讲堂| 曾文军:当机器学习遇到大视频数据

你离成为人工智能专家,还有多远的距离?
近日,四位来自微软亚洲研究院的AI大咖在中国科技大学进行了一场以“开启智能计算的研究之门”为主题的前沿分享。这四位嘉宾分别是:
● 首席研究员刘铁岩——人工智能的挑战与机遇
● 资深研究员谢幸——用户画像、性格分析与聊天机器人
● 首席研究员童欣——数据驱动方法在图形学中的应用
● 首席研究员曾文军——当机器学习遇到大视频数据
目前,我们已经发布了刘铁岩博士的演讲——人工智能的挑战与机遇,谢幸博士的演讲——用户画像、性格分析与聊天机器人,和童欣博士的演讲——数据驱动方法在图形学中的应用。
最后一位与大家分享的是曾文军博士的演讲——当机器学习遇到大视频数据,全文如下(文字内容略有精简)。希望这些关于前沿技术的思索能够开启属于你的智能计算研究之门!
今天很高兴有这个机会给大家分享一下微软亚洲研究院近两年在机器学习和视频大数据的分析和理解方面的一些工作以及一些思考。
AI兴起是由于有大数据等各方面的因素。大数据有各种不同的形态,其中视频信号占很大比重,现在的网络上,百分之七八十的流量是由视频信号所组成的,可以说它是大数据中的大数据。
这种大数据给我们带来了挑战,同时也提供了很大的机会。从机会角度来说,这些数据可能在几年前还不太容易得到,但现在我们能够分析这个大数据,提取有价值的信息,从而去支持新的产品或者服务,所以这里面蕴藏了巨大的机会。在有大数据的同时,我们的计算资源也在迅速发展,机器学习和深度学习在这几年也取得了非常快速的进步。现在是IT行业非常兴旺的时代。
关于视觉信号分析,可以发现它的发展也是起起伏伏,到一定阶段都会看到一些瓶颈。其中一个很大的瓶颈就是没有足够量的数据,所以模型或算法上的发展都受到了一定的限制。
2010年左右,李飞飞教授和她的同事以及学生构建了ImageNet Database,这是一个有标注的数据集,应该是目前为止最大的有标注的图像数据集。它按照WordNet的层级去组织,比如从哺乳动物到狗,再到一个明确的狗的品种。因为它有概念,同时每个概念里面也有几百到上千的图像可以跟它associat在一块,所以是一个很好的图像信号的表示,也是一个很好的知识库。这个数据库辅助了图像分析、计算机视觉等相关领域近期的快速发展。
除了ImageNet,近几年也有一些与图像识别相关的比赛,其中图像分类就是希望在100多万的标注图像上,去进行分类。当然,还有一些如物体检测、场景检测、场景分析和语义分割等。
关于ImageNet图像分类比赛,2012年前,错误的概率很大,所以基本上很难适用。2012年,Hinton的实验室第一次把深度神经网络用到这个任务上,一下有了很大的突破,也引起了很大的关注。随后这几年技术就一直有持续的发展,并且神经网络结构上的变化促使了比较大的进步。
短短几年内图像识别这个任务已经做的很不错了。当然还有一些更有挑战性的任务,像语义分割等等。虽然图像上已经有了很大的进步,但视频方面却还是差的很远。
视频信号相比于图像信号有更大的挑战,因为它是一个更高维的信号,里面的内容多样性也非常大。所以要去判断它、理解它都很困难,当然数据量很大也是另外一个问题。
还有一个问题,在很多情况下,视频是实时的,比如监控,因此在处理速度等各方面都有很大的要求。而且标注视频数据时每一帧都要标注,也很耗费时间、精力和成本。这也是为什么视频发展相比图像来讲还是落后一些。
缺少训练数据又是另外一个问题,如监控录像的数据很难获得。要解决这个问题,不能像其他视频一样可以从视频网站上找到很多数据做训练,所以发展也受到了阻碍,会稍微慢一点。
接下来,介绍一下微软亚洲研究院在视频分析方面做的一些工作。
我们最近两年尝试了以人为中心的方法(Human centric approach),意识到在视频里面,人是一个最主要的主体,要理解视频,首先要理解人。因此,我们围绕人,来进行人的检测,以及人的属性和行为的研究工作。
我们用了一些视觉方面的基础技术和深度学习的一些技术。下面举几个例子介绍一下这方面的主要问题、挑战,以及我们取得的一些最新成果。
人脸/人的检测及追踪是非常基础的问题,但在视频处理中,最基本的问题也是非常难的问题。比如要把视频里的人脸模糊掉,就是个难题。大家可能觉得人脸识别在图像方面已经做的很好了。可是一旦用到毫无控制的视频里面,其实并不是一回事。
人脸可能会出现侧面的情况,或者大小不一,各种形象都有可能,要做检测很难。所以一般这种问题,我们都要做检测追踪,如果是做逐帧的检测,很可能在很多帧上都检测不到这个人脸,所以只能通过跟踪的方法,利用全过程的相关性,从能够检测的那帧去跟踪到另一帧里不能检测到的人脸。
在这个视频人脸模糊问题里,因为隐私保护的要求,所以不能漏掉任何一帧里的人脸,如果漏掉一帧,那么就被看见了,因此每帧都在做检测,每帧都在做跟踪。还可能很多情况下,不是所有的人脸都需要被抹掉,可能某些个别的人脸要抹掉,这个问题就更复杂了,因为需要区分不同的人脸,只抹掉需要抹掉的,所以这里面当然就有人脸识别的问题。

同样的技术,用到不同的应用,比如名人识别(celebrity recognition),如果能够检测跟踪并识别到名人的脸,那么就可以知道一个名人他在某个视频里的什么时候出现,出现了多长时间等,这实际上也是一种具体的应用。
人脸当然是一个非常基础的问题,但是很多情况下,可以看到的人脸要么很小,要么看不见,所以必须依靠其他技术,例如,人体的检测与跟踪。人体的问题更复杂,因为它是一个不规则的形状,而且不是不变的,跟踪它比人脸还难,毕竟人脸的形状基本上还是比较固定的。
在这个基础上,我们希望知道一个人的属性是什么,如:性别、是不是戴帽子、衣着的类型等等,这可以被用来做更进一步的研究,搜索一个特定的人或是一类人。也可以做的再细一点,把人体的部分分开,这同样也是为了做理解和搜索,也可以做所谓的Re-Identification,就是在不同的相机视角里面,把同一个人找出来。
我们在这方面做了一些工作,做Re-Identification实际上是一个匹配的过程,要匹配一个人和另外一个人,可以用整个身体去匹配。如果能把一个人分割开,如上衣,下衣等等,理论上可以做的更好。
通过CNN网络学到一些特征,再用一些注意力模型(attention model)去把重要的部分抽取出来,然后再结合到一起作为一个特征的描述,这样就不是笼统的描述这个人可能是红色的,而是说这个人的这一部分是什么颜色,那一部分是什么颜色,这样做匹配就会更准确。
还有一个例子是在衣着比例不一样的情况下做匹配,这种时候整个人的匹配就会相对比较难。如果能够有一个方法,虽然衣着比例不一样,但是依旧可以把相应的部分提取出来,做局部的匹配,那么就可以做的更好。这些都可以通过深度学习去学的,包括各部分的关系、怎么样把某一部分找出来,实际上都可以通过深度神经网络去学的。

再进一步,我们还想知道人体的主要关节点在哪里,并把它提取出来。这十分有用,我们可以用它做一些动作的分析和识别,来看一个人到底在做什么样的动作。
这个问题其实也很有挑战性。一是动作可以有各种各样的表现,然后还有遮挡的问题,有些关节会被其他的身体部分给挡住。这方面的工作基本是用一个完全卷积网络(fully convolutional network)去提取信息,给出一个热度图,也就是一个概率。这个模型基本上可以给每一个不同的关节一个概率的分布图,这样就能大概知道,哪里可能是头、膝盖等。
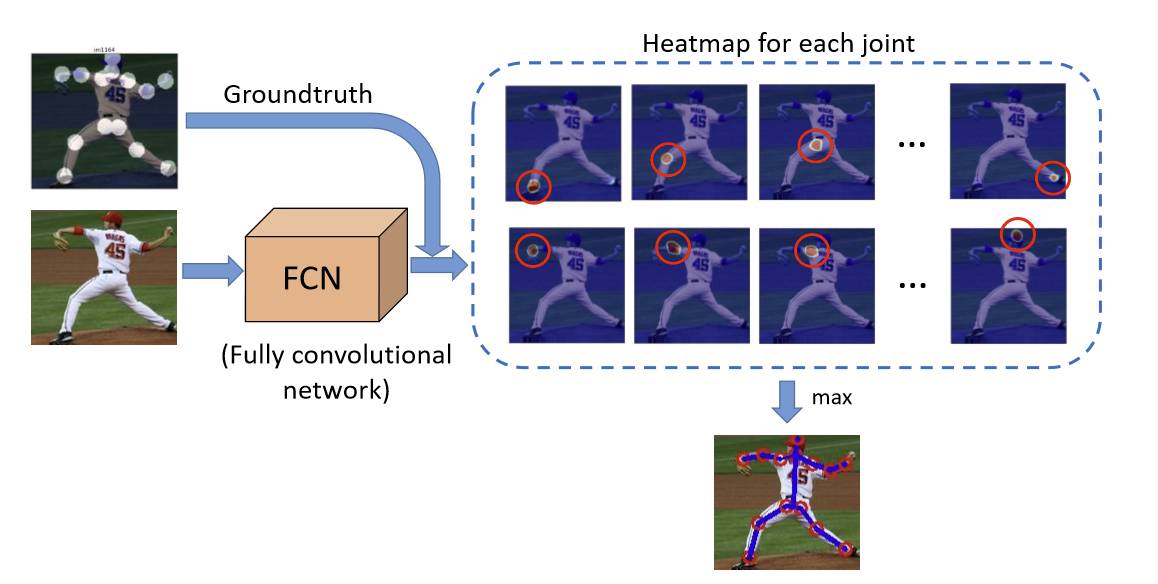
关于关节点估计(Pose Estimation)的挑战实际上也很多。第一个问题是相似性,左踝关节和右踝关节可能很难区分。在这种情况下,可能需要利用不同关节间的特殊关系来帮助确认。第二个问题是动作、姿势的多样性。如果利用关节间的特殊关系,就需要想办法去考虑到各种各样的情形,因为图像中不一定在头部左边的就是左肩。我们找到了一个方法可以把比较多样的状况标准化成比较一致的数据,只要数据一致之后就具有一定的统计性,有了统计性就会很好学。
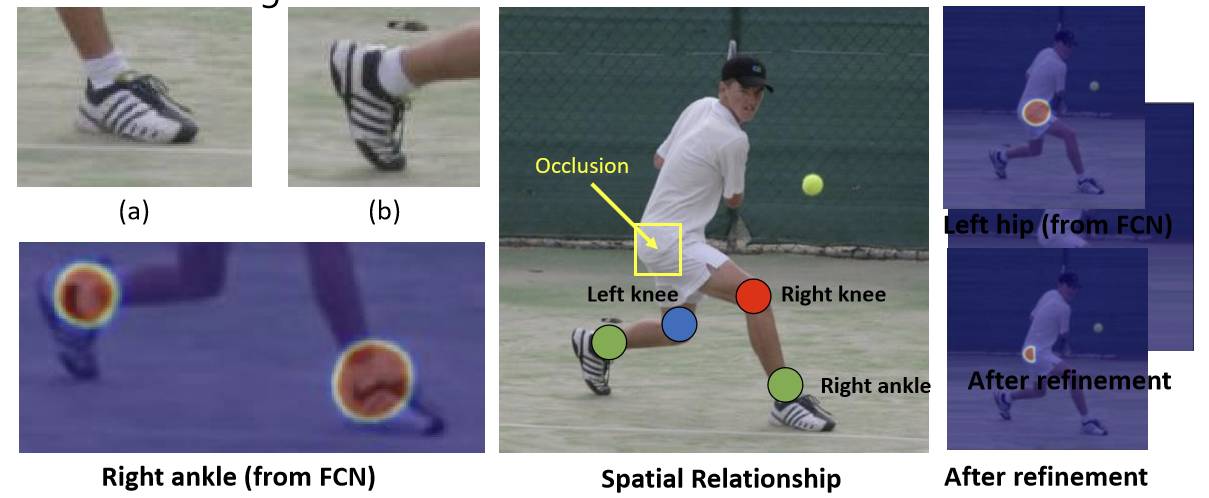
除此之外,我们也在做多人关节点估计,多人情况下一旦有多个人出现并且靠的比较近时就会有更多不明确的信息,谁的左肩、谁的右脚等等,会有更复杂的问题。
还有一个是在视频上做关节点估计,传统方法是一帧一帧的去解然后再做关节点的叠加。但原则上应该直接作为一个视频数据,去解决里面动作/关节点的检测和追踪。
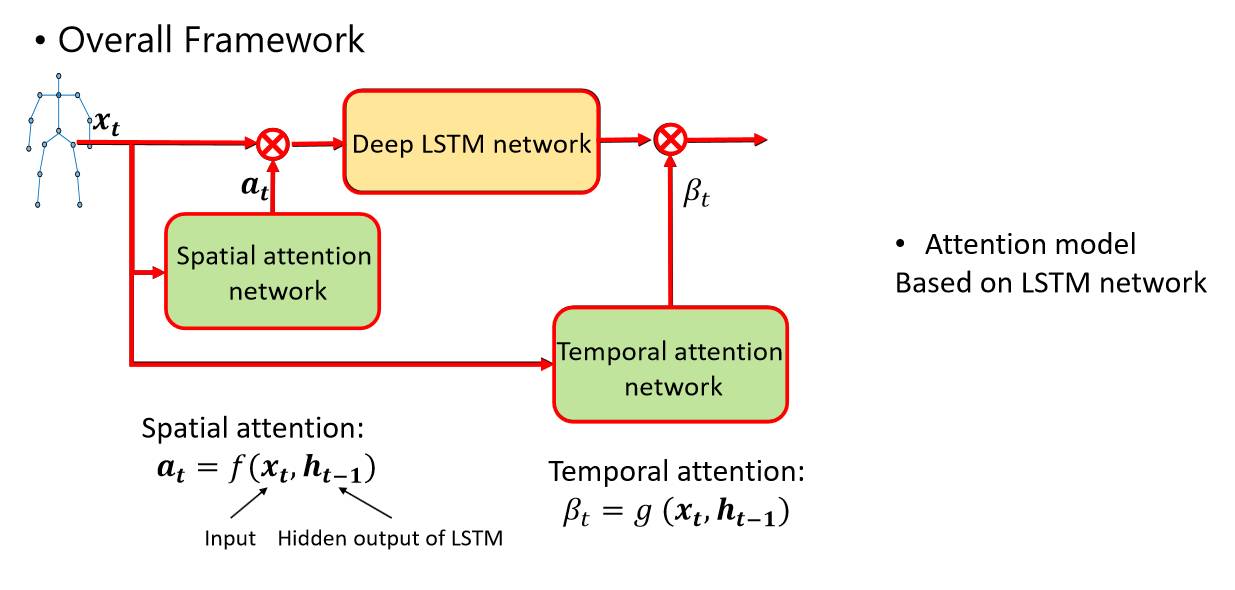
在行为识别方面,我们也有一系列的工作。比如一个RGB的视频,我们希望把他的姿态和关节点找出来,从而判断是什么样的动作。如下图,我们设计了一个网络,因为这是一个视频,就算从图像上得到关节的序列,但它还是一个时间序列的数据。所以一般在这种情况下,我们都可以用一个RNN。
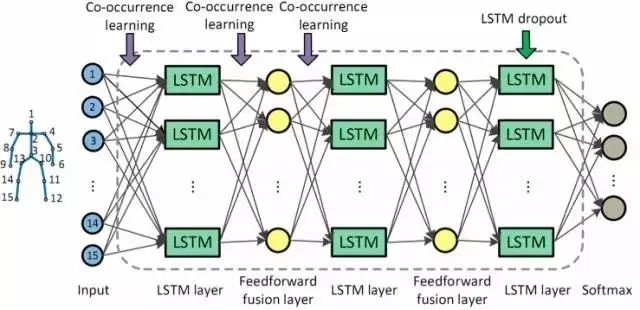
图中的LSTM是属于特殊类别的一种RNN,因为它有记忆性,所以在每一个时刻,它不但能看到当前这一帧的骨骼,还记下了前几帧的骨骼信息。因此,它可以做一个总体的判断,来表示在一小段时间里面,动作是如何变化的,这样行为识别可以做的更好。LSTM是目前非常流行的方法,它对于时序数据或者视频数据来说都是一个很好的工具。
同时,可能还要加一些约束,比如共现性学习(co-occurrence learning),对一定的动作,某些关节之间会有很大的相关性,所以需要将限制加入到网络中从而帮助更好、更快的学习。因为空间很大、参数非常多,所以一定要利用先验的知识或者一些特性。
此外,在做行为识别时,可以看到一个特定的动作其实不是所有的关节都是同样重要的。比如下图,喝水的时候,手部、肘部的关节可能比较重要,腿部可能就是噪声。
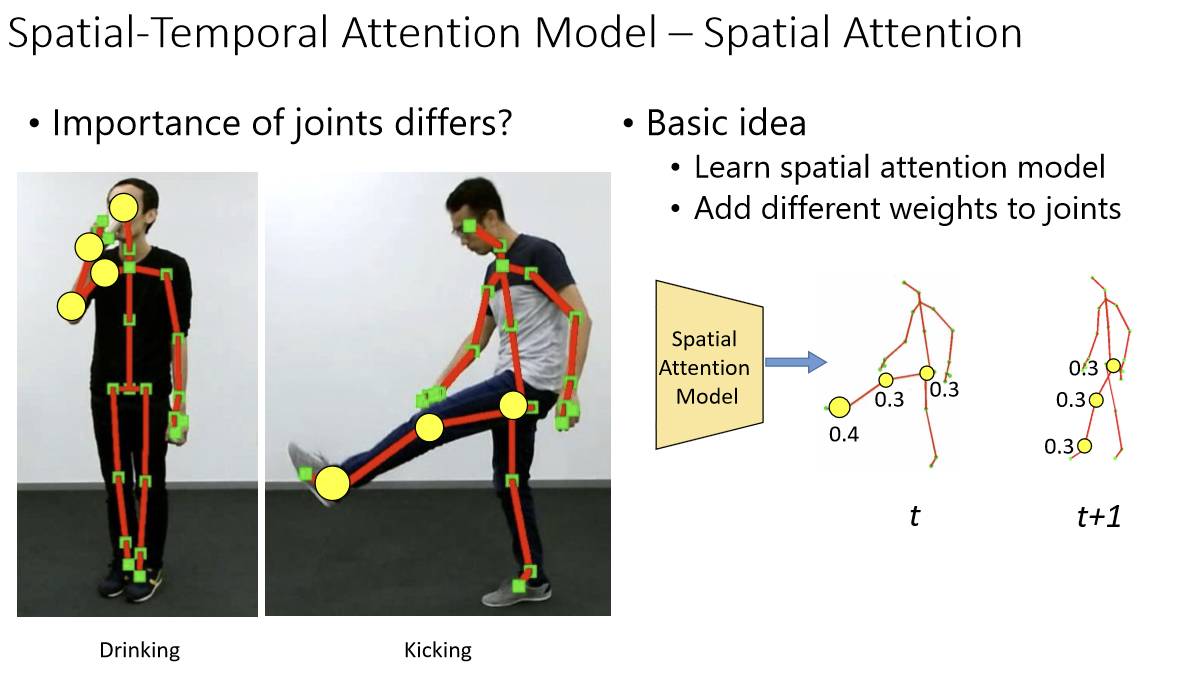
所以我们有一个空域注意力(spatial attention),就是做一个特定动作的分类器,从而更多关注那些需要学习的关节,这样就可以把噪声去掉,在做设计的时候才能做的更好。同样,在输出上也是一样,因为这是一个序列,所以实际上在每一帧里面可能都有一个输出。
在时域中,实际上也有一个注意力的问题,比如踢腿这个动作,可能踢的快到最高点的时候是最主要的点。其他时候也有一些输出,但是不见得是对这个动作最重要的输出。对于最有助于踢这个动作判断的,我们叫时域注意力(temporal attention)。最终得到一个如下所示基本的网络结构。
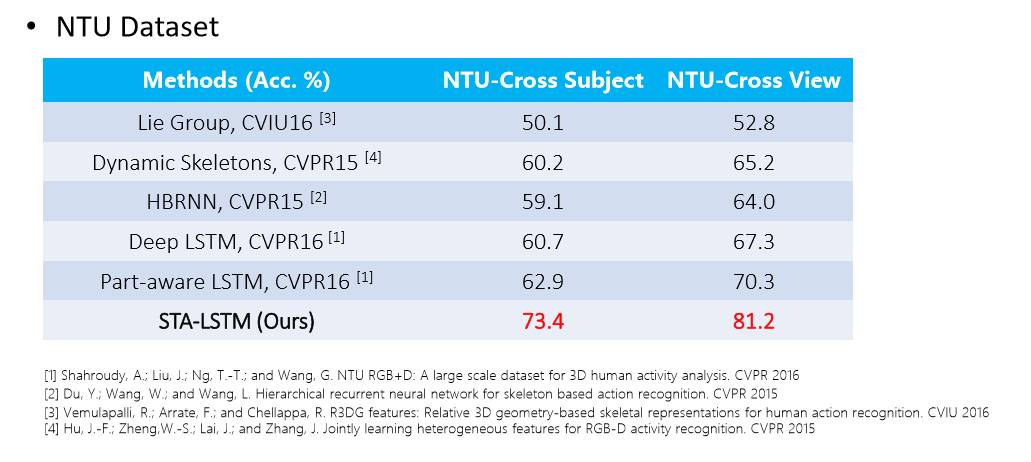
从NTU这个目前最大的3D skeleton数据集的结果可以看出来,在短短一两年的时间,提升还是很大的。我们的STA-LSTM方法做出的结果有很好的效果。
前面提到的重点都是在人上,但是其他比较主要的物体,像车我们也在做,包括车的检测、跟踪,双闪灯、左转灯等等,当然车牌也是很重要的一个部分,检测加识别。当然如果有检测和跟踪技术,同样也可以做一些编辑的应用,比如把车牌抹掉,这实际上跟之前提到的视频中的人脸部分的编辑面临同样的问题。
我刚才展示了我们最近做的一些工作。最后想对大家说,微软研究院和学校一个比较大的不同在于微软毕竟是一个大的企业,所以我们除了发很好的论文以外,还要考虑如何把我们的研究成果转化为生产力,去造福这个社会。目前,我们有很多的技术已经被运用到了产品里,有的还正在产品化的过程中,同时我们也在跟许多内部和外部的同行进行合作。我们希望与大家进行更多的交流,从而推动技术的发展!
谢谢大家!
你也许还想看:







