腾讯游戏 :我们如何基于 StarRocks 构建云原生数仓

作者 | 腾讯游戏公共数据平台部基础数据平台团队
他们在数据分析加速项目中,经过多方的技术栈选型,引入 StarRocks 作为数据分析平台的引擎底座。同时,在和 StarRocks 社区的不断沟通设计讨论中,他们为社区贡献了一套全新的 Serverless 存算分离方案,已完成第一版开发测试和代码合入社区主干的工作,并开始在腾讯游戏内部业务落地。
360、欢聚时代、游族等 StarRocks 社区成员对该方案特性也非常认同,接下来会一起参与方案的社区共建及优化落地,推动 StarRocks 在云原生数仓方向的持续演进
腾讯游戏公共数据平台部为腾讯数百款游戏提供基础的数据平台支撑,利用数据科学的方法,助力游戏在商业化、游戏品质和渠道效率层面进行提升。腾讯游戏业务的品类和产品数量多,环境复杂。面对日新增数据量在百 T 万亿条级的挑战,数据分析平台不仅仅要满足活跃、付费、新增等基础用户行为指标的分析,也要处理各种游戏内的复杂数据,包括对局数、道具产出、消耗等对局情况。同时还需要基于海量用户和数据进行运营支持。业务的发展给数据分析带来了三大挑战:
游戏业务对实时分析的需求越来越强烈,需要多维度、更及时的数据来支撑游戏运营决策,希望能够将实时和离线业务统一分析。
原有的解决方案依赖组件较多,架构偏复杂,运维难度大。
集群的数据量和计算量的增长并不完全匹配,对计算和存储的弹性要求越来越高。
经过选型评估,我们最终选择了 StarRocks 作为数据平台的底座,并且和 StarRocks 社区一起讨论设计了一套全新的 Serverless 存算分离方案,目前已经完成了第一版本的开发测试工作。基于腾讯云 Kubernetes(TKE)及对象存储(COS) 平台的 StarRocks 存算分离方案,目前已上线平稳运行。团队同时也在公司内参与腾讯大数据技术委员会领导的天穹 Oteam(详见 Part 五)开源协同建设,积极推动 StarRocks 成熟能力融入腾讯大数据体系之内。
为了简化腾讯游戏公共数据平台技术栈,提高查询效率,我们从不同维度进行了技术栈的筛选:
架构简洁,数据自动均衡,确保运维复杂度不会太高
查询高效,秒级响应,提供极速的即席查询体验
函数丰富,能够为业务提供 UDF 函数支撑
稳定支持实时和离线的数据源导入,支持流批一体架构
架构扩展性强,存算一体的架构能通过定制扩展实现存算分离
