【动态】 “人工智能安全与隐私”系列论坛第12期圆满落幕
4月7日,由中国图象图形学学会、深圳市大数据研究院主办,中国图象图形学学会视觉大数据专业委员会承办,香港中文大学(深圳)广东省大数据计算基础理论与方法重点实验室、腾讯研究院协办的“人工智能安全与隐私”系列论坛第十二期圆满落下帷幕。此次论坛由中国科学院自动化研究所副研究员梁坚主持,密歇根州立大学的汤继良教授作为主讲嘉宾,围绕可信人工智能的鲁棒性和公平性展开了详细的讨论。
直播录像请见:
https://www.bilibili.com/video/BV1Kr4y1p7A8
(点击文末阅读原文可跳转至链接)

本次论坛采用哔哩哔哩线上直播以及腾讯研究院视频号直播形式,梁坚副研究员回顾了论坛的创建历程,并对论坛举办过程中得到的众多组织、专家的支持表示了诚挚的感谢。在梁坚副研究员的主持下,"人工智能安全与隐私"系列论坛第十二期于4月7日上午10:00正式拉开帷幕。
讲座内容
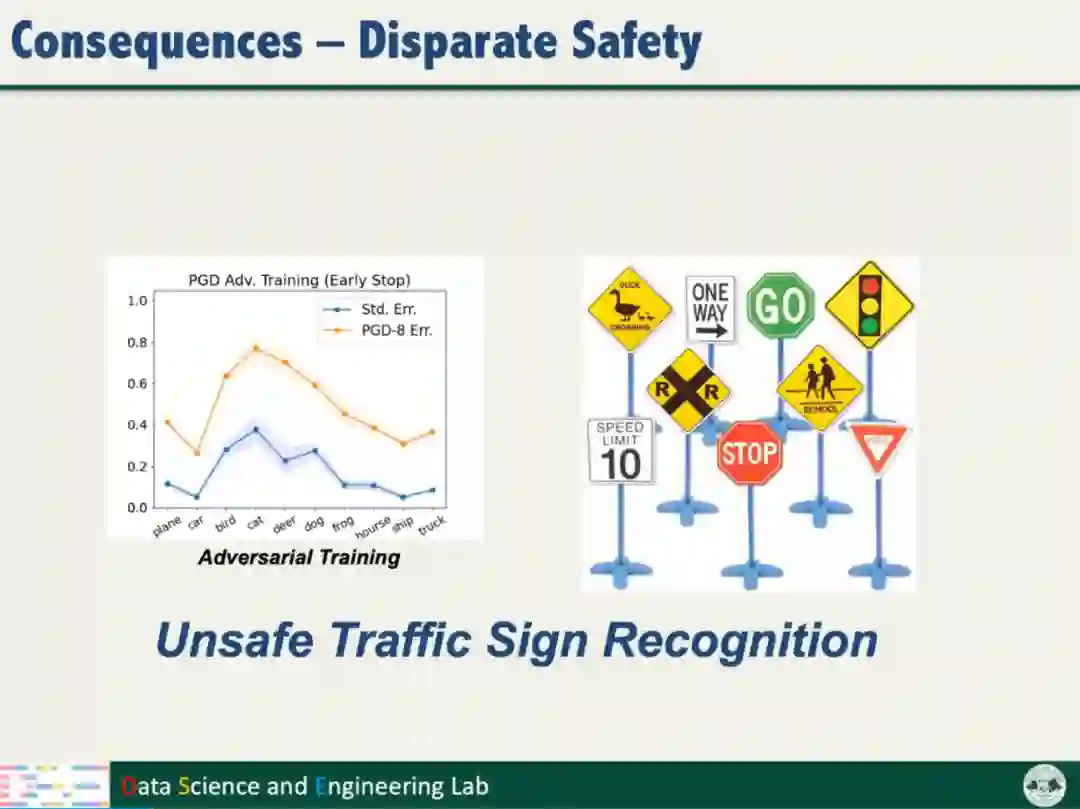
目前,人工智能已经取得了重大的突破,成为人脸识别、医疗诊断和自动驾驶等领域的重要技术。然而人工智能存在模型鲁棒性较弱的问题,容易被对抗样本攻击,导致准确性和安全性下降。例如物理世界的对抗样本攻击,在交通标识粘贴对抗扰动的图案,使自动驾驶汽车错误识别标识,给道路交通带来了严重的安全威胁。

