不会编程也能做这么酷炫的视频风格迁移?这个工具冲上Reddit热榜,还能在线试玩
贾浩楠 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这两天,Reddit上一则关于视频风格迁移的帖子火了,发布仅一天就冲上了机器学习社区的热榜第一。
明艳、华丽的Demo引起了网友们惊叹。
著名的恐怖片《闪灵》经过处理后,变得色彩明艳,有了漫画风格:

而电影《低俗小说》,处理效果像极了天主教堂五彩缤纷的玻璃窗:

大家纷纷留言追问“是不是对CNN的层过滤器进行过修改”?
但楼主却说「我不是程序员,也不清楚CNN是什么东西…….」
这就有点不可思议了,一个没接触过机器学习的小白,是怎么做到效果这么好的视频风格迁移呢?
「一键式」视频风格迁移工具
Reedit热帖的楼主,是一位纯艺术从业者,没学过计算机和编程。
但是他却却借助一款「一键式」的傻瓜工具,轻松完成了视频风格迁移。
这款工具名叫Deep Dream Generator。
熟悉图像风格迁移的读者可能对Deep Dream很熟悉,早在2015年谷歌就公布了这个软件。
最早Deep Dream是为2014年ImageNet视觉识别挑战赛而开发的,主要的目的也是识别图像中的人脸和其他目标。

但是随后有人发现,经过训练的Deep Dream能够反向运行,将给定图片的像素特征整合到目标中。
随后,Deep Dream开始在艺术创作圈流行,由它生成的风格迁移图像颇具梦幻色彩,所以被叫做「Deep Dream」。

而制作这个工具的团队将Deep Dream做成了简单易上手,不需要任何计算机知识,能够直接在网页使用的版本。
使用很简单,只需要上传目标图像和「风格」,一键点击,就能生成。
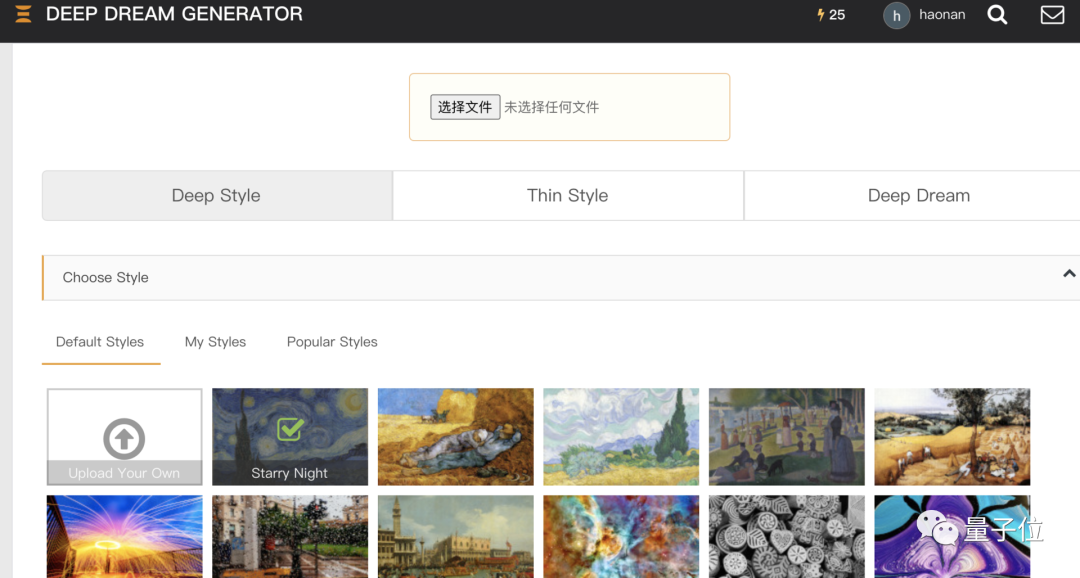
生成的图片效果完全由上传的「风格」决定:

有了这工具,就算是既不懂艺术,也不懂编程的小白,也能批量生产艺术作品。
视频风格迁移的两种方法
尽管Deep Dream Generator官网上并没有给出任何技术说明,但Deep Dream早已开源,并且风格迁移已经是深度神经网络应用中轻车熟路的一个领域了。
一般常见的风格迁移迁移算法由两种基本思路,一是优化法,第二种是在它之上优化而来的前馈法。
优化法
在这种方法中,其实并没有使用真正意义上的神经网络。
任务中并没有训练神经网络来做任何事情。只是利用反向传播的优势来最小化两个定义的损失值。
反向传播到的张量是希望实现的图像,从这里开始我们称之为「复刻」。希望转移其风格的艺术品,称为风格图像。而要将风格转移到其中的图片,称为内容图像。
「复刻」被初始化为随机噪声。然后与内容和风格图像一起,通过一个预先训练过的图像分类网络的几个层。
算法使用各个中间层的输出来计算两种类型的损失:风格损失和内容损失。在风格上,「复刻」与风格图像有多接近,在内容上就有有多接近。
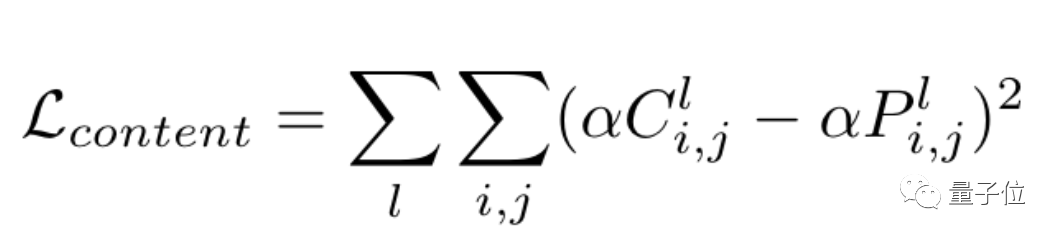
然后通过直接改变「复刻」,将这些损失降到最低。
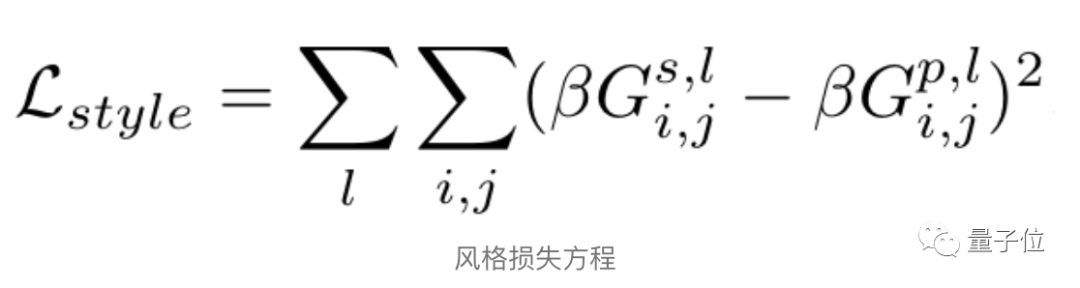
经过几次迭代,「复刻」就能够具备风格图像的风格和内容图像的内容。它是原始内容图像的风格化版本。
前馈法
优化法的缺点是运算成本较高,处理时间也比较长。
那么有没有好的方法能够直接利用深度神经网络的特性,减轻开发者的负担呢?
前馈法的本质,是创建一个未经训练的图像转换网络,它的功能是将内容图像转换为对「复刻」的最佳猜测。
然后将图像转换网络的输出结果作为「复刻,与内容和风格图像一起通过预训练图像分类网络来计算内容和样式损失。

最后,为了减少损失,需要将损失函数反向传播到图像转换网络的参数中,而不是直接到「复刻结果中。
任意风格迁移
虽然前馈法可以立即生成风格化的结果,但它只能对一个给定的风格图像进行复刻。
是否可以训练一个网络可以接受任何风格图像,并从这两张图像中产生一个风格化的结果呢?
换句话说,能不能做出一个真正任意的风格转移网络?
几年前,有研究人员发现,图像转换网络中的实例归一化层是唯一重要的代表风格的层。
如果保持所有卷积参数不变,只学习新的实例正则化参数,就可以实现在一个网络中表示完全不同的风格。
来自康奈尔大学的一个团队首次将这个想法变成现实。他们的解决方案是使用自适应实例归一化(Adaptive Instance Normalization),使用编码器-解码器架构从风格图像中生成Instance Norm参数,取得了相当好的效果。
当然,以上介绍的这三种方法都要求一定的编程计算机基础,但如果你只是想试玩Deep Dream Generator,可以直接点击下方传送门:
https://deepdreamgenerator.com/generator
参考链接
https://arxiv.org/abs/1703.06868
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
量子位年度智能商业峰会启幕,
李开复等AI大咖齐聚,
邀你共探新形势下智能产业发展之路


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



