如何实现Spark on Kubernetes?

阿里妹导读:大数据时代,以Oracle为代表的数据库中间件已经逐渐无法适应企业数字化转型的需求,Spark将会是比较好的大数据批处理引擎。而随着Kubernetes越来越火,很多数字化企业已经把在线业务搬到了Kubernetes之上,并希望在此之上建设一套统一的、完整的大数据基础架构。那么Spark on Kubernetes面临哪些挑战?又该如何解决?
文末福利:免费下载《阿里云云原生数据湖体系全解读》电子书。
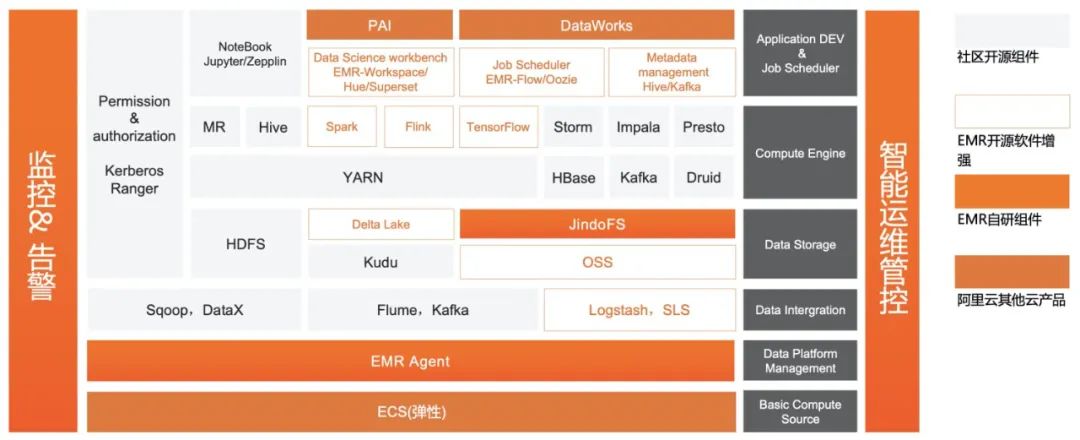
ECS物理资源层,也就是Iaas层。
数据接入层,例如实时的Kafka,离线的Sqoop。
存储层,包括HDFS和OSS,以及EMR自研的缓存加速JindoFS。
计算引擎层,包括熟知的Spark,Presto、Flink等这些计算引擎。
数据应用层,如阿里自研的Dataworks、PAI以及开源的Zeppelin,Jupyter。
是否能够做到更好用的弹性,也就是客户可以完全按照自己业务实际的峰值和低谷进行弹性扩容和缩容,保证速度足够快,资源足够充足。
不考虑现有状况,看未来几年的发展方向,是否还需要支持所有的计算引擎和存储引擎。这个问题也非常实际,一方面是客户是否有能力维护这么多的引擎,另一方面是某些场景下是否用一种通用的引擎即可解决所有问题。举个例子来说,Hive和Mapreduce,诚然现有的一些客户还在用Hive on Mapreduce,而且规模也确实不小,但是未来Spark会是一个很好的替代品。
存储与计算分离架构,这是公认的未来大方向,存算分离提供了独立的扩展性,客户可以做到数据入湖,计算引擎按需扩容,这样的解耦方式会得到更高的性价比。
希望能够基于Kubernetes来包容在线服务、大数据、AI等基础架构,做到运维体系统一化。
存算分离架构,这个是大数据引擎可以在Kubernetes部署的前提,未来的趋势也都在向这个方向走。
通过Kubernetes的天生隔离特性,更好的实现离线与在线混部,达到降本增效目的。
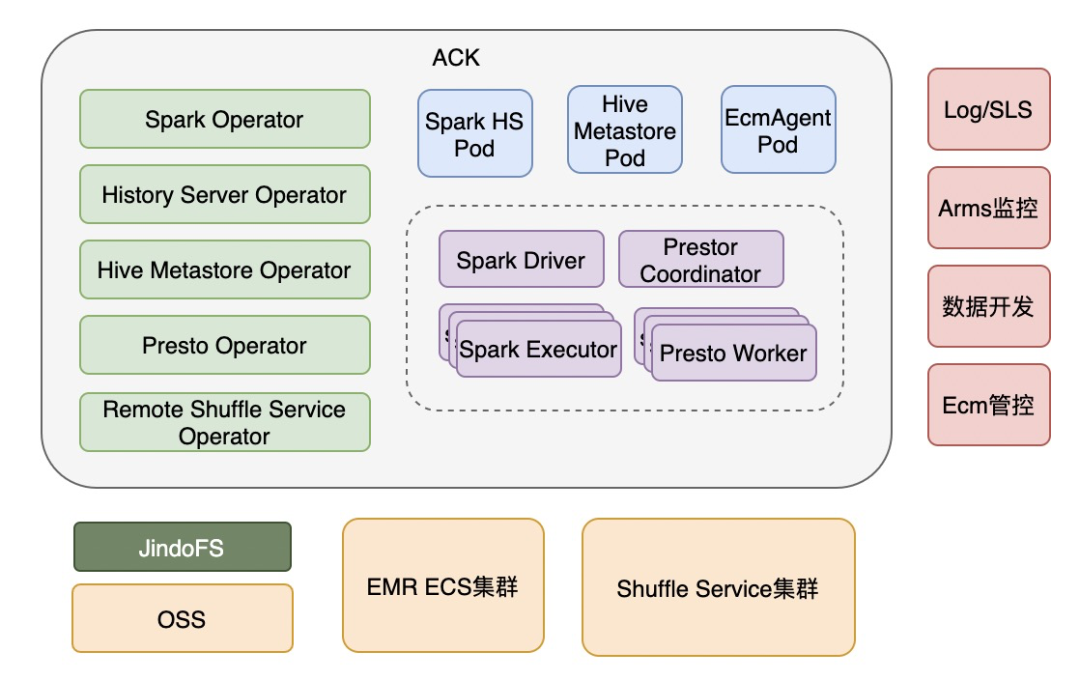
引入了JindoFS作为OSS缓存加速层,做计算与存储分离的架构。
打通了现有EMR集群的HDFS,方便客户利用已有的EMR集群数据。
引入Shuffle Service来做Shuffle 数据的解耦,这也是EMR容器化区别于开源方案的比较大的亮点,之后会重点讲到。
我个人认为最重要的,就是Shuffle的流程,按照目前的Shuffle方式,我们是没办法打开动态资源特性的。而且还需要挂载云盘,云盘面临着Shuffle数据量的问题,挂的比较大会很浪费,挂的比较小又支持不了Shuffle Heavy的任务。
调度和队列管理问题,调度性能的衡量指标是,要确保当大量作业同时启动时,不应该有性能瓶颈。作业队列这一概念对于大数据领域的同学应该非常熟悉,他提供了一种管理资源的视图,有助于我们在队列之间控制资源和共享资源。
读写数据湖相比较HDFS,在大量的Rename,List等场景下性能会有所下降,同时OSS带宽也是一个不可避免的问题。
如果用是Docker的文件系统,问题是显而易见的,因为性能慢不说,容量也是极其有限,对于Shuffle过程是十分不友好的。
