多语言识别的实现
文 / Arindrima Datta 和 Anjuli Kannan
软件工程师,Google Research

Google 的使命不单单是整合全球信息,而是要让 大众 能够使用这些信息,这意味着我们需要为尽可能多的语言提供我们的产品。而 Google 助理的核心功能是理解人类语言,这需要支持多种语言,也是我们面临的一大挑战:越是优质的自动语音识别 (Automatic Speech Recognition, ASR) 系统越需要大量视频及文本数据等内容,以便让数据需求型神经模型不断革新。然而,许多语言的可用数据几近为零。
我们一直在思考应当如何保证高质量的语音识别,尤其是语料数据稀缺的语言。研究社区近期的一个重要发现表明,神经网络可以从语料丰富型语言的音频数据中学到的大部分“知识” 并应用在语料稀缺型语言上,因此我们无需从头学习所有内容。由此,我们开始了多语言语音识别模型的研究,其中便包含多种语言的学习转录单一模型。
在发表于 Interspeech 2019 的 “基于流式传输端到端模型的大规模多语言语音识别” 一文中,我们曾提出了单一模型训练的端到端 (End-to-End,E2E) 系统,支持实时多语言语音的识别。通过在九种印度语的应用,我们展示了在多个语料稀缺型语言上, ASR 显著质量提升,同时也持续改进该系统针对语料富型语言的表现。
注:Interspeech 2019
https://interspeech2019.org/
基于流式传输端到端模型的大规模多语言语音识别
https://arxiv.org/abs/1909.05330
印度:语言的国度
我们把此次研究的重点放在了印度。
自古以来,印度就是一个多语言社会,拥有 30 多种语言,以及至少一百万的英语母语使用者。由于这些语言所处的地理位置相近,且有相似的文化历史,所以其中许多语言在声学和词汇上有所重叠。此外,许多印度人会使用两到三种语言,因此在对话中使用多种语言是一种普遍现象,同时也是训练单个多语言模型的天选之地。
在这项工作中,我们结合了九种主要的印度语言的使用,即北印度语、马拉地语、乌尔都语、孟加拉语、泰米尔语、泰卢固语、坎纳达语、马拉雅拉姆语和古吉拉特语。
低延迟的全神经多语言模型
传统的 ASR 系统包括负责声学、发音和语言模型的独立组件。虽然已有人尝试将部分或所有传统的 ASR 组件变成多语言组件 [1、2、3、4],但这种方法有可能非常复杂,且难以规模化应用。E2E ASR 模型可将全部三种组件结合至单个神经网络中,并保证可扩展性及参数共享的易用性。
注:将三种组件结合至单个神经网络
https://ai.googleblog.com/2017/12/improving-end-to-end-models-for-speech.html
经过最近一段时间的努力,我们已将 E2E 模型扩展成多语言模型 [1、2],但这并不能解决实时语音识别的需求,而这恰恰是 Google 助理、语音搜索和 Gboard 听写等应用程序运行所需的关键。为此,我们将目光转向 Google 的最近研究,该项研究使用递归神经网络传感器 (Recurrent Neural Network Transduce,RNN-T) 模型来实现流式 E2E ASR。RNN-T 系统每次会以单个字符的形式来输出字词,就好似有人在实时打字一般,然而该系统并不支持多语言。我们在此架构的基础上,开发出用于多语言 语音识别的低延迟模型。
https://arxiv.org/pdf/1211.3711.pdf
最近研究
https://arxiv.org/abs/1811.06621
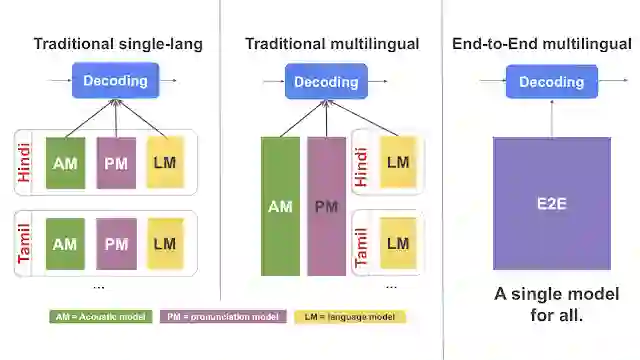
[左图]传统的单语言语音识别器,其中包括各种语言的声学、发音和语言模型 [中图]传统的多语言语音识别器,其中声学和发音模型可支持多语言,但是语言模型仅支持指定的语言 [右图] E2E 多语言语音识别器,我们已将其中的声学、发音和语言模型整合到单个多语言模型中
大规模数据带来的挑战
