概率图模型笔记(PART II)隐马尔科夫模型

 前情提要:
概率图模型笔记(PART I)
前情提要:
概率图模型笔记(PART I)
写在前面
隐马尔科夫模型(Hidden Markov Model,以下简称HMM)是比较经典的机器学习模型了,它在语音识别,自然语言处理,模式识别等领域得到广泛的应用。那么什么样的问题需要HMM模型来解决,一般有以下两个特征:
(1)我们的问题是基于序列的,比如时间序列,或者状态序列;
(2)我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
HMM模型基础
首先,我们要了解下什么是马尔科夫模型。Markov Model很大,主要有四个细分领域。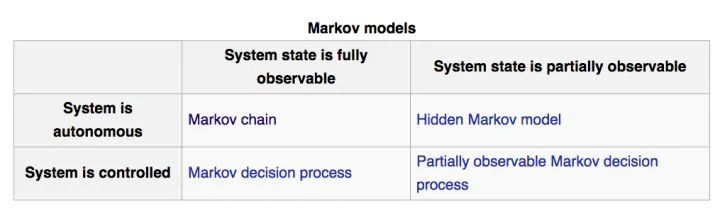
而HMM是马尔科夫过程的一种扩展,除了一组观测序列,我们还有相对应的一组隐藏序列,还是用图来表示
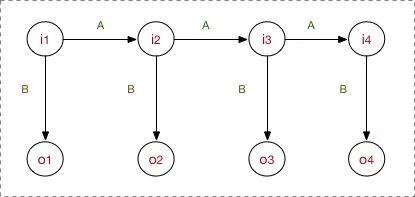
对于HMM 模型,假设Q是所有可能的隐藏状态的集合,V是所有可能的观察状态的集合,
对于一个长度为T的序列,I对应状态序列,O对应观察序列,
其中,任意一个隐藏状态 i 属于集合Q, 任意一个观察状态 o 属于集合V,如上图 HMM模型两个重要的假设:
-
「齐次马尔科夫链假设」,即任意时刻的隐藏状态只依赖于它前一个隐藏状态。当然这样假设有点极端,因为很多时候我们的某一个隐藏状态不仅仅只依赖于前一个隐藏状态,可能是前两个或者是前三个。但是这样假设的好处就是模型简单,便于求解(但同时也限制了HMM模型的效果)。如果在时刻t的隐藏状态是 ,在时刻t+1的隐藏状态是 , 则从时刻t到时刻t+1的HMM状态转移概率 可以表示为:
这样 可以组成马尔科夫链的状态转移矩阵A:
-
「观测独立性假设」,即任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态,这也是一个为了简化模型的假设。如果在时刻t的隐藏状态是 , 而对应的观察状态为 , 则该时刻观察状态 在隐藏状态 下生成的概率为 ,满足:
这样 可以组成观测状态生成的概率矩阵B:
除此之外,还需要一组在时刻t=1的隐藏状态概率分布Π:
一个HMM模型,可以由隐藏状态初始概率分布Π, 状态转移概率矩阵A和观测状态概率矩阵B决定。Π,A决定状态序列,B决定观测序列。因此,HMM模型可以由一个三元组λ表示如下:
HMM属于典型的生成式模型,即我们需要从训练数据中学到数据的分布,也就是上面介绍的HMM五要素:隐藏状态集合I,观测状态集合O, 初始隐状态概率分布Π,转移概率矩阵A以及发射概率矩阵B。
HMM观测序列的生成
那么HMM观测序列是怎么生成的呢?
输入:HMM模型参数
, 观测序列的长度T;
输出:经HMM模型的观测序列
流程:
-
根据初始状态概率分布生成隐藏状态 -
for t from 1 to T: -
按照隐藏状态 的观测状态分布B生成观测状态 ; -
按照隐藏状态 的状态转移概率分布A生成隐藏状态
所有的一起组合形成观测序列
HMM模型的三个问题
概率计算问题
即给定模型 和观测序列 ,计算在模型λ下观测序列O出现的概率P(O|λ)。这个问题的求解需要用到前向后向算法。这个问题是HMM模型三个问题中最简单的。
-
直接计算法
直观地,我们只要知道模型参数,就可以按照概率公式计算出给定观测序列的出现概率。虽然这种方式理论上可行但是最后计算量太大,不过我们可以通过了解这个过程来理解HMM是怎么运行的。
首先明确问题,我们最后要求得是P(O|λ),于是可以写成下列等式:
其中,右侧第一项是通过转移矩阵求一个隐藏状态序列的概率公式,右侧第二项是通过发射矩阵求由隐藏序列到最后观测序列的概率,因为隐藏状态有I种,所以最后需要把所有可能情况进行加和求解。也就是
但是利用上述过程求解计算量非常大,是 阶的,这种算法不可行。
-
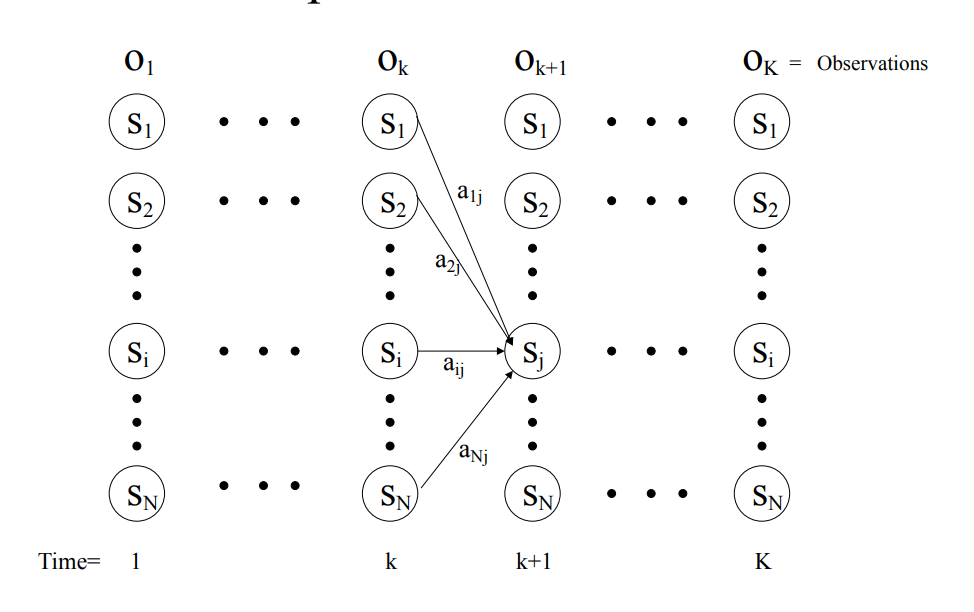
前向算法
首先定义前项概率 :给定HMM模型λ,定义到时刻t时部分观测序列为O1,O2,,,Ot,且隐藏状态为 ,即
前向算法流程:输入:HMM模型和观测序列;
输出:观测序列概率
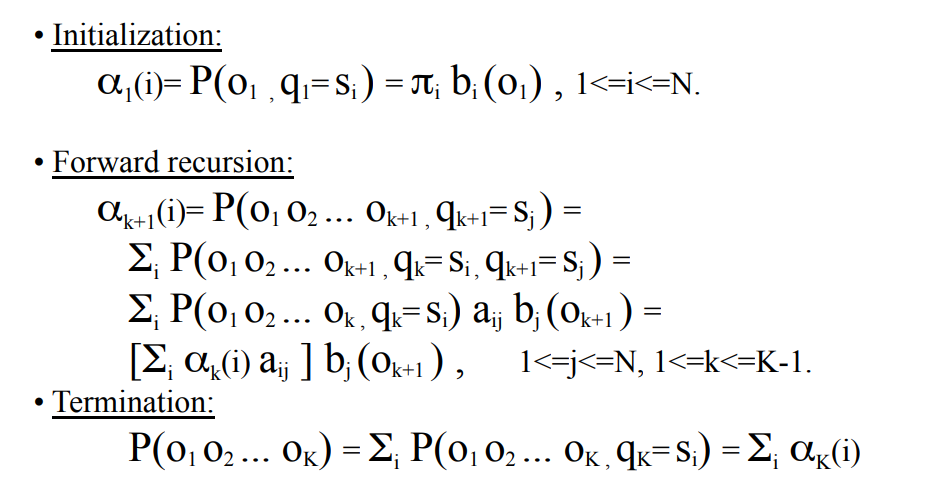
模型参数学习问题
即给定观测序列 ,估计模型 的参数,使该模型下观测序列的条件概率P(O|λ)最大。这个问题的求解需要用到基于EM算法的「鲍姆-韦尔奇算法」。这个问题是HMM模型三个问题中最复杂的。
根据训练数据是包括观测序列和对应的隐藏序列还是只有观测序列可以分为有监督学习和非监督学习。
-
有监督学习
给定数据集,其实就是根据三元组参数的定义去数词的频数。。。
-
转移概率
-
观测概率
-
初始状态概率
-
非监督学习
可见有监督学习情况求解模型的参数还是比较直观简单的,但是在很多时候,我们无法得到观测序列对应的隐藏状态序列,此时求解HMM模型的参数就会复杂一些,就会用到「Baum-Welch算法」,其实也就EM算法,只不过那个时代EM算法还没有提出概念。
我们的训练数据为,对于任意一个样本d,观测序列,其对应的未知的隐藏状态序列为:
-
Baum-Welch算法第一步(EM算法的E步):求Q函数
