最新论文:用于视觉SLAM的体素地图
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自当SLAM遇见小王同学

在现代视觉SLAM系统中,从关键帧中检索候选地图点是一种标准做法,用于进一步的特征匹配或直接跟踪.在这项工作中,我们认为关键帧不是这项任务的最佳选择,因为存在几个固有的限制,如弱几何推理和较差的可扩展性.我们提出了一种体素图表示来有效地检索视觉SLAM的地图点.通过以光线投射方式对摄像机frustum进行采样来查询来自摄像机姿态的可见点,这可以使用有效的体素散列方法在恒定时间内完成.与关键帧相比,使用我们的方法检索的点在几何上保证落在摄像机的视野内,并且遮挡点可以在一定程度上被识别和去除.这种方法也很自然地适用于大场景和复杂的多摄像机配置.实验结果表明,我们的体素图与具有5个关键帧的关键帧图一样有效,并且在EuRoC数据集上提供了显著更高的定位精度(在RMSE平均提高46%),所提出的体素图表示是视觉SLAM中基本功能的一般方法,并且可广泛应用.
同步定位和建图是机器人学的基础,在各种现实应用中起着举足轻重的作用,如增强/虚拟现实和自主驾驶.过去十年,这一领域取得了快速进展.今天最先进的SLAM系统,特别是视觉惯性SLAM,在功率和内存受限的设备上实时执行,并提供准确和鲁棒的估计.尽管该领域仍然存在挑战,但是SLAM已经达到了能够成功进行商业应用的成熟程度.基于关键帧的SLAM,在其他范例中,如基于过滤器的方法,可以说是当今最成功的一种.特别是基于关键帧的SLAM依赖于关键帧和可见地标的联合非线性优化,即BA,并获得了优于基于滤波器的方法的精度.继一些开创性工作之后,大多数最先进的稀疏SLAM系统使用并行线程进行跟踪(图像流计算实时姿态)和BA来减轻非线性优化的计算开销.对于直接和基于特征的方法,跟踪过程的中心任务是找到2D-3D对应关系,在当前图像和地图中的观察之间(例如3D点).虽然不同类型的地图用于稠密的SLAM,但很少有人研究稀疏SLAM的替代地图表示.基于稀疏关键帧的方法使用来自附近关键帧的信息来将图像与地图点相关联.这是一种强有力的启发式方法,在许多成功的系统中使用.另一类SLAM系统使用几何图元.
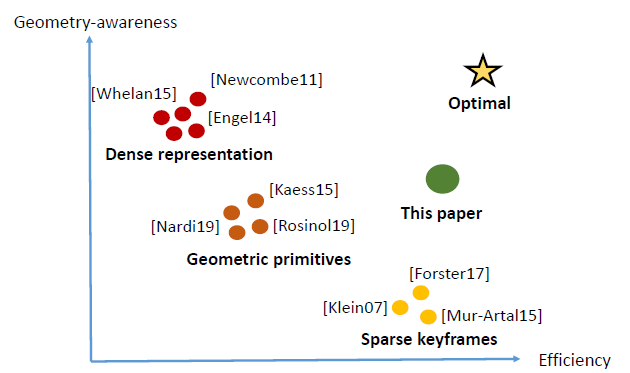
(图一)
最佳的SLAM系统应该是高效的,并且对地图有几何理解(用金星表示).直接方法(红点)将每个关键帧与半密集深度图相关联.他们有更多的场景信息,但效率不高.基于稀疏关键帧的SLAM(黄色点)将当前帧中的要素与附近重叠关键帧中的3D点相关联.虽然它们在计算上是高效的,但是它们不能提供对场景几何的更高层次的理解.其他使用几何图元(橙色点)的表示平衡了几何信息和效率,但对场景进行了假设,没有像稀疏关键帧方法那样实现效率.该文提出了一种用于稀疏SLAM的体素图,试图向SLAM的最优地图表示迈进一步.
