在线深度学习:在数据流中实时学习深度神经网络
本文转自机器之心公众号。
参与:Nurhachu Null、刘晓坤
在线深度学习的主要困难是模型的容量、复杂度等设置很不灵活,即模型是静态的,而数据流是动态的。本论文提出了一种适应性的网络框架,结合 HBP 算法,使网络结构能随着数据的流入而逐渐扩展、复杂化。这使得模型同时拥有在线学习和深度学习的优点,并在多种在线学习模型和数据集的对比实验中都取得了当前最佳结果。
近年来,我们见证了深度学习技术在很多应用中的巨大成功。学习深度神经网络面临着很多挑战,包括但不限于梯度消失、逐渐减少的特征重用、鞍点(以及局部极小值)、大量的需要调节的参数、训练过程中内部协变量的变化、选择好的正则化方法的困难、选择超参数,等等。尽管出现了一些很有希望的进展,但都是被设计用来解决优化深度神经网络时遇到的具体问题的,这些方法中绝大多数都假设深度神经网络是以批量学习的设置来训练的,这种设置需要所有的训练数据集在学习任务开始前准备好。这对于现实中很多数据是以流的形式先后到达的任务而言是不可能的,而且也可能没有足够的内存空间来存储。此外,数据还可能表现出概念漂移(concept drift,Gama et al. 2014)。所以,一个更加理想的选择就是以在线的形式去学习模型。
与批量学习不一样,在线学习(Zinkevich 2003; Cesa-Bianchi and Lugosi 2006)指的是这样一类学习算法:它们在顺序到达的数据流实例中学习优化预测模型。这种动态学习使得在线学习更具有可扩展性和更高的内存效用。然而,现存的绝大多数在线学习算法都被设计成使用在线凸优化来学习浅层模型(例如,线性方法或者核方法,Crammer et al. 2006; Kivinen, Smola, and Williamson 2004; Hoi et al. 2013),它们并不能学习到复杂应用场景中的非线性函数。
