![]()
本文内容整理自 PaperWeekly 和 biendata 在 B 站组织的直播回顾,点击文末阅读原文即可跳转至 B 站收看本次分享完整视频录像,如需嘉宾课件,请在 PaperWeekly 公众号回复关键词课件下载获取下载链接。
题图出处:economiststalkart.org
作者简介:
周博言,旷视南京研究院研究员,本科和硕士毕业于南京大学。研究方向为计算机视觉,主要包括长尾识别、目标检测等,曾参与多项计算机视觉国际竞赛,获得两项冠军,一项亚军,在 CVPR 2020 发表 Oral 论文一篇。
长尾分布是现实世界的一大难题,指的是少部分类别占据了大量样本,而大部分类别却只有少数样本。解决这一问题最主流的方法是类别再平衡策略,即通过重采样或代价敏感重加权来缓解类别不平衡问题。
这些策略之所以起效,是因为其显著提升了分类器的性能,但同时又会在一定程度上损害深度特征的表征能力。因此,我们提出了一个统一的双边分支网络(Bilateral-Branch Network BBN),两个分支各司其职,从而兼顾网络的特征表示能力和分类能力。
此外,我们还提出了一种全新的累积学习(Cumulative Learning)策略,配合 BBN 网络首先进行通用特征的学习,随后逐渐将注意力转移到尾部类的识别上。
![]()
什么是图像任务中的长尾识别问题?
在介绍长尾识别任务之前,我们先来看一下普通的图像分类任务。Mnist 和 ImageNet 是两个比较有名的图像分类数据集,Mnist 是一个手写字体的分类数据集,主要区分 0~9 十个数字。ImageNet 是一个比较庞大的分类数据集,一共包含了 1000 个类别,涵盖了现实世界里各种常见的类型。
随着近年来深度学习的不断发展,以上两个深度学习模型都能够达到非常好的效果。Mnist 上的 SOTA 可以达到近 99.8% 的 Top1 accuracy,即使是 ImageNet 这种百万量级的数据集也可以达到 88% 的 Top1 accuracy。
但是这两个数据集都有一个比较明显的特点,它们类别标签的分布是非常均匀的,也就是说每个类的样本图片数量几乎完全一致,这是一种比较理想的图像识别任务,但是实际情况很难达到这样的条件。
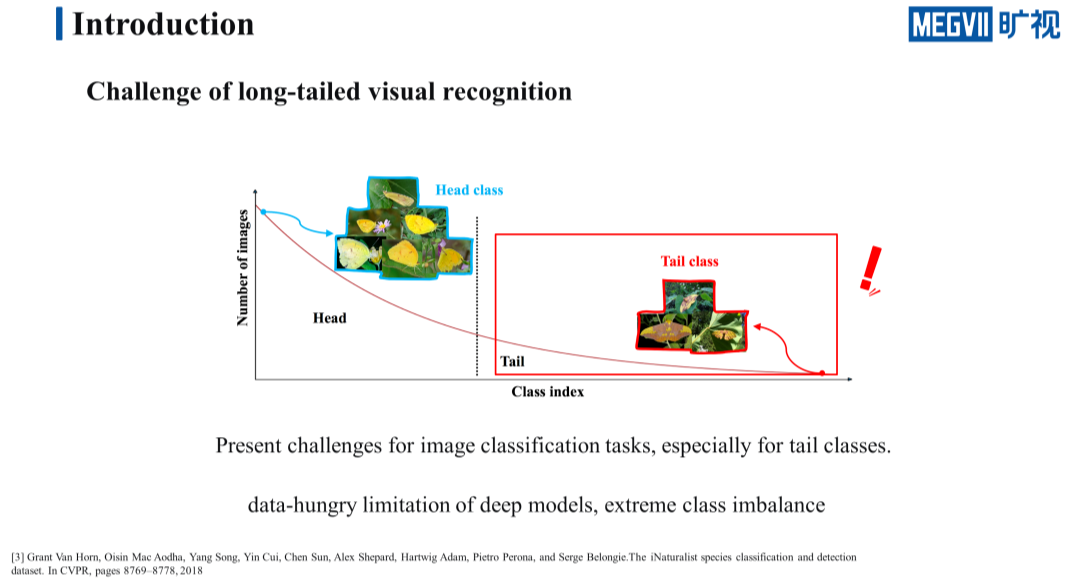
我们以图中的三辆车为例,这三辆车从左往右依次是雪佛兰、奔驰还有兰博基尼,显然这三辆车型的价格是越来越昂贵的,在现实世界里出现的概率其实也是依次减小的。像这种类别样本的数量逐级递减的情形就是我们所说的长尾分布,长尾分布在现实世界里无处不在。
我们将类别数量随着类别索引的变化画成一条曲线,它看起来就像一条长长的尾巴,这就是长尾分布名称的由来。上图中褐色的曲线就是一条长尾分布的曲线,在这条褐色曲线的中间画一条黑色的虚线。这条黑色虚线左边的类别统称为头部类,头部类的类别数量少,但每一类的样本却很多。虚线右边的类别统称为尾部类,尾部类的类别数量多,但是每一类样本却很少。
虽然深度学习模型在类别均匀的数据集上能够取得不错的效果,但在长尾分布的数据集中效果却往往不佳,这主要是由于尾部类效果比较差。首先,因为深度学习模型本身是数据驱动的,尾部类的数据少,自然就导致了尾部类的欠拟合;其次,因为尾部类和头部类的样本数量差距太大,这种极端的数据不平衡会导致网络倾向于把 tail 类的样本错分成 head 类。这两者都导致了长尾分布数据集上尾部类的识别性能不好。
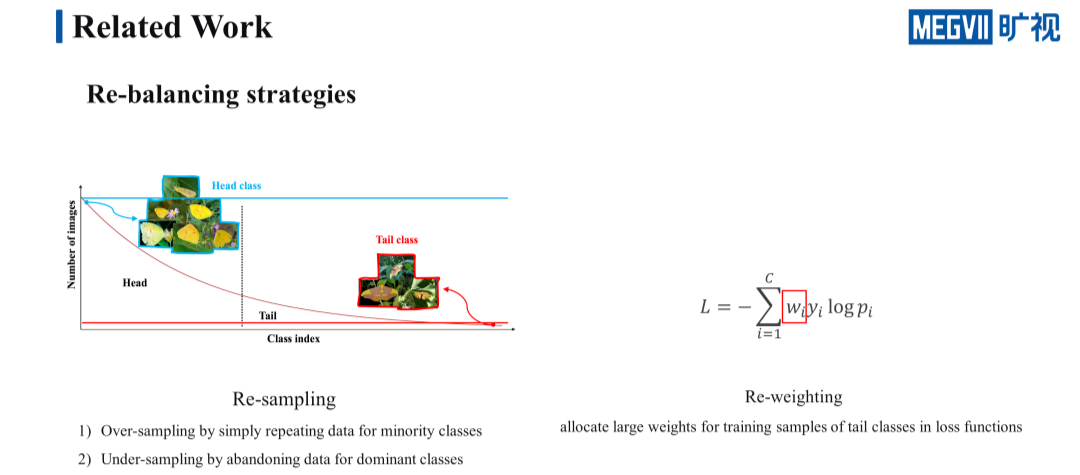
