我和欧阳娜娜一起搞研发
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
AI新闻播报,开车明星导航,现如今根据文本生成语音的AI技术,那真是飞入寻常百姓家——见怪不怪了。
在这档口,作为这背后AI语音合成技术的研发人员,除了常规收集语音数据、训练模型、优化模型……
还能玩出什么花儿来?

……跟欧阳娜娜一起搞研发,算不算?(误)
“公费追星”是一种怎样的体验
故事要从一个不太普通的周一上午说起。
一大早,网易有道的语音工程师刘银,就跟同事们一起搭上了飞往上海的飞机。
之所以说不普通,是因为这趟出差不仅有工作任务,还寄托了前方后方一众工程师们的一点小期待。

这是有道词典明星语音二期项目的第一个阶段——训练数据录制。
去年9月,有道词典上线了王源的明星语音,成为学习领域第一个上线该功能的产品,大受用户好评。于是在进一步打磨模型之后,他们打算趁热打铁,上线新的女声明星语音。
而音源,正是刘银和同事们这次要近距离接触交流的欧阳娜娜。
对于这样的出差机会,刘银镇守本部的同事们直言:“羡慕坏了。这哪是出差,根本就是粉丝见面会。”
但其实对于刘银来说,兴奋之余,也并非没有压力。
在有道词典的明星语音功能中,熟悉的明星声音能为你读出每一个单词、每一个例句,就像这样:
很显然,他们本身不可能完整地去录制全部的语音。
甚至因为时间成本的关系,最后能真正喂给TTS(语音合成)模型的源语音也非常有限:几个小时的录音,最后能用的可能只有一小部分。
要用极少的数据,最终合成出高质量的语音,从采集训练数据开始,就要做到严格的把控。
有道的工程师们为此做了两手准备。
一方面,结合一期项目的经验,不录单词,只录简单的短句,在有限时间内尽可能多地收集原始数据。
另一方面,就要靠刘银等人跟欧阳娜娜的临场交流,需要他们以技术人员的视角来“导演”录音过程,和欧阳娜娜本人打出配合,以录出可用性更高的语音数据。

所以这场“粉丝见面会”,还仅仅是一个开始。
如何把欧阳娜娜的声音装进有道词典里
虽然已经有过一次上线王源语音的经验,但在训练模型这个环节,包括刘银在内的有道AI语音团队4人小组,还是花费了2周多的时间在模型的调整上。
主要的原因在于,单词和句子所需要的语音合成效果不同,在建模方面需要分别进行调整。
同时,针对模型本身,有道的工程师们进行了多次对比实验,包括经典的基于注意力的Tacotron2模型,业内最新的Non-Attention架构等,以期实现最接近欧阳娜娜本人声音质感,同时发音准确、地道的合成效果。

例句级别:基于注意力的Tacotron模型
具体而言,在例句级别,工程师们采用了基于注意力的Tacotron模型。
Tacotron模型使用的是经典的Seq2Seq架构,通过注意力机制来解决编码器和解码器长度不一致的问题。
原始的Tacotron使用了Location Sensitive Attention。这种注意力机制的问题在于,不够鲁棒,且收敛速度较慢,尤其是在面对数据量较少的情况时,缺点尤为明显。其原因主要在于,没有充分利用声学模型的单调性这一特点。
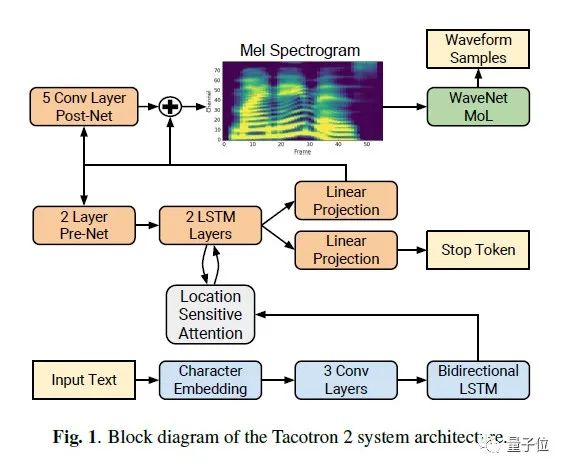
对此,有道工程师采用了改进版的Foward Attention,来替换Location Sensitive Attention,同时对注意力对齐矩阵进行损失约束,以提升模型的稳定性和收敛速度。

另外,基础的Tacotron建模方案在某些发音(如低频发音)上效果不够好。为此,工程师们还采用了ASR(语音识别)来打辅助。
通过ASR的辅助建模,合成的句子语音可懂性更强,准确性和韵律方面也有所提升,可以解决在纯TTS方案中,有一些音发不出来的问题。
单词级别:基于时长模型的Tacotron模型
再说说单词方面。
前面也提到,为了节省时间成本,有道工程师们拿到的训练数据都是短句,没有单词。
这就导致在采用上述用于例句的TTS方案时,合成的单词读音在韵律感和音调上会出现一定问题,比如对于单音节或双音节单词,出现重复发音、漏音、语速过快等情形。
为此,有道工程师们尝试了业内最新模型架构Non-Attentive Tacotron,通过时长模型来替代注意力计算模块。
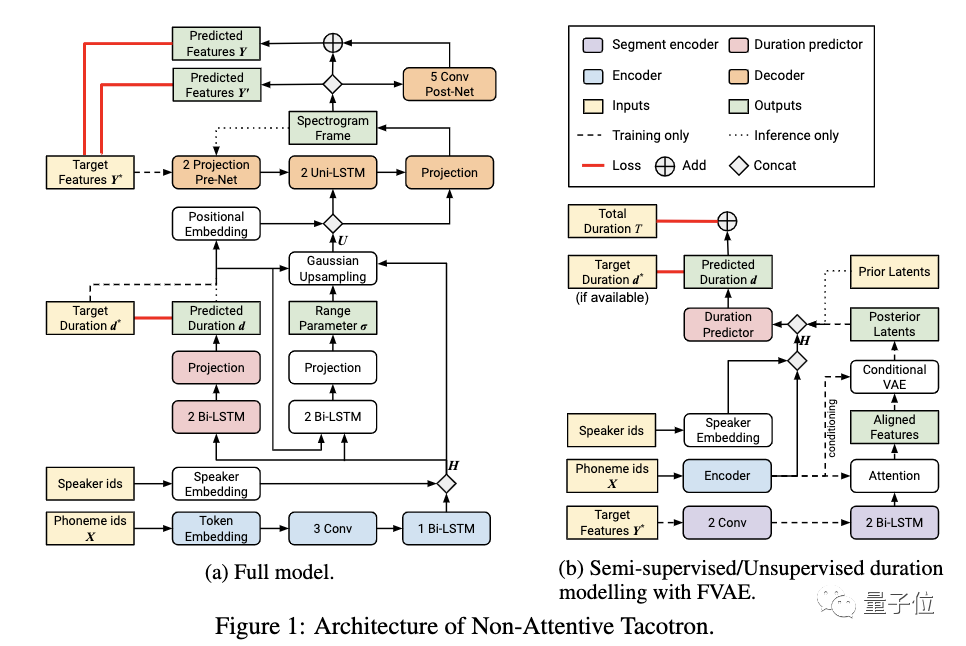
这样做的好处是,基于时长的模型可以显式地调节每一个音素的发音时长,让合成出来的单词读音更接近真人朗读的效果。
同时,Non-Attentive模型在保持模型稳定性方面也更具优势。
而除了模型方面的精挑细选、精细打磨,值得一提的是,网易有道AI语音算法团队此次的新明星语音新增了大量高采样率的英文女声数据,将采样率从16K提升到了24K,这就让合成语音在音质、听感和真实性方面有了进一步的提升。
至于最终的效果如何评价,请听——
私以为是欧阳娜娜本娜没错了。
“做产品是严肃的,但技术允许试错”
从项目启动到最终上线,此次有道词典的明星语音功能升级项目,整个研发周期大概持续了一个月的时间。
时间上看还是有点紧张,但对于研发小组的成员们来说,对于项目的兴奋感远远超过了追赶deadline带来的焦虑。
原因很简单——几个人都是根据兴趣自愿加入到项目当中的。

△网易有道AI语音团队
除了刘银,小组中其余几人的主要技术栈都不是语音合成。
比如主要负责例句模型的王晓强,日常更多承担的是语音识别方向的研发工作——这与语音合成几乎可以说是一个完全相反的方向。
甚至有一位同学,此前的学习、工作内容与深度学习完全不相关,而是传统的声学前端方向。
毕业前,曾在多家公司有过实习经历的王晓强坦言:
这种允许跨领域的技术文化,其实是很少见的。
对于网易有道AI本身,这样的包容度也着实可以贴上“大胆”的标签。
要知道,作为一款家喻户晓的查词工具,有道词典是网易有道用户量规模最大的产品,哪怕是一个微小功能的改动都需要严肃对待,更不必说像明星语音这样重要的功能更新。

但实际上,这样的包容和信任,反而给了刘银、王晓强等人更大的动力——自己选择承担的任务,就一定要做好。
从另一个层面来看,允许研发人员跨领域进行技术交流,并实际操作落地,也促成了整个技术团队的成长——不把技术视野局限在自己的一亩三分地,在思考问题时,反而更容易激发创新的火花。
还有重要的一点是:
在自己感兴趣的领域,有技术大佬带着飞,不仅不用交学费,甚至还有工资拿,这真是太开心了。
如果跟网易有道AI语音算法工程师们多聊一聊,就会发现,这支技术团队总是能把研发做成一件既靠谱又欢乐的事。
他们大都很年轻,思维活跃,性格跳脱,也更勇于创新和尝试。但同时,从学校到职场,从旧环境到新环境,他们又能用理工科的理性思维,快速地认识到应该“做什么”、“怎么做”。
这也反映在了一个个受到用户好评的语音功能上:能够自动进行语言检测的语音翻译功能、英语跟读打分、明星语音……
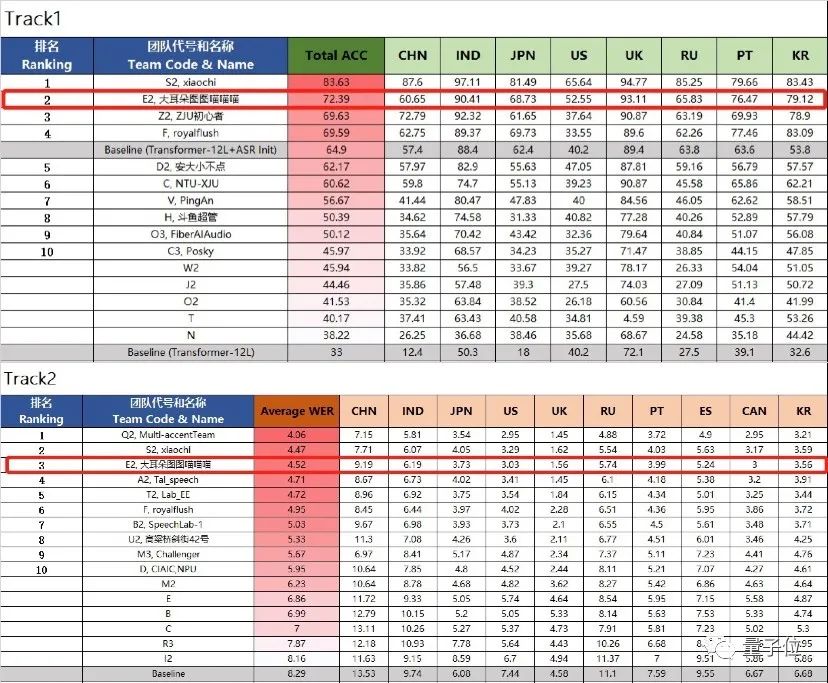
并且,他们还“上得了厅堂,下得了厨房”。不仅能在产品层面持续推动技术落地,学术、比赛成绩也拿得出手。比如去年,他们就曾在全球语音顶会INTERSPEECH 2020“口音英语语音识别挑战赛”上名列前茅。
这样的个人成长,背后也反映了网易有道对人才的重视。
有道AI语音团队负责人李庆辉就表示,一个脚踏实地的团队,应该给每个人充分的才华施展空间,而在这个空间之下,大家可以潜心钻研技术,在专注于自己侧重点的情况下,去突破个人的局限。
而当个人的能力不断突破进步,团队本身也就自然而然会成长起来。
人才,就是公司、团队最大的财富。
(应要求,文中所列人员均为化名)
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
点这里👇关注我,记得标星,么么哒~
加入AI社群,拓展你的AI行业人脉

一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~





