作者 | beyondma
转载自CSDN网站
近日DeepMind发布VQ-VAE-2算法,也就是之前VQ-VAE算法2代,这个算法从感观效果上来看比生成对抗神经网络(GAN)的来得更加真实,堪称AI换脸界的大杀器,如果我不说,相信读者也很难想象到上面几幅人脸图像都是AI自动生成出来的。
不过如此重要的论文,笔者还没看到专业性很强的解读,那么笔者就将VQ-VAE-2算法分为VQ,VAE,VQVAE2三部分来介绍原理,权当抛砖引玉。
什么是VQ
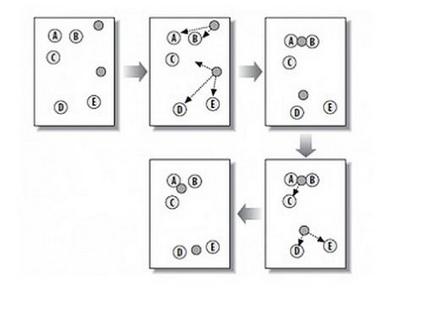
VQ是vector quantisationk(一般译作矢量量化)的缩写,他的主要思想是通过k-means算法进行聚类,将相近的点全部近似点簇的重心,从而在不损失太多信息的情况下对输入进行压缩。
k-means聚类算法:我在之前博客《终于把软微BING搜索-SPTAG算法的原理搞清了(https://blog.csdn.net/BEYONDMA/article/details/90578111)
也曾经介绍过k-means算法。算法先随机指定选取K个点做为初始聚集的簇心,分别计算每个样本点到 K个簇核心的余弦距离,找到距离最近的核心点,将它归属到对应的簇,所有点都归属到簇之后, M个点就分为了 K个簇。之后重新计算每个簇的重心,将其定为新的“核心”,重复上述步骤直到新核心不再改变为止或者改变距离达到一定值后中止。那么最终的K个簇就是最终的聚类结果。
k-means算法试图最小化失真,其定义为每个观测向量与其主质心之间距离的平方之和。通过迭代地将观测结果重新分类为星系团,并重新计算中心体,直到得到一个中心体稳定的构型,从而达到最小值。
那么VQ实际就是先把输入的图像进行-means聚类,完成后只保留最终留下的K个簇质心,簇上的其它点全部近似化为质心来进行存储,用这样的方式来进行压缩。
什么是VAE
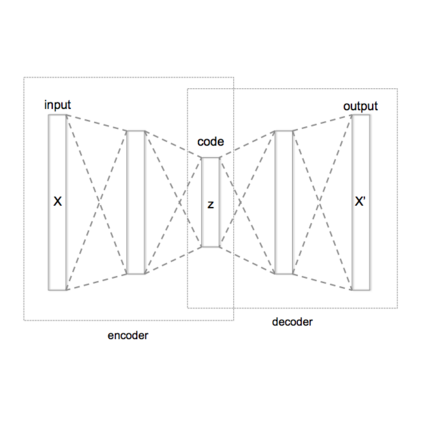
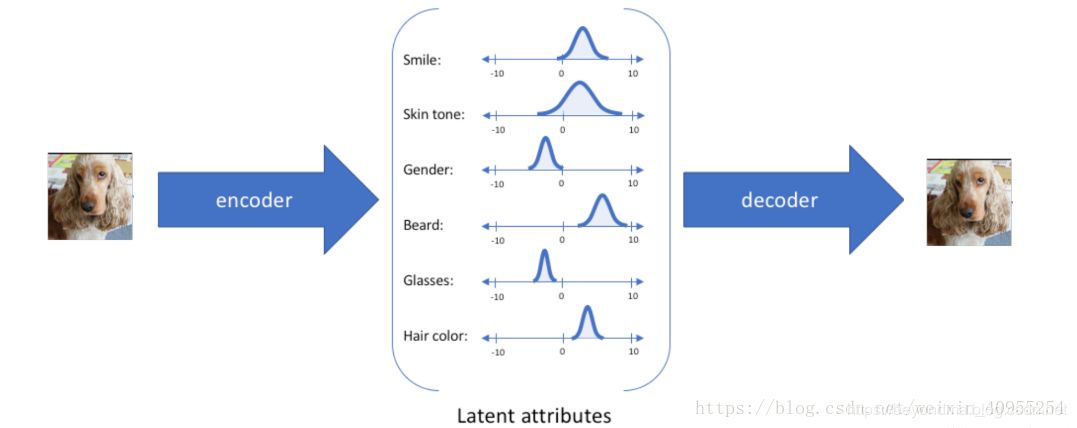