其中 表示HMM模型参数的当前估计值.
在M步我们要极大化上式。由于 ,而分母是常数,因此我们要极大化的式子等价于:
我们又有联合分布:
将其代入上述需要极大化的式子:
-
Baum-Welch算法第二步(EM算法的M步)
极大化Q函数,求模型参数A, B, PAI。这里我们以对模型参数PAI求导为例,由于PAI只在上式括号里的第一项出现,因此对PAI的极大化式子为,
同时注意到 还满足条件 , 因此根据拉格朗日乘子法,可以写出关于 的拉格朗日函数为:
求导得到:
令i分别从1到N,上式可以得到N个式子,然后把这N个式子相加和得到:
这样我们就得到了 的表达式
对模型参数A和B也是同样的思路求解。
Baum-Welch算法流程:
输入:D个观测序列样本
输出:HMM模型参数
流程:
1.随机初始化所有的参数
2.对于每个样本 , 用前向后向算法计算
3.更新模型参数:4.如果参数值已经收敛,则算法迭代结束,否则继续从第二步开始迭代
预测问题,也称为解码问题
即给定模型 和观测序列 ,求给定观测序列条件下,最可能出现的对应的状态序列,这个问题的求解需要用到基于动态规划的维特比算法。这个问题是HMM模型三个问题中复杂度居中的算法。
「维特比算法概述」
需要注意的是维特比算法并不是HMM所独有的,它是一种通用的解码算法,是基于动态规划的来求序列最短路径的方法。
首先定义两个变量
-
第一个是在时刻t隐藏状态为i所有可能的状态转移路径 中的概率最大值 ,记为
由 的定义可以得到 的递推表达式:
-
第二个变量是由第一个局部状态递推得到。我们定义在时刻t隐藏状态为i的所有单个状态转移路径中概率最大的转移路径中的第t-1个节点的隐藏状态为 ,其递推表达式为:
有了这两个局部状态,我们就可以从时刻0一直递推到时刻T,然后利用
记录的前一个最可能的状态节点回溯,直到找到最优的隐藏状态序列。
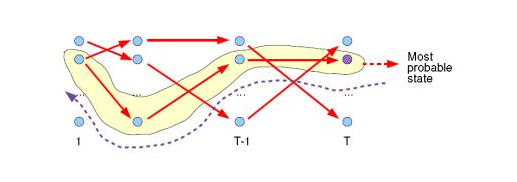
「维特比算法流程」
输入:HMM模型蚕食,观测序列
输出:最有可能的隐藏状态序列
流程:
1)初始化局部状态:2)进行动态规划递推时刻t的局部状态:
3)计算时刻T最大的 ,即为最有可能的隐藏状态序列的概率。计算时刻T最大的 ,即为时刻T最有可能的隐藏状态
4)利用局部状态 开始回溯,得到每个时刻的最优状态
最终得到最优路径,即最有可能的隐藏状态序列
- END -

推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