在本文的工作中,我们尝试通过解决一些「在线深度学习,ODL」中的开放性问题,例如如何从在线设置中的数据流中学习深度神经网络(DNN),希望以此弥补在线学习和深度学习之间的鸿沟。一种可能的在线深度学习的方式就是,在每一轮在线训练中仅在一个单独的数据样本上直接应用标准的反向传播训练。这个方法虽然简单,但是由于某些关键的原因,它会很快失效。一个关键挑战是如何在开始在线深度学习之前选择合适的模型容量(例如,网络的深度)。如果模型太复杂(例如,非常深的网络),那么学习过程会收敛的很慢(梯度消失和逐渐减少的特征重用),因此就会损失在线学习的优势。另一个极端是,如果模型太简单,那么学习的能力又会特别局限,并且,缺少深度的话很难学习复杂的模式。在关于批量学习的文献中,通常用来解决这个问题的方式是在验证数据中做模型选择。不幸的是,在在线设置中设定验证数据是不太现实的,所以在在线学习的场景中使用传统的模型选择方法是不太现实的。在本文的工作中,我们提出了一种新型的用于在线学习的框架,它能够从顺序到达的数据流中学习深度神经网络模型,更重要的是,随着时间的推移,它能够适应性地将模型容量从简单扩展到复杂,很好地结合了在线学习和深度学习的优点。
我们的目标是设计一种在线学习算法,它能够以一个浅层网络开始,这时候具有快速收敛的优点;然后随着更多的数据到达,逐渐地自动转换成更深的模型(同时还能共享浅层网络学到的知识),以学习更加复杂的假设,通过深度神经网络容量的自适应特性有效地提升在线预测性能。为了达到这个目标,我们需要解决这些问题:什么时候改变网络的容量?如何改变网络的容量?如何在在线学习中同时做到这两点?我们在统一的框架中以一种数据驱动的方式,设计了一个优雅的解决方案来完成这一切。首先,我们修改已有的深度神经网络,即将每一个隐藏层与输出分类器连在一起。然后,不使用标准的反向传播算法,我们提出了新的对冲反向传播(Hedge Backpropagation)方法,它在每一轮的在线学习中都会评估每一个分类器的性能,并且能够通过使用对冲算法 (Freund and Schapire 1997) 中具有不同深度的分类器去扩展反向传播算法,以便在线地训练深度神经网络。这允许我们训练具有适应能力的深度神经网络,同时在浅层网络和深层网络之间共享知识。
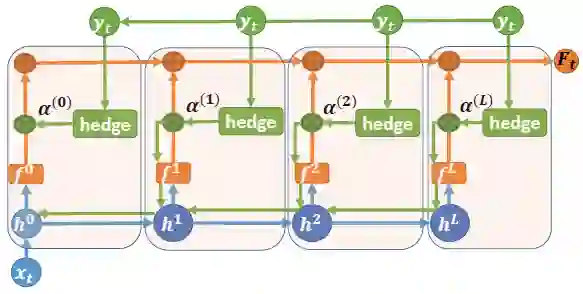
图 1:使用对冲反向传播(HBP)的在线深度学习框架。蓝色线代表计算隐藏层特征时的前馈信息流。橙色线表示经过对冲组合之后的 softmax 输出(表示预测)。绿色线表示使用对冲反向传播算法时的更新信息流。