VAE是variational auto encoding(一般译作变分自动编码),不过笔者感觉译为隐变更自动编码可能更贴切。VAE的主要思想是他认为图像、声音等信息是由多个隐变量(latent arrtibute),比如对于人的面部图像来说就由笑容,肤色、发色、发型等变量决定,那么VAE网络就先把图像中的笑容,肤色、发色、发型等变量识别出来,然后将这些变量传递给解码器生成图像。具体工作原理图如下:
VQ-VAE1代算法整体的工作方式
简单来讲VQ-VAE1代算法,在Encoder层计算latent arrtibute(隐向量)的向量族z,然后传递给隐层,在隐层按照刚刚所述的VQ算法进行压缩,然后输出给Decoder进行生成,其具体原理见下图。
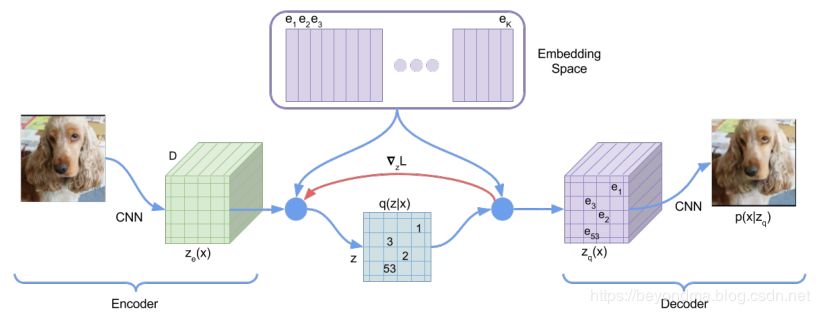
如果要进行换脸,那么只要将人脸A的Encoder进行编码计算latent arrtibute(隐向量),然后输出给FaceB的Decoder进行生成即可完成。
VQ-VAE2代算法的更新
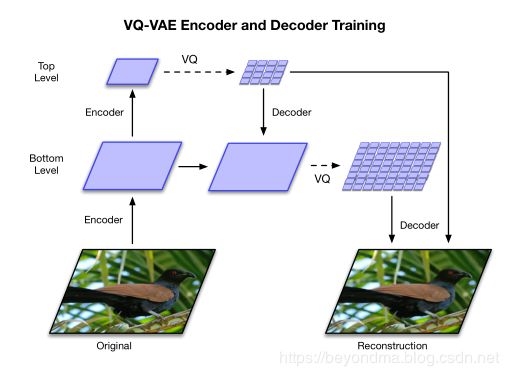
VQ-VAE2代其实总体和1代差别不大,主要将latent arrtibute(隐向量)分为top和bottom两层,其中top层记录整体细节主要是明亮度、色调等信息,而bottom层主要记录细节信息,从实际效果上看甚至包括了发丝、瞳孔等超级细微的层面。具体原理图如下:
VQ-VAE-2将AI换脸的技术提升到了真假难辩的高度
我在之前的博客《终于把AI换脸的原理搞清了》(https://blog.csdn.net/BEYONDMA/article/details/88365203)曾经介绍过deepfakes等项目的原理,不过之前那些换脸算法对于细节的把握程度远远达不到VQ-VAE-2的程度,从DeepMind的论文中可以看到,其生成效果之好、分辨率之高已经到达了刷新了笔者的认知极限。所以笔者最后也再次呼吁,不要将AI换脸技术用在歪路上。
附件VAVAE2论文原址:
https://arxiv.org/pdf/1906.00446.pdf