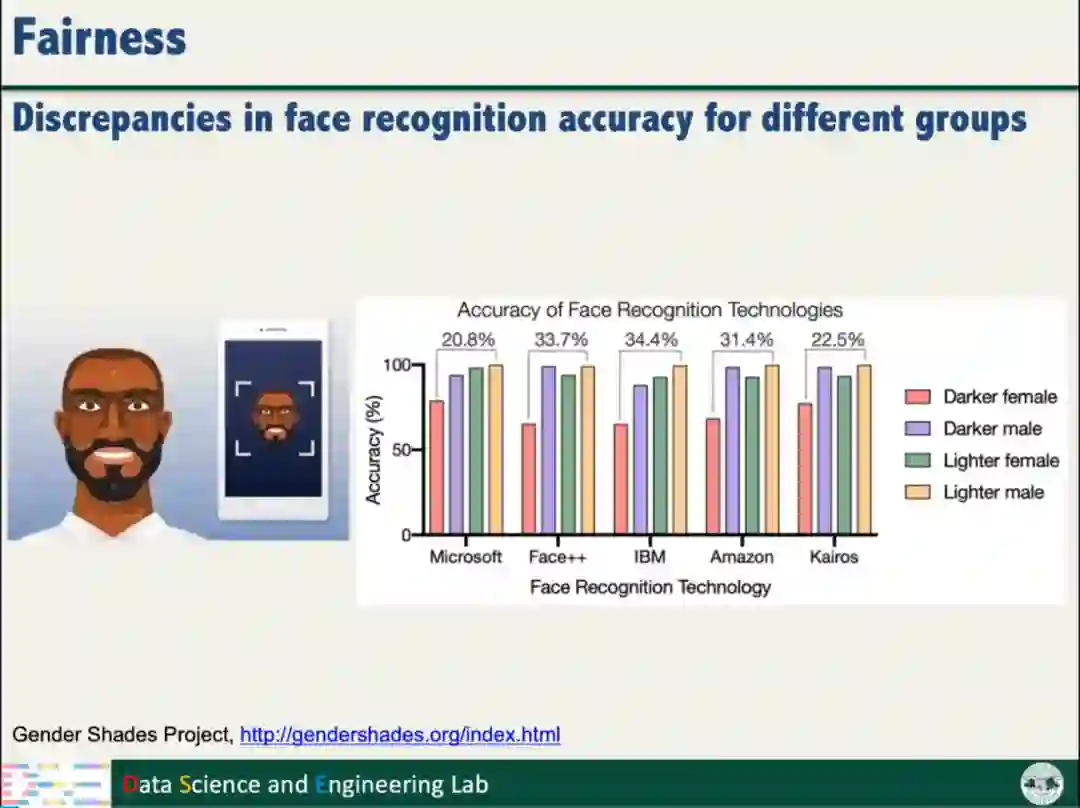
汤继良教授指出,人工智能系统不仅鲁棒性较差,而且存在一定的偏见,可能因为用户的性别、种族、年龄和收入等因素的不同,做出不同的决策结果。以人脸识别系统为例,白人的识别准确率比黑人高,男性的识别准确率比女性高。
人工智能模型的鲁棒性和公平性同等重要,缺乏任意一项都不能真正实现可信的人工智能。如何兼得模型的鲁棒性和公平性?对此,汤教授把上述问题分解为两个具体的研究问题:
(一)增强模型的鲁棒性后,模型是否存在不公平的表现?
(二)提高模型的公平性后,模型的鲁棒性是否发生改变?

01| 对抗训练与模型的公平性
首先回顾对抗攻击和对抗防御。对抗攻击向数据样本添加扰动噪声,形成对抗样本,使得模型的分类误差最大化。为了防御对抗攻击,对抗训练是最常用的方法,旨在最小化模型在对抗样本的分类损失。

汤教授发现,对抗训练增强模型鲁棒性的同时产生了不公平的问题,即对抗训练对不同类别数据的鲁棒性增益不同,且类别之间的增益差异较大。模型的不公平对智能系统安全和社会伦理带来了潜在的威胁。因此,需要解决以上问题,保障模型鲁棒性的同时不损害模型的公平性。
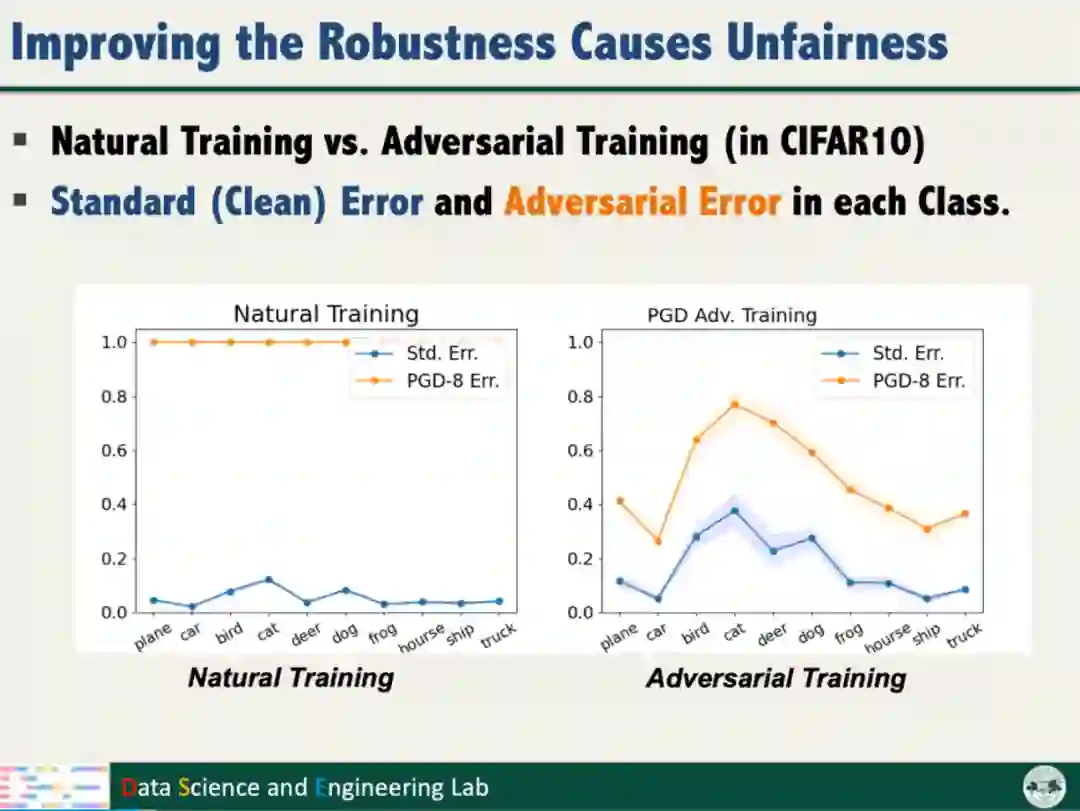

为了探究对抗训练产生不公平性的原因,汤教授从理论层面开展了分析。
首先从两个高斯分布中分别采样获取“容易”和“困难”的样本,由此训练得到的线性判别超平面,距离“容易”样本更近。

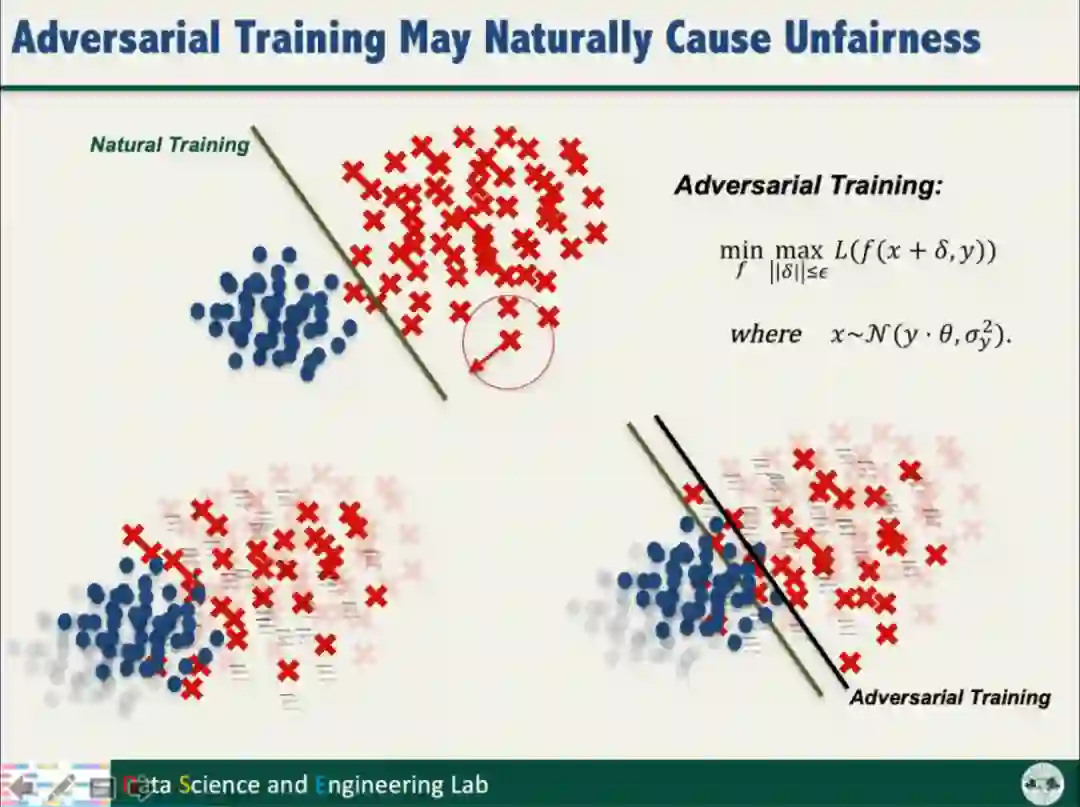

以上分析结果表明,对抗训练产生的不公平性是对抗训练本身一种的属性,与数据集或模型无关。
为了获得公平的模型鲁棒性,汤教授提出了一种动态训练框架,包括两种强化模型公平性的策略:
(1)针对表现较差的类别,提高训练的损失权重,使模型重点关注这些类别的数据样本;
(2)增大困难和容易样本之间的距离,缓解不公平问题

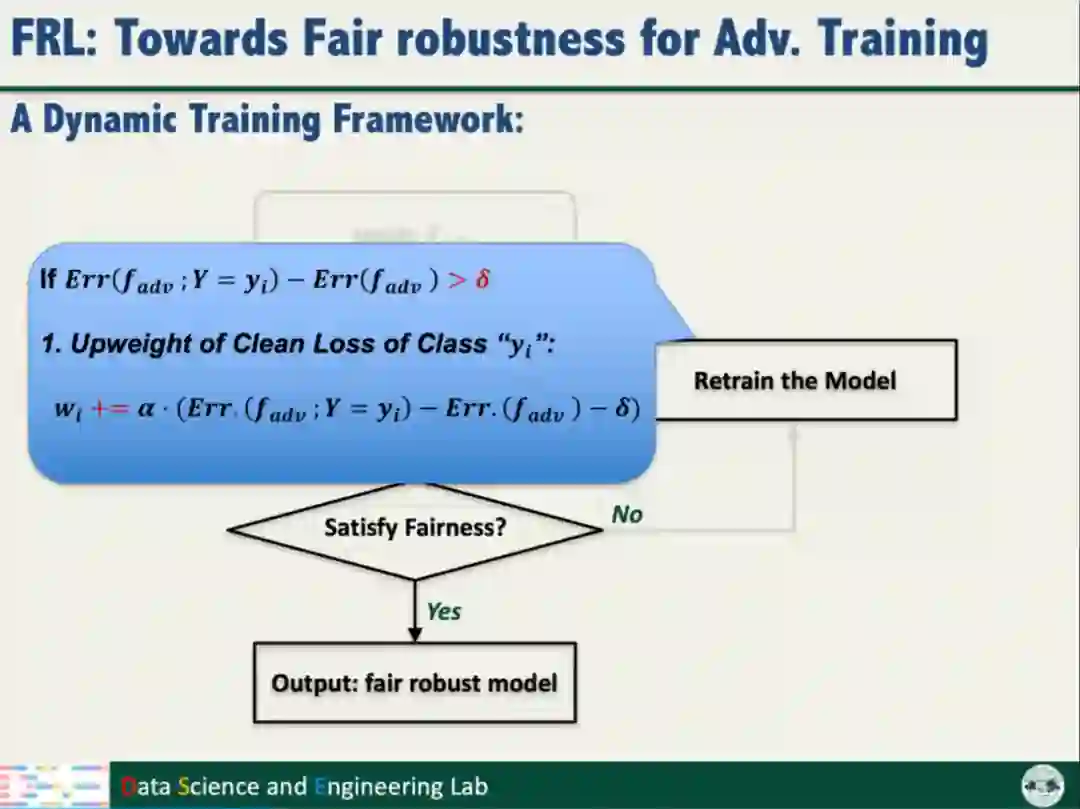

02| 公平性训练与模型的鲁棒性
公平性训练:模型不仅需要减少分类误差,还需要减少不同类别间的分类准确率差异。

为了探究公平性训练是否降低模型鲁棒性,汤教授开展了投毒攻击对模型公平性的研究。投毒攻击的目标是产生满足公平性约束的有毒数据样本,最大化模型对干净样本的分类损失。

投毒攻击的原始目标函数较难优化,通过进一步简化,得到常见的Min-Max的优化目标函数。



首先,为了评估公平性训练对鲁棒性的影响,汤教授在二维合成数据上开展了实验验证,该合成数据存在不公平问题。
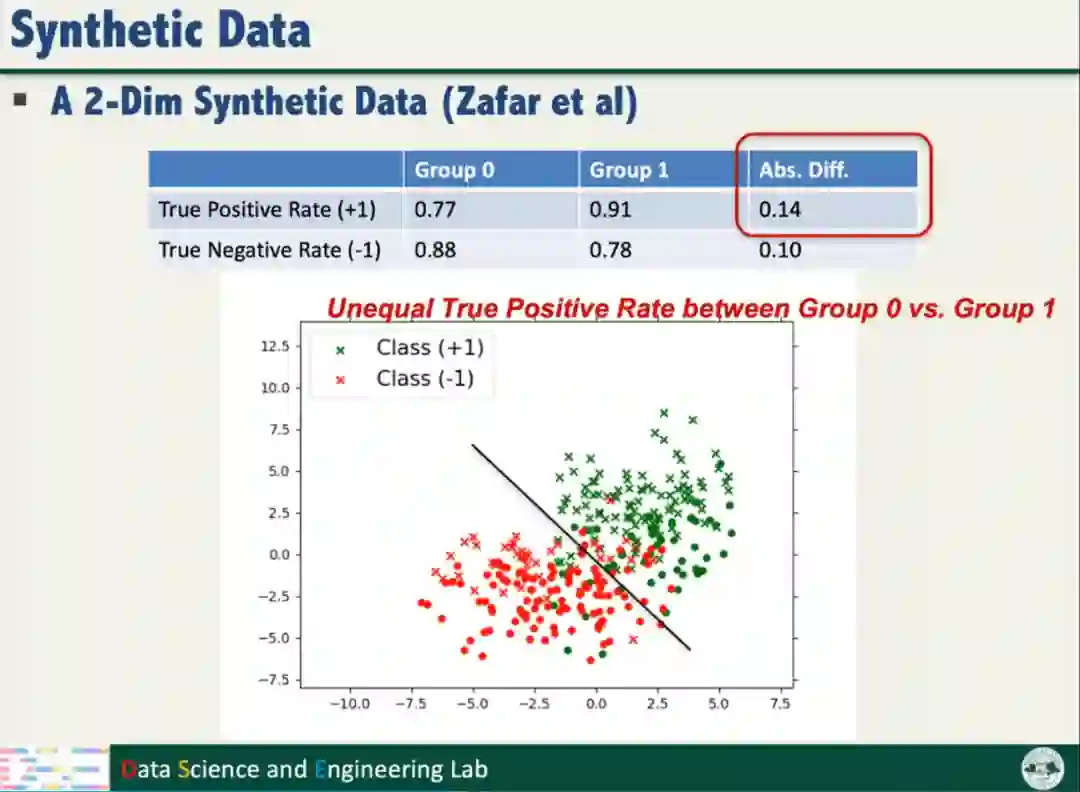
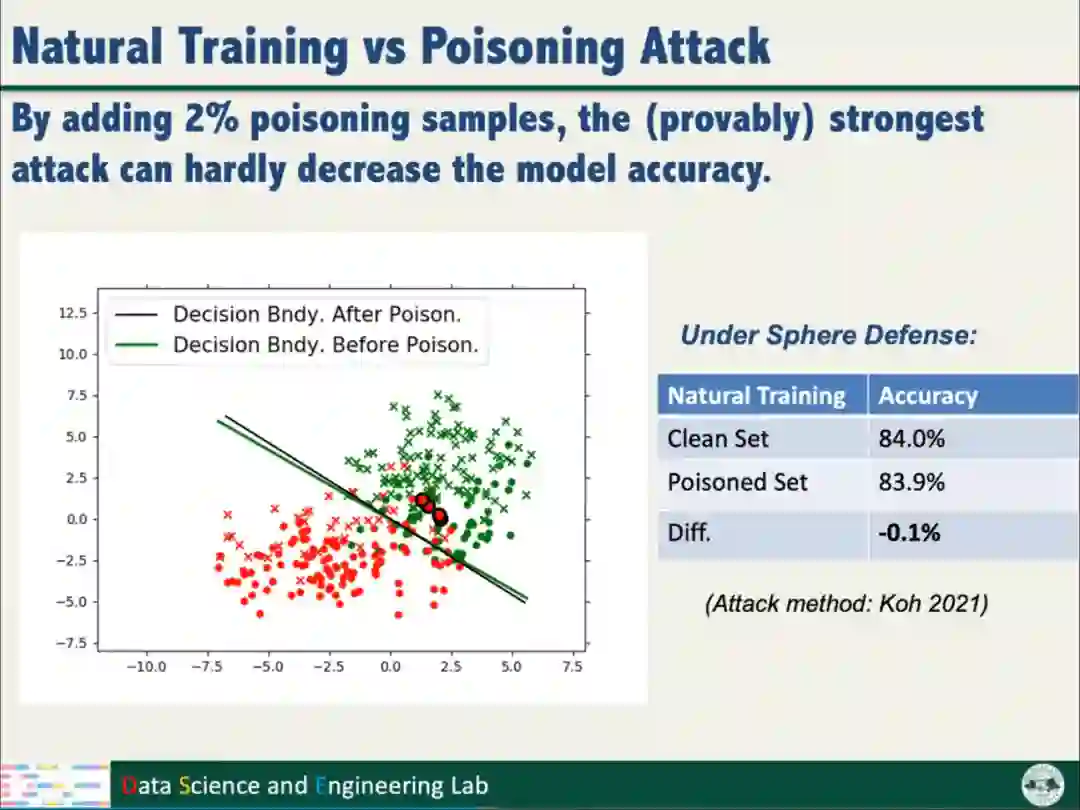
向数据添加2%的投毒数据样本后,采用Sphere Defense防御方法,以Natural training方式训练模型,模型的准确率几乎不变;以Fairness training方式训练模型,判别超平面发生明显的变化,模型的准确率也明显下降。实验表明公平性训练使模型面对攻击变得更加脆弱,需要新的防御策略。
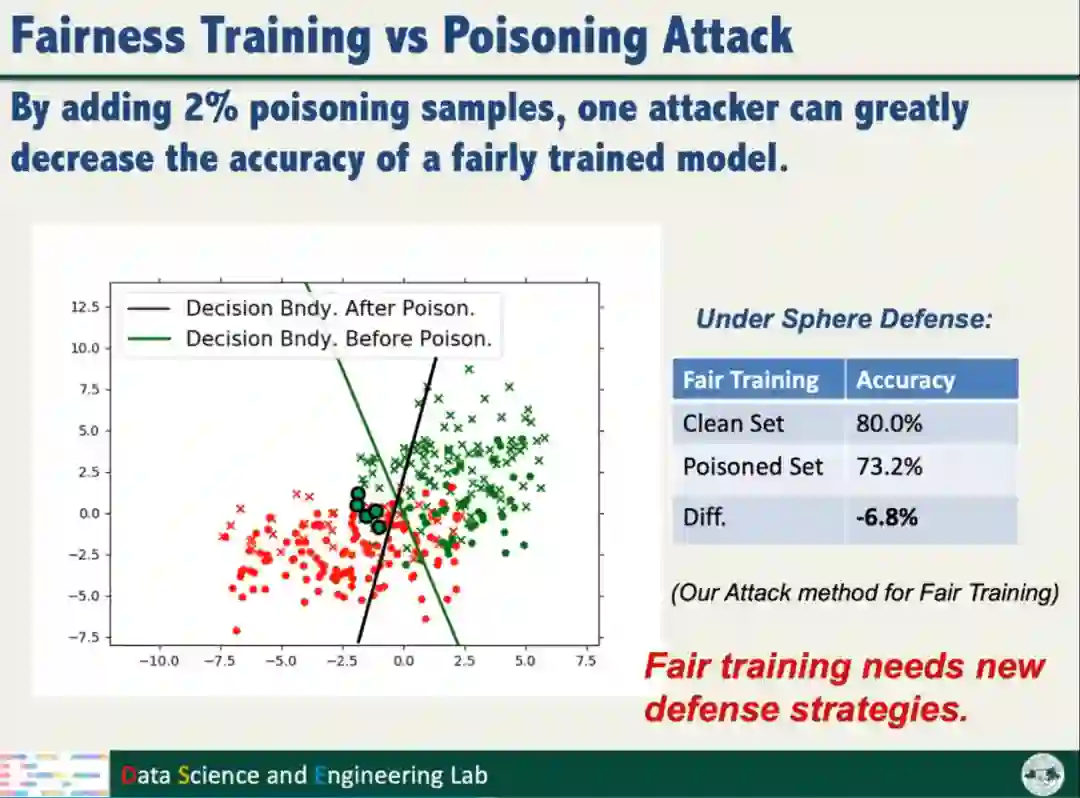
根据以上的分析结果,汤教授提出了公平鲁棒分类算法(Fair Robust Classification,简称RFC)。RFC将分类问题转化为多标签问题,通过训练额外模型,不仅考虑数据标签,还要考虑数据的Sensitive信息;对防御方法(如Sphere Defense和SEVER)进行适配改进。

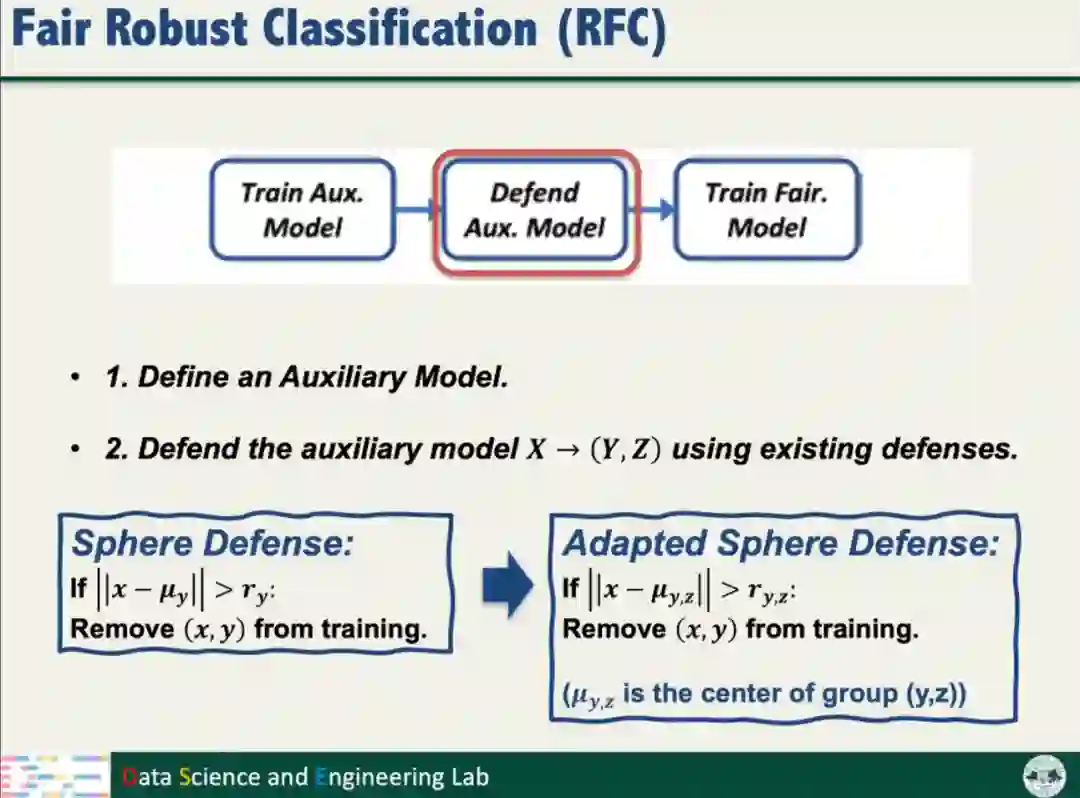

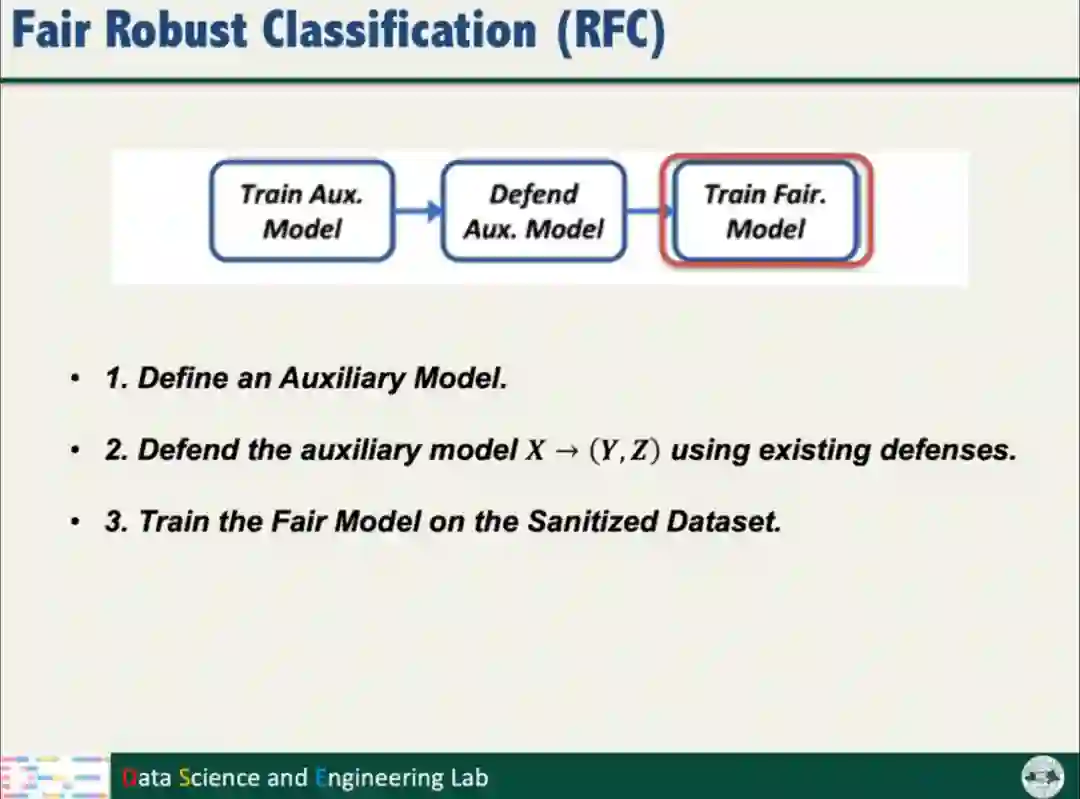
汤教授进一步从理论上证明,RFC添加的额外模型不会明显降低模型的性能和鲁棒性,确保额外模型没有带来新的风险。

综上,汤教授针对鲁棒性和公平性的研究问题,总结了两点结论:
1、提高模型鲁棒性的时候,可能会引起公平性的问题;
2、公平性训练可能会导致模型的鲁棒性下降。

03| 模型鲁棒性的未来展望
汤教授指出:
1、目前的鲁棒性还没有达到可信智能系统的要求。第一方面是提高模型鲁棒性可能会影响模型的性能,需要在二者之间权衡。第二方面是攻击和防御是一场无休止的竞赛,二者互相博弈。第三方面是鲁棒性具有多个种类,如对抗扰动的鲁棒性和噪声的鲁棒性等。
2、除了增强模型的鲁棒性,将数据变换为低脆弱性的形式,从根源上解决鲁棒的问题,同样可以获得鲁棒的人工智能。
3、现有的神经网络存在鲁棒性较差的问题,如何设计自身鲁棒的模型是近年关注的一个研究问题,目标是既增强模型鲁棒性,也不影响模型在干净数据样本的性能。
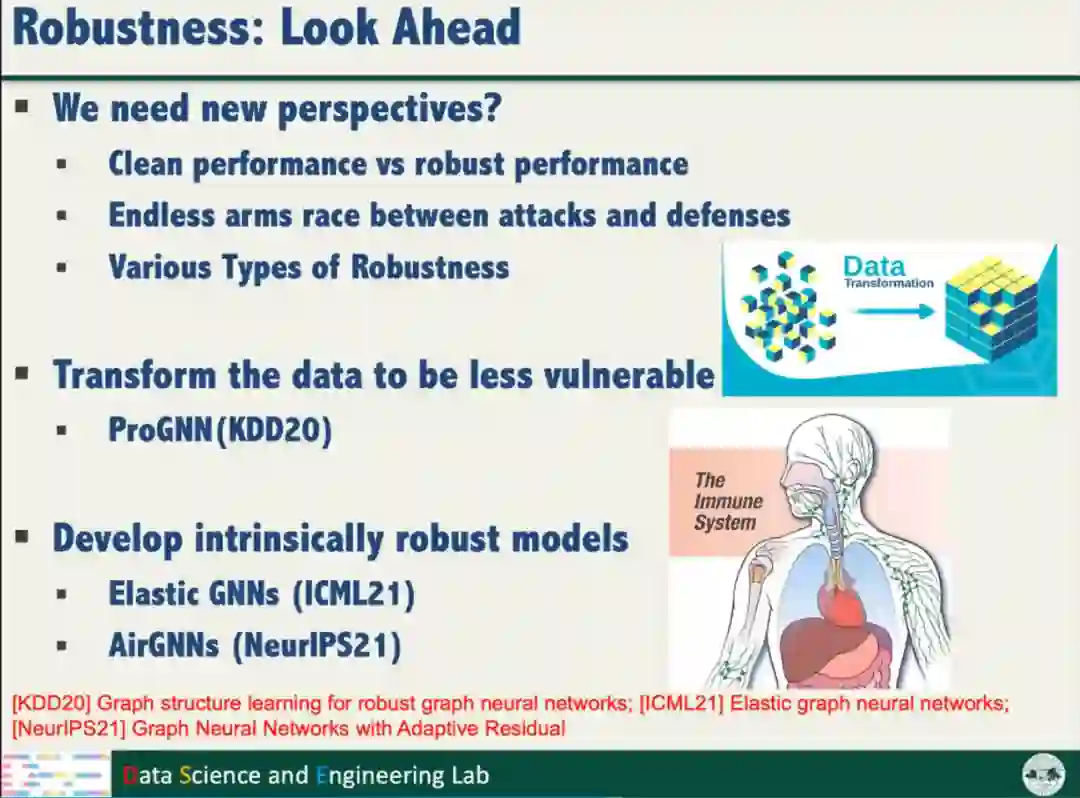
在图神经网络的鲁棒性方面,汤教授开展了一些研究工作。
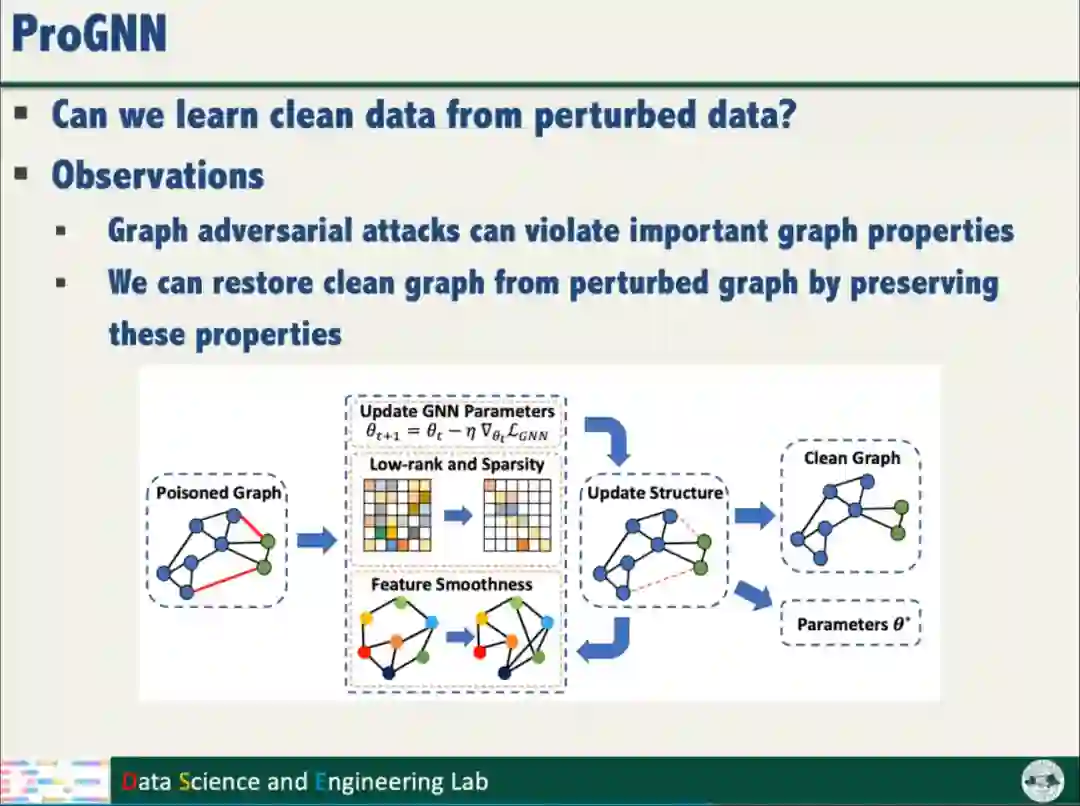
针对数据鲁棒性,汤教授提出了ProGNN,利用图邻接矩阵的低秩和稀疏特性,利用相邻结点的特征平滑特点,从被扰动的数据恢复干净的样本,实现数据的鲁棒性。
针对图神经网络的鲁棒性,汤教授发现L2正则化是模型鲁棒性差的原因之一,改用L1正则化即可增强模型自身的鲁棒性,取得了先进的鲁棒性能。

最后,汤教授表示,可信的人工智能应当在多方面均可信任,包括鲁棒性、公平性、可解释性和隐私保护等,各个方面之间存在相互关联,需要我们共同关注和深入研究。可信的人工智能是服务于人的,然而人工智能的可信任度和人的可信任度之间存在很大的差异,不仅需要计算机科学的算法研究,还需要系统、人类与社会等多方的共同努力,才能推进可信人工智能的发展。

问答环节
Q1
在研究对抗训练的过程中产生公平性的问题,请问做这个问题的动机是什么呢?在整个实验过程中,有没有发现算法的公平性和数据库有没有依赖性,或者是和某种对抗训练的方法产生依赖性,还是这是一种比较通用的现象?
汤教授:研究团队近年才开始关于模型鲁棒性的研究,最初对现有的对抗训练方法做一些实验,然后发现了不公平性的问题。对于不公平性会不会对数据或者是模型有一些依赖性的担忧,我们的研究工作提供了理论性的证明,说明了对于公平性和鲁棒性的问题,确实是对抗训练自身存在的问题。
Q2
之前有看到一些自监督模型可以提高标签分布不均衡等问题的鲁棒性,有没有考虑到这样的学习机制与公平性鲁棒性研究的结合?
汤教授:已有相关工作用自监督的方式提高模型的鲁棒性,至于其对公平性的帮助可以在之后的工作中进行研究再与大家分享。
Q3
改善对抗训练中公平性的方法是在对抗训练完成之后的,有没有在对抗训练中考虑这个问题?
汤教授:研究团队提出的算法框架就是在解决这样的问题,只不过用了验证集进行公平性的一个验证,这个在公平性的训练中是普遍的一个方式。此外,我们也尝试过将正则化或者公平性约束(Fairness Constraint)加到对抗训练中,也验证过其他的公平性约束方式,比如使用Group-level和Individual-level的方式。目前仍在研究的过程中,如果有新的进展将会向大家汇报。
Q4
鲁棒性和公平性中的trade off是怎么平衡的呢?
汤教授:系统的安全性存在一个共识:系统的安全性是由他的短板所决定的。比如自动驾驶的路标识别中,整个识别系统的安全性是由识别效果最差的路标所决定的。当然在针对不同的应用时敏感性是不一样的,针对不同的人群时也是不一样的。在现实社会中我们考虑安全性也是需要考虑人类对待此问题的理解。比如在美国种族平等是一个比较敏感的问题,如果黑人与白人之间的公平性差异达到0.5%,可能就产生很大的影响,但在亚洲的影响则可能相对较小。总体而言,公平性需要结合社会学和心理学,在不同地域和不同应用的决策都是不一样的。
Q5
当前公平性研究面临最大的困难挑战是什么?
汤教授:我对公平性的研究可能还不够深入,但以自己的理解来说,公平性确实还存在一些问题,比如公平性的影响在整个机器学习的流程中都是存在的,在数据标注时不同的教育背景和性别可能影响数据标注结果,在数据分布中也会引入公平性的问题,模型本身也会存在一定偏差,这些都是需要进一步研究的。另外,目前模型公平性仍未有十分明确的定义,需要进一步探讨研究。
Q6
目前有一大类做公平性的工作是从数据预处理的角度出发的,在数据层面上消除一些敏感信息,汤教授在这个层面有做过一些鲁棒性的研究吗?
汤教授:目前很多问题是由数据的分布影响的,数据中存在一些不平衡的现象。例如黑人的人脸识别准确率比白人低是训练样本中黑人样本少所导致的,这种问题可以通过数据预处理来消除。如同之前所讲的公平性训练,有一类方法会对数据做预处理或后处理,研究团队也做过该方法的鲁棒性研究,包括对抗样本的检测等。我们发现在样本不平衡的情况下,同样存在简单的样本变得更简单,困难的变得更难的现象。
Q7
目前对GNN的攻击, 修改图结构和修改节点特征这两种方式哪种更有效或者哪种更实际一些。
汤教授:相比于图像层面的对抗攻击与防御,图有更多的方式实现攻击,可以攻击图结构、节点的特征等。实际上,同时攻击图结构和节点特征的效果会更好。GNN存在一个假设,即相邻节点之间的特征是相似的。至于哪一种方法更好也要考虑GNN的假设,可能修改图结构会取得更好的效果,因为结点上的改变是通过平滑策略来消除影响的。



