【综述】智能医疗综述,48页论文详述医学AI最新进展
【导读】机器学习和深度学习为我们提供了一个全新的方法去探索未知领域。本文为大家带来了一份最新的智能医疗综述,这篇论文详细论述了深度学习在医学影像、电子健康记录、基因学、感知和在线健康交流方面目前的进展、挑战以及未来研究方向。
原文链接:
https://arxiv.org/abs/1909.00384
介绍:
机器学习和深度学习已成为一种新趋势,开启了一个全新的研究时代。事实上,深度学习也已经被运用到了各个领域,在健康卫生学领域对于人工智能的需求正快速增加,并且在医疗健康领域人工智能应用的潜在好处也已经被证明。
深度学习在卫生信息学领域有许多优点,它可以在没有先验的情况下进行训练,这有利于克服缺乏标记数据而导致的训练问题,并可以缓解临床医生的负担。例如,将深度学习用于医学图像,可以处理数据复杂性,检测重叠的目标点和3维或4维医学图像。
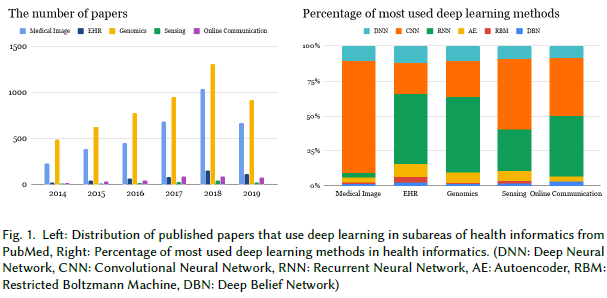
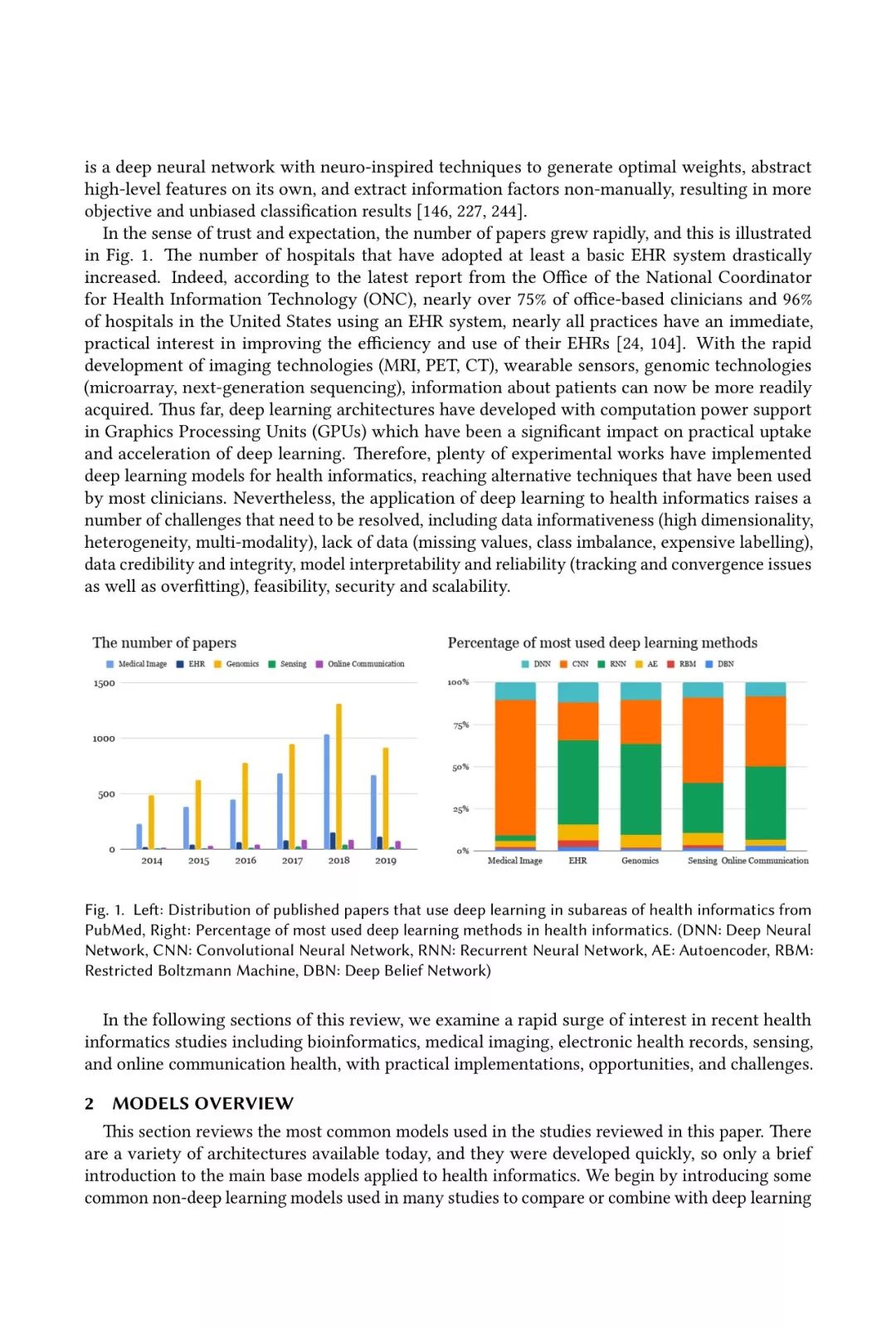
出于对深度学习在医疗健康领域的信心和期望,最近这一领域的论文数量增加的非常迅速,如下图所示。至少采用了一套基础的EHR系统的医院的数量也在井喷式的增加。然而,将深度学习应用于卫生信息学仍旧有一些挑战急待解决(如数据的信息性,缺乏标记数据,数据的可信度和完整性,模型的可解释性和可靠性等)。
模型概述:
支持向量机
SVM是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面。在训练阶段,当数据本身是线性可分的时候,SVM会寻找一个距离两边支持向量最大距离的超平面。如果数据不可线性划分,SVM会允许支持向量机在一些样本上出错也就是引入了所谓的软间隔和核方法。
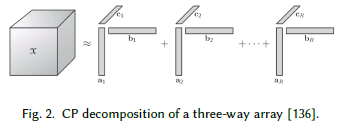
矩阵/张量分解
张量是一个多维的数组.n阶张量是n个向量空间张量积的一个元素,其中每个向量空间都有自己的坐标系。一阶t张量是一个向量,二阶张量是一个矩阵。所以,通常二阶张量分解被称作矩阵分解,三阶或者更高阶的张量分解被称作张量分解。其中一种张量分解是CANDECOMP/PARAFAC (CP)分解,一个三阶张量被分解成一组分量秩为1的张量,如图2所示。
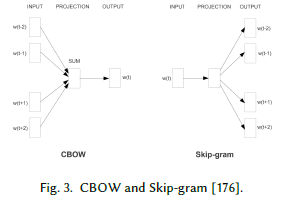
词向量
词向量是一种把词映射成带有真实数字的向量的一种技巧(word2vec就是一种典型的生成词向量的模型)。之所以考虑它,是因为它允许模型具有更多信息和更简洁的特性。从概念上讲,词语具有相似性和共现性,词首先被映射到一个具有多个维度的二元空间,然后再被映射到一个连续的,低维度的向量空间。word2vec引入了两种词分布表示:CBOW和skip-gram.CBOW是给定上下文预测中心词,skip-gram是给出中心词来预测上下文,如图3所示:
4.多层感知机
多层感知器(MLP)是一个前馈神经网络,每一 层都 有感知器(神经元)。当一个模型最少有三层,被 称之为浅层神经网络,当网络的层数大于三层时,该 网络就被称之为深度神经网络(DNN)。在一个n层 网络中,第一层称之为输入层,最后一层为输出层,剩余的n-2层为隐藏层。与SVM相反,多层感知机不需要先验特征选择,它本身结合了一些特性,可以靠自身去优化。
5.卷积神经网络
卷积神经网络(CNN)是一种受动物视觉皮层生物处理启发的算法。和之前全连接的神经网络不一样,CNN算法用共享权重的二维卷积层最终实现了动物视觉皮层的工作机制,能够识别空间信息和用池化层过滤得到更加重要的知识,只传递多关注的特征。如图4所示:
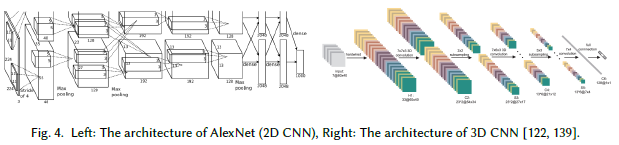
6.卷积神经网络
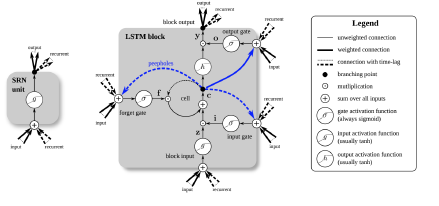
循环神经网络(RNN)是一类专门针对序列数据的神经网络。RNN基于当前的输入x,和前面的h(t-1)隐藏状态顺序更新一个隐藏状态,同样的,h(t-1)更新是基于x(t-1)和h(t-1),每一个输出的值先前的计算。尽管RNN在时序数据上展现出了优异的性能,但是RNN在梯度消失和梯度爆炸方面有局限性。为此,RNN的各种变体出现,以LSTM和GRU为代表,通过捕获长期依赖来解决这些问题。
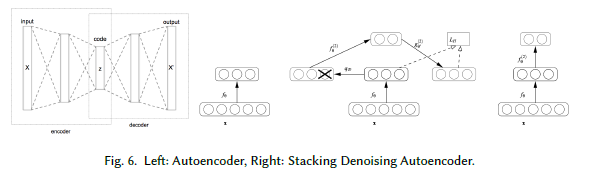
7.自动编码器
当神经网络非常深的时候,通过梯度下降更新的权重值将会接近0,这种现象被称之为梯度消失。针对这一问题提出了自编码器(AE)。自编码器是一种无监督学习方法,它有一个编码器和一个解码器组成(如图6)。AE的目标是找到能够最小化输入数据和重构输入数据之间的误差。