理想情况下,地图表示应该知道场景的几何形状,并且在计算时间和内存方面是高效的.图1显示了不同的地图表示如何在这些轴上执行.理想的表示应该允许更好的几何推理,这带来了更高的准确性.但在效率方面仍然与基于关键帧的方法相当.
我们沿着这些轴比较了基于稀疏关键帧的地图表示的有效性:
-
几何感知:在稀疏SLAM中,使用关键帧和它们的可见点(即共视图)作为地图只允许有限的几何推理.共可见度图没有遮挡的概念,并且难以确定和过滤遮挡点,这可能导致错误的数据关联和错误的估计.从地图中检索到的点最好与视野是极好的.不幸的是,来自重叠关键帧的点几乎没有几何保证,可能会有误报和漏点. -
效率:与使用所有帧相比,关键帧在BA中的有效性来自于它们保留了大部分信息的事实.对于一个由N个关键帧组成的局部地图,增加N通常会提高鲁棒性,但会导致更长的时间.此外,关键帧系统的设计对于多摄像机系统而言变得复杂.例如,将来自所有摄像机的图像设置为关键帧会保留大部分信息,但会引入高度冗余.
因此,我们认为使用关键帧对于跟踪过程中的数据关联并不是最佳的,尽管对不同的任务(即BA和点检索)使用一种通用的表示法是有诱惑力的.考虑到上述问题,SLAM的理想地图表示应该被设计用于高效、准确、几何感知的点检索,而不是简单地重用BA中的关键帧.
在这项工作中,我们提出了一个可伸缩的和几何感知的体素图表示.通过将环境表示为体素,可以直接指定地图覆盖范围,而不是隐式依赖于关键帧参数.从地图中检索点相当于访问感兴趣区域中的体素,此外由于体素只是3D点的容器,因此修改体素图中的信息(例如从新添加的关键帧添加点)并不重要.为了查询SLAM中数据关联的候选点,提出了一种基于射线投影的方法.具体来说,我们从图像中的规则网格向地图中投射选定的像素,并沿着射线收集体素中的点.尽管简单,这种方法有两个主要优点.首先我们的光线投射方法返回的点保证是地图中落在摄像机FoV中的所有3D点,对于这些点,基于关键帧的方法只能依赖于弱协方差假设(见图6).第二,一旦我们在沿着射线的邻近体素中遇到足够的3D点,我们就可以停止检查更远的体素.这使得我们的方法能够在一定程度上对遮挡进行推理.可以说,这并没有像稠密模型那样提供完整的几何推理,但效率要高得多.据我们所知,这是第一个旨在将基于体素的表示结合到稀疏SLAM系统中的工作.作为一种通用方法,我们的voxelmap表示可以用作各种SLAM系统的构建模块.

为了证明我们的地图表示的实用价值,我们采用了一种基于关键帧的稀疏SLAM-SVO的最新技术,以使用基于体素哈希的地图和光线投射点查询方法.值得注意的是,所提出的方法对于SLAM来说具有广泛的适用性.
SVO结合了直接和基于特征的方法的优势,特别是它首先通过在已知深度的稀疏patches上最小化光度误差来将新图像与先前图像对齐.这给出了关于新帧的姿态的良好先验.使用给定的先验,系统找到与新帧重叠的关键帧,通过将当前帧中的选定点投影到本地地图中的关键帧(按到当前关键帧的距离排序)来找到重叠的关键帧,直到找到一组M个重叠的关键帧.由于在大多数平移运动情况下,最接近的M个重叠关键帧是最新的M个关键帧,因此平均查询时间仅取决于M的值,而不取决于地图大小.通过Lucas-Kanade跟踪,系统进一步在新图像中搜索来自这些关键帧的点的匹配.一旦建立了对应关系,就通过仅运动的BA来估计姿态.系统还具有单独的建图线程,该线程使用贝叶斯滤波器进行深度估计.
提出的体素图表示法是基于[14]等人的工作.它将地图存储为哈希表,如图2所示
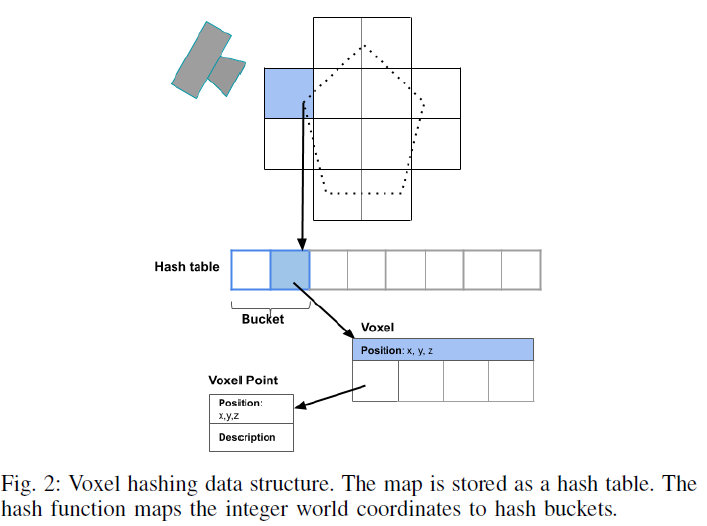
文献14:Real-time 3d reconstruction at scale using voxel hashing我们将实验结果分为两部分:模拟实验和真实世界实验.在模拟中,我们比较了我们的体素地图和光线投射地图查询与基于原始关键帧的方法在地图查询时间和遮挡处理方面的性能.我们还在EuRoC数据集上进行了实验,重点是重叠关键帧图的姿态估计精度.
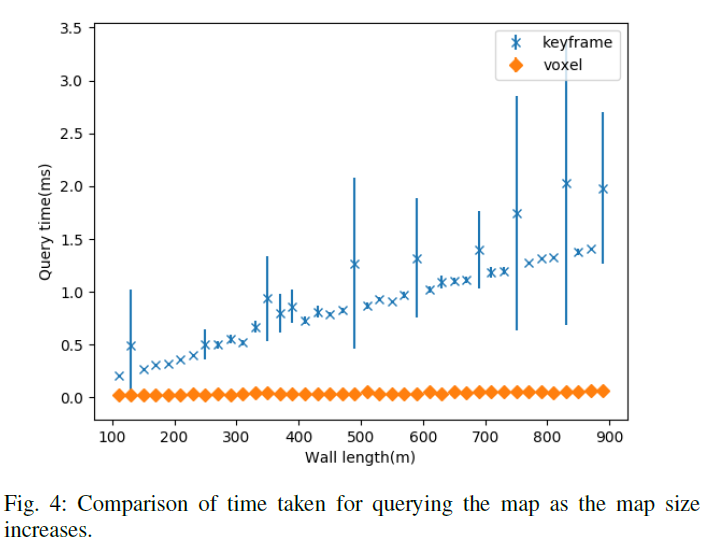
地图查询时间:这个实验的目标是显示随着地图大小的增长,我们的方法比关键帧缩放得更好.为此,我们模拟了一幅由直墙组成的地图.然后我们沿着一条平行于墙壁的线在10个位置查询地图(即获得可见的3D点).对于不同的地图尺寸,我们将墙的长度从100米增加到900米.为了确保地图点的密度相同,地图点从1000增加到9000.我们建立了两种不同的地图表示:
-
Naive-Keyframe:我们在墙上均匀地采样关键帧,这样每个点都属于一个唯一的关键帧.每个关键帧中的最大点数被固定为100.因此随着墙的长度增加,地图中的关键帧数量也会增加.这是为了模拟一个探索场景,其中地图不断扩展.为了查询给定姿态下的可见点,我们迭代关键帧中的点,一旦从查询姿态中有一个点可见,我们就认为这个关键帧与查询姿态重叠,并继续到下一个关键帧.查询时间是检查所有关键帧的总时间.
-
Voxel-hashing:我们分配了足够的体素来保存所有的地图点,体素网格大小固定为2m.在查询时,我们使用基于光线投射的方法来返回可见点的列表.
随着地图大小的变化,我们比较了上述表示的地图查询时间,重复每个实验5次。图4中绘制的结果显示,对于较小的地图大小,所有方法都有相似的查询时间.然而随着地图大小的增加,基于关键帧的方法的查询时间几乎线性增加;相比之下,使用我们方法的查询时间保持不变.这使得我们的方法在管理大规模地图点时特别有用.
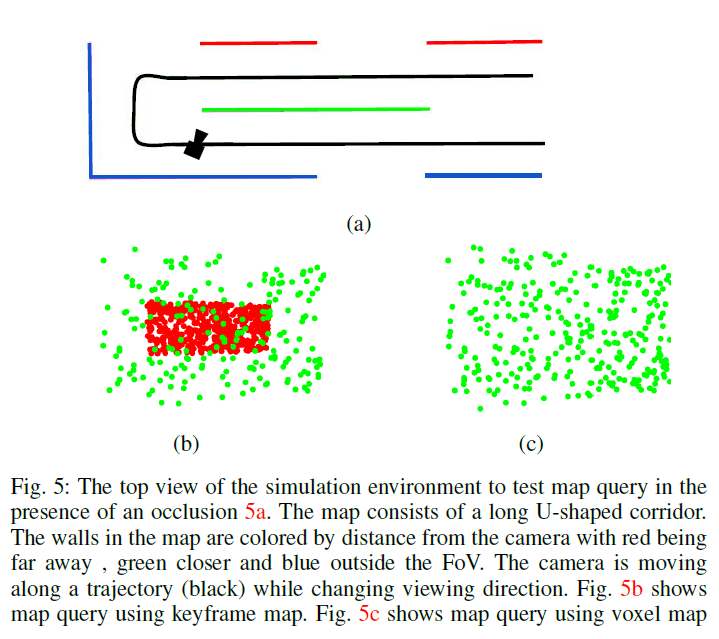
几何感知:在这个实验中,我们对验证我们方法的遮挡处理能力很感兴趣.我们模拟了一个类似走廊的环境和一个穿过走廊的摄像机轨迹,如图5a所示,基于原始关键帧和体素图的生成方式与前面的模拟相似.然后,我们在地图上查询转弯点处沿相机轨迹的姿态的可见点(如图5a所示).然后将可见点投影到图像平面上进行可视化,这些点的颜色表示与摄像机的距离(红色表示距离较远,绿色表示距离较近).照相机正在观察不同距离的两个平面的点.理想情况下,平面上距离较远的点(即红色点)应该被距离较近的点(即绿色点)遮挡.而原始关键帧查询没有遮挡的概念(图5b);由于光线投射查询方案,我们的方法能够识别沿着相同光线被遮挡的更远的点(图5c).