那么在面临这种长尾问题时都有哪些解决方案呢?目前作为主流且有效的方法是 re-balancing 一类的方法,re-balancing 可以细分成两类,分别是 re-sampling 和 re-weighting。
re-sampling 是通过重采样的方法,让训练集和测试集尽量维持一致的分布。re-sampling 又可以细分成 over-sampling 和 under-sampling,over-sampling 是指对尾部类数据进行重复采样,使得它达到头部类数据一样的水准。under-sampling 则反过来,主要是通过摒弃一些 head 类的数据,使得它和 tail 类达到相同的水准。
除了 over-sampling 和 under-sampling 之外,还有一些介于这两种采样之间的方法,它们既会舍弃部分头部类的数据,又会对尾部类的数据进行重复采样,总而言之,都是为了使训练集和测试集的分布保持一致。
re-weighting 是直接在损失函数上对 loss 进行加权,给 tail 类赋予更大的权重,从而让网络可以更加关注 tail 类的损失,提升 tail 类的性能。
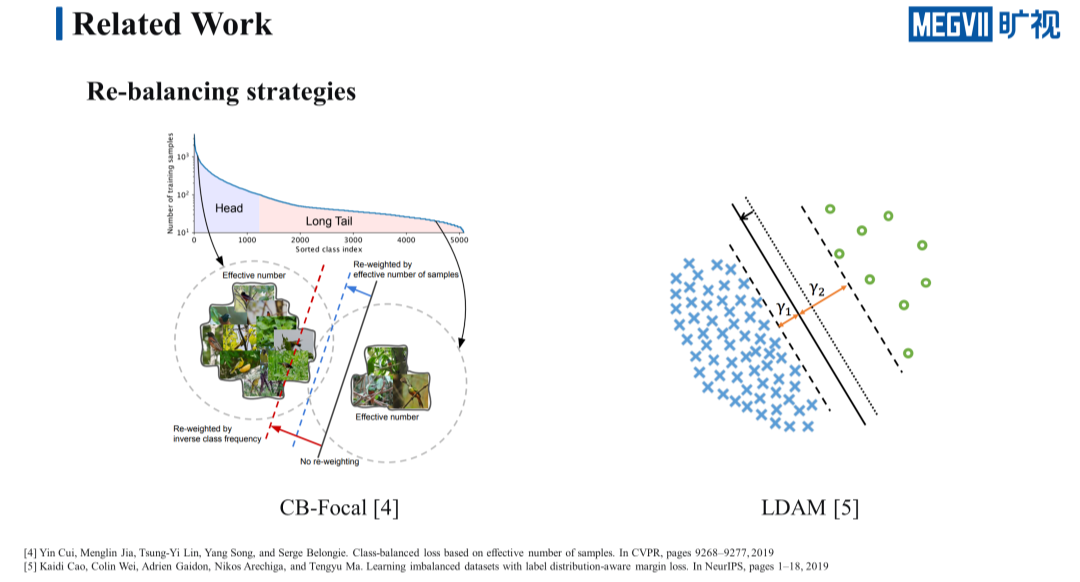
对于 Re-balancing 这一类的方法,这里主要介绍 2019 年的两篇 SOTA,第一篇是发表在 CVPR 上的 CB-Focal,CB-Focal 文中提出了一个有效样本的概念,并且通过有效样本的数量来对不同类别的损失进行一个重加权,在多个数据集上都取得了不错的效果。
另一篇是 2019 年 NeurIPS 的 LDAM,这篇 paper 主要是赋予了不同类别不同的 margin, tail 类的 margin 更大,同时他还采取了一种特殊的两阶段的 Re-weighting 策略,这两种方式在 Long-tailed CIFAR 和 iNaturalist 这两个知名的长尾数据集上都取得了 SOTA 的效果。
除了主流的 Re-balancing 方法,还有一些其它用来解决长尾问题的方案。第一种比较有名的是 Two-stage finetuning, 这类方法和 Re-balancing 这一类方法相似,它们都是把训练分成两个阶段,第一个阶段,直接在原始的 long tail 数据集上进行训练。
到第二阶段,会以一个很小的学习率,使用 re-weighting 或者 re-sampling 进行 finetuning,这种简单有效的方法就能够达到比较好的效果。除了 Two-stage finetuning,还有一些其它相对来说没那么主流的方案,比如 Meta learning,transfer learning,和 learning to learn 等,包括 Metric learning 也会有一些用来解决长尾问题的思路。
![]()
现有解决方案的不足
我们再回过头来看一下 re-weighting 和 re-sampling 这些策略,虽然它们可以较好地提升长尾识别的性能,但是也存在着一些缺点和不足。这些缺点和不足会不会导致 re-balancing 策略对网络产生负面的影响呢?
其实 re-weighting 还有 re-sampling 本质上都是人为地去给予不同数据不同权重,要么增大某些样本对网络的影响,要么削弱某些样本对网络的影响。假如我们不考虑验证计算的准确率,单纯地去增大或者削弱某些样本的权重,会不会对网络 universal pattern 的学习产生一些负面影响呢?
首先举一个简单的例子,Two-stage finetuning,为什么它比直接去做 re-weighting 还有 re-sampling 效果要好?为什么一定要经过第一阶段在原始分布上的 pre-training 操作呢?
