输入是什么,然后把这些子任务组合起来,最终解决问题。
以百度APP的搜索问答场景为例,输入的是问题,输出的是答案。
首先进行简单抽象为一个文本匹配问题。因为我们可以提前把这些答案准备好,用户提问时只需计算问题与答案的匹配度,问题与答案匹配度高,就把答案推荐出来,若匹配度低则不推荐。
再来进一步拆分。首先,用户输入的可能并非是明确的问题,未必有答案。因此我们需要前置一个“文本分类”任务来过滤问题,过滤掉大量的不是明确问题的流量。接下来,再将能够匹配答案的问题进行问答匹配任务。
2.技术选型
技术选型也可理解为一种广义的优化问题:在有限的条件下,找到合适的方案,优化出最好的目标。所以问题的核心是先明确现有条件的限制是什么、目标是什么。
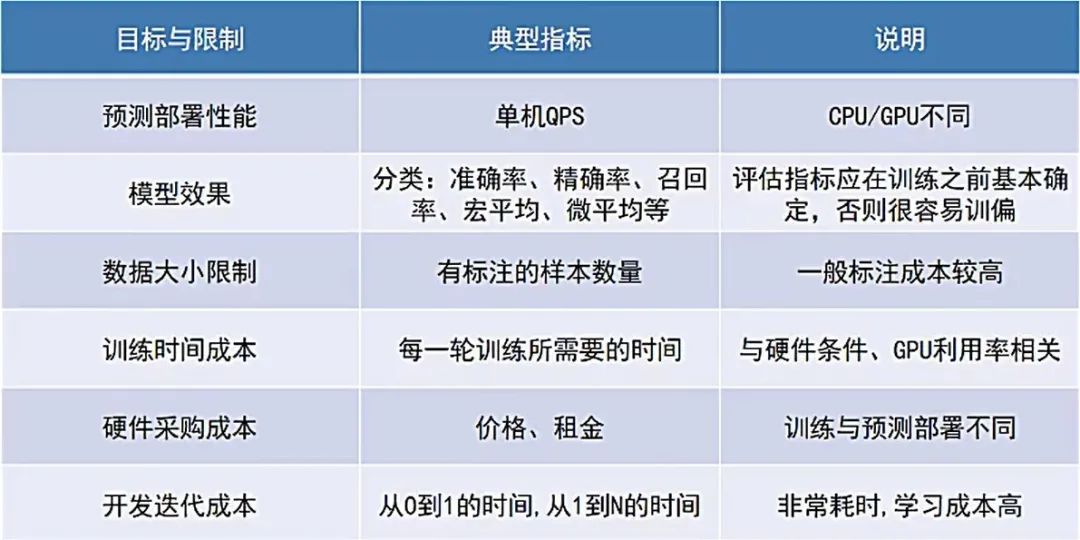
接下来,基于应用场景、硬件条件,选择相应的可选技术方案,来达到目标优化效果:
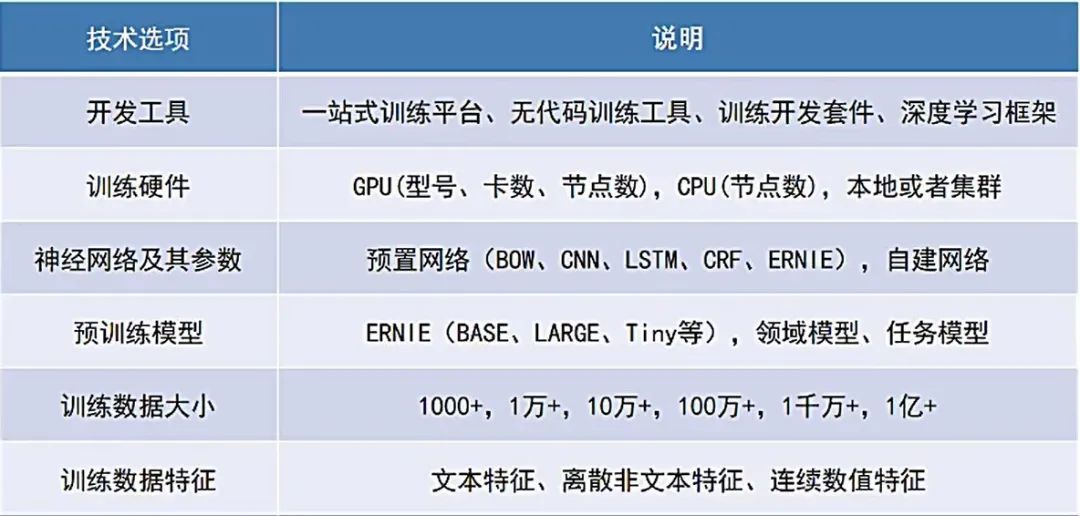
比如对于模型效果的提升的目标,可以借鉴以往经验:
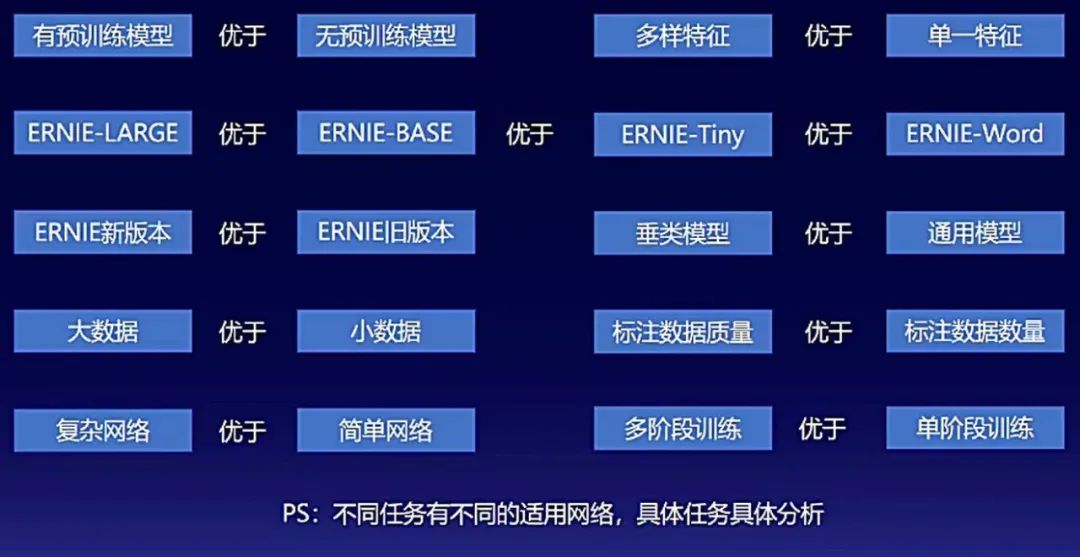
3.选择网络
