支持向量机(SVM)硬核入门-基础篇
1 引子
关于SVM,流传着一个关于天使与魔鬼的故事。
传说魔鬼和天使玩了一个游戏,魔鬼在桌上放了两种颜色的球(图1.1)。魔鬼让天使用一根木棍将它们分开。这对天使来说,似乎太容易了。天使不假思索地一摆,便完成了任务(图1.2)。

图1.1 分球问题1

图1.2 分球问题1的解
魔鬼又加入了更多的球。随着球的增多,似乎有的球不能再被原来的木棍正确分开(图1.3)。

图1.3 分球问题2及其解
魔鬼最后给了天使一个新的挑战(图1.4)。按照这种球的摆法,世界上貌似没有一根木棒可以将它们完美分开。但天使一拍桌子,便让这些球飞到了空中,然后抓起一张纸片,插在了两类球的中间(图1.5)。从魔鬼的角度看这些球,则像是被一条曲线完美的切开了(图1.6)。

图1.4 分球问题3
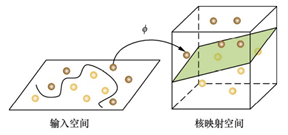
1.5 高维空间中分球问题3的解

图1.6 魔鬼视角下分球问题3的解
本小节引用自《百面机器学习》诸葛越)
2 概述
和第1节中的分球游戏类似,支持向量机SVM就是一个二分类模型,它通过引入一个超平面,将样本点分隔成两簇,以达到预测样本类别的目的。SVM算法的主要过程就是求出这个分隔超平面。其中:
分球问题1对应:线性可分支持向量机。这是最简单的支持向量机,所有样本都能够完美地被线性分隔。
分球问题2对应:基于软间隔的线性支持向量机。这种支持向量机能够容忍一定的误差和异常点。
分球问题3对应:基于核函数的非线性支持向量机。SVM将低维的样本特征空间映射到高维,再利用高维的超平面进行分隔。
在基础篇中,我将只介绍线性可分支持向量机,因为基础篇的目的是删烦就简,让读者了解到一个尽可能简单的支持向量机SVM。
剩下的两种支持向量机及一些高级的知识点,将会在进阶篇中进行描述。
3 基本概念
3.1 超平面
我们将由SVM学习得到的分隔超平面记为:
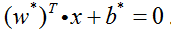
其中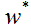
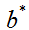
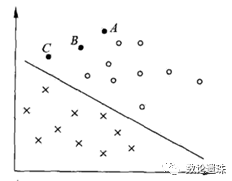
图3.1 样本点和超平面
3.2 决策函数
学习到超平面后,即可进行二分类问题的预测,相应的决策函数为:
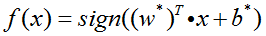
其中x为样本点的特征向量,f(x)输出的值为样本点的类别。
sign函数为符号函数:
当x>0时,sign(x)=1;
当x=0时,sign(x)=0;
当x<0,sign(x)=-1。
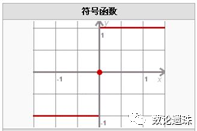
图3.2 Sign符号函数
3.3 间隔
间隔指的是样本点到超平面的垂直距离(最短距离)。
能够正确分隔样本点的超平面可能有无数个,为了找出其中最优的那个,我们需要通过间隔来评价超平面的分隔效果,并通过间隔数据来计算超平面的最优解,以达到最佳的分类预测效果。
如图3.3所示,线段AB的距离计算公式为(公式推导见本小节末):
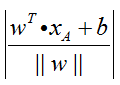
其中||w||为法向量w的L2范数(欧氏距离)。
在分类正确的情况下,不妨令:
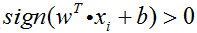
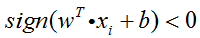
则此时:
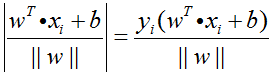
我们将其定义为样本点到超平面的间隔。
注:分类不正确的情况下,求得的间隔为负数,不影响计算的最终结果。
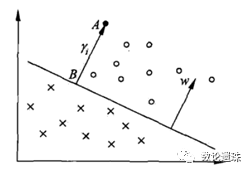
图3.3 间隔
在定义了样本点到超平面的间隔后,我们继续定义样本训练集到超平面的间隔:训练集中所有样本到超平面的间隔的最小值
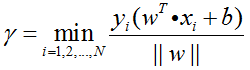
其中N为样本点数量。
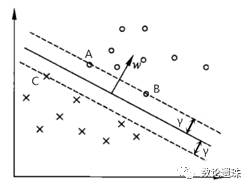
图3.4 间隔和支持向量
如图3.4所示,正例样本中距离超平面最近的点是点A和点B,它们距离超平面的距离为γ,负例样本中距离超平面最近的点是点C,它们距离超平面的距离也为γ。
支持向量机SVM算法的最终目的,就是求出一个超平面,使得训练集间隔γ最大,以达到最好的分类效果,即求得:
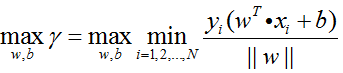
这也是后续最优化问题的目标函数。
附:简要推导下点到平面的距离公式:
记待求距离的点为x1,平面上任意一点为x0,平面为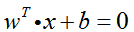
待求距离的点到平面上任意一点的线段向量为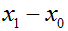
由于点到平面的距离为点到平面的垂线的距离,即点到平面上任意一点的向量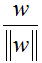
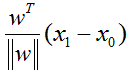
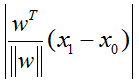
由于x0在平面上,故满足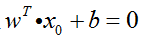
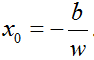
将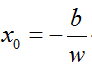
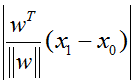
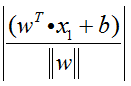
3.4 支持向量
最后解释支持向量机SVM算法名称的由来。
如图3.4,超平面仅由样本点A、B、C决定,和其它样本点无关。这些决定超平面位置的样本点,就被称为支持向量。
在线性可分支持向量机中,正例和负例至少各有1个支持向量,至多有无穷多个。
最为简单的情况是:正例1个支持向量,负例1个支持向量,超平面即为这两个支持向量的垂直平分线。如图3.5所示。
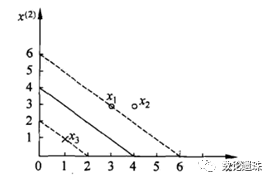
图3.5 由两个支持向量生成的间隔最大的超平面
4 最优化问题
4.1 原始问题
第一步:
如3.3节中提及的,SVM算法的目的是获得最高的分类准确率,等同于找到训练集间隔最大的最优超平面,等同于求下式的最优化问题:
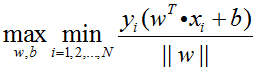
同时,考虑到所有的样本点都必须被正确分类,即要满足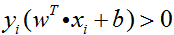
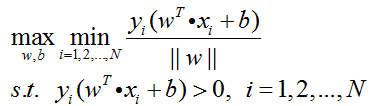
第二步:
对于超平面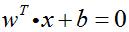
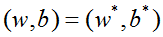
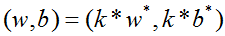
所以,为了简化最优化问题,令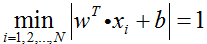
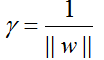
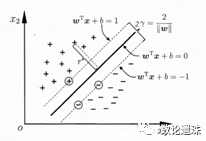
图4.1 将训练集间隔简化为1
此时原始问题及其约束条件可化为:
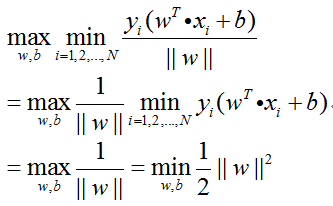
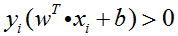
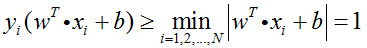
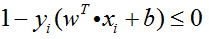
第三步:
所以优化目标可以表示如下,这也被称为最优化问题的原始问题:
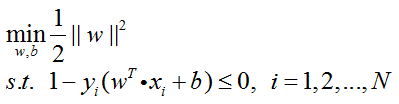
注:之所以将
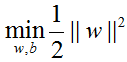
4.2 对偶问题
为了求原始问题的解w和b,我们可以借助朗格朗日函数,通过求解对偶问题的解α,来获取原始问题的解。同时,对偶问题也有助于引入核函数,方便将SVM推广到高维空间的非线性分类问题。
(为了保证文章的连贯性,拉格朗日对偶性的知识点在第6节中予以补充,这里不作展开)。
通过引入朗格朗日乘子α,原始问题
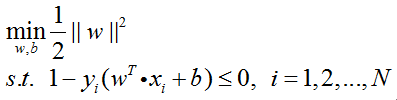
的朗格朗日函数为:
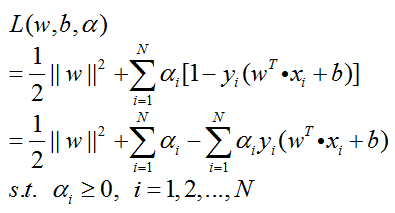
根据朗格朗日对偶性,原始问题等价于求拉格朗日函数的极大极小问题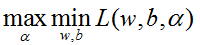
第一步:求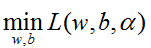
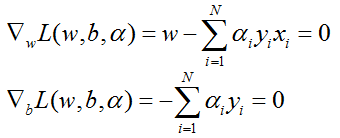
化简可得:
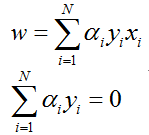
将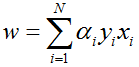
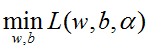
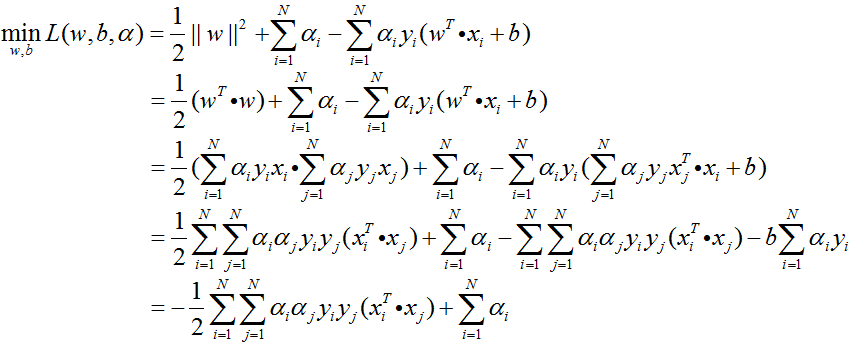
第二步:求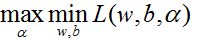
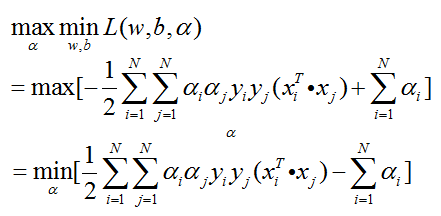
考虑约束条件,整理可得最优化问题的对偶问题:
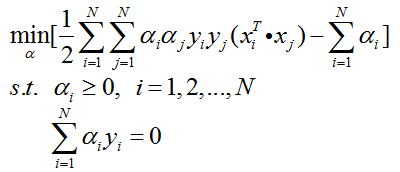
4.3 超平面和分类决策函数
在求解对偶问题的过程中,我们获取了α的值,并且得知了哪些样本点是支持向量。接下来就可以求解w和b:
根据w的表达式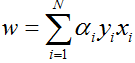
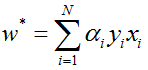
由于支持向量一定在超平面的训练集间隔边界上,所以满足等式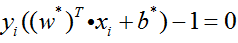
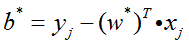
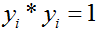
故分类问题的超平面为:
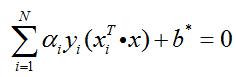
分类决策函数为:
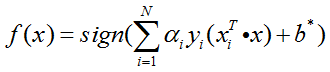
注:
(1)支持向量对应的α>0,原始问题的约束条件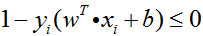
(2)非支持向量对应的α=0,原始问题的约束条件
(3)所以,记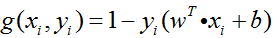
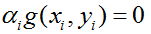
5 应用实例
题目:
训练集包含2个正例点和1个负例点,正例点是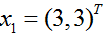