实际上第一个阶段和第二阶段最大的区别就在于:第一个阶段每个样本对于网络的影响和贡献实际上是一样的,不存在数据权重的概念,因为每个数据的权重都是 1。所以我们觉得第一个阶段取到的特征或者它的网络更加的具有泛化性,学到了更多 universal pattern 。
我们再举一个比较极端但是又很简单的例子,假设我们有两个数据集,第一个数据集是一个原始的长尾分布的数据集,一共有 100 张图,有两个类别,这两个类别的图片张数分别是 99 张和 1 张。
第二个分布的数据集是从第一个数据集里重采样得到的,也有 100 张图,两个类别,只不过第一个类别里有 50 张图是从 99 张图里面降采样得到的,而第二个类别里的 50 张图是通过第一个分布里那一张图片重复了 49 次得到的。
其实这两个数据集相比,有效的样本的数量是 100:51,这里的有效样本指的是不重复的样本。因为第二个数据集是从第一个数据集里面重采样得到的,它实际上有 49 个重复样本。显然用 100 个有效样本训练网络肯定要比用 51 个有效样本训练出来的网络特征更加具有泛化性,更加的 universal,因为它吃了更多的数据。
![]()
新的尝试:兼顾网络的特征表示能力和分类能力
所以我们提出了这样一个猜想,尤其是 re-balancing 这样一个策略它能够工作的机制在于它提升了分类器的性能,但是它又会在一定程度上损害特征的表示能力。我们怎么去证明这样一个猜想呢?
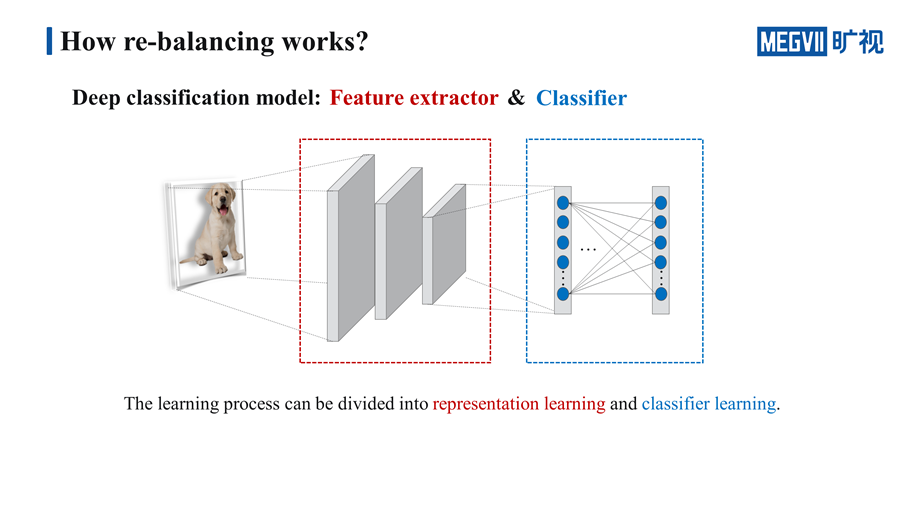
既然我们说它损害了特征,提升了分类器的性能,那就直接把网络拆解成分类器以及特征提取器两个部分。学习的过程也可以被分成表示学习以及分类器学习两个过程。
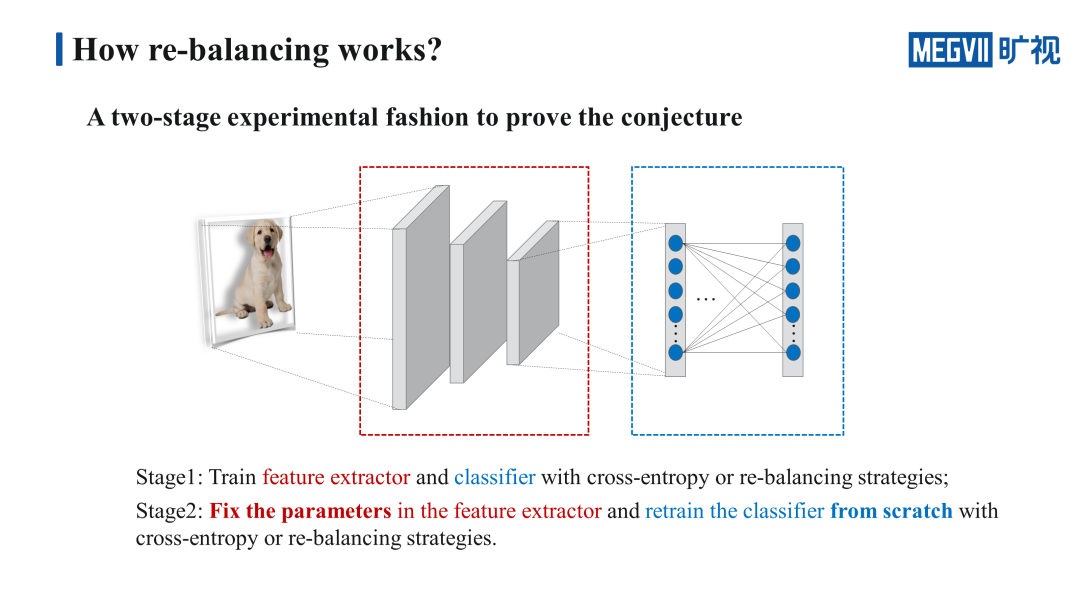
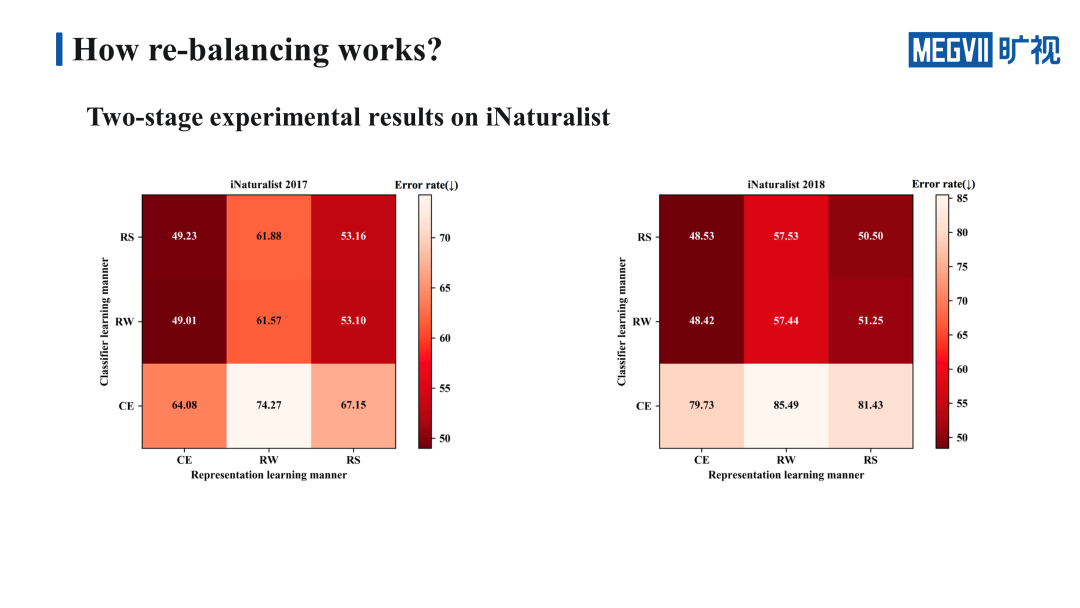
我们设计了一个 Two-stage 的实验来证明我们的猜想。首先在第一个阶段,使用 cross-entropy 和 re-balancing 的策略去训练整个网络。在第二个阶段我们会把第一个阶段训练得到的特征提取器的参数固定,然后重新训练分类器,训练分类器的方法也是使用三种不同的策略,这样我们就可以得到一个 3×3 的九宫格。
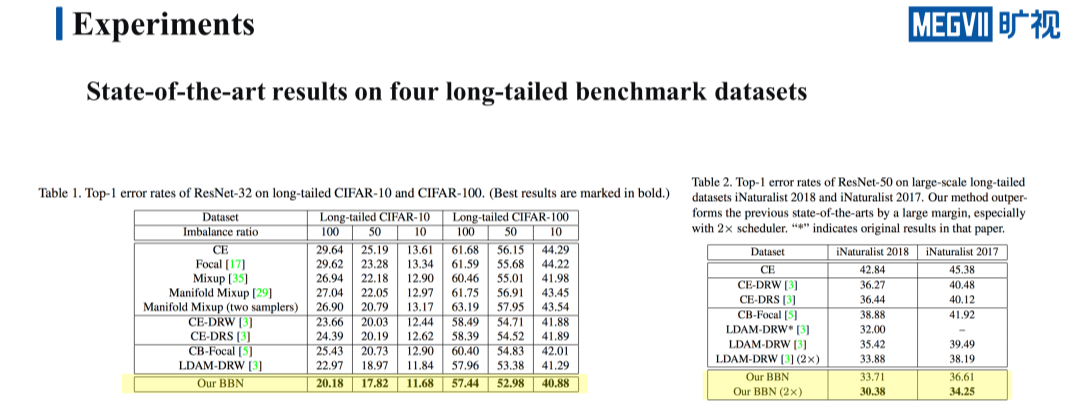
我们的实验主要是基于 Long-tailed CIFAR 和 iNaturalist 这两个长尾识别的 benchmark。Long-tailed CIFAR 是在原本的数据集基础之上,按照 explosion 曲线和设定的不平衡比例,人为造出来的,这里我们使用的是不平衡比例为 50 的 Long-tailed CIFAR,不平衡比例指的是最多的样本数和最少的样本数的比值。
为了确保实验的公正性,这里造 Long-tailed CIFAR 的方式和 LDAM 相同。iNaturalist 则是一个相对来说比较庞大的数据集,天然存在着长尾分布。我们一共在 Long-tailed CIFAR100、Long-tailed CIFAR10、iNaturalist2017、iNaturalist 2018 4 个数据集上进行实验,得出的结论都是一致的。
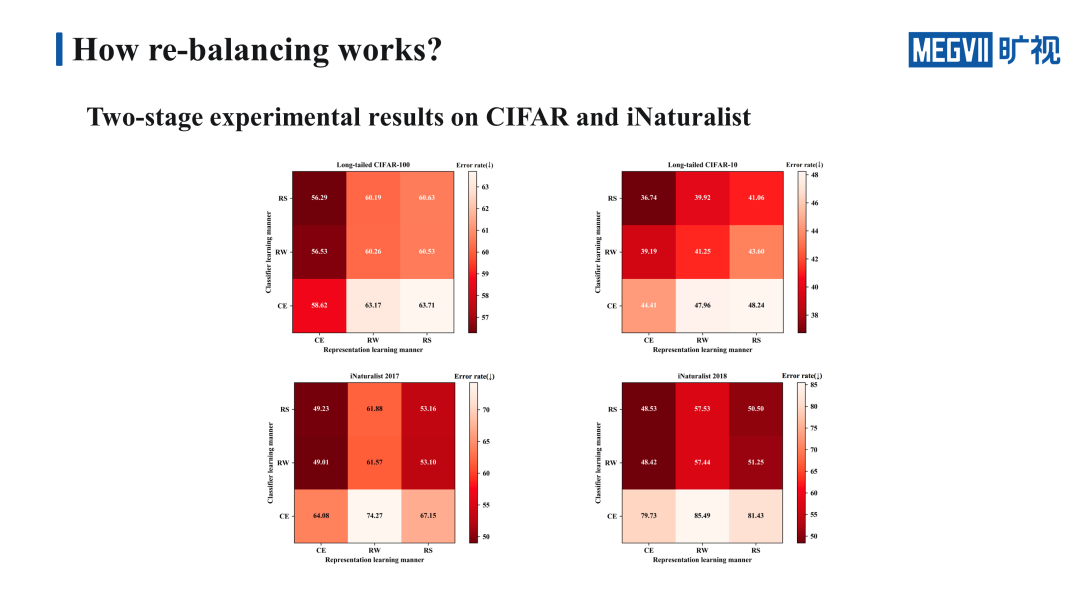
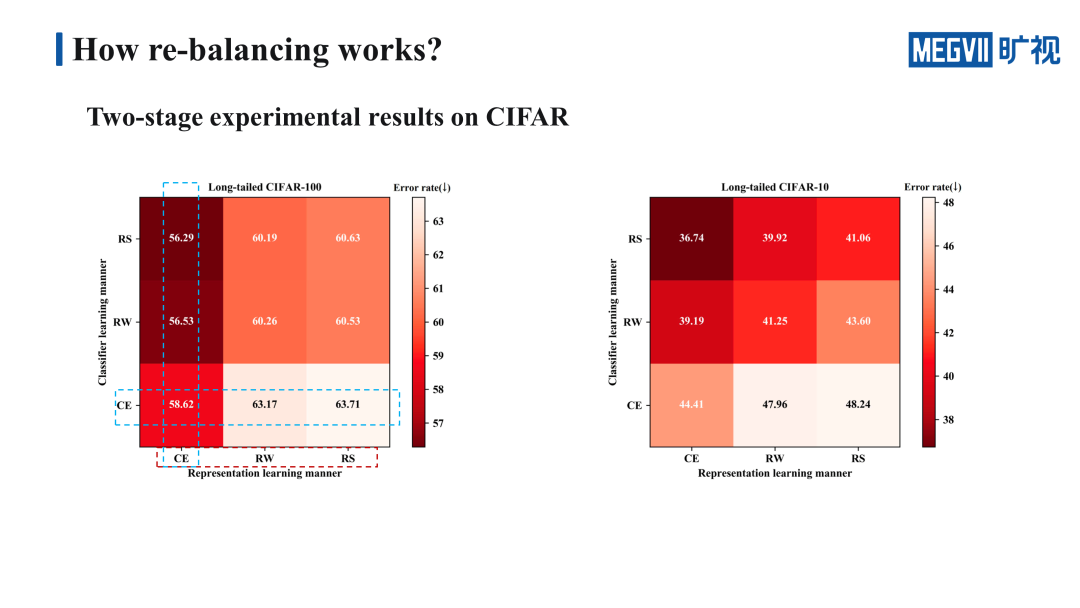
我们重点看一下 Long-tailed CIFAR100 上的结果,这里的九宫格横轴代表的是特征学习的方法,纵轴代表的是分类器的学习方法,九宫格里格子的颜色越深,代表错误率越低,效果越好。
首先纵向地看一下固定特征的学习方法,来比较几种不同的分类器的学习方式。明显 re-weighting 还有 re-sampling 的效果明显比 cross-entropy 要好,也就是说 re-weighting 和 re-sampling 学到的分类器性能是更强的。接下来我们再横向地来看一下固定分类器的学习方法,来比较几种不同的特征学习方法。明显 cross-entropy 的效果最好,换句话说,cross-entropy 学到的特征的表示能力是更强的。
我们还基于在 Long-tailed CIFAR100 上学习到的特征提取器,在 Long-tailed CIFAR10 上做了一个方法性验证,得到的结论也是完全一致的。
上面这两张表是在两个大型的数据集 iNaturalist 2017 和 iNaturalist 2018 上得到的实验结果,而结论也和 Long-tailed CIFAR10、Long-tailed CIFAR100 一致,这让我们的实验结论更加具有说服力。
这些验证实验都证明了我们之前提出的一个猜想,也就是 re-balancing 这样一类的策略,它虽然提升了分类器的性能,但是却会在一定程度上损害特征的表示能力。
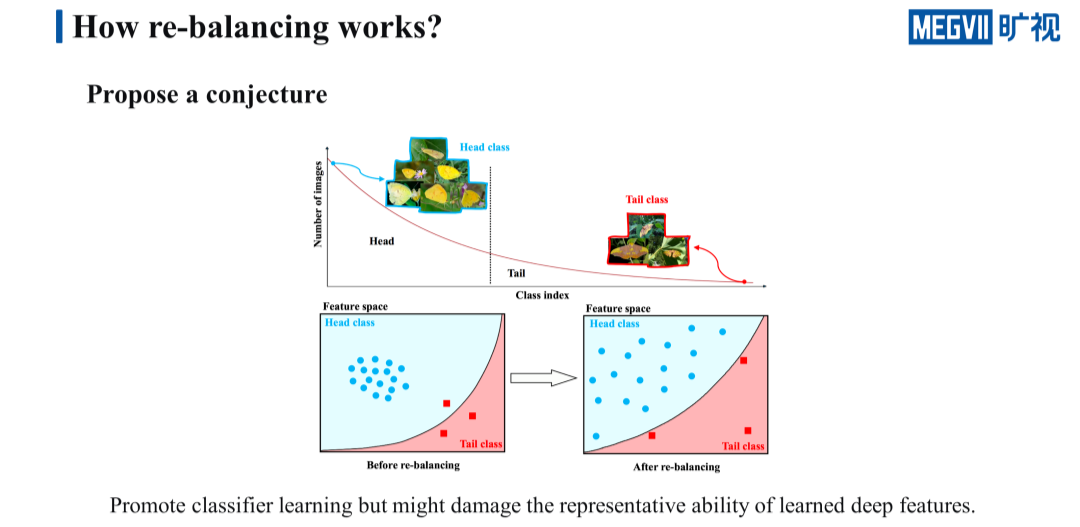
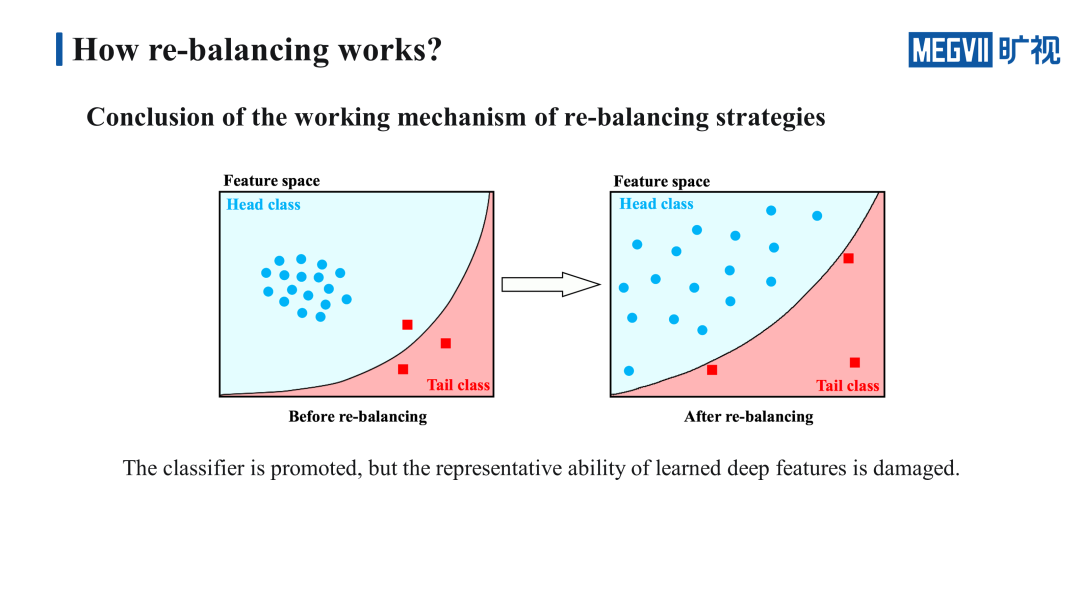
我们把刚刚的猜想画成一张比较形象的图,假设在一个二维的特征空间里有两个类别,分别是头部类和尾部类,蓝色的圆圈代表的是头部类的特征向量,红色的方块代表的是尾部类的特征向量,中间黑色的圆弧代表的是决策边界。
左边未进行 re-balancing 训练的特征空间中,两个类别各自的特征向量都聚成了一个比较紧的簇,但是决策面的坡度却比较大,导致有一个 tail 类的样本被错分到了 head 类里。
右边进行了 re-balancing 训练的特征空间则是完全相反的,它的决策边界向 head 类靠近了一些,所以不会再将 tail 类错分成 head 类,它使两个类各自的特征向量聚得相对松散了一些。这张图里簇的松紧程度代表特征的好坏,而决策边界的位置代表分类器的好坏,显而易见左边的特征好,右边的分类器好。
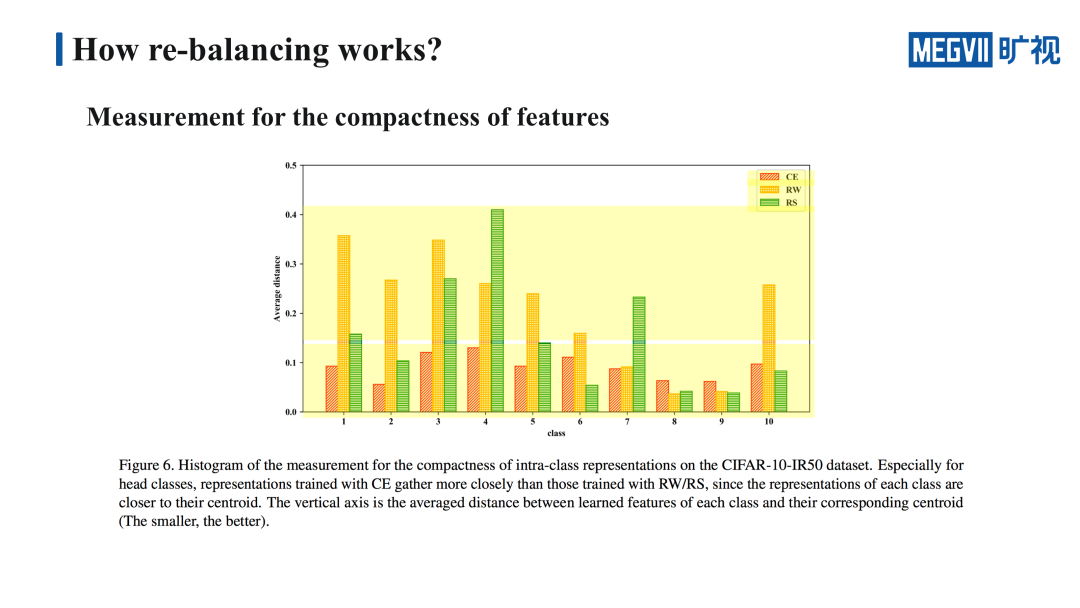
为了进一步证明 class-entropy 学到的特征在特征空间中的簇聚得更紧,我们还做了一个实验:分别用 class-entropy、re-weighting 和 re-sampling 训练三个网络,并且利用这三个网络提取 CIFAR10 上 10 个类别的特征,然后计算到每个类别的特征与类中心的距离,以此作为类内训练的一种度量方法。
上图中红色的条形图代表的是 class-entropy,黄色和绿色分别代表的是 re-weighting 和 re-sampling。可以明显地看到红色的条形图几乎一直低于黄色和绿色的条形图,这也进一步证明了通过 class-entropy 学到的特征,它每个类内的簇确实会聚得更紧一些。
既然 class-entropy 它学到的特征更好,而 re-weighting 和 re-sampling 学到的分类器更好,那么我们有没有什么办法既可以保留 class-entropy 学到的特征表示能力,又可以充分利用 re-weighting 和 re-sampling 来增强分类器的性能呢?
