图像算法可以稳定处理视频了!港科大开源港科大开源其通用算法

论文链接:https://arxiv.org/abs/2010.11838
项目主页:https://chenyanglei.github.io/DVP/index.html
视频演示:
论文详细介绍
 |
|
|---|---|
| 输入视频帧 | 应用图像上色算法的预处理视频 |

| 预处理视频 | 算法输出 |




图2. 利用作者算法处理一个不稳定的预处理视频

图3 算法框架对比
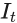 通过应用图像处理算法f可获得相应的预处理帧
通过应用图像处理算法f可获得相应的预处理帧
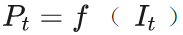 。。例如,图像处理算法f可以是图像着色,图像去雾或任何其他算法。该框架通过输入视频和预处理视频来获得具有时域一致性的输出视频,如图2所示。该算法整体框架如图3所示,作者使用一个全卷积网络g模仿原始图像算法f,同时保持时域一致性。
。。例如,图像处理算法f可以是图像着色,图像去雾或任何其他算法。该框架通过输入视频和预处理视频来获得具有时域一致性的输出视频,如图2所示。该算法整体框架如图3所示,作者使用一个全卷积网络g模仿原始图像算法f,同时保持时域一致性。

图4 两种时域不稳定现象
作者发现许多时域不一致问题属于单模态不一致:所有预处理帧接近于同一模式但是相互之间略有不一致。然而,对于某些任务,存在单一输入具有多种可能预测结果(例如,在上色算法中,汽车可能会被着色为红色或蓝色)。
在这种情况下,如图4右图所示,预处理视频中的时间不一致在视觉上更加明显。由于多个模态之间的差异可能很大,因此对不同模式进行平均会导致较差的性能,这与任何一种可能的输出都相去甚远。以前的方法无法生成一致的结果[19]或倾向于大大降低原始性能[3]。
作者提出了一种迭代加权训练(IRT)策略来处理多模态时域不一致的问题,因为它无法被基本的深度视频先验(DVP)来解决。在IRT中,置信度旨在为每个像素从多种模式中选择一种主模式,而忽略离群值(一种次要模式或多种模式)。
作者通过增加网络输出中的通道数量(例如,两个RGB图像为六个通道)以获得两个输出:一个主帧; 和一个离群帧。最终我们通过置信图来选择不同的像素用以训练两个不同的帧。

图5 算法效果对比示例

图6 IRT的影响

图7 不同网络结构的影响
总结
作者提出了一种简单而通用的方法来提高经图像算法处理的预处理视频时的时域一致性。
基于作者观察到的深度视频先验(DVP),作者通过利用单个视频从头训练CNN来实现时域一致性。与以前的工作相比,作者的方法要简单得多,并且可以产生令人满意的结果(更好的时域一致性以及更大程度保留原始算法效果)。
作者的迭代加权训练(IRT)策略还很好地解决了具有挑战性的多模态不一致问题。
作者认为,所提出的方法的简单性和有效性可以将图像处理算法转化成其对应的视频处理算法。因此,利用该框架,人们可以将最新的图像处理算法直接应用于视频。
作者方法的局限性之一是相对较长的测试时间。尽管作者的方法不需要训练大型数据集,但需要为每个视频训练一个单独的模型,与Lai等人相比,比直接推理要花费更多的时间。但是,与以前采用显式采用光流来增强时域一致性的方法不同,作者证明了这一点,通过神经网络训练可以隐式地实现视频先验(即时域一致性)。
作者表示,他们将专注于提高效率以缩短实际应用中的处理时间。此外,作者相信DVP的概念可以进一步扩展到其他类型的数据,例如3D数据和多视图图像。DVP不依赖于视频帧的顺序,并且自然应适用于维护多个图像之间的多视图一致性。对于3D volume数据,3D CNN也可能表现出DVP的相似属性。
作者介绍
雷晨阳,香港科技大学三年级博士生,博士导师陈启峰,本科毕业于浙江大学,主要研究领域:计算摄影学,图像处理和视频处理,low-level computer vision,3D vision。
邢亚洲,香港科技大学三年级博士生,博士导师陈启峰,本科毕业于武汉大学,主要研究领域:计算摄影学,图像增强,low-level computer vision。


点击阅读原文,直达NeurIPS小组~