在文本分类的场景下,以BOW网络为例,典型网络结构依次包括:输入文本的ID序列、 Embedding、BOW结构、全连接层、Softmax层。
其中BOW层可替换为CNN、TextCNN、GRU、LSTM,随着网络结构越来越复杂,模型效果一般也会依次提升。
Embedding层可以替换为ERNIE、Transformer,也会提升模型效果。
在文本匹配任务场景下,有4种不同的网络结构,分别是单塔pointwise、双塔pointwise、单塔pairwise、双塔pairwise。
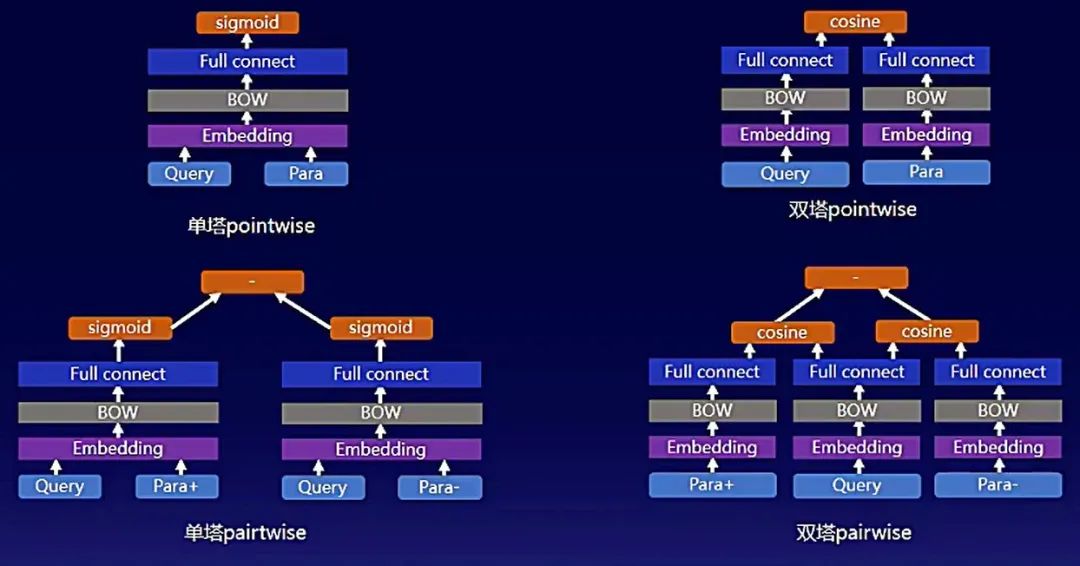
回到百度搜索问答场景下,在任务拆分这一步,我们将搜索问答拆分为文本分类、问答匹配两部分。文本分类、问答匹配对预测速度的要求都非常高,因此我们选择BOW网络。在文本分类时选择分类BOW,在问答匹配时选择双塔或者单塔BOW。
4.预训练模型
下图详细介绍了文心预训练模型的不同特点:
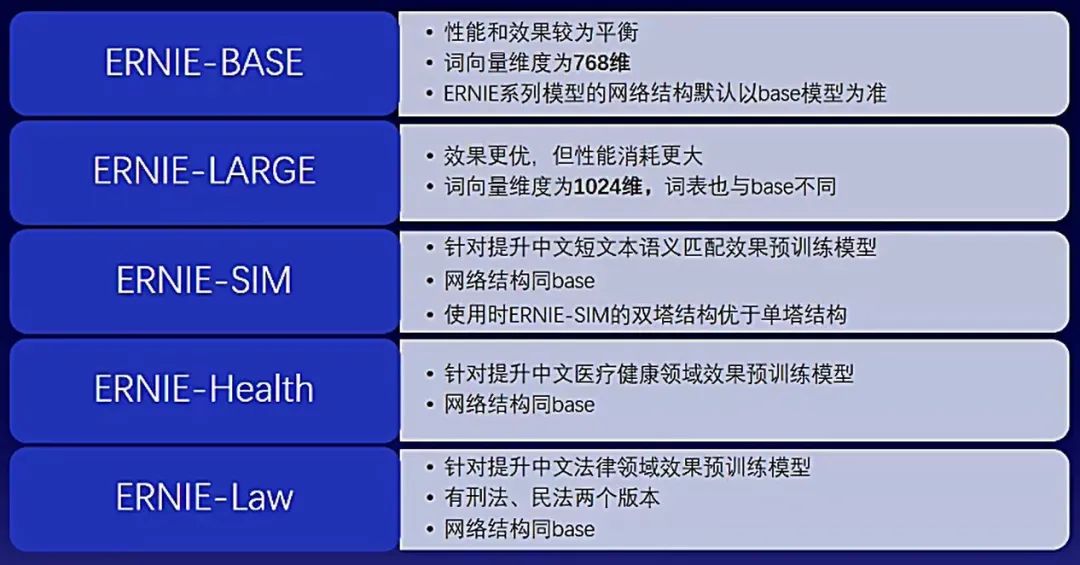
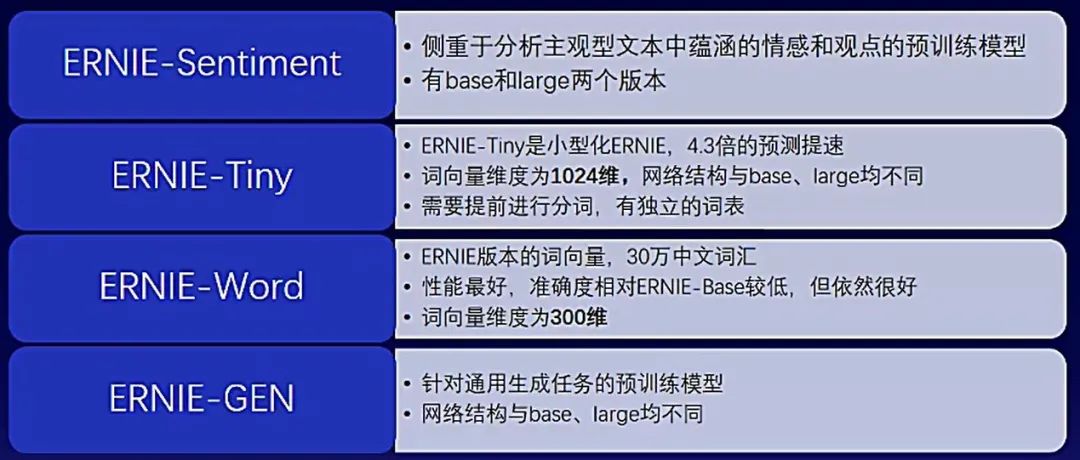
