深度解读 | ElasticDL 深度学习框架简化编程,提升集群利用率和研发效率的秘诀


ElasticDL 是一个基于 TensorFlow 2.x 和 Kubernetes 的开源的分布式深度学习编程框架。2019 年秋天的 Google Developer Day 活动中来自蚂蚁金服的 ElasticDL 团队展示了 ElasticDL 的第一个开源版本。本文更新这大半年来 ElasticDL 项目的进展,尤其是性能优化和业务落地。
ElasticDL
https://github.com/sql-machine-learning/elasticdl
ElasticDL 的首要设计意图是简化分布式编程。它允许用户只提供用 TensorFlow 2.0 API 描述的模型,而不需要用户写分布式训练过程代码。用户的模型定义只要能在本地调通,即可在分布式环境下用大规模数据训练模型,从而提升研发效率。
同时,ElasticDL 提供的弹性调度的能力在实践中可以让集群的利用高达 90%。当集群资源不足时,一个训练作业里的进程减少;当其他作业结束释放资源后,进程数量随之增加。这样的做法比 TensorFlow Distribution Strategy 专注容错(进程减少的情况下作业不失败,但不会增加进程数量)更进一步。并且,因为 ElasticDL 作业容忍变化的 worker 数量,所以每个作业的启动都不必等待集群有足够的资源,而是可以见缝插针的尽早开始训练,从而缩短等待作业启动的时间,让研发人员可以尽快看到第一个迭代的结果,万一分布式训练有问题,也能尽早发现,从而进一步提升了研发效率。

简化分布式深度学习编程
为了从海量数据中学习规律,我们需要编写分布式深度学习程序来完成训练任务。这在工业场景中尤为常见。
可分布式深度学习程序的编写很难 —— 编程者既要了解深度学习,也要了解分布式系统开发。在一个分布式深度学习系统中,需要启动和监控若干个 workers。因为既要拆分训练数据给 workers,还要综合各个 worker 算出的 gradients 来更新模型,所以涉及通信 (Communication) 和 同步 (Synchronization)。此外,当 worker 数目很多时,作业在执行过程中有 worker 挂掉的概率也会变得很大。如果一个 worker 挂掉,则整个作业重启或者恢复到最近的 checkpoint (Fault Recovery),那么重启之后可能又会有 worker 挂掉导致重启,于是作业不断陷入重启和恢复,永远也无法完成。这进一步要求编程者具备设计容错 (Fault Tolerance) 系统的能力。其实不仅分布式深度学习,其他分布式机器学习 程序、分布式离线和在线数据处理程序等各种分布式程序的写作,都对编程者有类似上述要求。
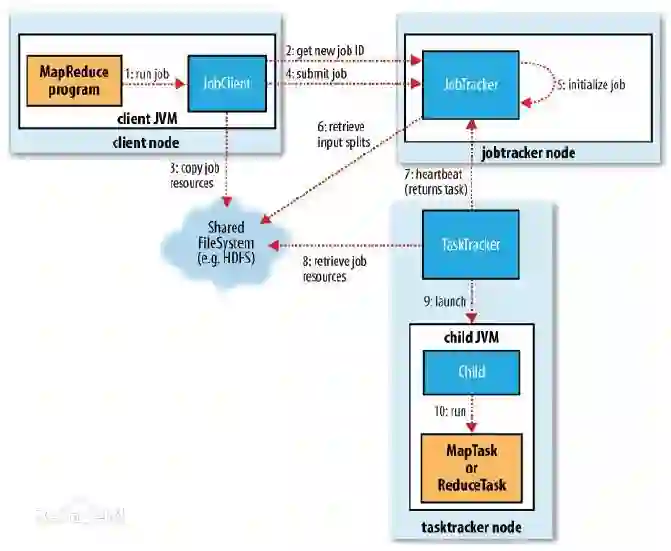
一个常见的解决思路是为特定类型的作业提供分布式编程框架,让用户只需要完形填空一样补上业务逻辑,而分布式计算(包括通信、同步、和容错)都由框架的代码来完成。一个典型的例子是离线数据处理程序用 MapReduce 框架来写。不管是 Google MapReduce 还是 Hadoop MapReduce,用户基本都只需填写 map 和 reduce 两个函数的实现即可。类似的,在线数据流系统基于 Storm 和 Flink 来写,用户只需提供 bolts 和 nuts 这样的业务逻辑定义。
在 ElasticDL 之前,蚂蚁金服的同事们使用过多种框架和类似框架的高层 API。这些方案 大都基于 TensorFlow 和 Kubernetes。
TensorFlow Estimator 作为构建在 TensorFlow 之上的一层 API,允许用户只需定义模 型,而训练过程封装在一个函数调用里。利用 Kubeflow 提供的 TF operator,我们可以将该训练过程以分布式作业的方式启动在Kubernetes 上。这个方案的局限是:它仅支持 TensorFlow 的 graph mode,不支持 eager execution;而 eager execution 可以 大幅简化调试,尤其方便跟踪网络各层输出。
Keras API 支持 TensorFlow 2.x 和 eager execution。目前 TensorFlow 2.x Keras API 还暂不支持 ParameterServer 分布式策略,对 AllReduce 分布式策略提供了实验性的支持。
-
Horovod 对用户代码有侵入性,用户除了必须熟悉 TensorFlow API 之外,还需学习 Horovod API。