算法 1:使用对冲反向传播的在线深度学习。
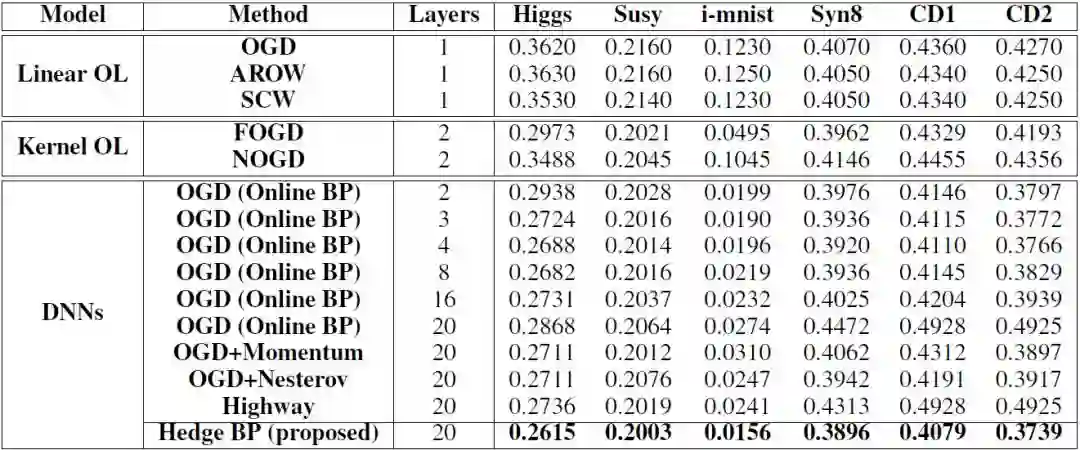
表 3:各种算法的最终在线累积错误率,加粗的是最佳性能。
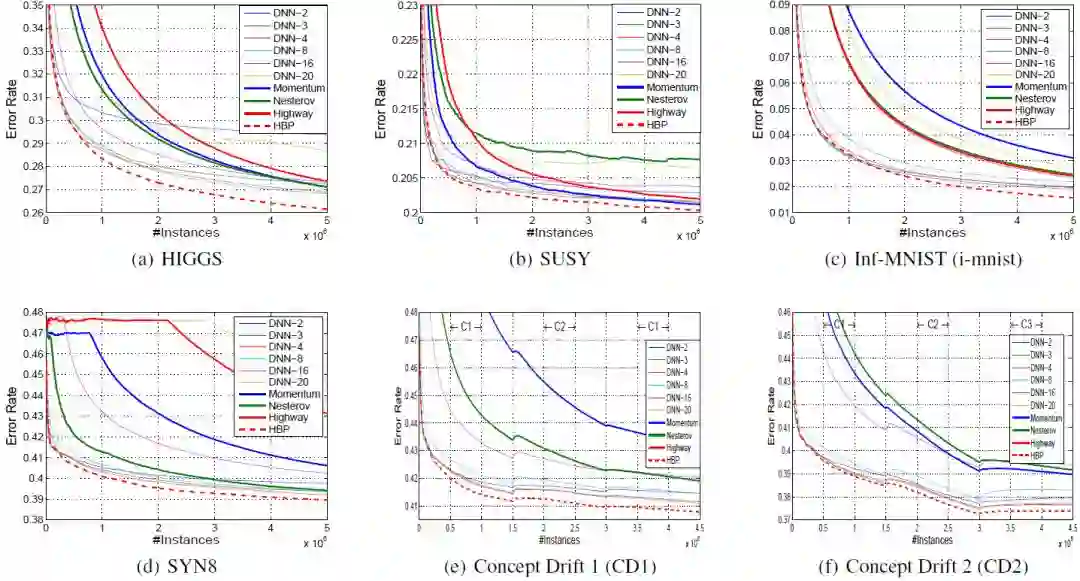
图 2:在线设置的深度神经网络在稳定场景和概念漂移场景中的收敛表现。
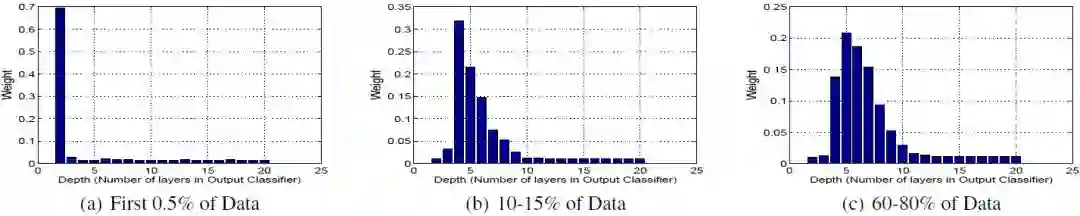
图 3:在 HIGGS 数据集上使用 HBP 算法,分类器的权重分布随时间的变化。
论文:Online Deep Learning: Learning Deep Neural Networks on the Fly

论文链接:https://arxiv.org/abs/1711.03705
摘要:深度神经网络(DNN)通常是通过反向传播算法以批量化的学习设置来训练的,它需要在学习任务之前就准备好所有的训练数据。这在现实中的很多场景中是不可扩展的,因为现实中的新数据都是以数据流的形式先后到达的。我们的目标是解决在高速数据流中进行在线参数设置的「在线深度学习」的一些开放性问题。与经常在浅层神经网络中最优化一些凸性目标函数的传统在线学习(例如,线性的/基于核的假设)不一样的是,在线深度学习(ODL)更加具有挑战性,因为深度神经网络中的目标函数的优化是非凸的,而且常规的反向传播在实际过程中也不能很好地奏效,尤其是在线学习的设置中。在这篇论文中,我们提出了一种新的在线深度学习框架,通过在线学习设置中使用一连串的训练数据,学习 DNN 模型的适应性深度,以解决这些挑战。实际上,为了高效地更新 DNN 中的参数,我们提出了一个新型的对冲反向传播(Hedge Backpropagation,HBP)方法,并在大规模的数据集上验证了我们的方法,包括稳定的场景和概念漂移的场景。
*推荐文章*
深度学习的这些坑你都遇到过吗?神经网络 11 大常见陷阱及应对方法
【深度神经网络 One-shot Learning】孪生网络少样本精准分类
加入极市Email List (http://extremevision.mikecrm.com/pdKKGSx),获取极市最新项目需求,以及前沿视觉资讯等。






