清华大学计算机全球排名第一! 领先于麻省理工和斯坦福等名校!
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
根据US News的最新大学工科最新排名显示,清华大学排名全球第一,领先于麻省理工、斯坦福和哈佛等学校。另外,中国的华中科技大学,浙江大学也进入全球前十。
另一件让华人感到骄傲的事:ICCV2017计算机视觉的顶级大会的最佳论文和最佳学生论文公布,被本科毕业于清华大学的何凯明大神包揽,再次荣登王者宝座!
1.ICCV 2017的最佳论文奖(Marr prize)颁发给了Facebook AI实验室(FAIR)何恺明等人的论文《Mask R-CNN》。

摘要:
我们在 COCO 竞赛的3个任务上都得到最佳结果,包括实例分割,边界框对象检测,以及人物关键点检测。没有使用其他技巧,Mask R-CNN 在每个任务上都优于现有的单一模型,包括优于 COCO 2016 竞赛的获胜模型。我们希望这个简单而有效的方法将成为一个可靠的基准,有助于未来的实例层面识别的研究。
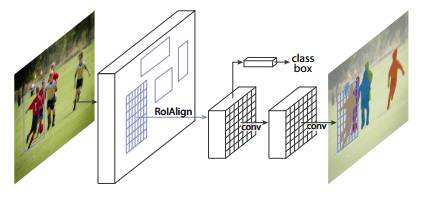
图1:用于实例分割的 Mask R-CNN 框架
Mask R-CNN 在概念上十分简单:Faster R-CNN 对每个候选物体有两个输出,即一个类标签和一个边界框偏移值。作者在 Faster R-CNN 上添加了第三个分支,即输出物体掩膜(object mask)。因此,Mask R-CNN 是一种自然而且直观的想法。但添加的 mask 输出与类输出和边界框输出不同,需要提取对象的更精细的空间布局。Mask R-CNN 的关键要素包括 pixel-to-pixel 对齐,这是 Fast/Faster R-CNN 主要缺失的一块。
2、ICCV 2017最佳学生论文颁发给了FAIR的《密集物体检测Focal Loss》何恺明也有参与

摘要:目前,最准确的目标检测器(object detector)是基于经由 R-CNN 推广的 two-stage 方法,在这种方法中,分类器被应用到一组稀疏的候选对象位置。相比之下,应用于规则密集的可能对象位置采样时,one-stage detector 有潜力更快、更简单,但到目前为止,one-stage detector 的准确度落后于 two-stage detector。在本文中,我们探讨了出现这种情况的原因。
我们发现,在训练 dense detector 的过程中遇到的极端 foreground-background 类别失衡是造成这种情况的最主要原因。我们提出通过改变标准交叉熵损失来解决这种类别失衡(class imbalance)问题,从而降低分配给分类清晰的样本的损失的权重。我们提出一种新的损失函数:Focal Loss,将训练集中在一组稀疏的困难样本(hard example),从而避免大量简单负样本在训练的过程中淹没检测器。为了评估该损失的有效性,我们设计并训练了一个简单的密集目标检测器 RetinaNet。我们的研究结果显示,在使用 Focal Loss 的训练时,RetinaNet 能够达到 one-stage detector 的检测速度,同时在准确度上超过了当前所有 state-of-the-art 的 two-stage detector。

系统学习,进入全球人工智能学院
周志华点评AlphaGo Zero:这6大特点非常值得注意!