如果用Hostpath,熟悉Spark的同学应该知道,是不能够启动动态资源特性的,这个对于Spark资源是一个很大的浪费,而且如果考虑到后续迁移到Serverless K8s,那么从架构上本身就是不支持Hostpath的。
如果是Executor挂云盘的PV,同样道理,也是不支持动态资源的,而且需要提前知道每个Executor的Shuffle数据量,挂的大比较浪费空间,挂的小Shuffle数据又不一定能够容纳下。
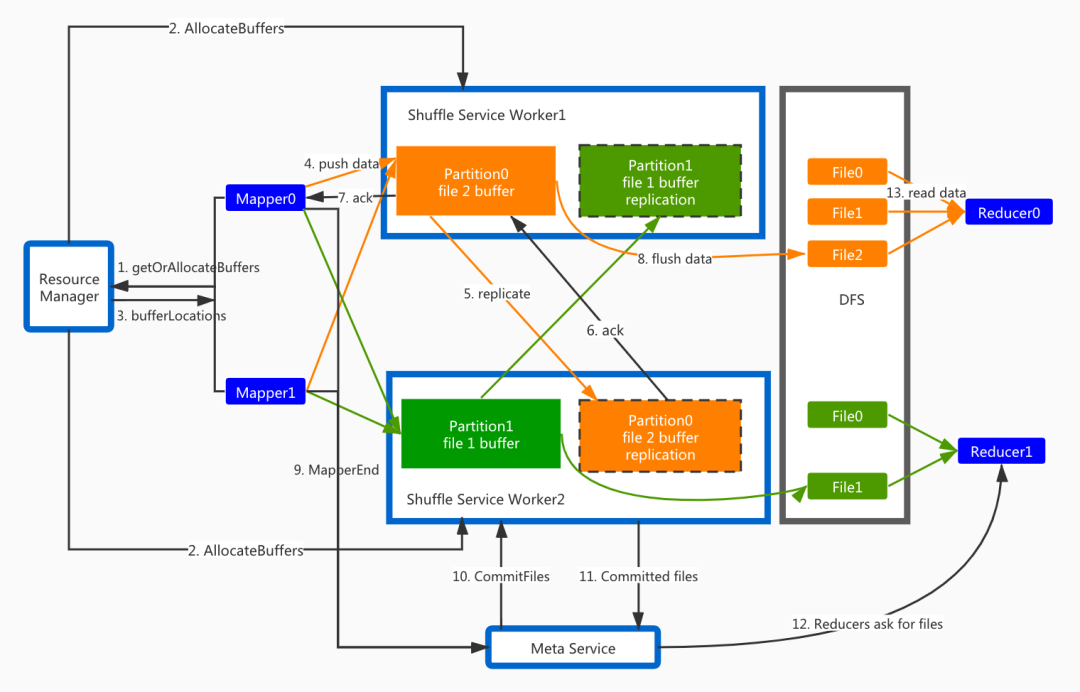
Shuffle数据通过网络写出,中间数据计算与存储分离架构
DFS 2副本,消除Fetch Failed引起的重算,Shuffle Heavy作业更加稳定
Reduce阶段顺序读磁盘,避免现有版本的随机IO,大幅提升性能
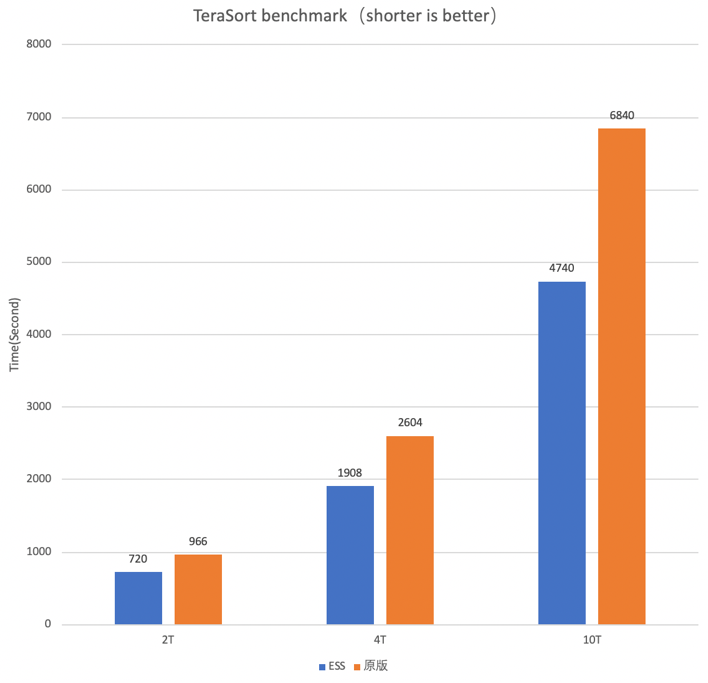
我们在这里展示一下关于性能的成绩,图4和图5是Terasort Benchmark。之所以选取Terasrot这种workload来测试,是因为它只有3个stage,而且是一个大Shuffle的任务,大家可以非常有体感的看出关于Shuffle性能的变化。
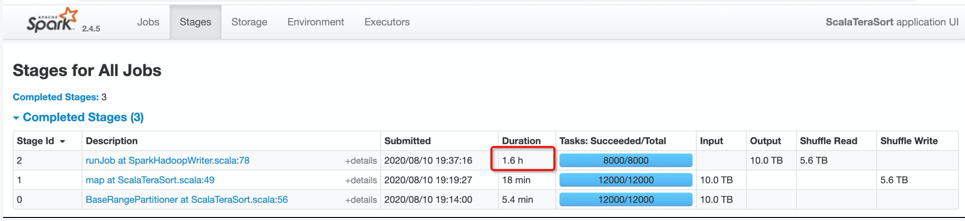
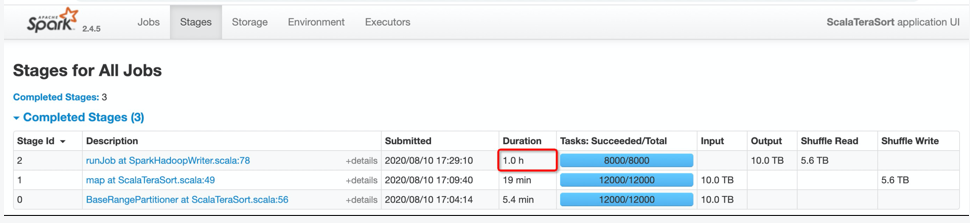
图4中,蓝色部分是Shuffle Service版本的运行时间,橙色部分是原版Shuffle的运行时间。我们测试了2T,4T,10T的数据,可以观察到随着数据量越来越大,Shuffle Service优势就越来越明显。图5红框部分说明了作业的性能提升主要体现在Reduce阶段,可见10T的Reduce Read从1.6小时下降到了1小时。原因前边已经解释的很清楚了,熟悉Spark shuffle机制的同学知道,原版的sort shuffle是M*N次的随机IO,在这个例子中,M是12000,N是8000,而Remote Shuffle就只有N次顺序IO,这个例子中是8000次,所以这是提升性能的根本所在。
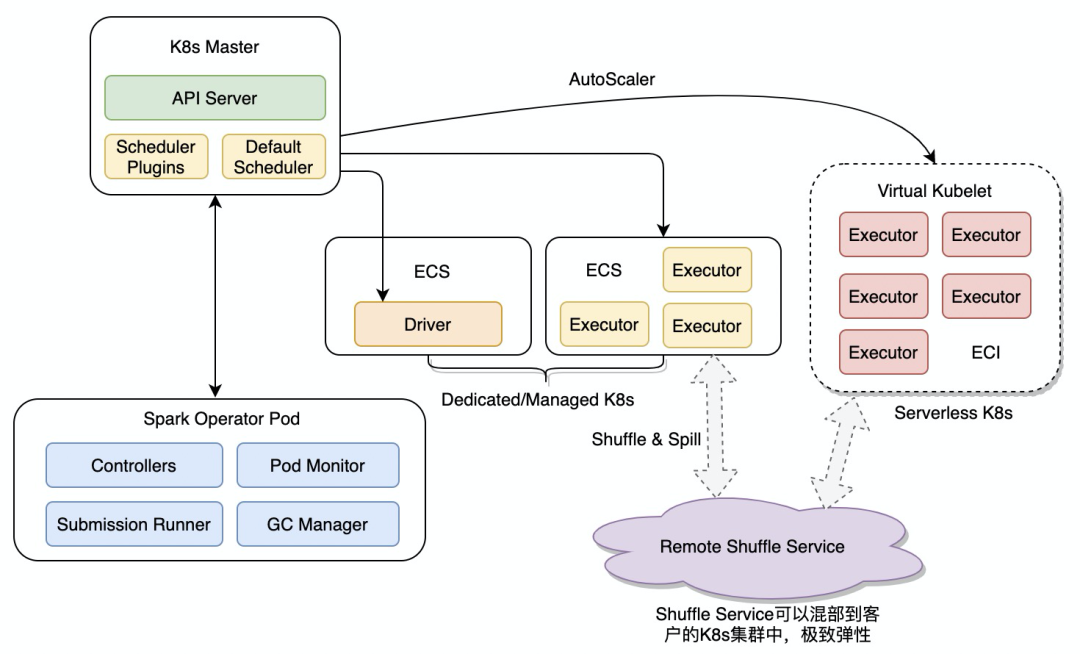
可以将Kubernetes计算资源分为固定集群和Serverless集群的混合架构,固定集群主要是一些包年包月、资源使用率很高的集群,Serverless是做到按需弹性。
可以通过调度算法,灵活的把一些SLA不高的任务调度到Spot实例上,就是支持抢占式ECI容器,这样可以进一步降低成本。
由于提供了Remote Shuffle Service集群,充分让Spark在架构上解耦本地盘,只要Executor空闲就可以销毁。配合上OSS提供的存算分离,必定是后续的主流方向。
对于调度能力,这方面需要特别的增强,做到能够让客户感受不到性能瓶颈,短时间内调度起来大量的作业。同时对于作业队列管理方面,希望做到更强的资源控制和资源共享。

阿里云首次发布云原生数据湖体系,基于对象存储OSS、数据湖构建Data Lake Formation和E-MapReduce的强强组合,提供存储与计算分离架构下,涵盖湖存储、湖加速、湖管理和湖计算的企业级数据湖解决方案。
点击“阅读原文”,立即下载了解吧!