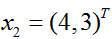
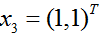
解:
最优化问题的对偶问题为:
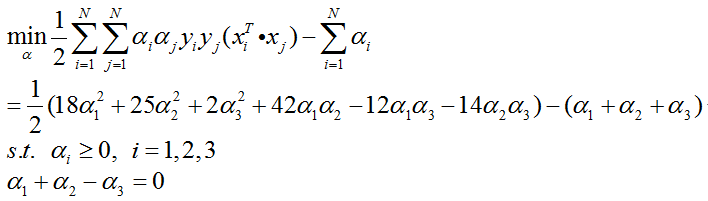
将α3=α1+α2代入对偶问题函数,并记为:
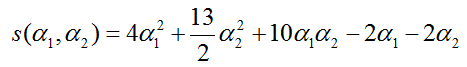
对α1和α2求偏导,并令其等于0,得出α1=1.5,α2=-1时取得极值。但该点不满足约束条件α≥0,故s(α1,α2)极值位于其定义域的边界上。
α1=0时,极小值s(0,13/2)=-13/2。α2=0时,极小值s(0.25,0)=-0.25。综合比较,s(α1,α2)在(0.25,0)处取得极小值,故:
α3=α1+α2=0.25。
此时可确定x1和x3为支持向量。
接着计算w:
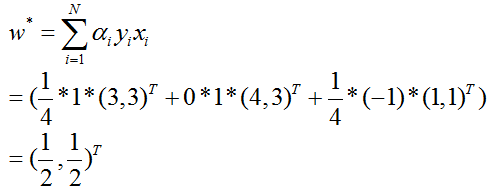
用支持向量x1来计算b:
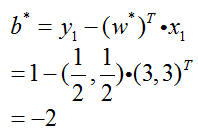
最后,由此可得:
分隔超平面:
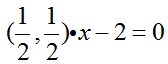
分类决策函数:
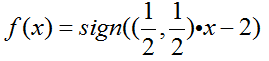
本小节引用自《统计学习方法》李航
6 附录:拉格朗日对偶性
这节介绍如何利用拉格朗日函数及对偶问题,求解带约束条件的最优化问题。此外,对偶问题还能为后续引入核函数提供便利。
对于如下最优化问题的泛用性表示:
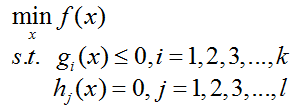
我们将其称为原始问题。
在求解f(x)的最小值的时候,还要考虑约束条件,很麻烦。有没有一个函数既能够表示f(x),又能够把约束条件包含进去呢?
为解决这个问题,拉格朗日函数被提出了:
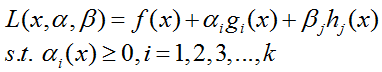
可以证明(我这里就不证明了):
在满足约束条件时,
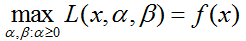
在不满足约束条件时
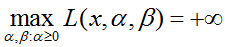
所以:
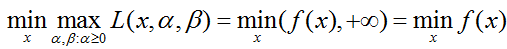
再交换下极大极小顺序(这里就不证明交换顺序不会改变函数结果了):
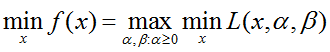
这样,我们就找到了原始问题(带约束条件的最优化问题)的替代形式,并命名为对偶问题:
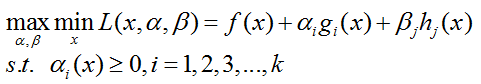
对偶问题相对于原始问题,就好求解多了。
最后,补充下最优值点需要满足的条件(KKT条件):
(1)原始问题可行:
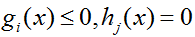
(2)对偶问题可行:
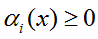
(3)对偶互补松弛:
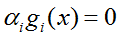
参考文献
[1]李航 统计学习方法 清华大学出版社
[2]张皓 从零构建支持向量机(SVM)
[3]诸葛越 百面机器学习 人民邮电出版社
[4]彭一洋 如何通俗地讲解对偶问题 https://www.zhihu.com/question/58584814
[5]周志华 机器学习 清华大学出版社
本文转载自公众号:数论遗珠,作者:阮智昊
推荐阅读
DigSci科学数据挖掘大赛:如何在3天内拿下DigSci亚军
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