在经过一系列的对比后,我们选择 StarRocks 作为分析平台 OLAP 存储引擎,并决定与 StarRocks 社区合作,将计算层从 BE 节点剥离,形成存算分离的结构。在当前 StarRocks 的存算一体架构中,BE 既作为存储节点,也作为计算节点负责执行查询计划任务。随着接入业务查询分析场景越来越多,定位发现很多查询的瓶颈并不在 IO,而是在计算(CPU 和内存)。因此,如果我们希望提升用户体验,就只能选择加 BE 节点。但是 BE 节点本身又是带存储的,不仅扩容时会带来数据迁移,而且扩充的存储资源也是一种资源浪费。同时,针对不同的查询分析场景,如 SQL 相对固定的报表分析以及自定义 SQL 查询,期望二者之间能进行节点的隔离,避免相互影响。综合上面两点需求,我们认为需要对 BE 节点进行改造,实现了纯计算节点 CN(Compute Node)以及 BE 数据的数据下沉,来构建存算分离后的 StarRocks 的 Serverless 架构。
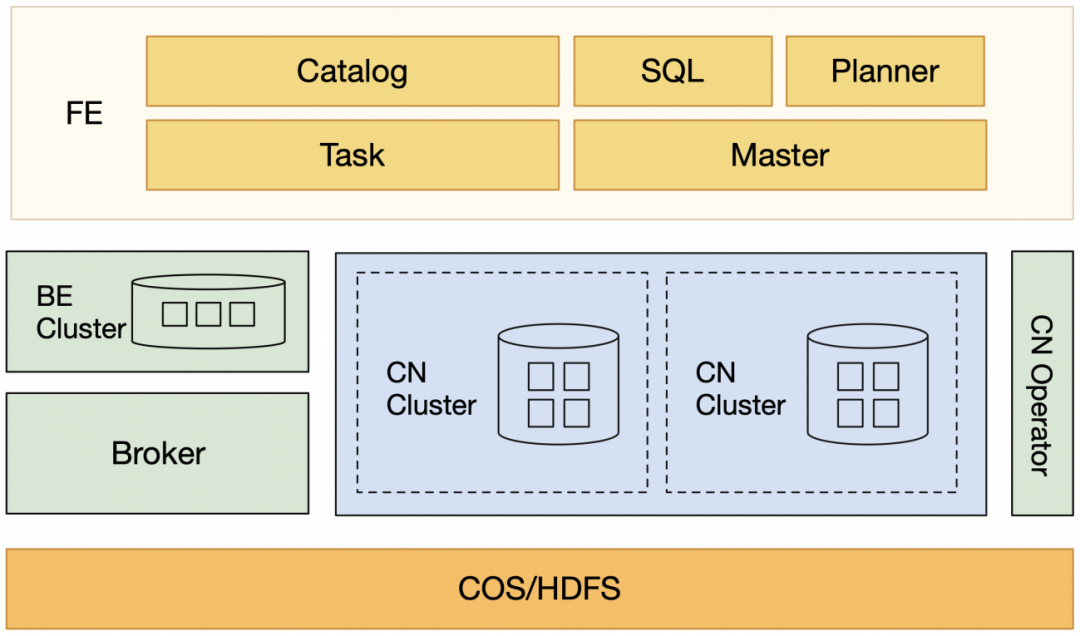
在拆分了存储层与计算层后,我们选择 Kubernetes 作为 StarRocks 上云的运维底座。基于 Kubernetes,我们开发了 StarRocks CRD 与 StarRocks Controller。StarRocks CRD 帮助我们可以通过声明式 yaml 文件进行 Operator 及 StarRocks 的部署,而 StarRocks Controller 帮助我们管理 pod 的状态,将现实的状态向期望状态转化。
在 StarRocks 中,FE 节点接收到客户端发起的 SQL 请求,经过 Optimizer 生成一棵分布式执行计划树,然后转换成 BE 可以直接执行的 PlanFragment,根据元信息下发到相应的 BE 节点。
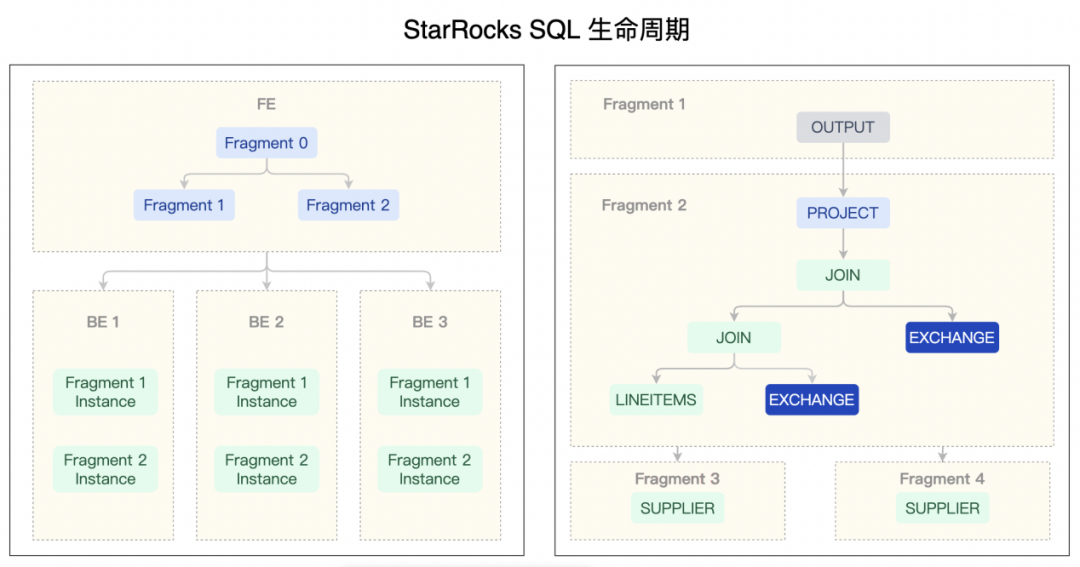
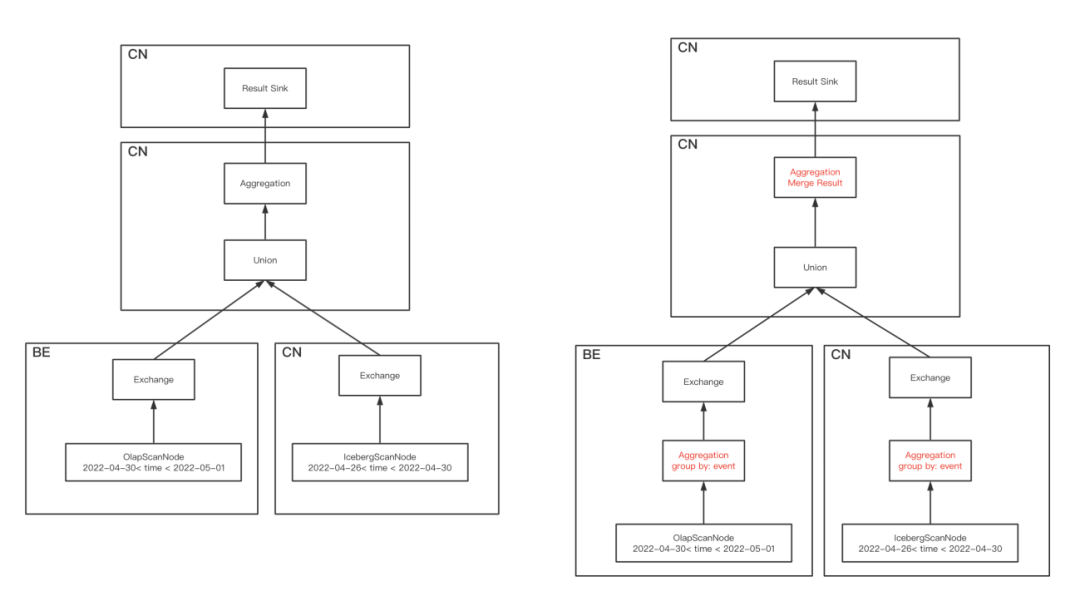
以简单的聚合为例。原先 StarRocks 的逻辑是,StarRocks 会根据数据所在位置,选择对应的 BE 进行数据读取以及初次聚合操作,如果数据存在于外表中,也会由这些 BE 进行读取聚合。然后给这些 BE 一个 partition id ,将数据根据聚合的 key 进行 hash 分组,将分组后的数据分发到对应 partitionId 的 BE 上,BE 通过 ExchangeNode 接收数据进行二次聚合,完成后最终交由原先选举的 ResultSink 对应的 BE 进行最后的聚合计算。
为了将计算操作从 BE 节点中拆分出来,我们需要完成以下步骤:
新增一种 DummyStoargeEngine 的存储引擎,不存储数据,只用来保存 StarRocks cluster id
裁剪 BE 节点的 InternalService 和 HttpService,并支持使用空存储路径启动
调整启动参数和新增启动脚本,支持和 BE 同时运行
在经过拆分后,我们将 BE 的计算能力独立出去成为一个无状态的 Computer Node (CN) 节点,在设置了 CN 节点的调度参数后,整体的执行逻辑发生了变化,如下图所示:
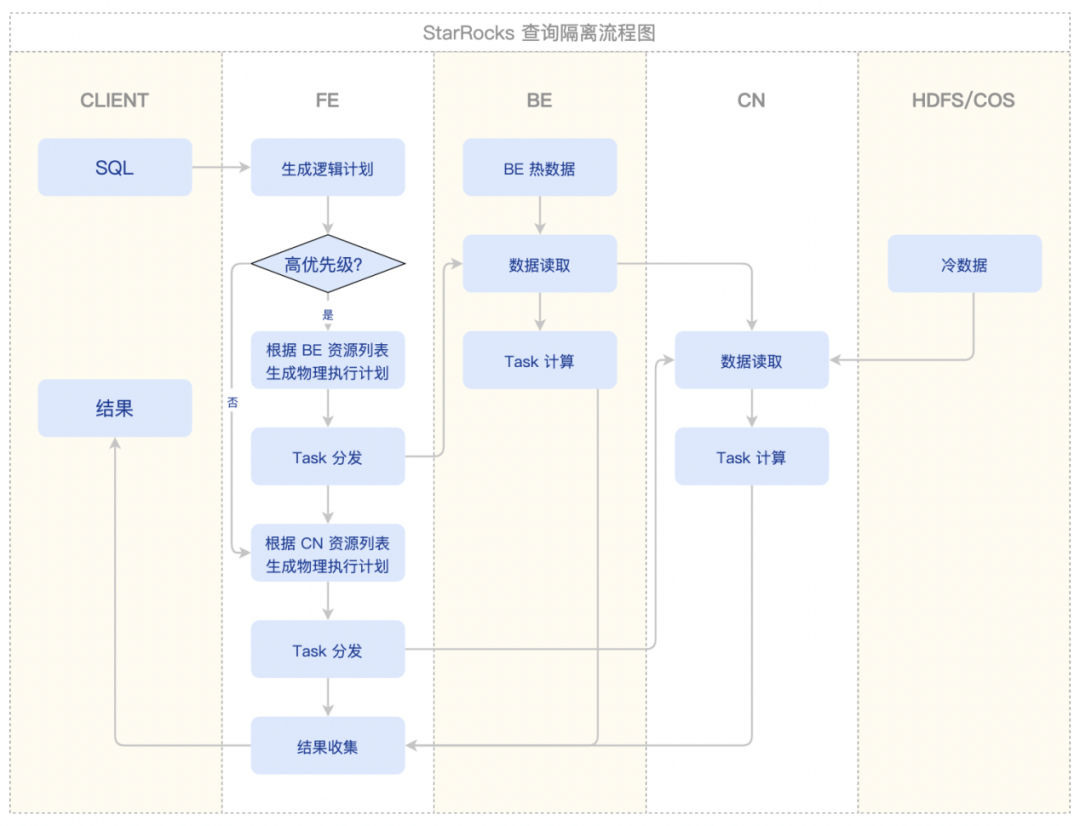
我们依然以简单的聚合操作为例:
OlapScanNode 会选 tablet 所在的 BE 进行数据读取以及初次聚合操作,而 HdfsScanNode 则会根据数据情况均衡地分发给 CN 进行读取与初次聚合
为每个 CN 生成一个 partitionId,将 BE 与 CN 初次聚合后的数据根据聚合的 key 通过 hash 计算对应到 partitionId 然后发送到所在的 CN 上,CN 通过 ExchangeNode 接收数据进行二次聚合
从这些 CN 节点选取一个作为 ResultSink,上一步完成后最终交由这台 CN 进行最后的聚合计算
游戏业务遇到周年庆、营销活动、节假日等节点,会伴随后端流量、日志量的激增,也会带来分析平台负载激增。CN 计算节点拆分独立后,我们进一步结合 Kubernetes(TKE)能力,打通公司算力平台,最终使得 StarRocks 具备计算层面的弹性伸缩能力。基于云原生的理念,我们通过容器化的方式来创建 CN 节点,并通过 K8s 的能力来做到快速的创建和扩缩容。
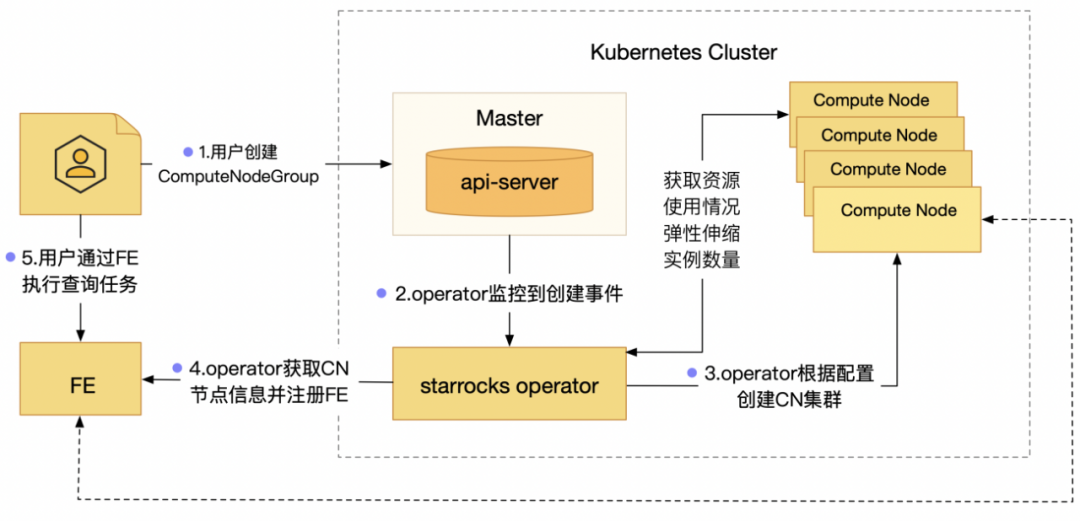
团队实现了 StarRocks 的 Operator 自定义控制器,负责监控 k8s 集群内的自定义资源的创建、改动、销毁等事件,并触发相应的逻辑。StarRocks Operator 主要分为两个组件:
CRD 用来定义 ComputeNodeGroup 的资源类型,帮助我们通过声明的方式进行节点在 Kubernetes 上的部署与管理。在 CRD 中,我们定义了 ComputeNodeGroup 资源类型,用来管理 CN 节点的状态
StarRocks Controller 会根据声明的信息创建 Deployment,帮助我们管理集群的状态。当我们声明式的扩容或缩容节点时,Controller 可以帮助我们将集群向期望状态转化。
当容器启动成功以后,自动调用 FE 的接口,将这些 CN 注册到集群里面。当我们将 StarRocks 迁移到 Kubernetes 后,就可以利用 Kubernetes 原生的 HPA(Horizontal Pod Autoscale)资源对象,对 StarRocks 的 CN pod 进行动态伸缩管理,使 CN pod 可以根据资源指标实现流量变化的自适应,自动弹性地扩充新节点或者销毁不需要的节点。
在 HPA 资源对象中,我们对 CPU、Memory 指标进行了监控,当指标发生变化时,Controller 会每 15s 检查一次指标是否发生了变化。一旦触发了伸缩条件,Controller 会向 Kuberneters 发送请求,修改 CN pod 的数量。为了避免因抖动产生过于频繁的伸缩,我们在 HPA 上做了限制,每 5 分钟,Controller 只能发送一次伸缩请求。
在我们从 BE 节点将计算操作独立抽出成为 CN 节点后,可以通过 Kubernetes 的 HPA 功能完成 CN 节点的弹性扩缩容。同时,针对 BE 的存储功能,我们也与 StarRocks 社区一起规划设计了冷热数据分离存储的功能。为了更好存储一年甚至几年的冷数据,我们决定将 BE 节点中的冷数据下沉到 HDFS 或 COS 等更为廉价的存储。一方面期望大幅降低成本,另一方面,面向业务开发,期望湖仓技术在接下来演进中能够更好融合。
基于前述架构,BE Cluster 保存业务的热数据(可以根据时间,如保存近 2 个月的;也可以根据 BE 本地容量占比),非热数据则保存到底层廉价的 COS 或者 HDFS 中;在实际业务中,在如下两个典型场景,我们达成了不同的资源使用及负载隔离的目的:
高频访问热数据的 BI 分析场景,默认走 BE Cluster 提供秒级高效的查询分析性能;
用户自定义 SQL 的探索分析场景,会访问更长周期历史冷数据,分析平台可以通过 CN Operator 拉起一个 CN Cluster,构建起该场景对应的分析集群,优先访问底层下沉数据。
同时,CN Cluster 集群容量,可根据分析 workload 的负载,自助一键式伸缩;或通过配置集群自动扩缩容策略,让 CN Cluster 进行自动伸缩;当探索分析场景结束后,亦可释放此次的 CN Cluster 资源,达到计算资源“按需使用”高性价比方式。
当前选择了基于 Iceberg+(HDFS/COS) 的方案。以分区下沉方案为例,大概可分为四个步骤:
在 BE 上支持导出 ORC 格式文件,生成的 ORC 格式文件通过 Broker 上传到 COS/HDFS 中
提取生成的 ORC 文件统计信息,通过 Iceberg API 添加一个分区
添加定时任务生成需要下沉的分区信息。当数据下沉之后,即可通过 StarRocks 进行查询分析。在上述架构中,我们初期在 Iceberg 外表功能测试中遇到了若干问题,对应的优化项均已提交开源社区,后文将有所罗列。
当执行查询语句时,我们通过分区元数据信息,自动判断数据存在本地还是外部存储生成不同的 ScanNode。如果需要同时获取两边的数据,则通过一个 Union 算子,将两个 ScanNode 的结果进行合并,获得全量数据。
在数据下沉及查询功能完成之后,性能压测中,我们发现存算分离相比存算一体,在业务典型业务 SQL 场景,性能差距在 50-100 倍之间。通过分析 Profile,在以下方面做了优化:
FE 生成执行计划的时候,会多次调用 Iceberg 的 planFiles 接口来获取计算 CBO 的统计数据和 HDFS NODE 的 Range location。而这两个操作需要获取 Iceberg 的元数据,需要和远端存储交互,这也是 FE 耗时最多的地方。对此,我们也参考 Iceberg 社区,尽量减少对依赖包改动的原则下,在 StarRocks 中添加 Iceberg FILEIO cache 机制,将 Iceberg metadata.josn, manifest, manifest-list 缓存下来,加速 FE 的生成执行计划。
Iceberg 表频繁刷新,也会增加 100ms 左右的耗时,我们保证每条 SQL 只刷新一次,跳过其他情况下的表刷新。
调试本地和外部存储同时查询的语句时,我们发现这种查询比单独查询两边的数据都要慢,大概能有 5-8 倍的性能差异。通过定位,我们发现是生成的 Union 执行计划不优导致的。具体来说,如果原来的执行计划只有一个 ScanNode,并且上面包含 Aggregate(或者 Project)算子的时候,这个算子会被下推到 ScanNode 所在的 Fragment。而我们生成 Union 的时候,将 ScanNode 替换成了 Union,这个时候生成物理计划的时候会插入一个 ExchangeNode,这就会导致每次执行都会做一次全量数据传输。为了解决这个问题,我们优化了执行计划,将 Aggregate 的第一阶段聚合下推到了 Union 下面,从而减少了大量 Exchange 传输数据量,达到了直接查询外表相当的性能表现。
经过上述优化,截止目前,我们基于业务真实的 1TB,260 亿行单表数据量,CN 和 BE 均投入为 12 个节点,分别对应存算分离及存算一体两条链路 ,采用典型 SQL 进行对比测试。性能差距从 50-100 倍,缩减到了目前的 5 倍左右。在整体方案具备按不同业务场景 ,不同 SQL 负载,可以互相隔离的前提下,达成了性能和成本平衡的初步目标。

存算分离是 StarRocks 迈向云原生的第一步,我们已经初步完成了:
独立无状态的 Compute Node 支持灵活的计算扩展。
存储层可以在对象存储上进行灵活的资源扩展。
Compute Node 支持在热存储(BE)和 冷存储(对象存储)上执行查询。
通过数据下沉机制,可以实现数据在冷热存储的转储。
长期来看,我们会按照社区的路线图一起继续完善云原生架构:
支持多集群模式,能够让独立的集群完成独立的特定的任务,比如晚上有大规模 ETL 作业时可以弹性出一个专用的 ETL 集群。
完善 Primary Key 的存算分离机制,解决秒级实时更新场景下的存算分离难题。
持续优化缓存机制,让存算分离架构的查询性能可以媲美存算一体架构。在 Compute Node 上增加 Local cache,降低远程数据访问的延迟。
BE 会逐步演进成一个多集群公用的 Global cache,为 Serverless 架构提供完整算子下推能力的通用查询加速层。
实现 FE 存算分离,为更大规模的云原生数仓设计元数据管理架构。
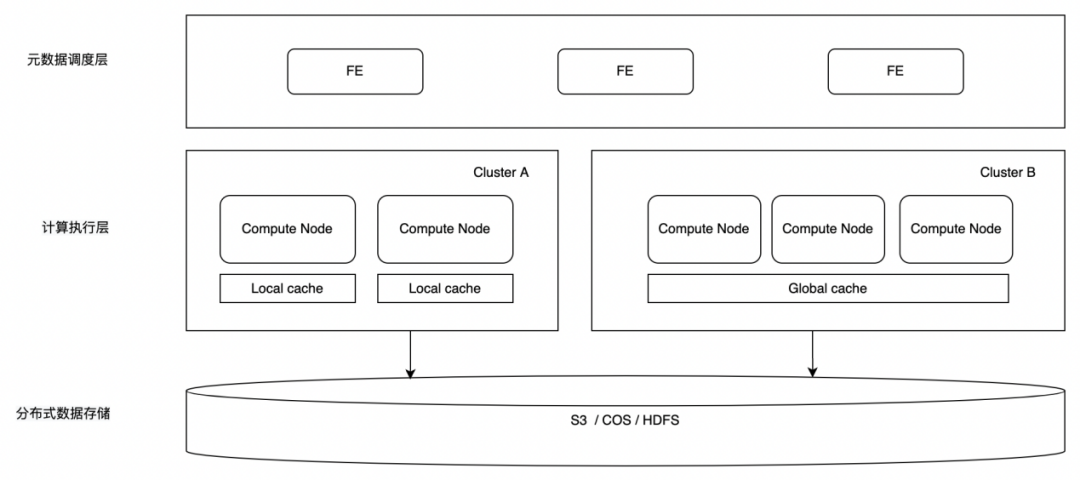
从上图可以看到,StarRocks 未来会支持两种计算分离模式,左边的模式类似 Snowflake 的架构,计算层上有一个本地的 Local cache,可以保证数据缓存命中时的高性能。但是,在集群做弹性的时候会导致 cache 数据的重新分布和远程加载,所以在扩容过程中会有一定的性能损失。此种模式比较适合对弹性要求不高,比较适合追求极致性能的业务场景。
在右侧的架构中,我们在现在的计算和存储层之间增加了一个公共的全局数据缓存,可以给上层所有 Compute Node 提供包括算子下推内的计算能力。这样就可以实现秒级的弹性以及弹性过程中集群的性能稳定,同时可以针对每一个请求即时分配计算资源,计算完成以后马上释放,实现真正的 Serverless 级别的弹性伸缩。比较适合在满足性能要求下追求弹性的业务场景。
通过支持两种计算分离模式,可以非常好的利用 StarRocks 来统一满足各类业务要求,实现“极速统一”的数据分析新范式。
天穹是协同腾讯内各 BG 大数据能力而生的 Oteam,作为腾讯大数据领域的代名词,旨在拉通大数据各个技术组件,打造一个具有统一技术栈的公司级大数据平台体系。从底层数据接入、数据存储、资源管理、计算引擎、作业调度,到上层数据治理及数据应用等多个环节,支持腾讯内部近 EB 级数据的存储和计算,为业务提供海量、高效、稳定的大数据平台支撑和决策支持。
我们选择 StarRocks 作为腾讯游戏公共数据平台 OLAP 分析引擎的同时,也深刻感受到了 StarRocks 社区开放、包容、共创的开源文化。在腾讯游戏业务落地的过程中,我们还参与了 UDF 函数开发、Iceberg 外表查询优化以及 StarRocks CN Operator 等功能模块的共同开发:
-
漏斗函数
[#4985] Add window_funnel aggregate function
https://github.com/StarRocks/starrocks/pull/4985
-
外表优化
[#6846] Generate statistics for empty iceberg table
https://github.com/StarRocks/starrocks/pull/6846
[#6237] Support FileIO cache for iceberg table
https://github.com/StarRocks/starrocks/pull/6237
[#5680] Reduce call to get iceberg TableStatistics
https://github.com/StarRocks/starrocks/pull/5680
[#5640] Reduce Iceberg metadata refresh operation
https://github.com/StarRocks/starrocks/pull/5640
-
CN 节点和 FE 调度
[#5441] Add Compute node to support serveless
https://github.com/StarRocks/starrocks/pull/5441
[#6394] Add compute node in FE
https://github.com/StarRocks/starrocks/pull/6394
-
StarRocks CN Operator
https://github.com/StarRocks/starrocks-kubernetes-operator
随着更多的业务落地 StarRocks 以及更深入的使用,我们会持续在执行计划优化、物化视图、CN 节点分组逻辑等功能以及云原生数仓方向上深入建设,与大家一起在社区共创的路上行稳致远。
没有内卷、996 和“老板”,乐视过上神仙日子?WPS 重申“删除用户本地文件”一事;小米被指违反 GPL 协议 | Q 资讯

点个在看少个 bug 👇
