卷积神经网络(CNN)融合PMF模型构建推荐系统

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
本文全部代码 github 地址
在公众号 datadw 里 回复 CNN 即可获取。
深度学习在推荐系统上的运用,具体用了卷积神经网络(CNN)提取文本特征,融合PMF模型进行推荐。
具体论文见http://dm.postech.ac.kr/~cartopy/ConvMF/
用户对项目评分数据的稀疏是推荐系统质量恶化的主要因素之一。为了处理稀疏性问题,已经提出了几种推荐技术,其另外考虑辅助信息以提高评估预测的准确性。特别是,当评级数据稀少时,基于文档建模的方法通过额外使用文本数据(如评论,摘要或概要)提高了准确性。然而,由于单词模型的固有局限性,它们难以有效地利用文档的上下文信息,这导致对文档的浅薄理解。本文提出了一种新的上下文感知推荐模型,卷积矩阵分解(ConvMF),将卷积神经网络(CNN)集成到概率矩阵分解(PMF)中。因此,ConvMF可以捕获文档的上下文信息并进一步提高评分预测的准确性。我们对三个真实世界的数据集进行的广泛评估表明,即使评分数据非常稀少,ConvMF也远远优于最先进的推荐模型。我们还证明了ConvMF成功捕获文档中单词的细微差异。
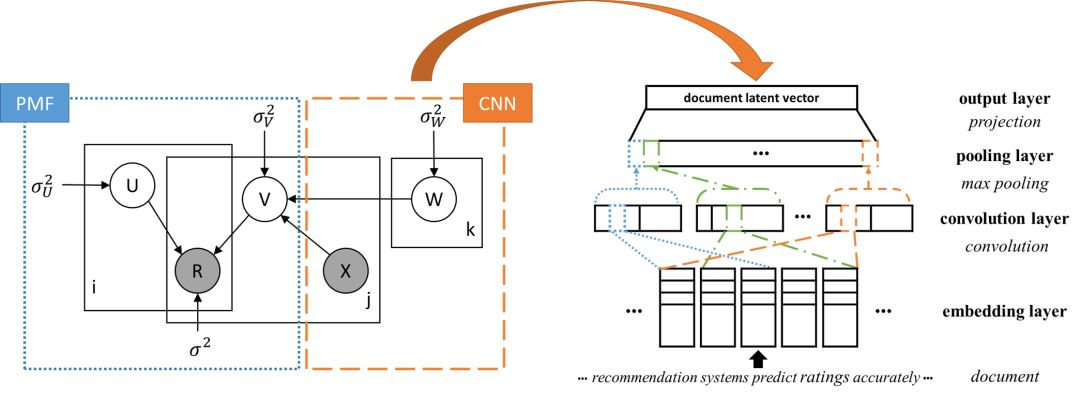
图1. ConvMF概述
左图是集成了概率矩阵分解(PMF)模型和卷积神经网络(CNN)模型的ConvMF的概率图形模型,右图是CNN模型利用项目描述的详细架构文档。 使用从CNN模型获得的文档潜在向量作为项目变量(V)的高斯分布的均值,其作为CNN和PMF之间的桥梁起着重要作用,有助于完整分析描述文档和评分。 有关更多详细信息,请参阅我们的论文。
http://dl.acm.org/citation.cfm?id=2959165
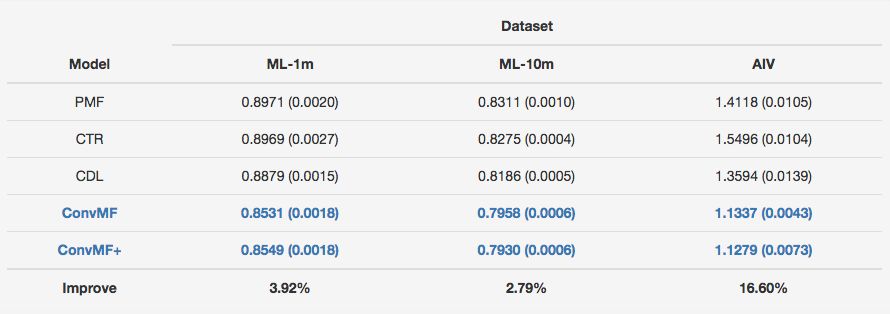
上表显示了每个测试集上五种方法的整体评级预测误差。 请注意,每个数据集都被随机分成一个训练集(80%),一个验证集(10%)和一个测试集(10%)。 “提高”表明“ConvMF”相对于最佳竞争对手的相对改进。 与三种模型相比,ConvMF和ConvMF +在所有数据集上都取得了重大改进。
预训练词嵌入模型的影响:
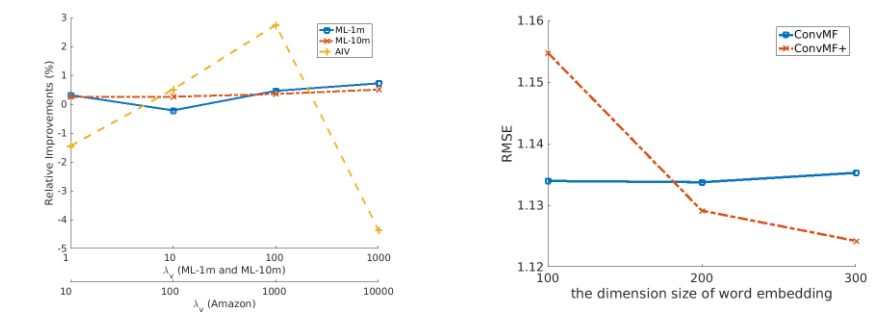
两幅图介绍了ConvMF的预训练词嵌入模型的影响。 左图显示了ConvMF +与ConvMF在三种不同λv数据集上的相对改进。 随着数据更加严重偏斜(即亚马逊即时视频),预先训练的词嵌入模型的影响也会增加。 请注意,高的λv值会导致ConvMF和ConvMF +尝试利用超过评分的项目描述文档。 右图显示了字词嵌入模型的维度大小对Amazon Instant Video数据集的影响。 由于模型中包含的信息越来越丰富,ConvMF +的测试误差随着预先训练的字嵌入模型的尺寸大小变得越来越小而降低。
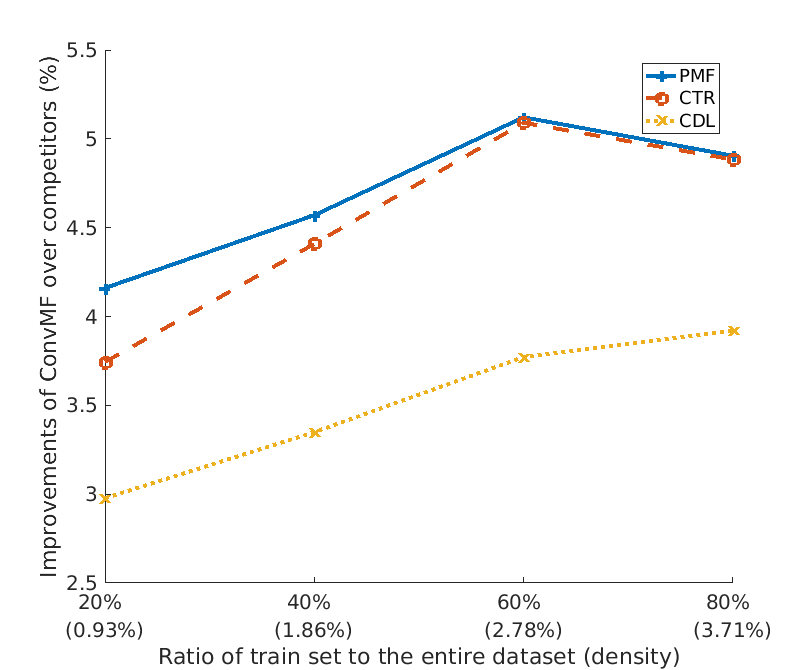
该图显示了三种方法对spaseness数据集的ConvMF的改进。 ConvMF在所有范围内都超过了三个竞争对手,而且我们可以看到,当数据密度增加时,这些改进会增加。 这表明ConvMF的CNN已经很好地整合到PMF中,用于评估信息的推荐任务。
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注