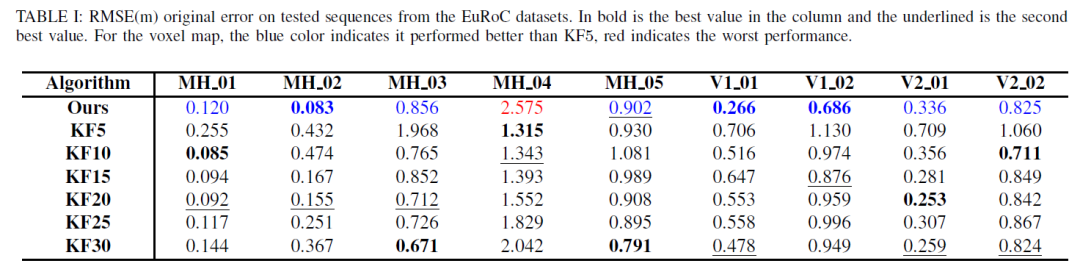
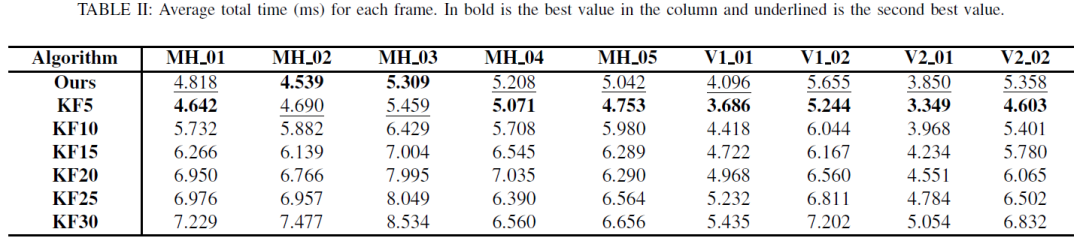
我们在EuRoC上以两种配置运行了单目版本的SVO:将地图中的关键帧数量从5个增加到30个;测试序列的均方根误差(RMSE)为SIM3与所有帧对齐计算.结果如表一所示.我们还计算了数据集每帧整个系统所需的时间.结果如表二所示.从表1可以看出,随着地图大小从5个关键帧增加到30个关键帧,RMSE总体上减少了.表二显示,随着地图大小的增加,计算时间增加,这显示了关键帧图在计算时间和估计误差方面的效率-精度权衡.相比之下,体素图能够以更低的计算时间获得更好的精度.它并不总是优于所有关键帧序列,因为体素图的性能取决于环境和体素大小.在MH04的情况下,体素图在轨迹上没有一致的比例,这导致了更高的RMSE.我们强调,我们的方法在计算时间方面的表现类似于最低关键帧图大小(5个关键帧图,即KF5),同时实现了更高的精度.例如与KF5相比,我们在EuRoC序列上实现了3%(MH 05)至80%(MH02)的平均46.2%的改善.体素图的颜色表示相对于KF5的性能,蓝色表示体素图相对于KF5的改进,红色表示最差的性能.我们还在图6的MH01中显示了定性结果,其中我们可以看到体素图返回的点与相机的FoV更加一致.
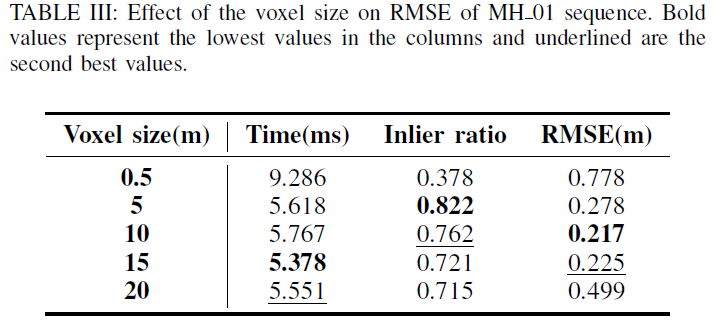
表三中的结果表明,体素尺寸影响估计误差:
本文针对稀疏SLAM提出了一种可扩展的几何感知体素图,旨在跟踪过程中替代关键帧进行数据关联.地图被组织在体素中,并且每个体素可以在恒定的时间内使用其位置上的散列函数来访问.使用体素哈希方法,通过在恒定时间内对摄像机平截头体进行采样,可以有效地查询摄像机姿态中的可见点,这使得所提出的方法可以很好地适应大场景.此外通过以光线投射的方式对camera frustum进行采样,我们能够处理遮挡,这是使用关键帧不可能做到的.最后我们使用模拟以及真实世界数据验证了所提出的方法相对于关键帧的优势.
从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓



