赛尔笔记|基于深度学习方法的对话状态跟踪综述
作者:哈工大SCIR 滕德川
1. 引言
1.1 研究背景
随着互联网和个人智能终端的普及和广泛应用,各种各样的互联网应用和个人应用如雨后春笋般不断涌现,如出行预定、网上购物和提醒事项设置等。这使得人们的日常生活和出行变成越来越方便,但是越来越多的应用增加了用户的时间成本和使用难度,因此对虚拟个人智能助手的需求日益增加。对话式人工智能是实现虚拟个人智能助手的核心技术,可以分为开放域对话系统和面向任务的对话系统两个大类。然而,人类对话本质上是复杂的、含有歧义的,距离创造出一个可以面向任意场景的开放域对话人工智能仍有很长的路要走。因此,工业实践上聚焦于建立完成特定任务的对话系统,即任务型对话系统。任务型对话系统首先通过理解消息、主动询问和解释澄清来确定用户的需要,随后通过调用应用程序接口完成对相关资源的查询,最后返回正确的结果。在用户和对话系统的交互过程中产生的对话可以被叫做任务对话,它是一段由任务驱动的多轮对话。一个典型的模块化任务型对话系统如图1所示,由四个关键部分组成:
-
自然语言理解模块:将用户文本消息转化为可以被机器理解的语义标签,如意图、槽位和槽值; -
对话状态跟踪模块:在对话中的每一轮基于对话历史维护最新的对话状态,通常表示为一组槽位-槽值对; -
对话策略模块:基于当前的对话状态,决定对话系统的下一步动作,比如确认用户的需要,查询资源库和提供满足条件的结果等。另外,对话状态跟踪和对话策略模块的组合被称为对话管理器; -
自然语言生成模块:将对话策略模块决定的系统对话行为转换成人类的语言,回复给用户。
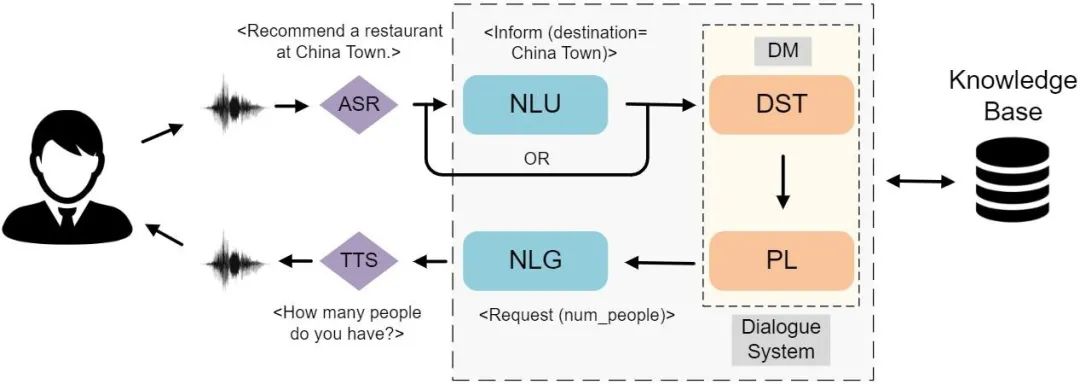
其中,对话状态跟踪的研究是任务型对话系统领域中十分重要的研究课题之一。具体来说,对话策略和自然语言生成两个模块需要基于当前的对话状态,才能选择下一个系统动作并生成系统回复。因而,对话状态的正确识别对于增强任务型对话系统的整体性能至关重要。
1.2 动机
近年来,随着深度学习方法在图像、语音和文本领域的突破,它的应用范围逐渐地扩张到对话系统领域。得益于其强大的表示能力,建立在深度学习之上的任务型对话系统的性能不断提升,逐渐地成为了主流。而对话状态跟踪作为任务型对话系统的核心模块,许多基于深度学习的对话状态跟踪器(可以被称作神经对话状态跟踪器)也被提出,展现出了优异的性能和更强的泛化能力。另一方面,许多基准数据集的提出,如DSTC2[1]、WOZ 2.0[2]、MultiWOZ 2.0[3]和CrossWOZ[4]等,让使用深度神经网络结构解决对话状态跟踪任务成为可能,同时提供了测试平台以广泛地、公平地评估对话状态跟踪系统的性能。蓬勃发展的神经对话状态跟踪研究呼吁系统性地调研和分析最新进展的工作出现。对此,我们在本篇文章中深入整理总结了基于深度学习方法的对话状态跟踪的发展历程。
1.3 对话状态跟踪的新范式
自然语言理解和对话状态跟踪模块紧密相关。从模块的输出形式来说,两者都完成了对话的槽位填充,事实上他们却扮演了不同的角色。自然语言理解模块尝试对当前的用户文本消息进行分类,比如意图、领域类别以及消息中每个单词的所属槽位。也就是说,它通常通过为用户文本消息中的每个单词标注槽位标签的方式完成槽位填充。然而,对话状态跟踪模块不分类或者标注用户消息。而是基于整个对话历史,尝试为预先定义的槽位列表中的每个槽位名找到相应的槽值。在对话的每一轮,它在到当前轮的整个对话历史中进行检索,决定哪些内容可以被填入槽位列表中的某个特定槽位中。不难发现,与对话状态跟踪模块相比,自然语言理解模块有如下几个缺点:
-
它的输入一般只有本轮的用户消息,分类过程缺少了系统消息以及对话历史的帮助; -
不能识别槽值不直接出现在文本中的槽位。例如,用户在预定酒店时要求其房间有无线网络,此时“网络”槽位的槽值应为“是”,该槽值并没有直接出现在用户输入的文本中; -
错误的语义槽识别结果可能会对后续模块产生不良影响。
早期的对话状态跟踪方法将自然语言理解模块的输出作为对话状态跟踪模块的输入,而最近的方法考虑到自然语言理解模块的诸多限制,直接使用原始用户消息来跟踪对话的状态。
2. 任务概览
在这一节中,我们首先给出对话状态跟踪的任务定义,然后简要描述常用的数据集和评价指标。
2.1 任务定义
对话状态
对话状态跟踪的目标是,在对话的每一轮,从系统回复和用户话语中抽取相关信息更新对话状态。对话状态是连接用户和对话系统的桥梁,包含了对话系统完成一系列决策时需要的所有重要信息。考虑到诸如跟踪效率、跟踪准确率、领域适应性和端到端训练等众多要求,对话状态存在许多的表现形式。接下来以第二届对话状态跟踪挑战DSTC2提供的任务型对话数据集为例,简单介绍该数据集的对话状态的定义。
在对话中,用户通过指定约束条件寻找合适的餐厅,也可能要求系统提供某些槽位(如餐厅的电话号码)的信息。数据集提供了一个本体(ontology),其中详细地描述了所有可能的对话状态。具体来说, 中列出了用户可以询问的属性,被叫做可请求槽位(requestable slot),比如餐厅提供的菜品类型或者餐厅的电话号码。它也列出了可以被用户提出作为约束条件的属性及其可能的取值,这些属性被叫做可通知槽位(informable slot)。图2展示了DSTC2中的 的细节。因此,某个对话轮的对话状态被定义为三个部分:
-
目标约束(Goal Constraint):每个可通知槽位的值都可以由用户指定,作为用户达成某一目标(如预定一个西苑餐厅周日下午6点的6人桌)的约束条件。槽值可以来自 ,也可以是特殊值 或 。其中, 表示用户对该槽位的取值没有偏好, 意味着用户尚未为这个槽位指定一个有效的目标; -
被请求槽位(Requested Slots);这些槽位的槽值可以被用户询问,应该由系统通知给用户; -
当前轮的搜索方法(Search Method):搜索方法表明了用户与系统交互的类别。 表示用户尝试发起一个约束, 表示用户需要一个替代选项, 表明用户想要询问某个槽位名对应的槽值, 表明用户想要终止对话,而其他情况的类别都为 。
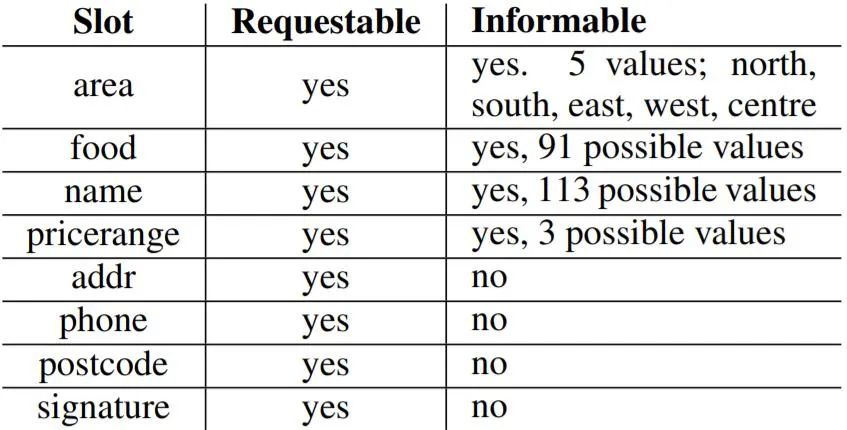
在DSTC2关于对话状态的定义中,当前轮的搜索方法也可以看作是一个特殊的槽位 Search_Method,它的取值有5种可能。由此可见,任务型对话的对话状态可以统一定义为一组(槽位,槽值)对,随着对话的进行不停的更新。接下来给出对话状态跟踪任务的形式化描述。
形式化定义
令 表示一个 轮对话, 和 分别表示对话第 轮的系统回复和用户话语。假设我们有 个 预定义的槽位 ,那么对话第 轮的对话状态被定义为 。其中, 表示槽位 的相应槽值, 是槽位 的取值空间。把所有槽位的取值空间放在一起,可以构建出一个本体 。
基于对话 和本体 ,任务被定义为学习一个对话状态追踪器 ,该追踪器可以有效地捕捉用户在对话中表达的意图。根据定义可以看出,跟踪器可能需要在每一轮预测多个槽位的值。除此之外,一些槽位的取值空间可能是巨大的,也就是说,这些槽位存在大量的可选值。这些现象让对话状态的预测变得更有挑战性。
值得注意的是,我们使用“槽位”这个术语表示领域名称和槽位名称的组合,从而包含领域和槽位信息。例如,我们使用餐厅-价格范围而不是价格范围,去表示餐厅领域的价格范围槽位。当对话包含多个领域时,这种格式非常有用,它也被许多之前的研究工作广泛采纳。
2.2 数据集
神经对话状态跟踪器需要一定规模的面向任务的对话数据集进行训练或者验证,同时在这些数据集中每个对话轮都应该有相应的对话状态。由于面向任务的对话数据获得难度高且标注对话状态费时费力,大大地增加了人工标注工作量。目前大部分方法,采用的训练测试数据集主要以DSTC2、WOZ、MultiWOZ和CrossWOZ数据集为主,数据集的统计数据见表1。
表1 常用任务型对话数据集统计

其中,CrossWOZ 是中文任务型对话数据集,DSTC2和WOZ 是单领域任务型数据集。
2.3 评价指标
运用已经构建好的开放数据集,研究人员可以对神经对话状态跟踪器进行训练,而判断已训练的跟踪器的优劣则需要建立一个通用的评价标准。评估对话状态跟踪器的常用指标是联合目标准确率(Joint Goal Accuracy)和槽位准确率(Slot Accuracy)。
联合目标准确率
在对话的每一轮,将对话状态跟踪器的输出和人工真值标注进行对比。其中,人工真值标注包括了所有可能的(领域,槽位)对的槽值。联合目标准确率被定义为每个槽位的值都被正确预测的对话轮的比例。如果一个槽位还未被提及,它的人工真值标注被设为 ,而且值为 的槽位也需要被预测。联合目标准确率是一个相对严格的评价指标,即使一个对话轮中只有一个槽位被错误地预测,该轮的对话状态也是错误的。因此,一个对话轮的联合目标准确率的取值要么是 ,要么是 。
槽位准确率
槽位准确率独立地将每个(领域,槽位,槽位)三元组和其对应的人工真值标注进行比较。与联合目标准确率相比,它的评价粒度更为精细,但不适合评价对话跟踪器的整体性能。每个对话轮中大多数的槽位未被提及(即槽值为 ),即使槽值全部被预测为 ,槽位准确率也会很高。
3. 现有方法及分类
对话状态跟踪的历史由来已久。早期的研究工作使用人工设计的规则或者统计方法实现对话状态的跟踪。
-
由于人工总结的规则无法覆盖对话中的所有情形,基于规则的方法有许多的限制,如有限的泛化性能、高错误率、较差的领域适配能力等等。 -
而统计方法建立在数据的概率分布之上,其性能被数据中的噪音、歧义、矛盾等严重损害。
随着硬件计算资源的快速提升以及深度学习的崛起,研究人员开始考虑把各种各样的深度神经网络结构引入到对话状态跟踪器中,代表性的研究工作如DNN[5]、RNN[6]、NBT[7]和TRADE[8]等。这些神经对话状态跟踪器在大量的有标注数据集上训练之后,其性能超越了基于规则和统计的方法。相比于早期方法,该类方法将研究者从设计规则的繁杂工作中彻底解放出来,同时也增加了对话状态跟踪器相对于不完美数据的鲁棒性。
典型的神经对话状态跟踪器以对话历史、本轮对话和预定义的槽位列表为输入,输出到本轮对话为止的最新对话状态。为了更为具体地总结现有方法的核心特点,我们提出了神经对话状态跟踪器的通用结构,包含三个部分:特征抽取、状态操作预测和状态解码。
3.1 特征抽取
3.1.1 槽位与对话的特征抽取
由于需要跟踪对话状态中的所有槽位,研究人员关注如何从对话文本中抽取与每个槽位相关的信息,这不仅需要对槽位和对话进行语义表示,还可能需要交互式地对两者进行建模。因此,槽位与对话之间的信息交互可以分为两种类型:
-
分离式建模;分别表示槽位和对话 -
交互式建模:获得的对话表示与槽位相关,槽位表示同样与对话相关
分离式建模
Mrkšić等人在2017年提出NBT模型,见图3,
-
利用 表示学习方法分别将候选槽位-槽值对和对话中的词语嵌入到稠密的单词向量中, -
在状态解码阶段,NBT模型才在两者的表示上进行推理计算,从而 判断该槽位-槽值对是否出现在对话中。
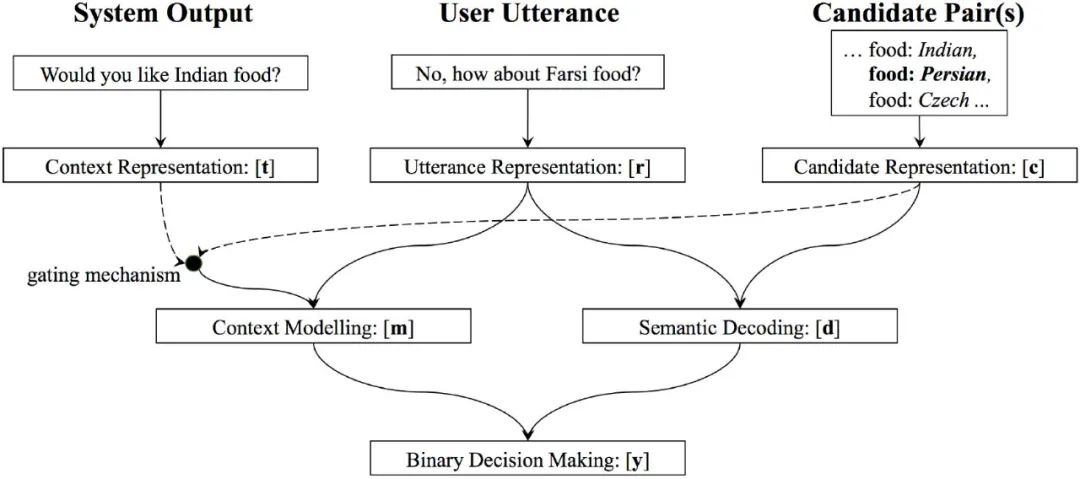
这类分离式特征提取方法有如下特点:
(1)得到的槽位特征与对话历史特征互相独立;
(2)在一个对话回合内,无论槽位-槽值对有多少,对话历史的特征提取只需要进行一次。
交互式建模
如果选择对候选槽位-槽值对和对话进行交互式建模,会有以下两个缺点
(1)对于完整的本体 的依赖:在应用时,需要明确每个槽位的可能取值,无法识别槽位的未见槽值;
(2)当槽位的可选槽值的数量过多时,这类方法的时空复杂度较高。
为了避免以上的缺点,研究者转变方向探索建模槽位与对话间关系的方法。Shan等人[9]提出CHAN(Contextual Hierarchical Attention Network)模型(结构如图4),
-
使用slot-word attention机制从之前每一轮对话中抽取与槽位相关的信息, -
利用slot-turn attention机制进一步地从整个对话历史中选取与槽位最相关的特征。
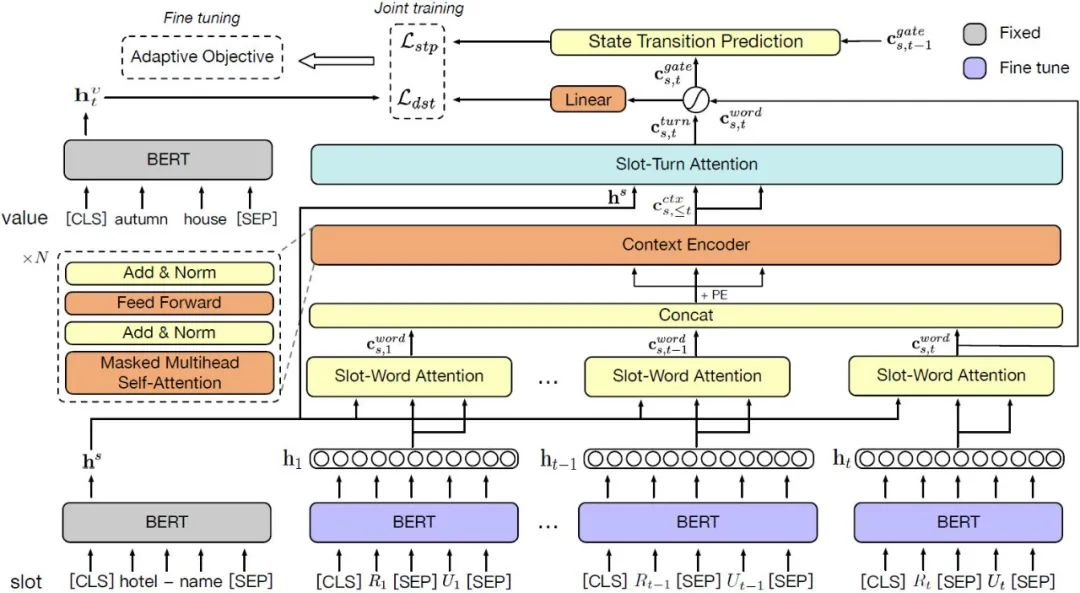
相比于分离式建模,
-
联合建模槽位和对话历史可以帮助槽位更精确地 定位对话历史中与该槽位紧密相关的部分; -
然而,联合建模的时空复杂度高于分离建模。
3.1.2 槽位间的关系建模
除了建模槽位与对话之间的相关性,有些工作还考虑到槽位与槽位之间可能存在的关系[10, 11, 12, 13],如共指和槽值共现等。
-
共指关系表示一个槽位的值来自于另一个已经存在的槽位; -
槽值共现指的是槽值间可以有很高的共现概率,如餐厅的名字与它提供的菜品类型高度相关。
不考虑槽位间关系的对话状态跟踪器,独立地预测每个槽位的槽位,忽略了槽位之间存在的联系。CSFN-DST[10]和SST[11]模型构建了一个schema graph试图捕获不同槽位之间的相关性。SAS[12]模型计算了一个槽位相似度矩阵,从而实现相似槽位之间的信息流动和信息交互。在槽位相似度矩阵中,若两个槽位被认为相似,两者之间相似度设为 ,否则为 。判断槽位的相似性有两种方式:(1)计算不同槽位的名称和类型之间的余弦相似度,根据两个超参数判断是否相似;(2)槽位名称和类型的K-means聚类结果。
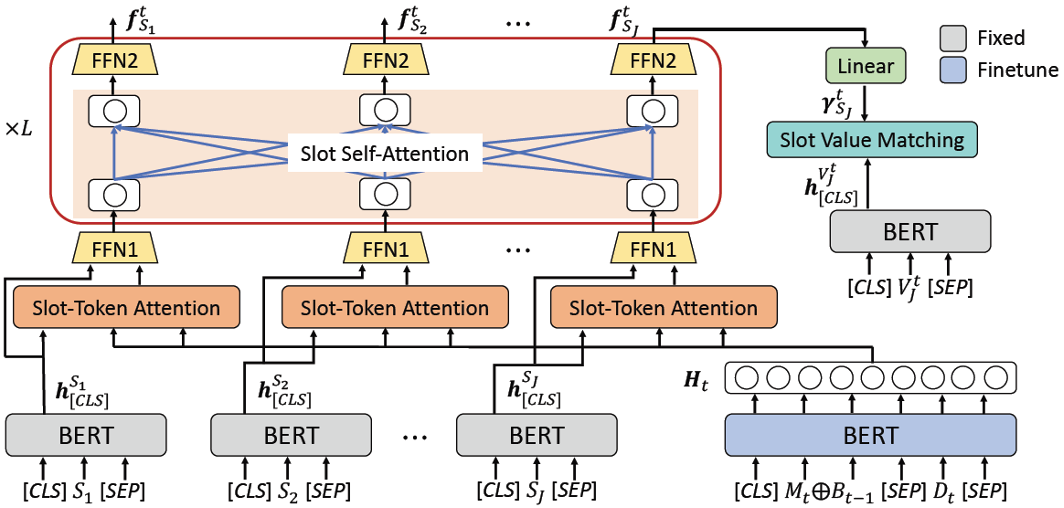
然而,CSFN-DST和SST模型不具有扩展性。在这两个模型中,人工构建的schema graph不能完全地反映出槽位间的相互关系,同时构建图的过程中使用了许多先验知识。对于SAS模型,一方面,超参数难以设定,另一方面,非 即 的相似度设置方案明显不合理。除此之外,以上三种方法都只依据槽位名称衡量槽位相关性,可能会忽略或者高估一些槽位之间的关系。为了解决上述缺陷,Ye等人[13]提出了STAR模型,利用槽位的名称和相应的槽值更精确地建模槽位关系。
3.2 状态操作预测
对槽位和对话文本进行表示和特征抽取之后,提取后的特征可以被用来确定针对槽位的操作类别,即状态操作预测。根据不同的槽位更新机制,我们可以将状态操作分为两个大类:面向状态识别和面向状态更新。采用前者的跟踪器注重于从整个对话中抽取状态,而后者更关心状态跟踪的效率提升。
面向状态识别的操作
采用这类状态操作的方法直接利用提取后的特征预测从对话开始到当前的最新对话状态,可以不设置状态操作,也可以设置特殊操作辅助模型完成状态识别。如图5中的TRADE模型使用三类状态操作判断槽位是否属于特殊值,即 、 和 。
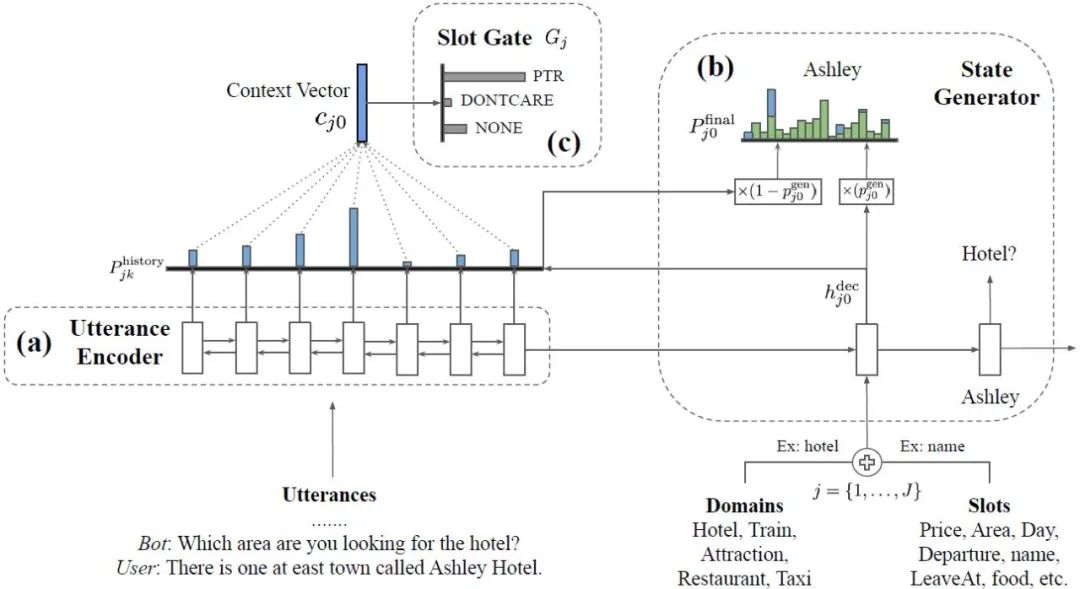
尽管包括TRADE在内的方法已经取得了不错的效果,这类方法仍然存在问题:在对话的每一轮,模型都需要预测从对话开始到当前对话为止出现的所有槽位-槽值对。随着对话的继续,从越加冗余的对话历史文本中抽取对话状态就越加困难,这类解决方案可以称之为独立方案,如图6所示。
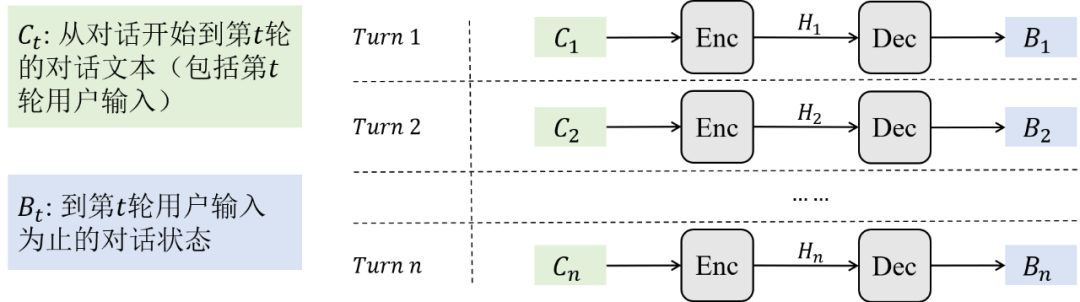
从方案的表现形式上来说,独立方案将包含 轮交互的完整对话的对话状态生成问题拆解成了独立的 个子问题,子问题间互不干扰。每个子问题的解法是把到当前轮为止的对话历史看作一个整体,直接从其中生成所有已出现的对话状态。可以看出这类方法重复预测不变槽位的槽值,这一缺陷导致跟踪状态的效率低下,在实际使用中很难达到极短响应速度的要求。
面向状态更新的操作
采用面向状态更新操作的方法追求高效地完成状态跟踪,尽可能地减少对不变槽位的重复计算,进而减少任务型对话系统的响应速度。比如,SOM-DST(Selectively Overwriting Memory for Dialogue State Tracking)模型[14]通过减少冗余计算和并行跟踪所有槽位,可以将每轮对话的状态跟踪推理时间缩减为TRADE模型的 8%。
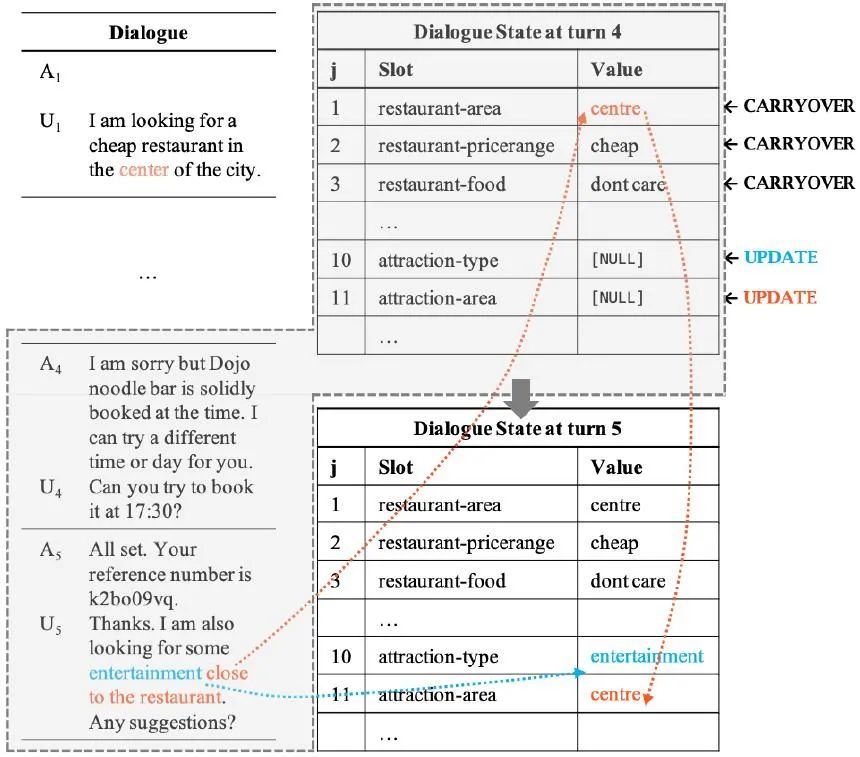
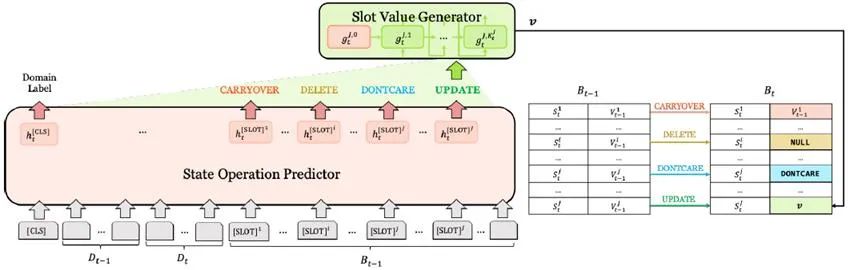
具体来说,SOM-DST把对话状态看作一个可以选择性重写的存储结构(memory),进而将对话状态跟踪解耦成两个子任务:
(1)状态操作预测子任务决定了对memory中的每个槽位执行的操作类型,包括 、 、 和 等操作;
(2)槽值生成子任务为memory 中需要重写的槽位生成新的槽值。图7展示在对话的第 轮,SOM-DST如何更新对话状态, 操作发生在第 和 个槽位上,第 个槽位的新槽值需要推理并引用第一个槽位的槽值 “center”。
如图8中的模型图所示,SOM-DST将前一轮对话 、本轮对话 和前一轮的对话状态 作为输入,对本体 中的所有槽位并行处理,输出本轮的对话状态 。实际上,解耦之后的模型只需要生成需要改动的槽位(所有槽位的最小子集)的槽值,状态操作预测器负责筛选需要生成新值的槽位,槽值生成器只为被选择的槽位解码槽值。减少需要解码的槽位和对所有槽位并行处理使得SOM-DST模型的平均响应时间达到了27ms,相比于TRADE模型的340ms,这是一个更可以被用户接受的响应时间。
与之类似,Lin等人[15]提出最小信念跨度(minimal belief span),认为当系统与不同领域的API交互时,从头开始生成对话状态是不可扩展的。他们提出的MinTL框架基于最小信念跨度,在上一轮的对话状态上进行 、 和 这三种操作,从而实现对话状态的更新。
我们将这类方法称为递进方案,如图9所示,递进方案将每一轮的对话状态看作一种明确的数据结构,在生成当前轮的对话状态时不光可以看到对话历史,还可以利用之前轮已生成的对话状态。该类方法可以根据当前轮对话对之前轮的对话状态进行更新,从而更快速地完成对话状态的生成。
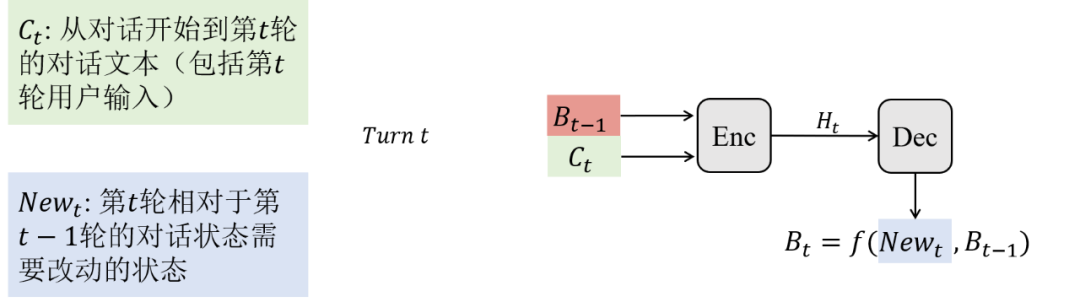
3.3 状态解码
作为神经对话状态跟踪器的最后一个分量,状态解码部分基于前面分量获得的所有信息完成对槽值的解码。虽然跟踪器的目的是从对话中找出某一槽位的槽值,但是面向不同的应用场景,可以有不同的方式解码槽值。
3.3.1 基于预定义本体
如果应用中,槽位的所有可能槽值已知,那么在对话的每一轮,状态解码器可以试图寻找与对话历史最相关的槽位-槽值对。这种解码方式需要事先知道完整的本体 ,因此归纳为基于预定义本体 的状态解码器。
多分类解码器
对于每个槽位,多分类解码器从所有可能的槽值中选择正确的那个,如STAR模型[13]。图10中,槽位特征 经过一个线性层转换,获得的 与该槽位所有槽值的向量表示计算相似度,相似度最高的值作为结果。
二分类解码器
采用这种解码器的对话状态跟踪器,一次完成一个槽位-槽值对和对话历史的特征抽取。基于抽取后的特征,二分类解码器判断该槽位-槽值对是否出现在对话之中,如图3中的NBT模型。
由于每个槽位需要完成多次完整的模型推理计算,二分类解码器增加了系统的响应时间。
3.3.2 基于开放词表
然而,在任务型对话系统的实际应用场景下,某些槽位的槽值列表不能完整地获得。
-
比如与时间相关的槽位, 预约的就餐时间等,设计者很难将所有可能的槽值全部枚举出来; -
也可能因为没有遍历后端数据库的权限,对话系统无法访问到所有已存在的 餐厅名称。
面向这类应用场景,许多研究工作设计了基于开放词表的状态解码器直接从对话中找出或者生成槽值。
复制生成机制
在一个槽值的每一步解码步中,TRADE模型[8](图5)结合复制机制(copy mechanism)和生成机制,对两种机制得到的词表概率分布加权平均,概率最高的单词作为解码步的输出。其中,复制机制实现从对话历史中选择值,生成机制生成未直接出现在对话中的单词,两者的结合提高了对话跟踪器的实用性和开放性。
识别文本跨度
基于文本跨度(text span)的解码器,通过在对话历史文本中选取子序列的方式,直接从对话历史中抽取槽值。如高等人[16]将对话状态跟踪任务转化为抽取式的问答任务,随之提出的DST-Reader模型通过预测子序列的开始和结束从输入的对话文本中抽取槽值。
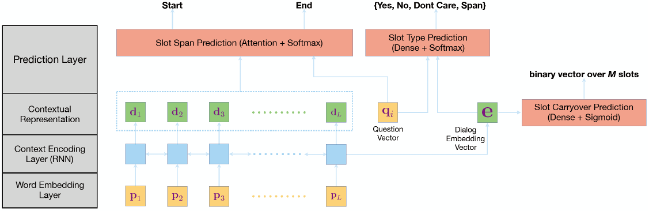
如图11的示意图所示,模型
-
将对话文本序列 看作一段篇章(passage),针对每一个槽位 ,构建一个问题(question)去询问当前对话中的某一个槽位的槽值是什么,如“ what is the value for slot i?”; -
若状态操作类型为 ,则从对话中选取子序列的开始位置和结束位置,得到的子序列即为槽值。
3.3.3 混合方法
根据槽位的槽值可枚举性,槽位可以被分为可枚举槽位和不可枚举槽位。可枚举槽位指的是该槽位的可能槽值固定不变,如“酒店星级”一般被分为一星至五星。而不可枚举槽位是之前提到的预约的就餐时间和餐厅名称这类槽位。
上述的两类状态解码器都是以同等的方式对待所有的槽位。然而,
-
基于预定义本体 的状态解码器在面对不可枚举槽位时,无法解码出未出现在槽值列表中的值。 -
基于开放词表的状态解码器理论上虽然可以生成没有直接出现在对话中的槽值,但显然基于预定义本体 的状态解码器更适合处理可枚举的槽位。
因此,一些研究工作提出了混合方法,使用两种状态解码器分别处理可枚举槽位和不可枚举槽位。
4.结论
基于深度学习方法的对话状态跟踪模型,即神经对话状态跟踪模型,在过去几年受到研究者的广泛关注。针对这一任务型对话系统中的重要模块,本文首先介绍了对话状态跟踪任务的重要性、定义、常用数据集以及评价指标。随后,提出一个通用框架细致地梳理了近些年的神经对话状态跟踪模型,分为特征抽取、状态操作预测和状态解码三个阶段。
在特征抽取阶段,跟踪器完成对槽位和对话历史的特征抽取,获得蕴含丰富信息的文本表示;有的模型更进一步地对两者进行交互式的建模,得到分别与槽位和对话更为相关的特征表示,帮助后续模块更准确地跟踪槽位状态;更有甚者建模槽位间的特征表示,充分利用槽位间的共指和槽位共现等关系。在状态操作预测阶段,提取后的特征可以被用来确定针对每一个槽位的操作类别。在每一个对话轮,面向状态识别的操作帮助跟踪器在对话历史中寻找所有槽位的槽值;而面向状态更新的操作识别出需要更新的槽位,在状态解码阶段对其槽值进行解码,这减少了冗余的计算,但可能会损失一定的跟踪准确率。状态解码器将前面分量获得的所有信息作为输入,输出槽位的槽值。基于预定义本体的解码方式需要完整的本体,在每个槽位的所有可能槽值上完成分类;基于开放词表的解码方式直接从对话历史中获得槽值,可以通过复制加生成的模式,也可以通过识别文本跨度在对话历史中确定包含槽值的连续子序列;混合方法对可枚举和不可枚举的槽位分别采用第一种和第二种解码方式,从而同时保证了对话状态跟踪的准确率、实用性和开放性。
参考文献
[1] Henderson M, Thomson B, Williams JD. The second dialog state tracking challenge[C]//Proceedings of the 15th annual meeting of the special interest group on discourse and dialogue (SIGDIAL) 2014 Jun (pp. 263-272).
[2] Wen TH, Vandyke D, Mrkšić N, et al. A Network-based End-to-End Trainable Task-oriented Dialogue System[C]//Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers 2017 Apr (pp. 438-449).
[3] Budzianowski P, Wen TH, Tseng BH, et al. MultiWOZ-A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing 2018 (pp. 5016-5026).
[4] Zhu Q, Huang K, Zhang Z, et al. CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset[J]. Transactions of the Association for Computational Linguistics. 2020;8:281-95.
[5] Henderson M, Thomson B, Young S. Deep neural network approach for the dialog state tracking challenge[C]//Proceedings of the SIGDIAL 2013 Conference 2013 Aug (pp. 467-471).
[6] Mrkšić N, Séaghdha DÓ, Thomson B, et al. Multi-domain Dialog State Tracking using Recurrent Neural Networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) 2015 Jul (pp. 794-799).
[7] Mrkšić N, Séaghdha DÓ, Wen TH, et al. Neural Belief Tracker: Data-Driven Dialogue State Tracking[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 2017 Jul (pp. 1777-1788).
[8] Wu CS, Madotto A, Hosseini-Asl E, et al. Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics 2019 Jul (pp. 808-819).
[9] Shan Y, Li Z, Zhang J, et al. A Contextual Hierarchical Attention Network with Adaptive Objective for Dialogue State Tracking[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 2020 Jul (pp. 6322-6333).
[10] Zhu S, Li J, Chen L, et al. Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings 2020 Nov (pp. 766-781).
[11] Chen L, Lv B, Wang C, et al. Schema-guided multi-domain dialogue state tracking with graph attention neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence 2020 Apr 3 (Vol. 34, No. 05, pp. 7521-7528).
[12] Hu J, Yang Y, Chen C, et al. SAS: Dialogue state tracking via slot attention and slot information sharing[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 2020 Jul (pp. 6366-6375).
[13] Ye F, Manotumruksa J, Zhang Q, et al. Slot Self-Attentive Dialogue State Tracking[J]. arXiv preprint arXiv:2101.09374. 2021 Jan 22.
[14] Kim S, Yang S, Kim G, et al. Efficient Dialogue State Tracking by Selectively Overwriting Memory[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics 2020 Jul (pp. 567-582).
[15] Lin Z, Madotto A, Winata GI, et al. MinTL: Minimalist Transfer Learning for Task-Oriented Dialogue Systems[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) 2020 Nov (pp. 3391-3405).
[16] Gao S, Sethi A, Agarwal S, et al. Dialog State Tracking: A Neural Reading Comprehension Approach[C]//20th Annual Meeting of the Special Interest Group on Discourse and Dialogue 2019 Sep 11 (p. 264)
本期责任编辑:赵森栋


