CVPR 2020 Oral | 将SOTA行人再识别系统精度降至1.4%,中大、暗物智能等向视觉模式匹配的鲁棒性发起挑战
机器之心专栏
作者:Hongjun Wang、Guangrun Wang等
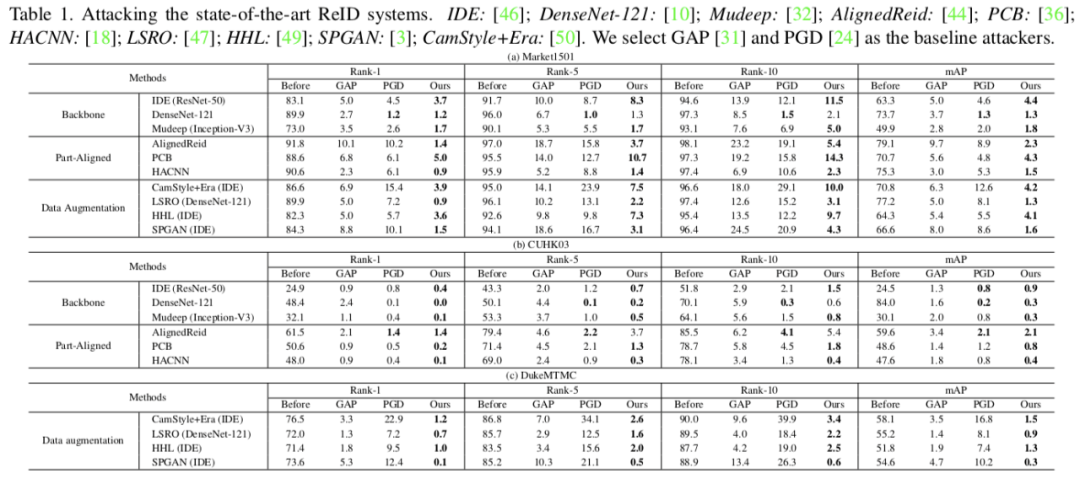
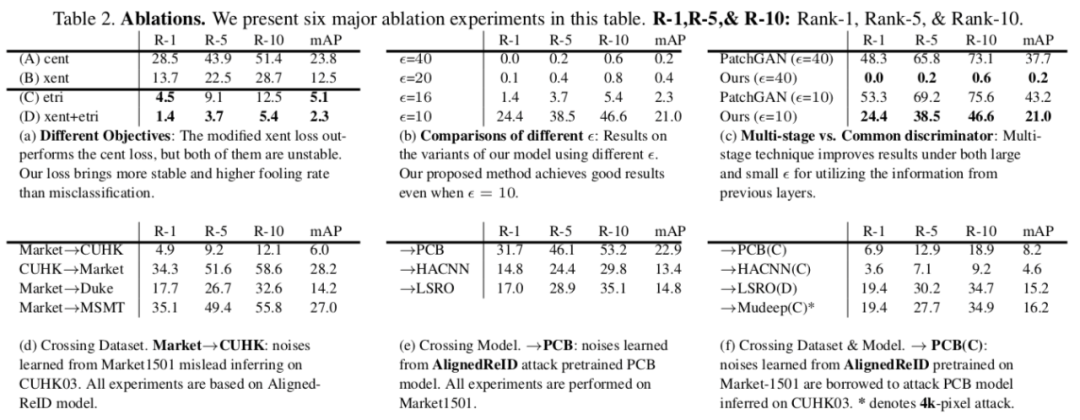
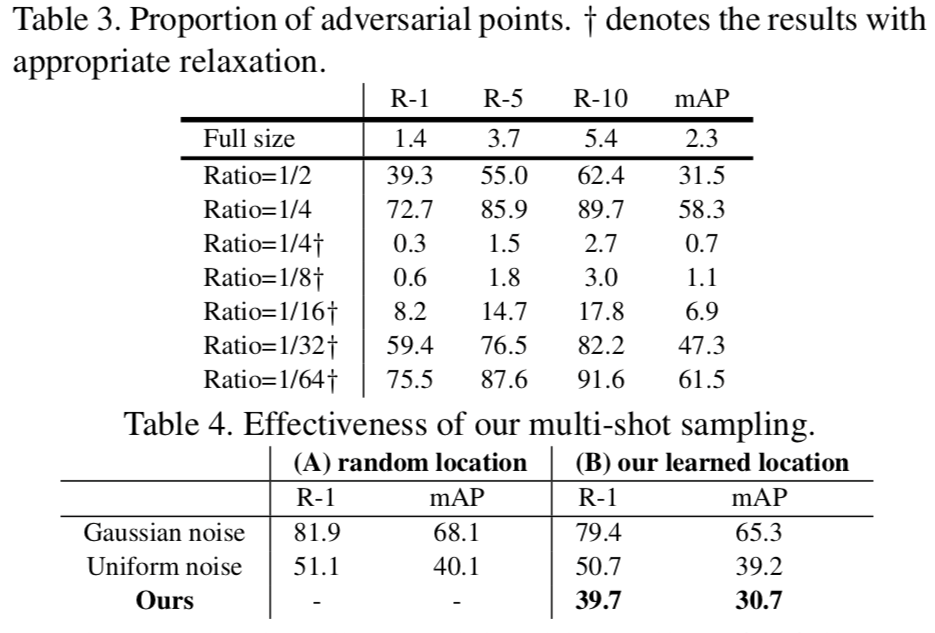
行人再识别系统(re-ID)无处不在,可以在不同摄像头拍摄的视频中精确地找出同一个人,但这种系统也很容易被对抗样本所欺骗,因此检验 re-ID 系统抵抗对抗攻击的鲁棒性非常重要。来自中山大学、广州大学和暗物智能的研究者们通过提出一种学习误排序的模型来扰乱系统输出的排序,从而检验当前性能最佳的 re-ID 模型的不安全性,为 re-ID 系统的鲁棒性提供了改进的方向。该论文已被 CVPR 大会接收为 oral 论文。



论文链接:https://arxiv.org/abs/2004.04199
代码链接:https://github.com/whj363636/Adversarial-attack-on-Person-ReID-With-Deep-Mis-Ranking
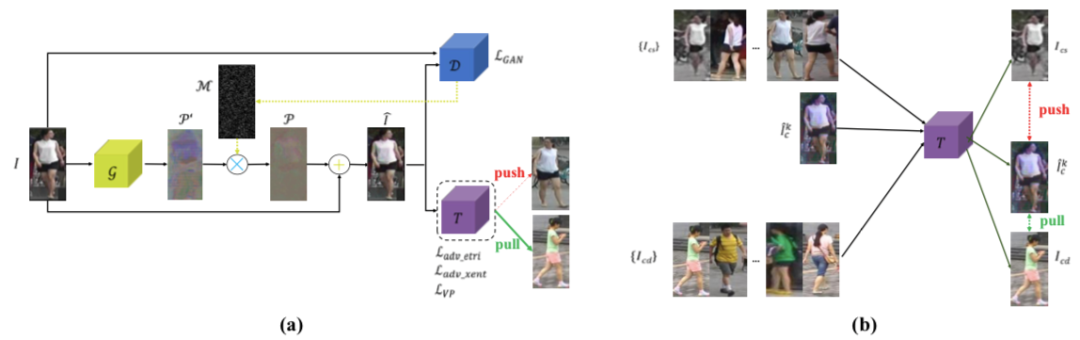
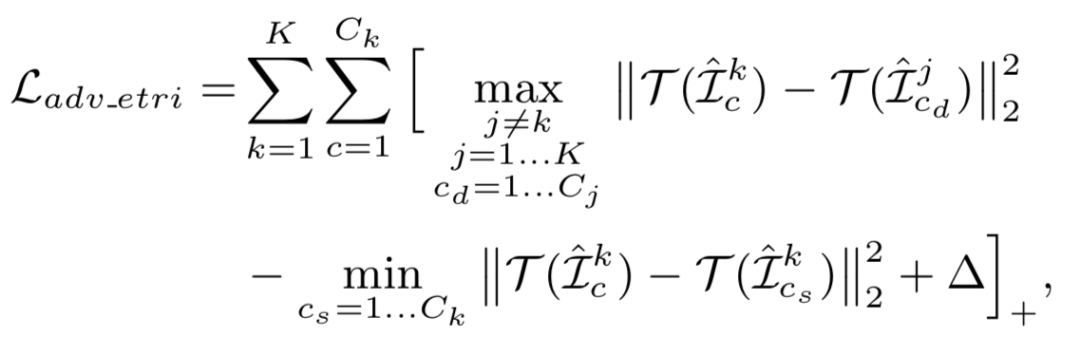
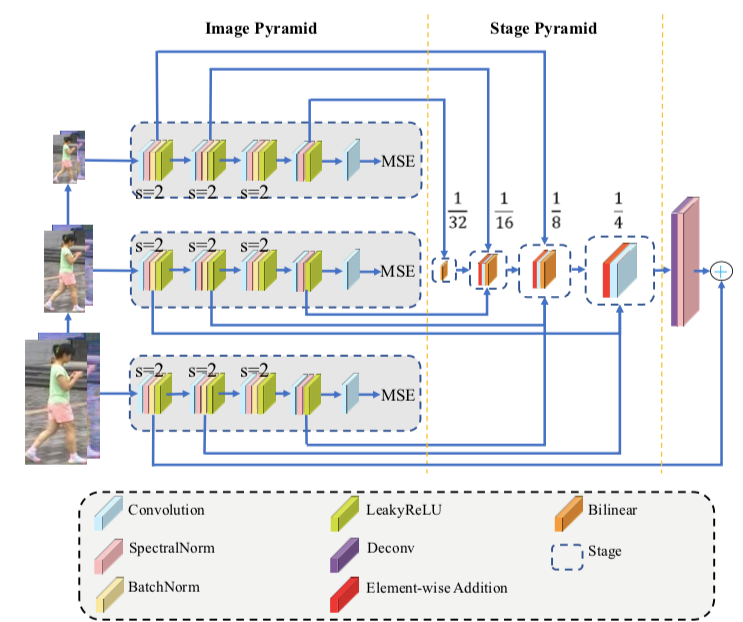
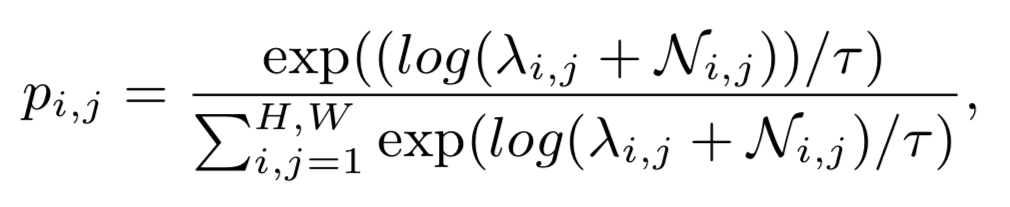
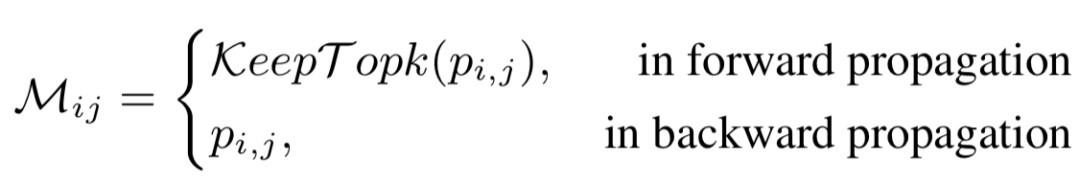
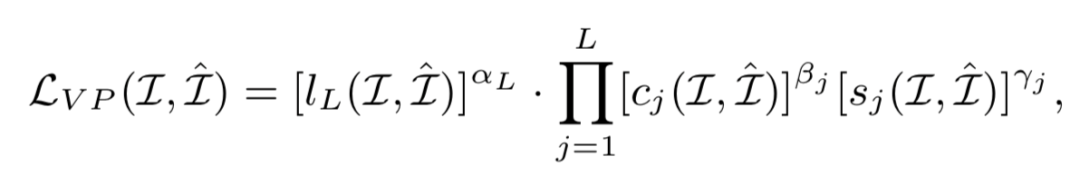
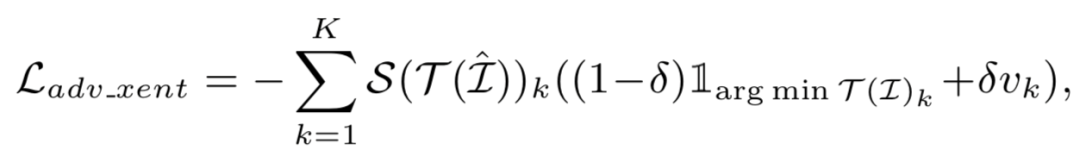
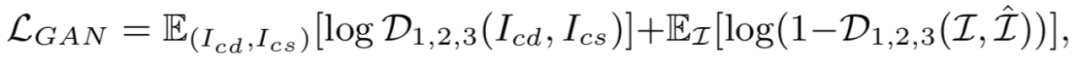



Hongjun Wang*, Guangrun Wang*, Ya Li, Dongyu Zhang, Liang Lin, Transferable, Controllable, and Inconspicuous Adversarial Attacks on Person Re-identification With Deep Mis-Ranking [C]. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Washington, USA, June 16 - 18, 2020.
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In S&P, pages 39–57. IEEE, 2017. 4, 8
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. CoRR, abs/1412.6572, 2014. 3
Shengyong Ding, Liang Lin, Guangrun Wang, and Hongyang Chao. Deep feature learning with relative distance comparison for person re-identification. PR, 48(10):2993– 3003, 2015. 2, 3
XuanZhang,HaoLuo,XingFan,WeilaiXiang,YixiaoSun, Qiqi Xiao, Wei Jiang, Chi Zhang, and Jian Sun. Aligne- dreid: Surpassing human-level performance in person re- identification. CoRR, 2017. 1, 2, 5, 6, 7
