每周一起读 × 招募 | WWW 2019:基于层次化强化学习的多源搜索展示优化

”每周一起读“是由 PaperWeekly 发起的论文共读活动,我们结合自然语言处理、计算机视觉和机器学习等领域的顶会论文和前沿成果来指定每期论文,并且邀请论文作者来到现场,和大家展开更有价值的延伸讨论。
我们希望能为 PaperWeekly 的各位读者带来一种全新的论文阅读体验、一个认识同好、找到组织的契机、一次与国际顶会论文作者当面交流的机会。
6 月 23 日(周日)下午 2 点,“每周一起读”将邀请清华大学计算机系本科生高信龙一,和大家分享其发表于计算机领域顶级会议 WWW 2019 的最新文章。该论文研究电子商务环境下的多源搜索展示优化,提出将整个搜索页面设计建模成一个层次化序列决策过程,用以更好地捕捉用户的行为与意图。


高信龙一
清华大学计算机系本科生
高信龙一,清华大学计算机系本科生,从事自然语言处理方向研究,导师为黄民烈副教授。他预计于 2019 年在清华大学计算机系取得工学学士学位。他的研究兴趣主要在对话系统以及强化学习。他在人工智能国际会议 WWW, ACL, AAAI 等上发表了数篇论文。
WWW 2019


Abstract: In this paper, we investigate the task of aggregating search results from heterogeneous sources in an E-commerce environment. First, unlike traditional aggregated web search that merely presents multi-sourced results in the first page, this new task may present aggregated results in all pages and has to dynamically decide which source should be presented in the current page. Second, as pointed out by many existing studies, it is not trivial to rank items from heterogeneous sources because the relevance scores from different source systems are not directly comparable. To address these two issues, we decompose the task into two subtasks in a hierarchical structure: a high-level task for source selection where we model the sequential patterns of user behaviors onto aggregated results in different pages so as to understand user intents and select the relevant sources properly; and a low-level task for item presentation where we formulate a slot filling process to sequentially present the items instead of giving each item a relevance score when deciding the presentation order of heterogeneous items. Since both subtasks can be naturally formulated as sequential decision problems and learn from the future user feedback on search results, we build our model with hierarchical reinforcement learning. Extensive experiments demonstrate that our model obtains remarkable improvements in search performance metrics, and achieves a higher user satisfaction.
时间:6 月 23 日(周日) 14:00–16:00
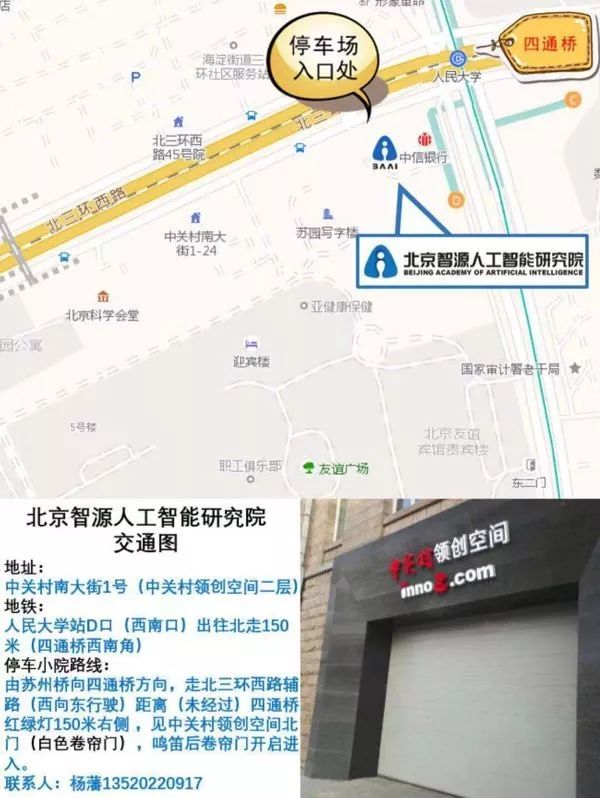
地点:北京智源人工智能研究院102会议室
北京市海淀区中关村南大街1-1号
中关村领创空间(信息谷)
长按识别二维码,即刻报名👇

报名截止日期:6 月 22 日(周六)12:00
* 场地人数有限,报名成功的读者将收到包含电子门票二维码的短信通知,请留意查收。
注意事项:
* 如您无法按时到场参与活动,请于活动开始前 24 小时在 PaperWeekly 微信公众号后台留言告知,留言格式为放弃报名 + 报名电话;无故缺席者,将不再享有后续活动的报名资格。

1 / 扫码关注
扫码关注 PaperWeekly👇

PaperWeekly

清华大学计算机科学与技术系

北京智源人工智能研究院

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 立刻报名