由于语料数据的不平衡,使用大规模的现实数据来训练多语言模型会变的非常复杂。考虑到各语言使用者分布的差异和语音产品的成熟度,很容易导致每种语言的可用转录数据量相差较大。因此,多语言模型在训练过程集中更易受到语料占比高的语言的影响。这类偏差在 E2E 模型中尤为突出,与传统的 ASR 不同,E2E 模型无需使用额外的语言类文本数据,而是只需从音频训练数据中学习语言的词汇特征即可。
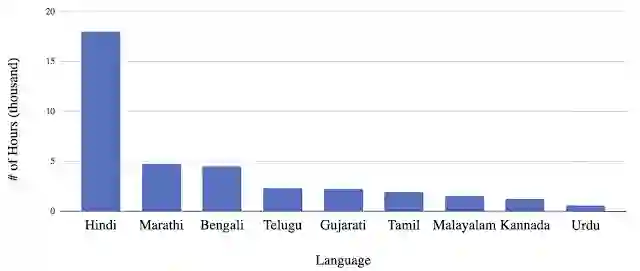
九种语言的训练数据直方图,表明可用数据之间的巨大差异
我们对架构作出一些调整进而解决此问题。首先,我们提供额外的语言标识符作为输入信息,该输入信息来源于训练数据语言区域中获取的外部信号,即个人手机上的语言偏好设置。系统会将该信号与音频输入相结合,使其成为 one-hot 特征向量。我们假定该模型不仅能使用语言向量消除语言间的歧义,还可以根据需要学习不同语言间的特点,这将有助于改善语料数据间的不平衡情况。
注:one-hot
https://www.kaggle.com/dansbecker/using-categorical-data-with-one-hot-encoding?
基于全局模型中使用不同表达方式来表示特定语言的想法,我们通过残差适配器模块的形式,为每种语言分配额外的参数,从而进一步扩充了网络架构。适配器对每种语言的全局模型作出微调,并可同时维护单个全局模型的参数效率,进而提升性能。
注:残差适配器模块
https://arxiv.org/abs/1705.08045
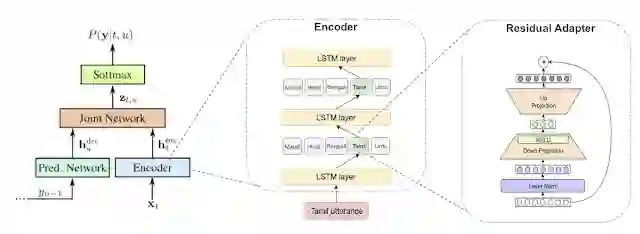
[左图] 带有语言标识符的多语言 RNN-T 架构 [中图] 编码器内部的残差适配器。如果输入泰米尔风格的语句,则只能使用泰米尔适配器来激活各个层级 [右图] 残差适配器模块的架构详图。如需了解更多详情,请参阅我们的论文
注:论文
https://arxiv.org/abs/1909.05330
在整合了全部元素的基础上,我们的多语言模型要优于所有单语言识别器,尤其是在坎纳达语和乌尔都语这类的语料稀缺型语言上有很大的提升。此外,由于该模型为流式 E2E 模型,简化了训练的过程与服务的提供,同时也适用于 Google 助理这样的低延迟应用程序中。至此,我们希望可以继续研究其他语系的多语言 ASR,以更好地为我们不断增长的多元用户提供帮助。
致谢
我们要感谢以下人士对研究作出的贡献:Tara N. Sainath、Eugene Weinstein、Bo Li、Shubham Toshniwal、Ron Weiss、Bhuvana Ramabhadran、Yonghui Wu、Ankur Bapna、Zhifeng Chen、Seungji Lee、Meysam Bastani、Mikaela Grace、Pedro Moreno、Yanzhang (Ryan) He 和 Khe Chai Sim。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
多语言研究[1]
(https://ieeexplore.ieee.org/document/6639084)多语言研究[2]
(https://www.merl.com/publications/docs/TR2017-182.pdf)多语言研究[3]
(https://arxiv.org/abs/1811.03451)多语言研究[4]
(https://ieeexplore.ieee.org/document/7404803)多语言模型[1]
(https://arxiv.org/abs/1712.01541)多语言模型[2]
(https://arxiv.org/abs/1711.01694)语音搜索
(https://support.google.com/websearch/answer/2940021?co=GENIE.Platform%3DAndroid&hl=en)Gboard 听写
(https://support.google.com/gboard/answer/2781851?co=GENIE.Platform%3DAndroid&hl=en)
更多 AI 相关阅读: