IBM沃森会成为第一个被抛弃的AI技术吗?

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)

感谢 IBM 引领我们创造了这么多个 AI 第一,包括:
1996 年 IBM 的深蓝(Deep Blue)创造了电脑首次击败顶尖人类选手的历史。
2011 年沃森参加综艺节目《危险边缘》获胜。
我确信,还有很多 IBM 创造的令人瞩目的第一我没有提到,但是,由于我们今天要讲的是沃森,其他的我们就不多讲了。
沃森的非凡之处是,在 2011 年,我们认为是 AI 的这些技能:图像和视频处理、面部识别、文本和语音处理、棋类活动之外的游戏、自动驾驶汽车,所有这些是如此的原始,它们还没有接近商用,并且也不会在几年内就投入商用。
时间快进到 2013 年,IBM 宣布,医疗保健,特别是癌症诊断和治疗方案的推荐将成为沃森的王牌。
据报道,到 2015 年为止,IBM 在沃森上的投入已经超过了 150 亿美元。
2018 年之前的两年里,媒体报道了很多关于医院缩减规模或放弃沃森的消息。在 2017 年,著名的 MD Anderson 提出了他们的项目。纽约斯隆凯特琳癌症中心自 2012 年以来一直在帮助训练沃森,但是没有用在他们的病人身上。IBM 自己也宣布了缩减在沃森医疗保健项目上工作的员工规模。
尽管沃森是第一个开箱即用的大型 AI 应用程序,所有跟它的缺点有关的新闻不禁让我们产生了疑问,沃森是否会成为在这个 AI 不断增长、快速前行的世界中第一个被抛弃的 AI 技术?
在我们回答这个问题前,我们必须弄清楚沃森到底是什么。问题是,在 2011 年沃森赢得比赛后,IBM 很快地把几乎每个引入的 AI 的版本都命名为沃森。它扩展到基于 CNN 的图像处理,甚至是用于建模的分析平台,这些都跟最初的沃森没有丝毫关系,或者说,现在的沃森在为此背锅。
沃森是一个问答机系统(Question Answering Machine,简称 QAM),医院在用的沃森问答机与那台赢得比赛的沃森几乎一模一样。也即,利用自然语言处理(NLP)文本输入和输出,沃森问答机搜索大量的知识,并提供最可能正确的答案。
在问答机和简单搜索之间有个重要的区别。
在普通的搜索中,通常会返回好几页的链接,通过这些链接 可能找到答案。
对于问答机,要求返回一个答案,该答案是通过内部模型评分得到的最能代表 正确答案的那一个。
正如数据科学家都心知肚明(也许在使用沃森的医生不一样),所有的模型都会出错,包括假阴性和假阳性。在癌症检查中,这尤其成问题。我们不希望成为被诊断为假阴性的患者,因为癌症的症状被忽略了;也不希望成为被错误治疗癌症的健康人。
医生们所经历的有点微妙。正如预期的那样,沃森在诊断或治疗上的建议大多数是正确的。但是,沃森偶尔会给出明显错误的建议或不恰当的治疗方案。
在推出沃森后的乐观期,医院和 IBM 都认为这是个有价值的第二观点的来源。然而,随着时间的流逝,美国的医生们发现,他们需要不断地仔细检查沃森的建议,并且,沃森没有告诉他们那些他们所不知道的事。
在过去的几年中,IBM 也跟沃森合作,并推出了基因组学独特的版本,意在根据病患的基因标记识别治疗方案。根据一些零散的轶事报道,沃森基因组版本偶尔会发现医生们没有预料到的东西。在海外有限的使用中,这些报道更为常见。但是,在美国,据报道,IBM 对每位接受该检查的病患收取 200 到 1000 美元的费用,没有为医院带来任何财务上的收入。
最重要的是,用于癌症和在其他医疗保健应用中的沃森看起来要灭绝了。
这可能只是实施中的一个缺陷。
也可能表明 AI 问答机的未来已经到了极限,并且,将来不会成为 AI 的一个主要组成部分。
也可能两者兼而有之。
为了探索这个问题,我们需要回顾一下问答机的工作原理和如何设置它。
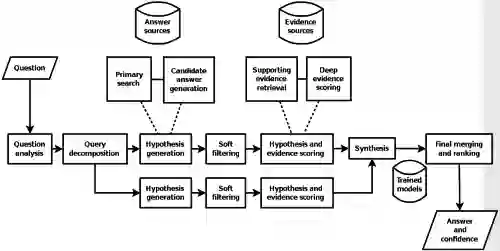
自然语言处理(Natural Language Processing,简称 NLP):NLP 是问答机的核心。NLP 一直在稳步地进步,能够解释一串单词所隐藏的含义,并解释这些词的语境。(如:“I’m feeling blue”我心情不好,“find the boat with the red bow”找到有红蝴蝶结的船)。RNN 利用它们不断增长的能力来分析字符串或词序,无论是输入还是输出,都是改进的主要驱动力。因此,问答机能够接受对话式查询(如,这是我的病人的病历以及目前的状况,最佳的行动方案是什么),并且提供文本输出。
访问受管理的知识库: 该过程首先加载大量的结构化和非结构化源数据,这些数据跟要考虑的领域有关(即,癌症诊断、医疗保健利用管理、法律、社交媒体的看法)。这个知识库是人类管理的,并且必须由人类进行不断地更新以移除那些不再准确的源文件,或添加新的材料。
摄取: 像沃森这样的问答机随后开始对知识库构建索引,并对元数据进行初步探索以让其接下来的处理更有效率。问答机可能也会构建图形数据库附件以提供帮助。
初步训练: 问答机需要一种监督学习形式。数据科学家加载大量的问题和相应的回答,问答机从中学习归纳出哪些术语和习语一起出现,以及关于最有可能答案的逻辑核心。问答机不是简单地重复这些“正确的”样本答案,它们学会超越,并根据这些训练数据找出其他正确的答案。
假设和结论: 当问问答机一个问题的时候,它将解析该问题以发展出一系列潜在的意义或假设,并在支持它们的知识库中寻找证据。然后,对每个假设进行统计评估,以确定问答机是否正确,并把答案呈现给终端用户。
知识发现: 在一些应用中,多个回答或替换方案事实上可能是目标。这些有可能代表了人类之前从未想到过的事实和环境的组合,比如化学物质、药物、治疗方案、材料或 DNA 链的组合,可能代表其领域的新颖创新。在一些癌症应用中,沃森返回可能治疗方案的优先列表。
这不意味着要对每个用例进行法医研究,但是,我有强烈的预感,这里出了问题。像沃森这样的问答机非常耗费人力,远远超过我们目前在用的任何其他机器学习 /AI 应用。
加载所需的所有文档和数据以建立原始知识库,以及持续审查和去掉过时知识的需求,同时要跟上该领域的所有最新发现,这些都需要大量的人工。
在此基础上,还对搜索相关模型进行初步及持续的训练,其中的模型由人类生成的成对的问题和回答进行训练。
这是一个非常不同于我们已经习惯的 AI/ 机器学习实施模型。我怀疑,对于一个像癌症或一般的医疗保健这样的巨大且复杂的主题,在数据库的维护中,巨大的人力因素是一个致命弱点。
我确信在某种情况下,知识体系会受到更多的限制,而且变化速度也变慢了。我们在 2016 年回顾沃森时,列出了 30 个不同的部署沃森的例子,其中包括:
Macys 部署了“Macy’s On Call”,这是一个移动 web 应用程序,点击沃森以允许消费者输入自然语言问题,这些问题都是关于每个商店独特的产品分类、服务和设施,并且消费者接收到对于该查询的定制回复。
VineSleuth 开发了其 Wine4.me 应用程序,根据感官科学和预测算法为消费者推荐红酒。该初创企业把沃森的语音分类器和翻译服务用于杂货店的售货亭。
希尔顿全球酒店集团(Hilton Worldwide) 利用沃森为“Connie”助力,“Connie”是酒店业第一个受沃森支持的机器人礼宾服务。“Connie”根据来自沃森和 WayBlazer 的领域知识,向客人介绍当地的旅游景点、餐饮推荐和酒店特色及设施。
Purple Forge 为加拿大的 Surrey 开发了基于 311 服务的沃森,用于回答市民关于政府服务的问题。(何时收集回收物品?)该应用程序能够回答 1 万多个问题,比人类更有效率,同时成本也更低。
这些例子的共同之处是,知识库非常有限,并且 / 或者变化缓慢。其次,也许更相关的是,随着聊天机器人爆发性地投入应用,这些更简单的面向客户的应用程序现在正在得到解决。因此,看起来,该市场的“低端”似乎受益于 NLP 借助聊天机器人的进步,或者,更常见的是不用沃森问答机。
在该市场的“高端”,知识库是非常庞大且迅速变化的。可以预见一个复杂的问答机假设 / 搜索算法能够结合以前没有结合的知识元素以创造独特的新见解。沃森在该领域面临着来自不同方法的复杂问题的竞争。
例如,人们希望结果是发现新的化学物质、材料、药物或 DNA 功能。尽管沃森仍然在这一领域有用武之地,但是,研究人员越来越倾向于使用较少人力的 CNN 和 RNN 来进行探索。这在生物领域尤其如此。
对于沃森来说,在这个连续统一体中的中间仍然有可能有个适合它的最佳位置,但是,这些机会看起来越来越渺茫,因为底层的聊天机器人和顶层的更高级技术限制了它。
也许现在还不是说问答机在 AI/ 机器学习领域没有一席之地的时候,但是,在设置和维护过程中那么高的人力需求就没有通过深度神经网络、强化学习和大量非人类计算能力来完成同样的工作那样有吸引力。
阅读英文原文:
https://www.datasciencecentral.com/profiles/blogs/watson-time-to-prune-the-ml-tree

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!