8.注意力学习
可以通过将查询和一组键值对映射到输出来描述注意力机制。将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。注意力机制包括点积注意力和多头部注意力。如图7所示:
9.迁移学习
在迁移学习中,首先训练一个基于基本数据集的基本网络,然后使用学习到的特征,目标网络也在目标数据集上进行训练。这一过程通常是有意义的,当目标数据集小到需要训练且研究人员希望避免过拟合时,这一过程会有显著的改进。通常,在训练一个基本网络之后,复制前n层并将其用于目标网络,然后随机初始化目标网络的其余层。迁移的层可以保留为冻结或微调,这意味着要么锁定层,以便在训练目标网络期间没有变化,要么反向传播目标网络的备份和重新初始化层。
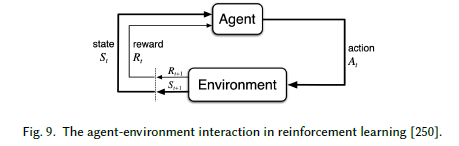
10.强化学习
强化学习作为一种代理学习策略被引入,是为了在环境中采取措施来最大化累计奖励。在每一个时间戳t,代理从环境中观察状态st,并在状态s中采取行动.环境和代理在当前状态st的基础上转移到一个新的状态s(t+1)并且选择行动,它向代理提供一个标量奖励r(t+1)作为反馈。如图9所示:
深度学习方法的应用:
1.医疗图像
深度学习在医疗数据集上的第一个应用是医疗图像包括:MRI,CT,PET,X-ray,Microscopy,US,MG等。
2.电子健康记录
电子病历和电子健康记录经常被交替使用。对医生来说电子病历就是数字版本的图纸,关注治疗历史和电子病历的目的是与其他卫生保健提供者(如实验室和专家)共享患者的总体健康信息。
3.基因学
人类基因组数据包含了大量的数据。一般来说,识别基因本身探索功能和信息结构,调查环境因素如何影响表型是现在研究的目的之一。
4.在线健康交流
生物传感器是可穿戴的、可植入的环境设备,可以将生物反应转化为光电信号,使持续监测健康和幸福成为可能。由于EHR经常缺失病人的自我报告和在临床环境之外的人类活动和生命体征,通过密切分析患者的病情,持续跟踪这些活动和体征有望改善治疗结果。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“DHSP2019” 就可以获取综述下载链接~
内容预览









更多精彩内容,请下载观看