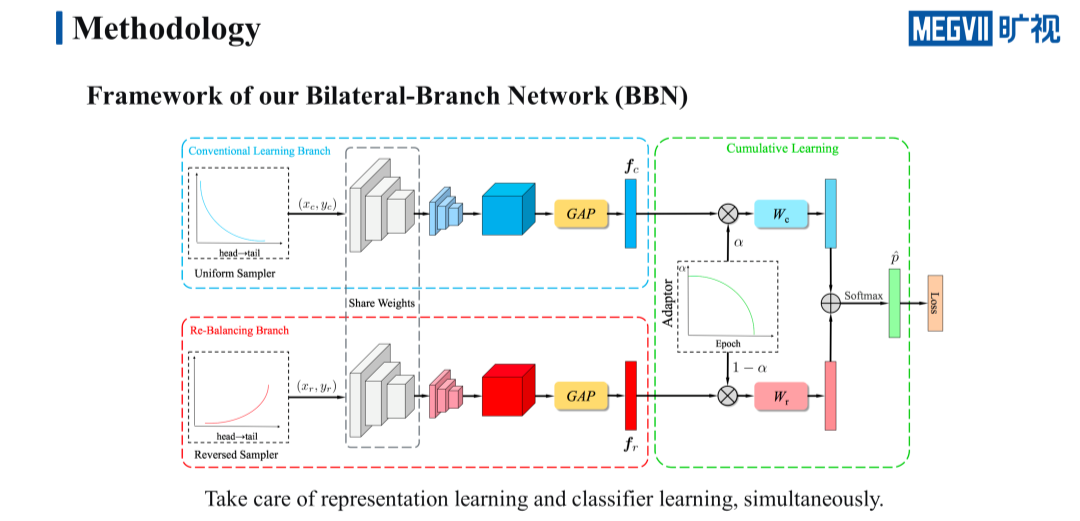
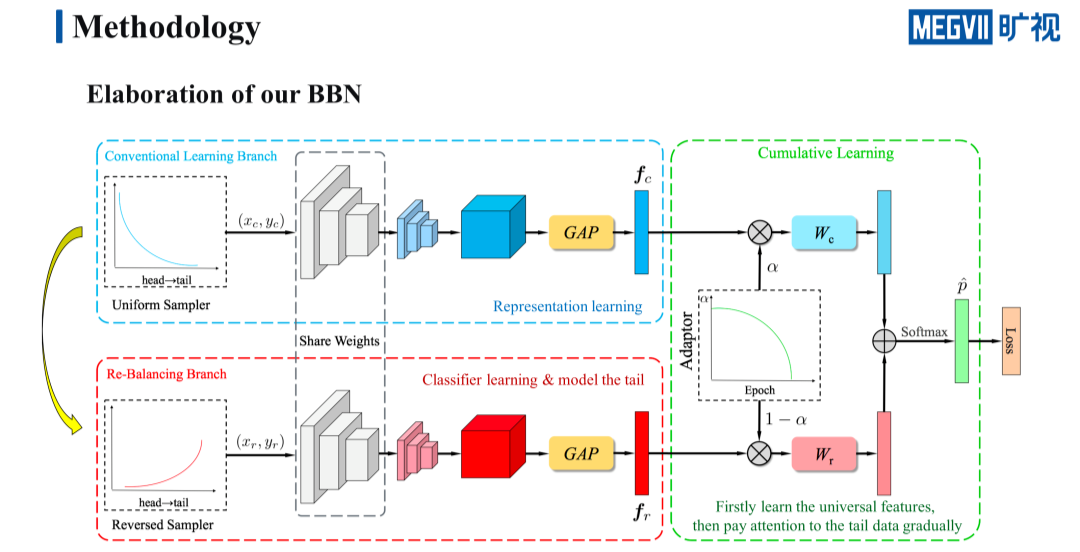
基于这样的目的,我们提出了一个全新的 framework:BBN。BBN 的出发点是希望可以兼顾特征的学习和分类器的学习。为此我们设计了两个分支,一个分支的作用是尽可能保留 class-entropy 的特征表示能力,另一个分支的作用则是提升 tail 类的分类性能。
此外还涉及了一个渐进式的学习策略,使用一个 Adaptor 来控制两个分支在整个训练过程中的学习比重,这使得网络在训练的前期更加关注特征的学习,在中后期再逐渐地转移和过渡到分类器的性能提升上来。
接下来我们将详细介绍 BBN 网络结构里的每一个模块。
首先是传统学习的分支,顾名思义,传统学习分支的输入来自一个普通的均匀采样器,它从原始的 long tail 分布里进行收集采样,主要作用是进行特征表示的学习。
其次是 re-balancing 分支,re-balancing 分支来自一个逆向采样器,逆向采样器的每个类被采样的概率与该样本的数量成反比,意味着样本的数量越少,那么它被采样的概率就越大。这个分支的主要作用在于进行分类器的学习,并且侧重点在 tail 类的学习上,从而可以提升 tail 类的识别性能。
这两个分支还有一个共享权重的设计,这样设计的主要目的有两个:第一个是可以减少参数量,提升训练和测试的速度。第二个目的则是因为传统分支的特征表示能力更好,共享权重可以让 re-balancing 这一分支受益于传统学习分支的特征,从而更好地进行分类器的学习。
这两个分支通过一个 Adaptor 来控制各自在训练过程中的学习占比,Adaptor 会生成一个随 epoch 递减的 α,用这个 α 来对两个分支的特征进行加权,最后再送入各自的分类器中,计算交叉熵的损失。
需要注意的是 α 随着 epoch 的增加逐渐减小,这样设计的目的是让网络可以首先专注于特征的学习,当学到的特征足够好了之后,再逐渐地转移到 tail 类的性能提升上来,毕竟特征是分类器的基础。
我们来看 BBN 的实验结果,首先是几个主要的长尾 benchmark 上的实验结果,我们一共在 8 个数据集上利用三种不平衡比例进行了实验,分别是 long-tailed CIFAR10,long-tailed CIFAR100,以及两个大型的长尾数据集,iNaturalist 2017 和 iNaturalist 2018。
可以看到无论是在小型数据集 long-tailed CIFAR 上,还是在大型数据集 iNaturalist 上,我们的方法相对于之前的 SOTA 都有一定提升。
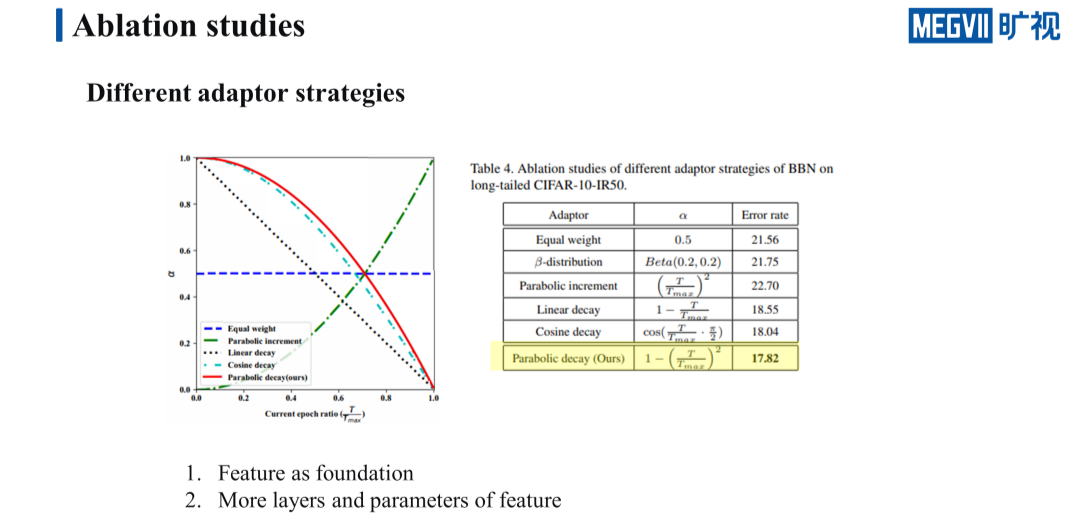
接下来我们看一下不同的 Adaptor 生成策略对于网络性能的影响。我们通过 Adaptor 生成的 α 来控制网络的学习重心,直白来讲就是网络更关注哪一方面的学习,α 如果大于 0.5 网络就更关注特征的学习,反之 α 如果小于 0.5 网络就更关注 tail 类的分类性能。设计的原则是特征是标识分类器的基石,如果没有好的特征,那么好的分类器也无从谈起。
表格里的前三行分别是固定值、β 分布及抛物线居中,这三种策略的效果都很差,这也证明了特征是分类器的基石这一原则。我们要让网络在前期更加关注特征学习,随后再慢慢地将注意力转移到 tail 类的分类性能上面。
后三种都是 decay 的递减策略,这三种策略都符合特征是分类器基石这一原则,并且这三种策略的效果越来越好,这是为什么呢?
我们看一下左边这张图,以图中的蓝色线作为参考,三条曲线与蓝色线交点的横坐标越来越长,表示它们的效果越来越好,这是因为特征提取器的参数相对于分类器的参数而言更大,它的层数也更深。
所以我们倾向于让特征去花更多的时间来学习,当特征学得足够好,再去关注 tail 类的分类性能,当然也不是说特征学的时间就越久越好。总的来说网络的性能对于不同的递减策略来说也不是很敏感,比如 Cosine decay 相比于我们使用的 Parabolic decay 也就差了仅仅 0.2 个点而已。
之前的九宫格实验证明了 cross-entropy 的特征要比 re-weighting 和 re-sampling 好,所以我们这里设计了一个实验来证明 BBN 网络确实可以保留 cross-entropy 的特征表述能力:主要利用从 BBN 的两个分支提取出来的特征分别训练一个分类器,并与 cross-entropy、re-weighting 和 re-sampling 训练出来的分类器做一个横向的对比。
可以看到 CB 这一分支,也就是传统学习这一分支它的性能与 cross-entropy 差别不大,这证明 CB 这一分支确实可以比较好地保留 cross-entropy 的特征表示能力。另外值得一提的是,RB 这一分支的性能也比 re-weighting 和 re-sampling 要好不少,这可以归功于我们权重共享的这样一个设计。
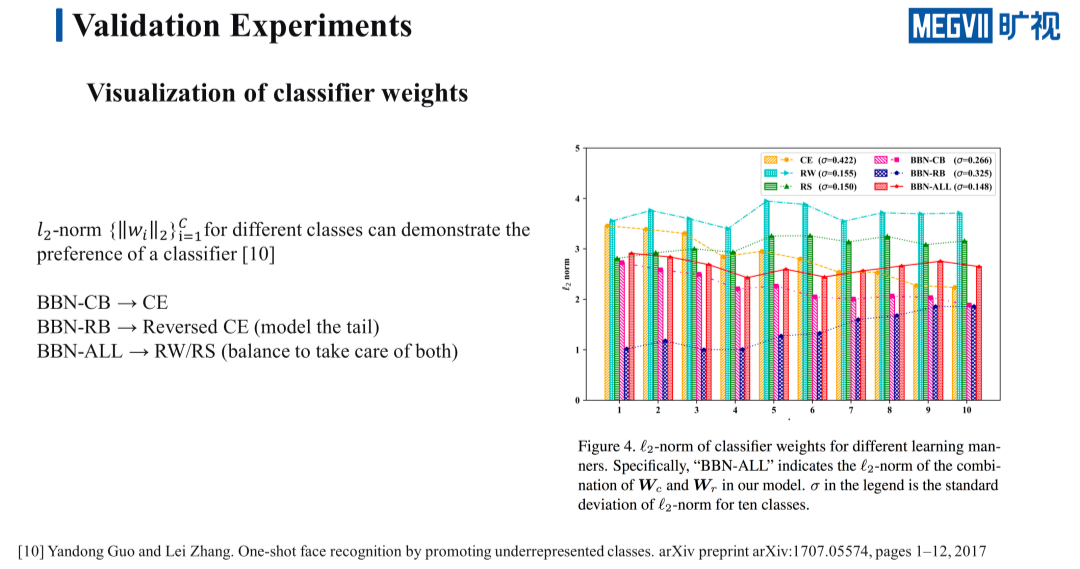
接下来我们来看一下分类器模长的可视化实验,分类器的 L2 模长在一定程度上能够反应分类器对各个类别的偏爱程度,类别的模长越大,分类器就会倾向于把这个样本分为这一类。
我们重点看一下 BBN 的分类器模长,CB 这一分支在图中是粉红色的条形图,可以看出粉红色的条形图从 head 类到 tail 的模长越来越小,这和普通的 cross-emtropy 差不多,是更偏爱 head 类的,而 RB 这一分支在图中是深蓝色的条形图,正好和 CB 相反,从 head 类到 tail 类的模长越来越大,是更偏爱 tail 类的,这说明这一分支确实提升了 tail 类的分类性能。
CB 和 RB 结合到一起之后在图中是红色的条形图,连接起来之后是一条相对比较平坦的曲线,对于每个类的偏爱程度是差不多的,并不会有特别的分类倾向。
最后我们再与 ensemble 的方法进行对比,BBN 的 CB 和 RB 两个分支如果完全不进行权重共享,看起来就和模型集成有一些相似。可以看到的是无论是 Uniform sampler+Balanced sampler 还是 Uniform sampler+Reversed sampler,提升的效果都比 BBN 差很多。
关于数据实战派
数据实战派希望用真实数据和行业实战案例,帮助读者提升业务能力,共建有趣的大数据社区。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()