def forward(): inputs = tf.keras.Input(shape=(28, 28), name="image") x = tf.keras.layers.Reshape((28, 28, 1))(inputs) x = tf.keras.layers.Conv2D(32, kernel_size=(3, 3), activation="relu")(x) x = tf.keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu")(x) x = tf.keras.layers.BatchNormalization()(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x) x = tf.keras.layers.Dropout(0.25)(x) x = tf.keras.layers.Flatten()(x) outputs = tf.keras.layers.Dense(10)(x) return tf.keras.Model(inputs=inputs, outputs=outputs, name="mnist_model")
def loss(labels, predictions): labels = tf.reshape(labels, [-1]) return tf.reduce_mean( input_tensor=tf.nn.sparse_softmax_cross_entropy_with_logits( logits=predictions, labels=labels ) )
def optimizer(lr=0.1): return tf.optimizers.SGD(lr)
def feed(dataset, mode, _): def _parse_data(record): if mode == Mode.PREDICTION: feature_description = { "image": tf.io.FixedLenFeature([28, 28], tf.float32) } else: feature_description = { "image": tf.io.FixedLenFeature([28, 28], tf.float32), "label": tf.io.FixedLenFeature([1], tf.int64), } r = tf.io.parse_single_example(record, feature_description) features = { "image": tf.math.divide(tf.cast(r["image"], tf.float32), 255.0) } if mode == Mode.PREDICTION: return features else: return features, tf.cast(r["label"], tf.int32)
dataset = dataset.map(_parse_data)
if mode == Mode.TRAINING: dataset = dataset.shuffle(buffer_size=1024) return dataset

-
文件名或者表名, -
第一条记录相对于文件(或者表)开始处的偏移 (offset), -
这个 task 里的总记录数。
-
RecordIO
https://github.com/wangkuiyi/recordio -
MaxCompute
https://www.alibabacloud.com/zh/product/maxcompute
-
读取一个 mini-batch 的训练数据。 -
用本地模型 (local model) 作为参数调用用户定义的 forward 函数以计算 cost。如果 模型很大,则部分参数可能来自于 parameter server。 -
给定 cost,worker 利用 TensorFlow eager execution 的 GradientTape 机制,进行 backward 计算,得到梯度 (gradient)。 -
如果是 synchronous SGD,此时 worker 调用 AllReduce 实现 FTlib 来同步 gradients 并且更新模型。如果是 asynchronous SGD,worker 不定时的向 parameter server 上传 gradients,也不定时地从 parameter server 获取全局模型参数。
-
在 parameter server 上惰性初始化 (lazy initialize) embedding vectors —— 在使用到 vector 的时候才初始化。 -
把一个 embedding table 拆分到多个 parameter server 进程里以均衡存储与通信负载。 -
worker 从 PS 请求 embedding vectors 时,先滤除重复的 embedding ID,只取回不同 ID 的 vectors,从而减少通信量。 -
worker 向 PS 发送梯度时,先把相同 ID 的梯度进行合并(调用 TensorFlow 的 embedding vector combination 函数),从而减少通信量。