回到百度搜索问答场景,教师模型就需要选择预训练模型了。为提升教师模型的效果,其中的分类任务选择ERNIE-BASE 2.0,匹配任务选择ERNIE-SIM。
5.训练模型
为提升训练效率,如何选择GPU或CPU,可结合实际情况参考如下:

那么如何用好GPU、提升训练效率?大原则是GPU的利用率越高,训练速度越快。
首先,先小后大,先单机单卡,再单机多卡,最后多机多卡。一般来说,单机多卡的GPU利用率更高、更快。
其次,训练数据与batch-size方面的改进。如将大文件拆成多个小文件,设置合理的数据缓冲区以提升数据读取速度;根据神经网络中最大矩阵估算显存占用,估算batch-size等;多卡模式下多进程训练,添加混合精度训练等方法,提升训练速度。
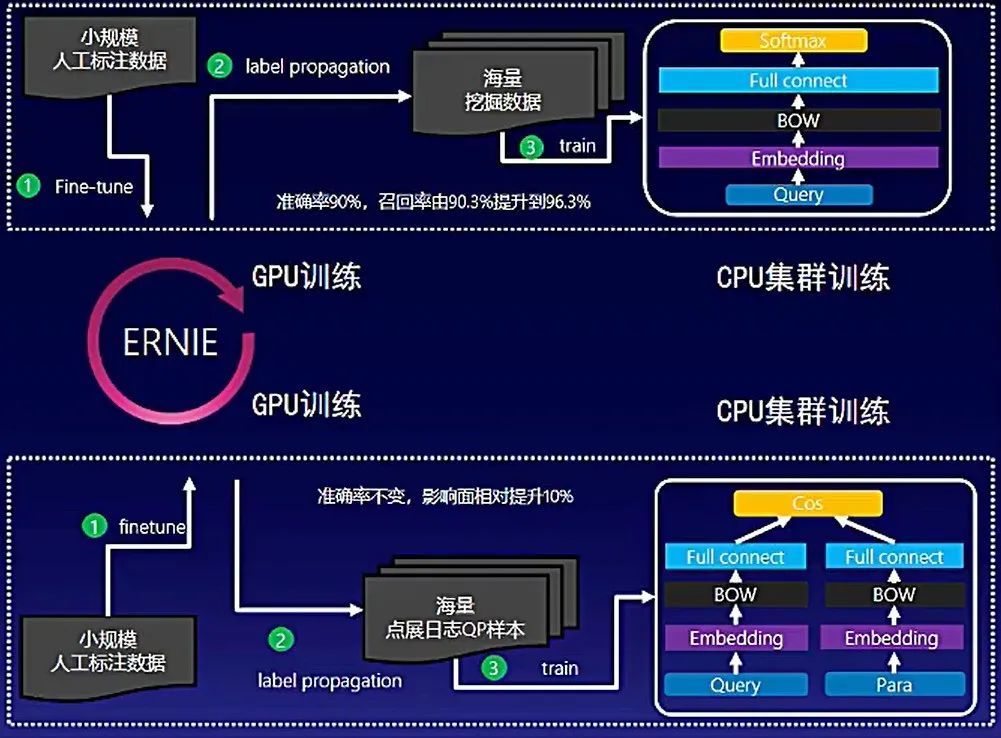
回到百度搜索问答场景,教师模型选择GPU训练,而学生模型是海量数据的浅层网络,用CPU集群训练效果更好。
6.提升效率
如何提升迭代效率,不浪费宝贵的开发时间?我的经验是,要选择合适的开发平台和工具:

另外,规范的开发流程也是提升迭代效率的关键。首先,需要分析业务背景,明确任务的输入和输出,将其抽象成已得到解决的NLP典型任务,并且明确评估指标。
第二步,快速实现NLP模型基线,建议大家准备几千条、格式规范的训练数据,进行无代码训练。同时选择好网络和预训练模型。
最后,不断优化模型效果。比如结合业务需求、进行更细致的技术选型,小数据调试,配置参数级训练、进行自主调参等。
7.优化效果
对于ERNIE系列预训练模型,模型优化最重要的一点是优化数据质量。即反复观察bad case,针对典型case增加正确样本;同时也可以考虑数据降噪相关策略,提升模型效果。
其次是优化数据数量。通过观察学习曲线来评估数据数量是否合适,可以考虑数据增强、数据蒸馏等策略。
第三点是增加数据特征,可以考虑增加非文本特征,或增加新的文本特征(如N-gram、subword、分词边界、词性等)。
第四点是优化调参与组网。大原则是通过学习曲线观察是否过拟合,若过拟合则降低模型复杂度、增加数据量,若欠拟合则增加模型复杂度。
One more thing
为了进一步降低企业应用AI的门槛与成本,EasyDL还重磅推出「万有引力」计划,为有AI应用需求的企业提供专项基金,详情请点击「阅读原文」。

— 完 —

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~





