【动态】第三届CSIG图像图形技术挑战赛冠军团队介绍
赛道介绍
总决赛冠军为中英文购物小票信息理解大赛的发票给你薅一地队。该赛道的目标是设计算法,结合人工标注的OCR文字框以及文字内容,对中英文小票图像中的关键信息进行理解,重点考察模型对关键信息的抽取,筛选,整理和汇聚的能力,如下图所示。这种关键信息抽取结果一方面可以提高各种实际应用场景的工作生产效率,比如金融领域的票据分析、教育领域的智能阅卷等业务需求;另一方面也可以作为描述文档和事件的额外线索,辅助各类计算机视觉或自然语言处理领域的实际应用任务,例如事件分析、文档检索、信息重构等。竞赛组织方提供2989例有标注的训练数据,初赛阶段有600例测试数据,复赛阶段有600例测试数据。

参赛方案
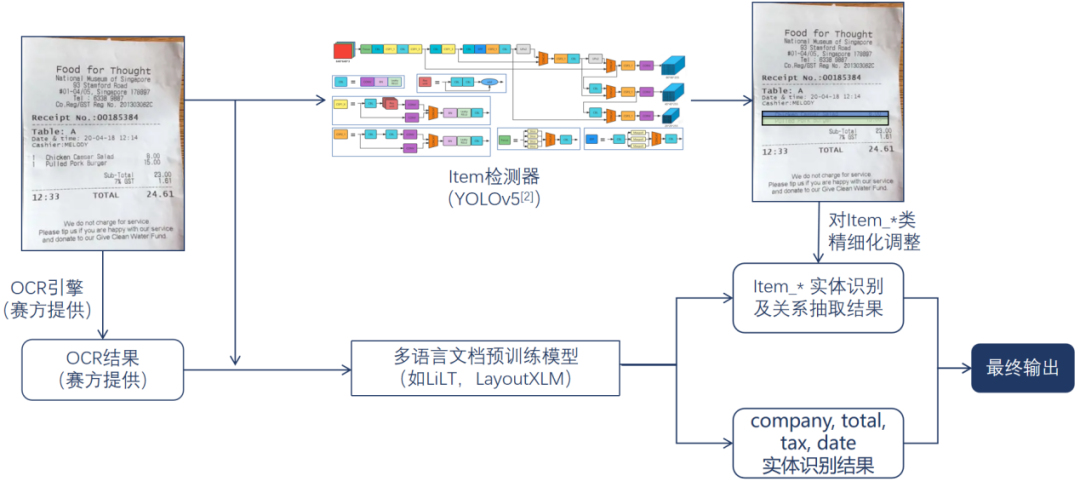
团队提出了一种基于多语言文档预训练模型主分支和目标检测辅助分支的实体分类与关系抽取算法。首先,使用多语言文档预训练模型如LiLT[1]、LayoutXLM[2]等提取并计算输入小票中的多模态特征,并构建实体分类Head和关系抽取Head实现company、total、tax、date和item-name、item-cnt、item-price实体的识别,同时完成每组item的name、cnt、price三种属性的组合。由于属性组合的任务较为困难,单纯使用关系抽取Head的结果仍有不足,且票据中存在各种折叠、褶皱、换行等负面因素影响关系抽取Head性能,因此本方案又额外引入了基于YOLOv5[3]的目标检测辅助分支,对每个item项的区域进行定位。基于两个分支结果的融合与适当的后处理归一化输出,得到最终的关键信息抽取结果。
在主分支中,因为比赛数据提供的OCR信息为中英文兼有,因此使用了多语言文档预训练模型。此类模型结合了大量多语言文档的文本语义、位置或图像信息进行预训练,比起其他纯文本语言模型或者不基于预训练的方法更适配当前的竞赛任务。在数据预处理上,基于XLM-Roberta[4] tokenizer对输入文本数据进行分词,并做出了进一步的改进:原始的XLM-RoBERTa tokenizer对数字和符号类文本存在欠切分问题,而本方案针对性地对其进行了char-level的改进,使得改进后的tokenizer在解决了对数字和符号类文本的欠切分问题同时,也对字母类文本的语义进行了合理保留。
在辅助分支中,检测器检测出每个item项的区域位置,用来精细化调整主分支的输出结果。根据购物小票的版式特性,本方案通过坐标回归的方式简单高效地做到准确的item检测。通过训练集样本分析得到item项的宽高比范围,并通过聚类算法得到较好的Anchor配置。
在工程实现上,对于原始字典字符集中不包含的稀少字符,我们通过扩充tokenizer字符缓存列表的方式,成功解决了tokenizer将未见过的字符解码成<unk>的异常问题。
该方案使用了多任务共享的主干网络,在其基础上针对不同任务设计相应的子Head,通过这种方式使得模型的存储量和计算量显著减少,性能也得到了进一步提升。
在得到模型预测结果和人工规则结果后,该方案又实现了两者的融合策略。在这种方式下,两者的优势得到了互补,各自的错漏情景也得到了修正。该方案也针对多种实体类别设计了相应的可以统一输出格式的后处理解析规则。这样的规范化处理可以方便后续的信息存储与检索应用需求。
总结与展望
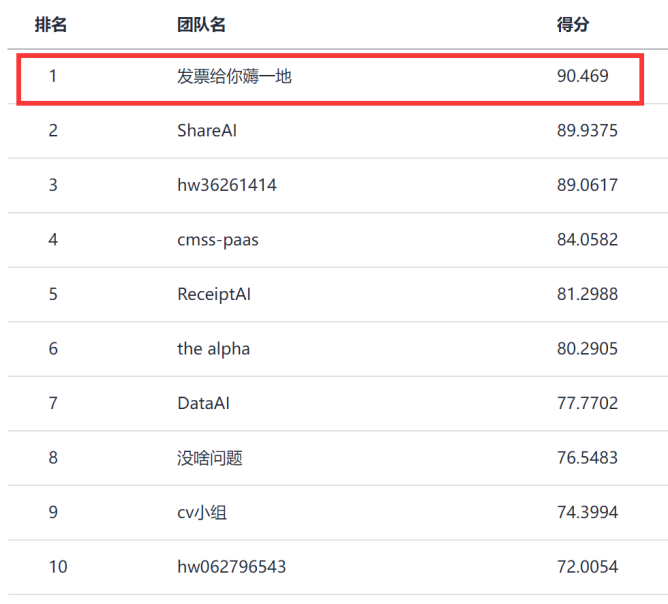
从下表可以看出,团队在本次竞赛中取得较好的关键信息提取效果,在官方发布的指标排行中,本队得分取得第一,是唯一一个分数达到90分以上的队伍。
参考文献
[1]Wang J, Jin L, Ding K. LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 7747-7757.
[2]Xu Y, Lv T, Cui L, et al. LayoutXLM: Multimodal pre-training for multilingual visually-rich document understanding[J]. arXiv preprint arXiv:2104.08836, 2021.
[3]Glenn Jocher, Alex Stoken, Jirka Borovec, NanoCode012, Ayush Chaurasia, TaoXie, Liu Changyu, Abhiram V, Laughing, tkianai, yxNONG, Adam Hogan, lorenzomammana, AlexWang1900, Jan Hajek, Laurentiu Diaconu, Marc, Yonghye Kwon, oleg, wanghaoyang0106, Yann Defretin, Aditya Lohia, ml5ah, Ben Milanko, Benjamin Fineran, Daniel Khromov, Ding Yiwei, Doug, Durgesh, and Francisco Ingham. ultralytics/yolov5: v5.0 - YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations, Apr. 2021.
[4]Ruder S, Søgaard A, Vulić I. Unsupervised cross-lingual representation learning[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts. 2019: 31-38.