-
Gang Scheduling
https://en.wikipedia.org/wiki/Gang_scheduling

-
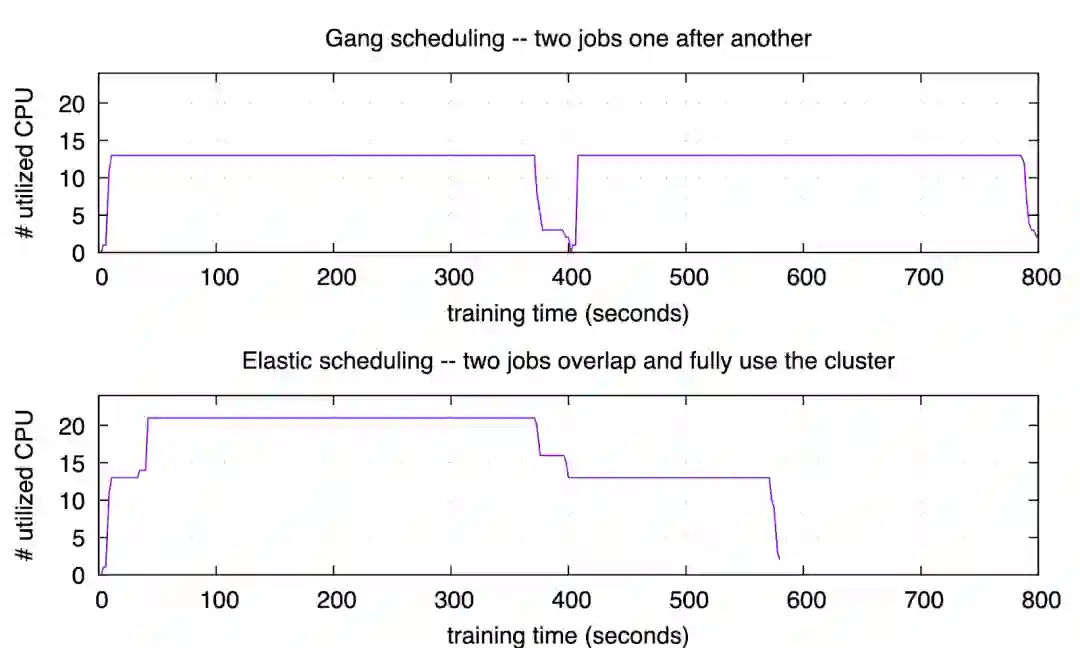
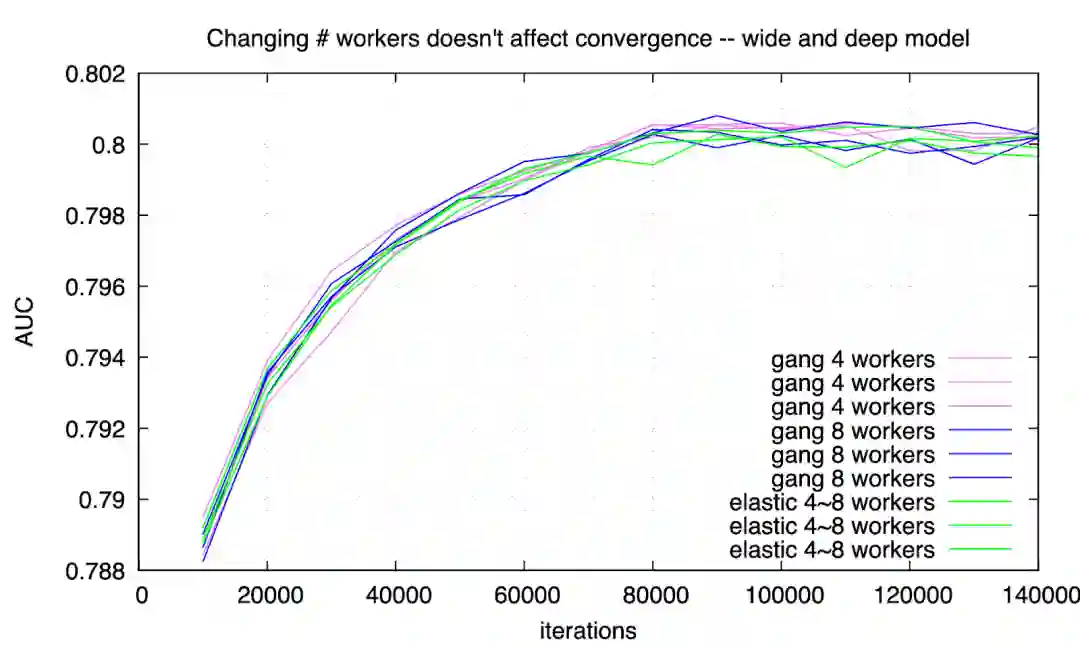
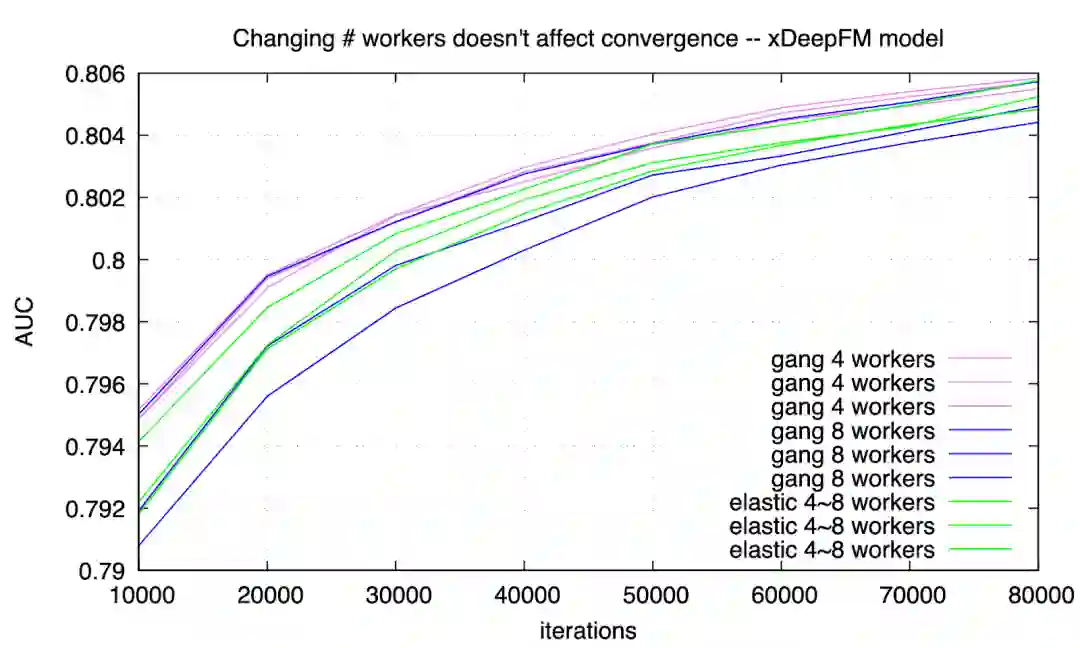
用户等待作业启动时间几乎是 0 。这对于 AI 工作很重要,因为用户最关注的是第一个迭代尽快开始—— 如果第一个迭代失败了,很可能是用户程序的 bug。另外,深度学习模型往往需要手动调优,学习率、optimizer、activation 等配置如果不合理,往往在前几个迭代就能发现;因此第一个迭代能立刻开始,对模型调优的工作效率提高有很大帮助。 -
集群利用率高 。第二个实验 (elastic scheduling) 执行期间,有一段时间集群利用率是 100%;其他时间也不低于第一个实验 (gang scheduling)。 -
作业完成更快 。第二个试验里,两个作业用了约 580 秒;第一个实验里需要约 795 秒。





更多精彩推荐
☞GitHub 开源代码究竟受不受美国出口管制?Linux 基金会白皮书官宣答案!
☞云计算与星辰大海的结合——不要回答,来自百亿光年外的未知信号
![]()
点分享 ![]()
点点赞 ![]()
点在看