协作多智能体强化学习中的回报函数设计

©PaperWeekly 原创 · 作者|李文浩
学校|华东师范大学博士生
研究方向|强化学习
下面总结几篇涉及到为使得多智能体强化学习(MARL)算法能够更好地解决协作问题,而对智能体回报函数(reward function)进行设计的近年论文。这些论文主要可分为以下两个方向:1)解决多智能体社会困境(social dilemma)问题;2)解决多智能体探索(exploration)问题。


AAMAS '18

论文标题:Prosocial learning agents solve generalized Stag Hunts better than selfish ones
论文来源:AAMAS '18
论文链接:https://arxiv.org/abs/1709.02865
这篇工作属于比较早期的工作,其解决的问题也都是只有两个智能体的问题。并且这里所用的多智能体算法属于 Independent MARL 方法,即每个智能体都将其他智能体当作环境的一部分。这篇论文不考虑 MARL 中的环境不平稳(non-stationary)问题。
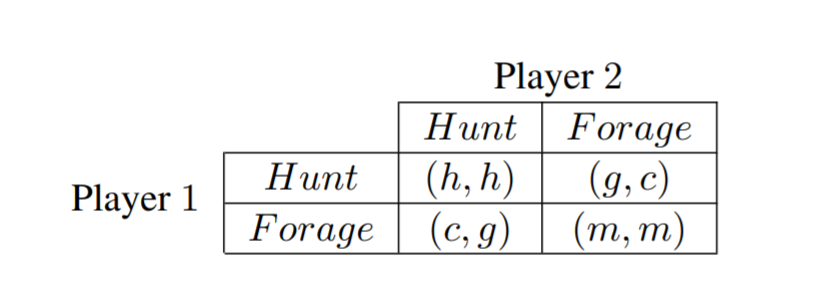 ▲ 图1:Generalized Stag Hunts Problem
▲ 图1:Generalized Stag Hunts Problem

下面我们考虑如何设计一个算法能够使得两个智能体能够收敛到收益主导的纳什均衡。首先引入以下定义:
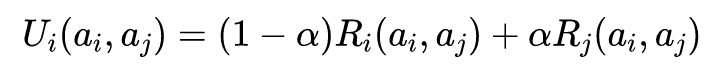
由此,我们可以得到以下定理:
下面给出证明:
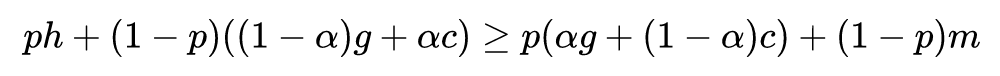
将其扩展到大于两个智能体的场景(并不能扩展到一般的多智能体场景,实质上还是两个智能体),我们可以得出以下引理:
上面引理的定义这里不再详细推导了,感兴趣的读者可以参考原论文。
实验部分,作者在简单环境(matrix game)以及复杂环境(markov game)下,以及两个智能体以及多个智能体条件下,都进行了实验。其中前者使用的是 REINFORCE 算法,后者使用的是 A3C 算法。
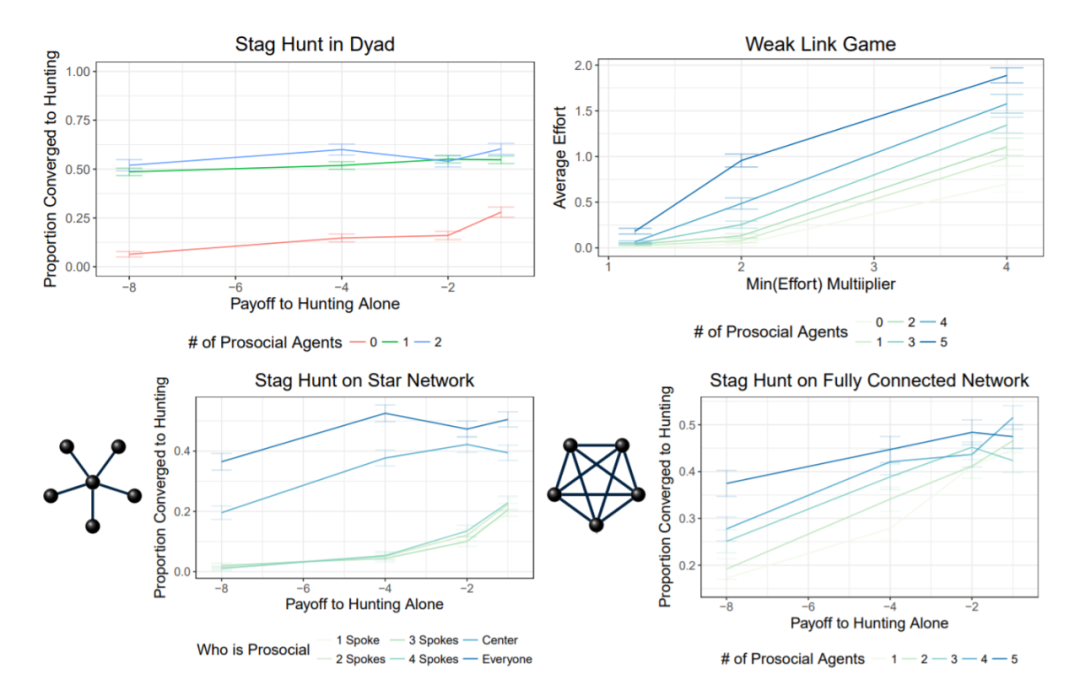
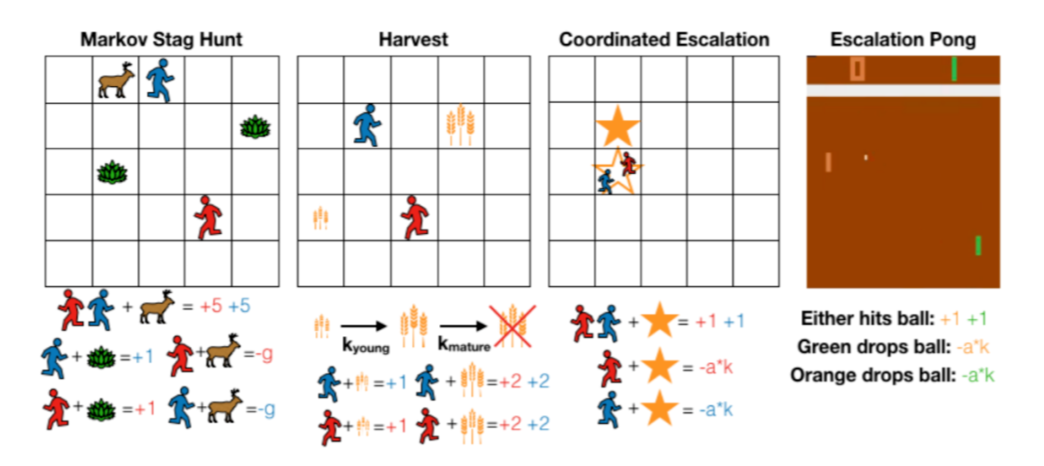
▲ 图4:虽然马尔可夫游戏有更复杂的策略空间,但是依旧保留了雄鹿狩猎问题的高层属性,即社会困境。
亲社会性同样存在很多局限性。首先,如果游戏(或者游戏中的某些部分)不属于雄鹿狩猎游戏,那么赋予一个智能体亲社会性可能或引入新的次优的纳什均衡。
例如,在社会困境中一个亲社会智能体可能会被其同伴所适应。其次,在一个智能体的动作只会对其余智能体造成微弱影响的环境中,亲社会回报将会增加智能体收益的方差,从而使得强化学习算法收敛速度变慢。
最后,本文假设智能体能够对其余智能体的行为做出最优回应,但是当智能体无法做出最优回应时,做出自私的决策可以有更好的结果。本文关注于亲社会性是因为这是一个只改变智能体回报函数的简单方法。
如何在智能体学习的过程中显式地考虑其余智能体的影响,而不是像本文一样独立学习(这个已经有一些工作)?
由于深度强化学习引入函数估计,如何设计一个好的网络结构?
人类的活动中,自身很难收敛到收益主导的纳什均衡,但是引入人工智能体后,可以引导人类群体收敛到更好的结果,如何将本文的结果扩展到人机协同中?
-
社会困境与更好地协作之间有何联系?

ICLR 2018

论文标题:Consequentialist Conditional Cooperation in Social Dilemmas with Imperfect Information
论文来源:ICLR 2018
论文链接:https://arxiv.org/abs/1710.06975
本文考虑的问题是,使用强化学习方法解决只有部分观察(部分观察到环境以及其余智能体的动作)的社会困境。
最简单的社会困境即囚徒困境(Prisoner's Dilemma, PD),两个智能体在两个动作中选择其一,合作或背叛。互相协作双方可以获得最高的收益,但是无论一个智能体选择什么动作,另一个智能体都可以通过背叛得到较高的收益(与雄鹿狩猎问题类似)。
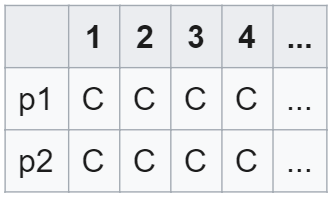
当上述问题变成一个重复问题时,即两个智能体不断面临囚徒困境,目前比较好的策略是“以牙还牙” (tit-for-tat, TFT)。TFT 策略很简单,即复制另一个智能体上一轮的动作,用未来的协作来回馈现在的合作。
TFT策略有以下几个特点:1)易于解释;2)从协作开始;3)如果另一个智能体同样选择协作,则会收到很高的收益;4)可以避免被适应;5)该策略会原谅另一个智能体的背叛行为。
具体看一个例子,假定现在的收益矩阵如下所示:
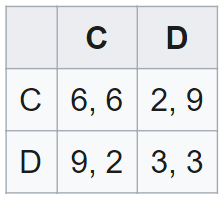
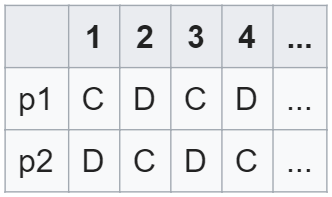
TFT 属于条件协同(conditionally cooperative)策略的一种,即使用这种策略的智能体只有当某种特定条件满足时(对于 TFT 来说,这个条件即另一智能体上一个动作选择协同)才会选择协同。
然而 TFT 策略需要对另一智能体的行为具完美的观测,且需要完美地理解另一智能体的行为的未来结果。
如果信息是不完美的,则智能体必须依靠其能够观测到的信息,来预测另外智能体是否协作并由此进行回应。
本文表明,当游戏能够遍历所有状态(ergodic),则观察到的回报能够作为统计量——如果当前总回报(平均回报)超过某一与时间无关的阈值(通过使用强化学习算法进行自我博弈计算),则智能体选择协作,否则不协作。
本文将上述过程称之为结果性条件协作(consequentialist conditional cooperation,CCC)。
本文的实验环境为 Fishery。在 Fishery 游戏中,两个智能体生活在有鱼出现的湖泊的两侧。该游戏智能体只拥有部分观测,因为智能体无法观测到整个湖面发生的情况。鱼随机产卵,从未成熟开始,从一侧游到另一侧并变得成熟。
智能体可以在湖边捉鱼。捕捞任何成熟度鱼类都能获得回报,但成熟的鱼类更有价值。因此,合作策略是指将幼鱼留给另一智能体的策略。但是,存在一种背叛策略,即既捕捉幼鱼也捕捉成熟鱼。
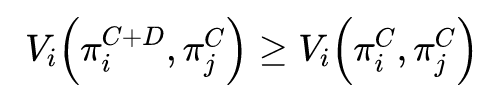
本文使用的强化学习算法基于策略梯度方法,但是不能使用基于状态值函数的方法(例如演员-评论家算法)。例如智能体做了两个不同的策略:“吃掉幼鱼”以及“将幼鱼放去另一边”,只看状态的话这两个状态是一致的(幼鱼消失),因而反而会妨碍强化学习算法收敛。
同时,一般部分观测环境下运行的强化学习算法都会使用 RNN 作为策略网络,但是本文使用的环境 Fishery,由于智能体做决策不需要根据不能观察到的部分(另一边的情况),因而 RNN 是无用的。
为了能够使用 CCC 策略,我们必须计算出 CCC 需要的阈值。计算这个阈值时必须考虑到下述三种情况引入的方差:1)两个智能体的同种策略,由于使用的是函数估计,因而不一定一样(输出层存在随机采样);2)初始状态的不同在有限时间可能会造成影响;3)回报本身就包含随机性。
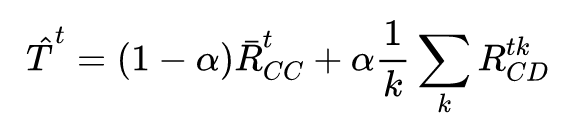

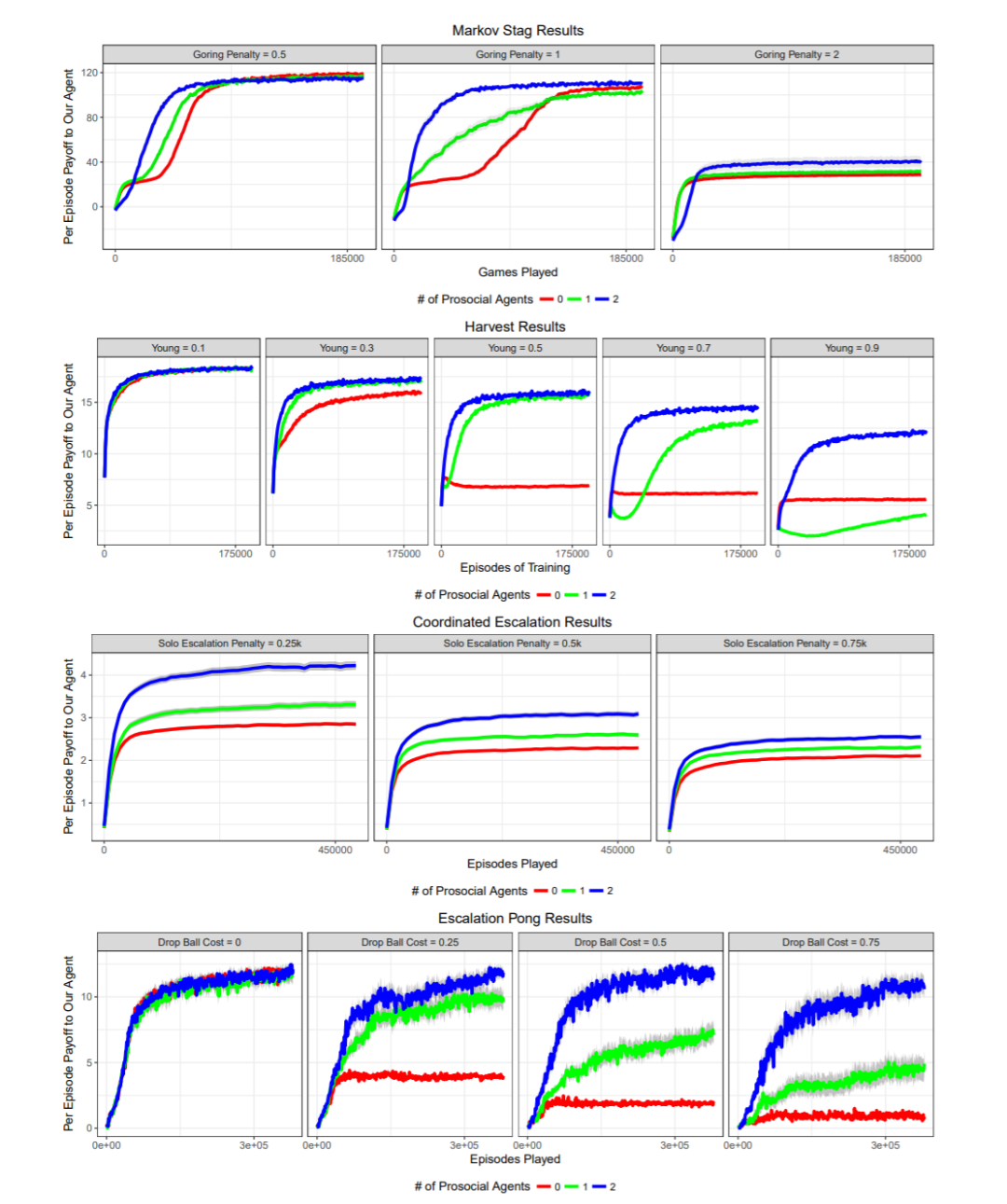
实验一:Fishery
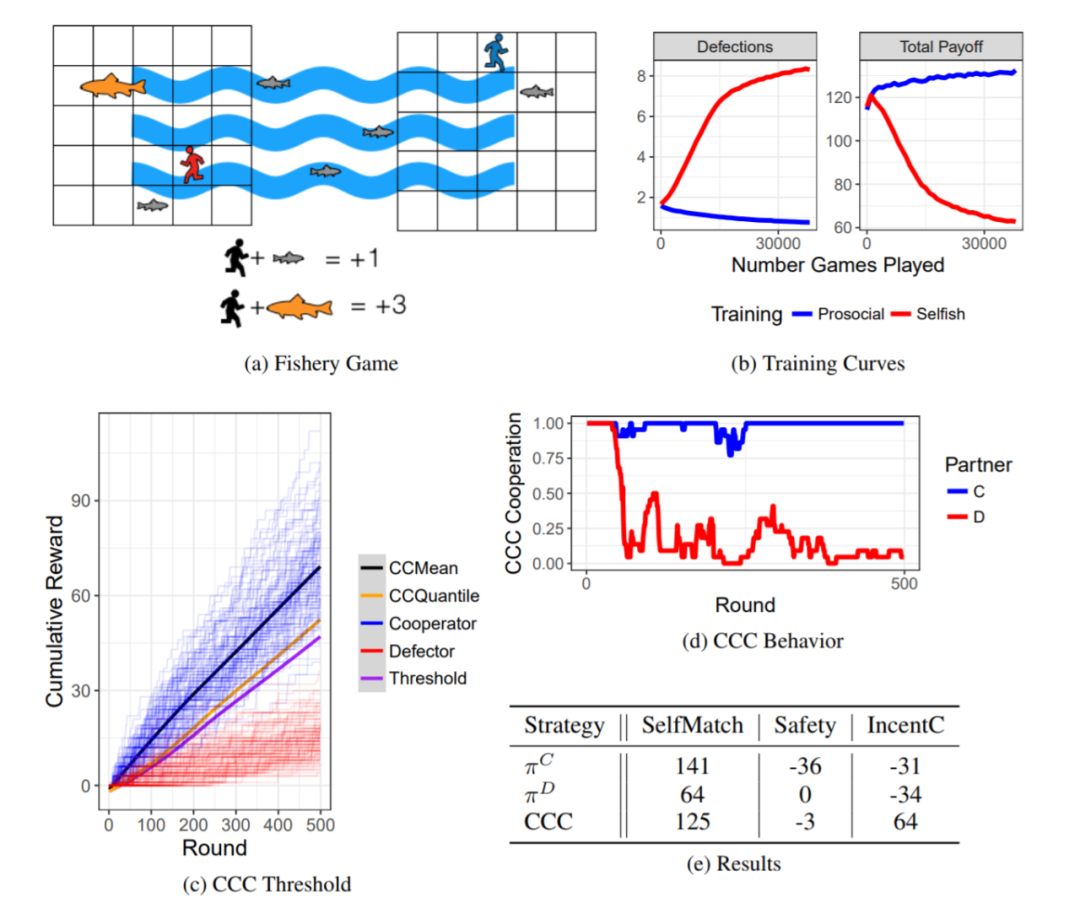
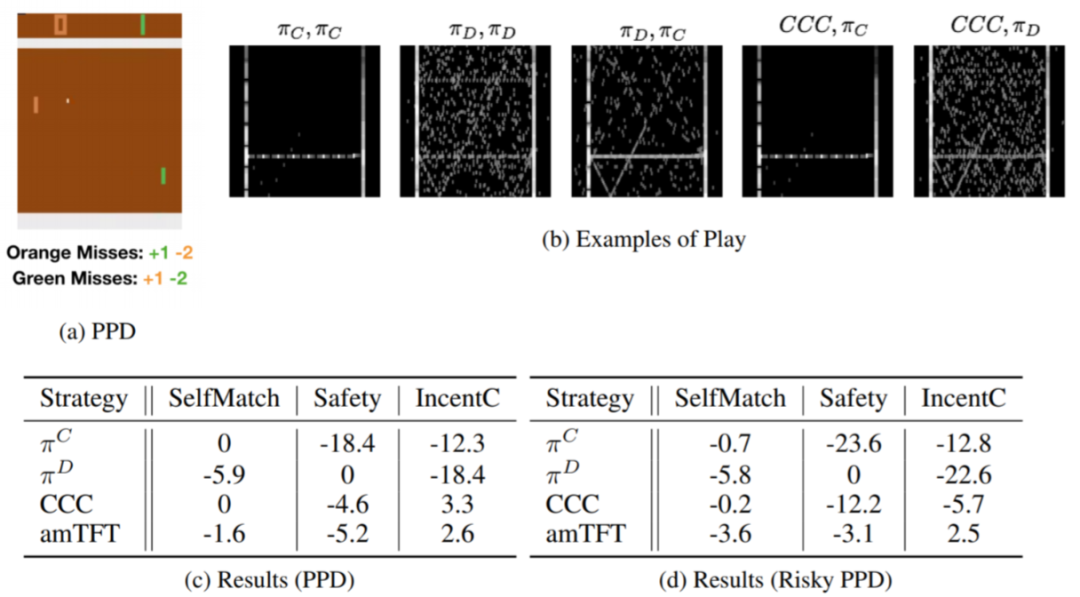
▲ 图7:在乒乓球运动员困境中,进行自私策略的自我博弈训练会使得智能体努力去得分,从而收敛到很差的集体利益上。协作者则会尝试去轻柔的击球,从而两方都可以得分并且没有一方会失球。采用 CCC 策略的智能体面临一个协作的智能体时也会协作,同时不容易被背叛者所欺骗。然而,在更加有风险的乒乓球运动员困境中,CCC 的表现无法超过基准算法。

NIPS 2018

相比于上述两篇工作只能解决 repeated matrix 社会困境问题,这篇工作通过引入不公平厌恶(Inequity aversion [1] )理论,使得基于此的强化学习算法能够解决复杂的视频游戏,并且是真正的多智能体社会困境问题。
许多不同的研究领域,包括经济学,进化生物学,社会学,心理学和政治哲学,都得出了以下观点:公平规范(fairness norm)能够解决社会困境。在一个众所周知的模型中,通过假定智能体具有不公平厌恶偏好来解决社会困境。
拥有上述偏好的智能体会寻求一个平衡,即自身对个人奖励的渴望,以及保持自己的奖励与他人的奖励之间的偏差尽可能小,之间的平衡。
具有上述偏好的智能体可以通过抵制超越其余智能体的诱惑,或(如果可能的话)通过惩罚和劝阻搭便车(free-riding)行为来解决社会难题。不平等厌恶模型已成功地用于解释各种实验室经济博弈中的人类行为。
对于社会困境问题,如果用收益矩阵(payoff matrix)来表示,只能够表示只有 2 个智能体的情况。一旦智能体数量大于 2,则收益矩阵将变成高维张量,不易于表示以及处理。因而本文使用了另一种表示方式,谢林图(Shelling Diagram [2] )。
谢林图简单来说,描述了在其余协作者数量固定的情况下,一个智能体选择协作或者背叛后,获得的相对收益。因而谢林图的横坐标是除了某个智能体之外,剩余智能体中选择协作动作的智能体个数;纵坐标则是这个智能体分别选择协作以及背叛,所对应的收益。
我们可以看几个只有两个智能体的社会困境问题(例如上述的雄鹿狩猎,或者囚徒困境等),对应的谢林图。
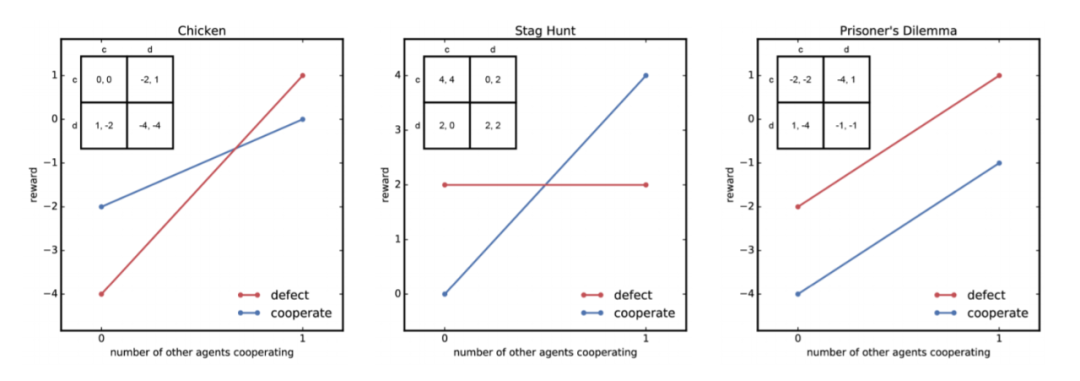 ▲ 图8:Chicken,雄鹿狩猎以及囚徒困境的谢林图表示
▲ 图8:Chicken,雄鹿狩猎以及囚徒困境的谢林图表示
3. 要么具有恐惧(fear)属性,要么具有贪婪(greed)属性,要么都有:
恐惧:为了防止被利用更倾向于互相背叛,即对于足够小的 有 (上述谢林图中靠近原点,红线值大于蓝线值,例如雄鹿狩猎问题、囚徒困境问题);
贪婪:相比于互相合作更倾向于利用协作者,即对于足够大的 有 (上述谢林图中靠近终点,红线值大于蓝线值,例如 Chicken 问题)。
所以根据上述定义,上面展示的三个问题都属于智能体数目为 2 的序列社会困境问题。同时,我们还可以定义,一个序列社会困境问题是跨时期的(intertemporal)。跨时期的意思是,在短期内(short-term)选择背叛是最优的。
多智能体社会困境问题可以分为以下两类:
-
Public goods dilemmas,我称之为生产者困境,即单个智能体为了提供公共资源必须付出成本。 -
Common dilemmas,我称之为消费者困境,即单个智能体为了自身利益会自私地占有公共资源。

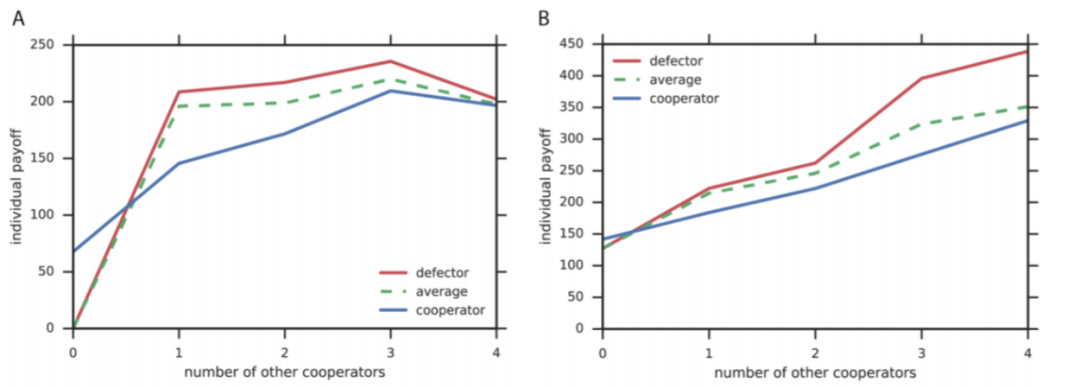
▲ 图9:游戏截图。A:Cleanup 游戏。B:Harvest 游戏。B 图中同时展示了智能体的局部视野范围,这个范围对于所有游戏来说是相同的。
在每个 episode 开始时,环境都会被重置为废物水平刚好超过此饱和点。为了使苹果生长,智能体们必须清除一些废物。在这里,我们存在一个社会困境。
某些智能体需要通过清理含水层为公共利益做出贡献,但是呆在苹果田里将会获得更多的个人回报。这样一来,如果所有智能体都选择背叛,那么没人会得到任何奖励。一个成功的团体必须在搭便车与提供公共资源之间取得平衡。
这个游戏面临的困境如下。每个人如果只为了自己的短期利益,那么都会选择尽快收集周围的苹果。但是,如果智能体不这样做,则整个团体的长期利益就会提高,尤其是当许多智能体分布在在同一地区时。
但是因为选择背叛策略的智能体越多,永久耗尽当地资源的机会就越大,因此上述情况很难出现。因而为了团队的利益,合作者必须放弃个人利益。
下面我们需要证明这两个游戏确实属于多智能体社交困境问题,否则即使通过设计算法解决了这两个游戏,也无法证明我们的算法能够有效地解决多智能体社交困境问题。这里我们就可以画出这两个游戏的谢林图来进行验证。
然而现在的问题在于,画出谢林图必须要明确定义两个不相交的策略集合,即协作策略集合以及背叛策略集合。
但是对于复杂的马尔可夫游戏,上述策略集合很难定义。因为本文对提出的两个游戏通过实验数据来进行分析。我们可以通过对环境进行一些修改来强行使得智能体学习执行协作策略以及背叛策略。
-
在 Harvest 游戏中,我们通过修改环境,阻止智能体从低密度地区收集苹果,来使得智能体强制执行协作策略。 -
在 Cleanup 游戏中,我们通过移除智能体清理废物的能力,来强制智能体执行背叛策略。
设计了两个社会困境游戏之后,下面我们着手解决这两个游戏。像上面讲的一样,我们引入不公平厌恶模型来解决这个问题。不公平厌恶模型最开始提出时只适用于无状态(stateless)游戏,即类似于雄鹿狩猎、囚徒困境等,该模型简单来说就是对智能体的回报函数进行修改,正式定义如下:
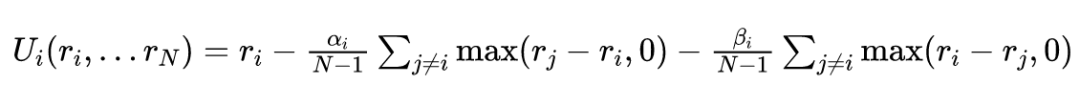
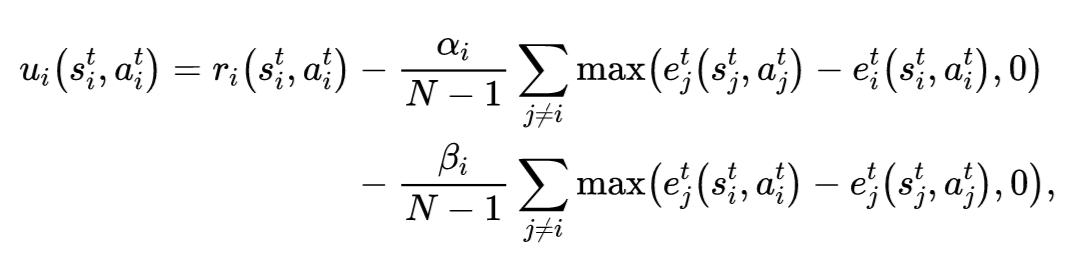
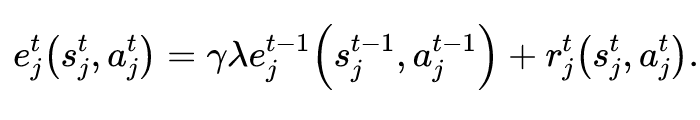
上述时间平滑回报的计算类似于资格迹(eligibility traces)的计算方式。
下面就是实验部分了。在展示结果之前,我们特别定义了几个评价指标。不像单智能体强化学习可以仅仅通过累积收益来衡量智能体的性能。
在多智能体系统中,无法只通过一个简单的标量来去追踪整个系统的性能。因而我们提出了不同的社会性结果衡量指标来对群体行为进行总结,同时辅助分析。
-
效用度量 (Utilitarian metric, ):又被称为集体收益(collective return),定义为 。 -
公平性度量(Equality metric, ):定义为 。 -
可持续性度量(Sustainability metric, ):定义为 其中 。
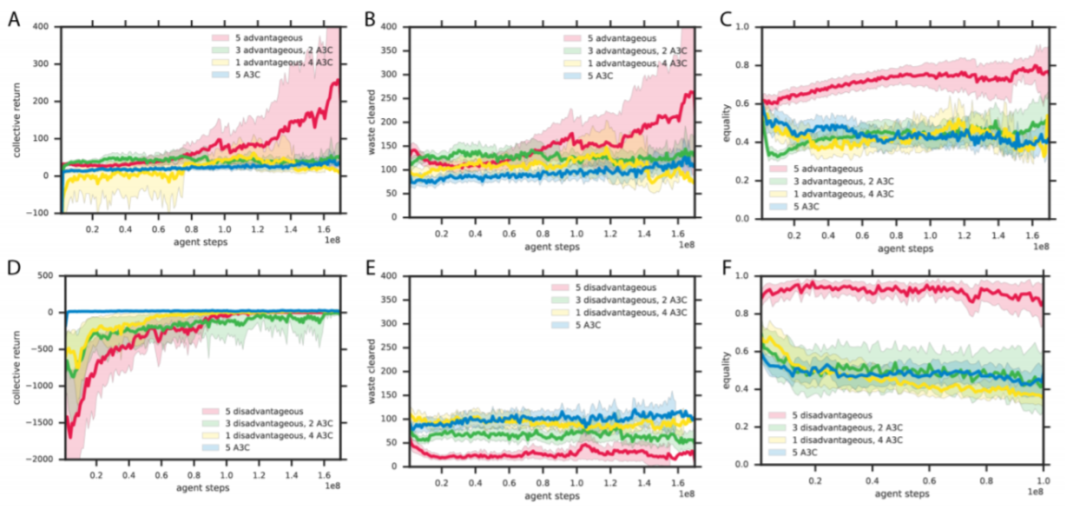
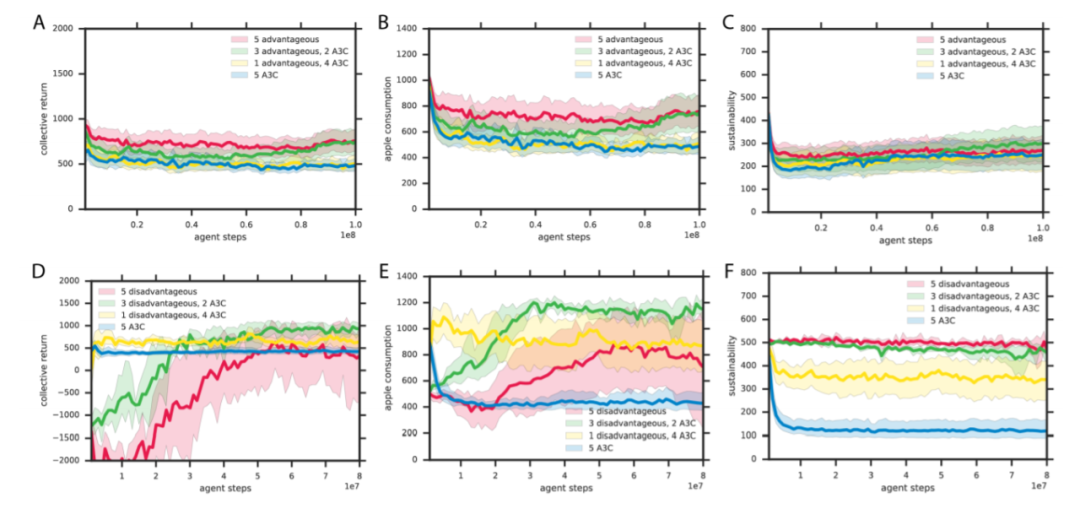
1)我们的背叛智能体很容易被剥削,从实验可以看出需要一个背叛智能体群体才能实现合作;
2)我们的智能体使用结果而不是预测,这在随机性过大的环境中将会存在很严重的问题(这是上一篇文章得到的结论);

PMLR 80, 2018

论文标题:Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning
论文来源:PMLR 80, 2018
论文链接:https://arxiv.org/abs/1810.08647
这篇文章开始将上述文章中为了解决社会困境问题而提出的修改回报函数的方法中,所引入的附加项看作是强化学习中更常见的固有回报(intrinsic reward),并将社会困境看成是更加一般的协作多智能体强化学习问题,且是更需要通过智能体之间的协作来解决的多智能体强化学习问题。
这篇文章其实很好的回答了第一篇文章最后提出的问题:社会困境与更好地协作之间有何联系?
对于上面几篇工作,作者认为他们都是用的是人工设计的回报函数,带有比较强的先验信息(或归纳偏倚,inductive bias),同时需要获取其余智能体的回报。这些假设使得这些算法无法独立地训练每个智能体。
除了对回报函数进行重新设计,也有些其他方法来解决多智能体强化学习中的协作问题,但一般都是通过中心化训练。虽然通信学习方法也是独立学习,但是最近一些工作表明,即使通过中心化学习,想要学到有意义的通信协议也是十分困难的。
为此,本文提出了一个协作多智能体强化学习算法,通过引入能够反映智能体自身动作对其余智能体的因果影响程度的固有回报,来鼓励智能体协作,并把这种固有回报称之为社会影响固有回报(social influence intrinsic reward)。同时,这种固有回报还能促进通信学习算法习得更有意义的通信协议。
因果影响通过反事实推断来评估。在每个时间步,智能体模拟自己选择不同的、反事实的动作,并评估其对于其余智能体动作的影响。能够使得其余智能体动作产生较大改变的动作,被认为具有较大的影响力并会获得奖励。这种固有回报的构建方式,类似于最大化智能体动作之间的互信息。
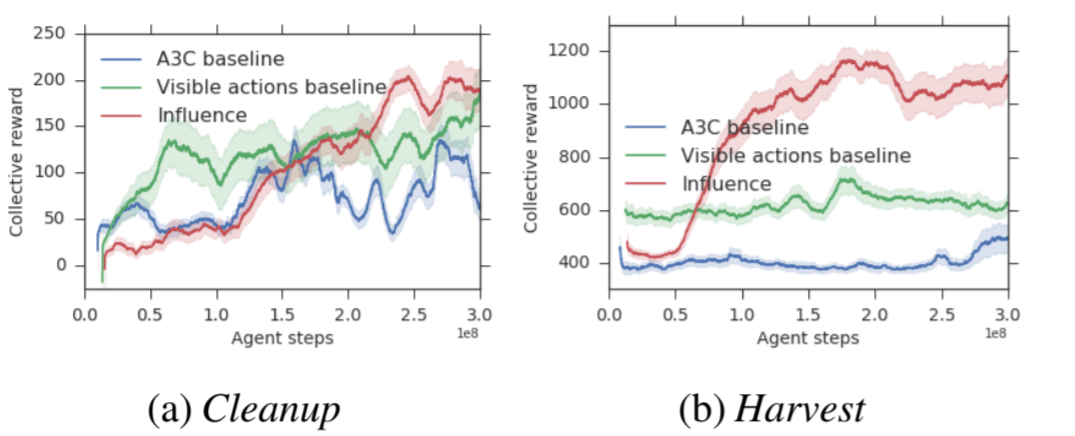
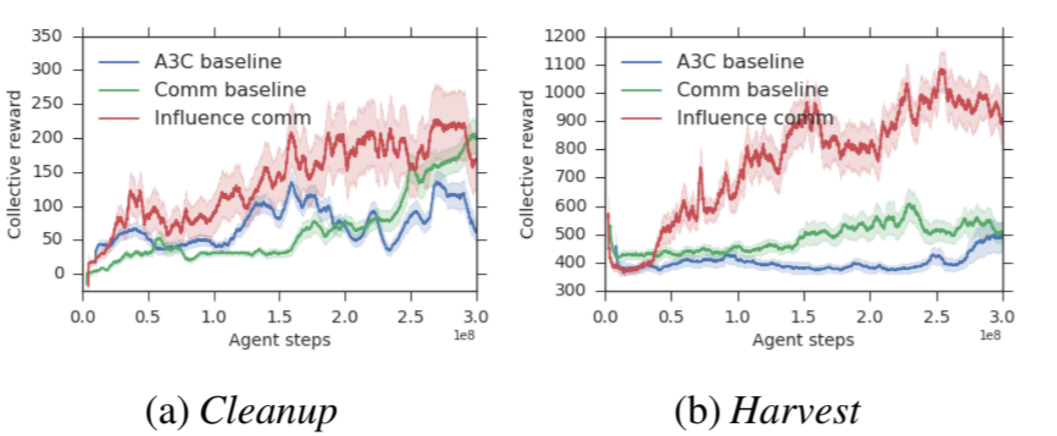
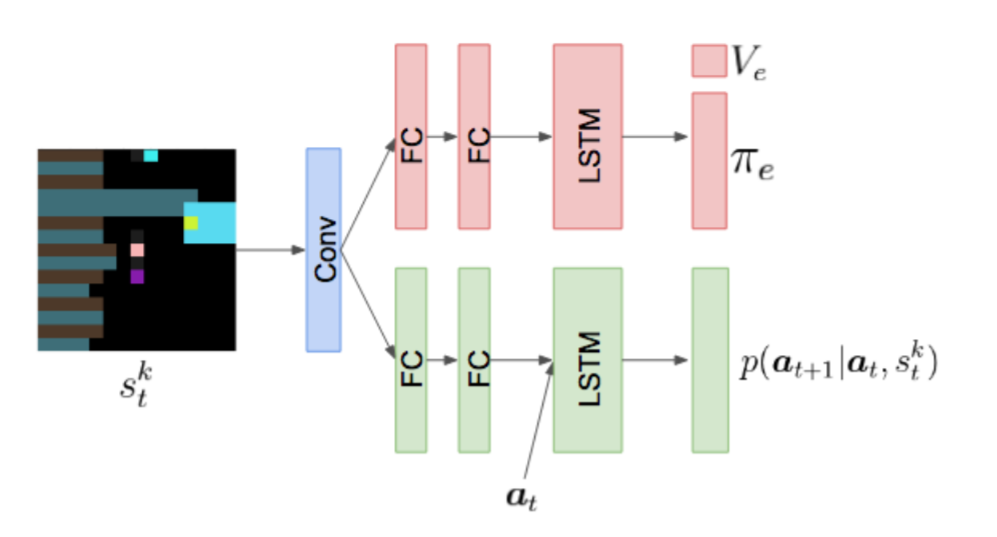
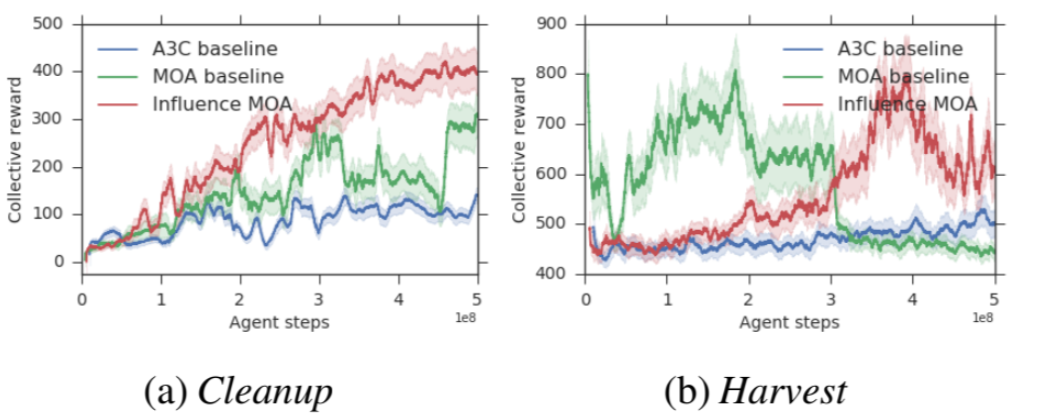
本文采用的实验环境与上一篇论文完全一致,所想要解决的也是序列社会困境问题。本文使用 A3C 算法来训练每个智能体,同时采用 LSTM 网络。
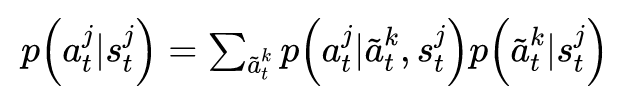
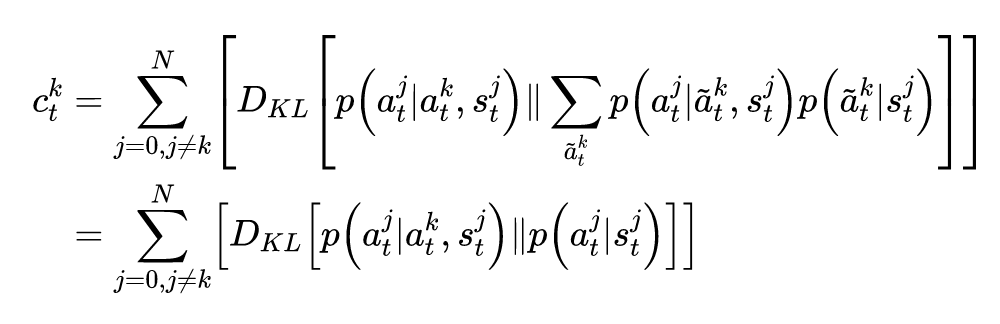
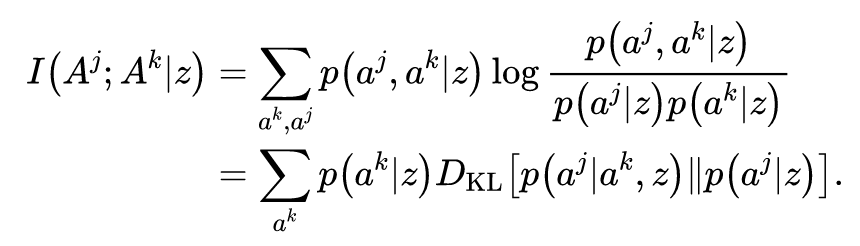
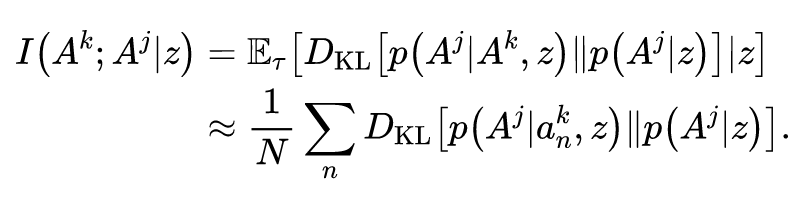
因果影响回报与互信息之间具有联系是十分有意思的,因为在单智能体强化学习领域,有一种经常被使用的固有回报——赋权回报(empowerment),赋权的意思是会给执行的动作与环境的未来状态互信息较大的智能体奖励,即对环境的未来状态赋权。
如果从赋权的角度来解释,因果影响回报则是对其他智能体的动作赋权。
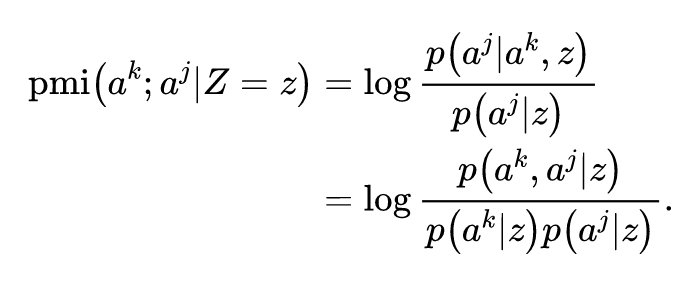
采用社会影响还有另外的优点。我们知道(下述理论来源于 MADDPG),多智能体策略梯度的方差随着环境中智能体数目的增多而增大。社会影响通过引入智能体动作之间的外部依赖关系来减小上述方差。因为智能体策略梯度的条件方差小于或等于边际方差。
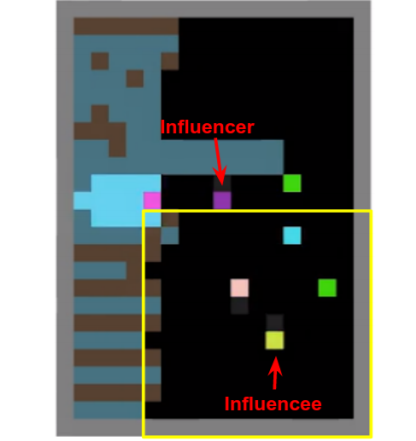
▲ 图14:一个影响者具有高影响力的时刻。紫色的影响者智能体发出了绿色苹果出现的信号给黄色被影响者智能体,即使绿色苹果处于黄色被影响者智能体局部视野范围之外。
在这个案例研究中,紫色影响者智能体学会了使用自己的动作作为一个二元编码,来传递环境中是否存在苹果这个消息。Harvest 游戏中同样有类似的行为。这种基于行为的通信可以与蜜蜂的摇摆舞联系起来。这表明,因果影响回报不仅可以促进协作,还可以促进通信的产生。
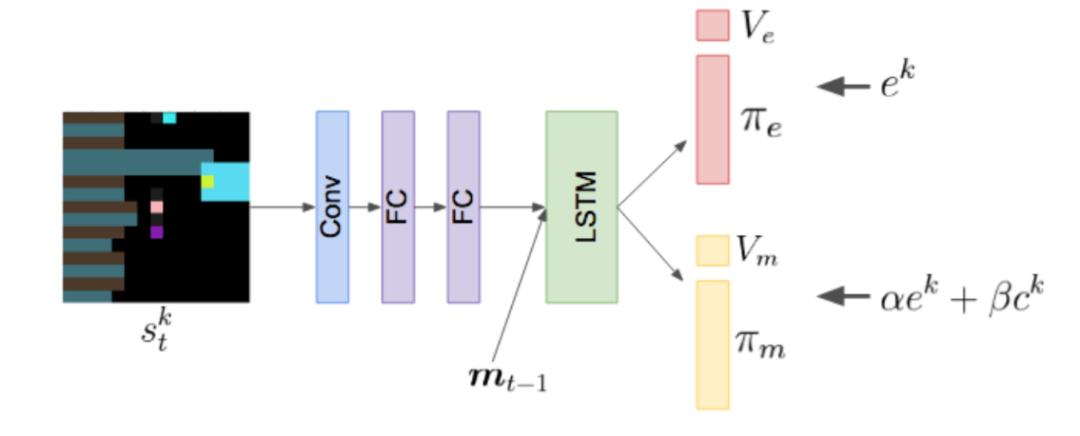
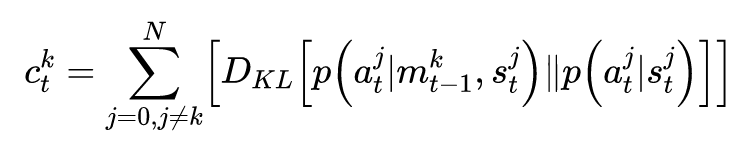
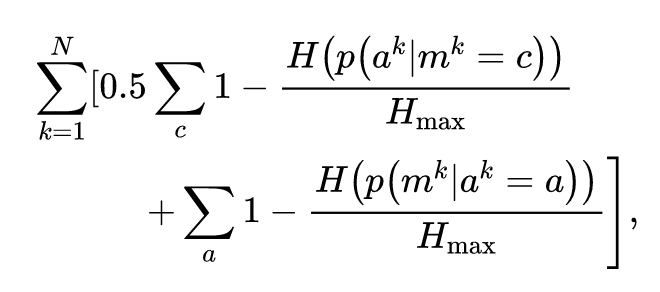
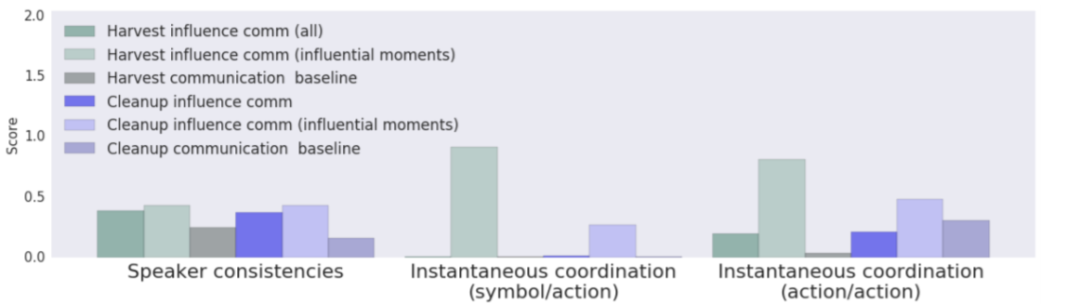
2. 即时协作性(instantaneous coordination,IC)包括如下两个互信息(MI)指标:
信号/动作 IC:衡量影响者/通信发起者的信号与被影响者/通信接收者的下一步动作之间的互信息;
-
动作/动作 IC:衡量影响者/通信发起者的动作与被影响者/通信接收者的下一步动作之间的互信息;
为了计算这两个指标,我们对所有轨迹的所有时间步计算上述两个指标,并选取任何两个智能体之间的最大值,从而确定是否存在任何一对智能体之间存在协作。注意这两个指标都是即时的,即只能捕捉到两个智能体在连续两个时间步之内的短期依赖性。


点击以下标题查看更多往期内容:
-
强化学习中从仿真器到现实环境的迁移
-
漫谈强化学习中的引导搜索策略
-
多智能体强化学习(MARL)近年研究概览
-
鱼和熊掌如何兼得?基于强化学习的多尺度信息传播预测
-
将“softmax+交叉熵”推广到多标签分类问题
-
BERT在小米NLP业务中的实战探索

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






