世界模型:代理能在自己的梦中学习吗?(下)
编者按:Google Brain hardmaru和IDSIA Jürgen Schmidhuber的新作。探索了为流行的强化学习环境构建生成式神经网络模型。其世界模型(world model)可以通过无监督方式快速训练,以学习一个压缩的环境的时空表示。使用提取自世界模型的特征作为代理的输入,训练一个非常紧凑和简单的策略解决所需任务。甚至可以让代理完全在自己的幻梦(由世界模型生成)中训练,然后迁移策略至实际环境。
论文网站(包含互动交互Demo):https://worldmodels.github.io/
论文PDF: https://arxiv.org/abs/1803.10122
VizDoom实验:梦中学习
如果我们的世界模型对于它的目的而言足够精确,对于手头的问题而言足够完整,那么我们应该能够用世界模型替换真实环境。毕竟我们的代理并不直接观测现实,而只能看到世界模型让它看到的东西。在这一实验中,我们在幻觉中训练代理,该幻觉是由代理的世界模型生成的。我们训练该世界模型模拟VizDoom环境。
代理学习躲避房间另一侧怪兽发射的火球。这一环境没有显式的奖励,所以,演化奖励可以定义为代理存活的时间。每次游戏的最大时长为2100帧(约60秒),在100次连续游戏中,平均存活时间超过750帧(约20秒),视为解决该问题。
除了一些关键的差别,我们的VizDoom实验大致上和赛车任务差不多。在赛车任务中,M只建模下一个zt,而VizDoom实验网速,M模型在预测zt之外,还预测代理是否死于下一帧(二元事件donet)。
在幻想过程中,我们不需要V模型编码任何真实像素场景,因此我们的代理完全在潜空间环境中训练。我们之后会讨论由此带来的好处。
虚拟环境和真实环境的接口一致,因此当代理在虚拟环境中学习到一个满意的策略后,我们可以很容易地将该策略部署回实际环境,看看策略的迁移效果如何。
模型参数数量

梦中训练
在一些训练之后,我们的控制者学习如何在梦中移动,如何在梦中躲避由M模型生成的怪兽发射的火球。我们的代理在这一虚拟环境中的成绩大约为900帧。
我们训练基于RNN的世界模型以模仿由人类程序员设计的完整游戏环境。仅仅通过取自随机片段的原始图像数据,世界模型学习如何模拟游戏的基本方面——例如游戏逻辑、敌人行为、物理、3D图像渲染。
例如,如果代理选择向左,那么M模型将学习移动代理至左方并相应地调整游戏状态的内部表示。它同时学习阻挡代理在任意一个方向移动得太远时穿墙。M模型偶尔需要留意由不同怪兽发射的多个火球的轨迹,连贯地让火球沿着各自的预设方向前进。它同时必须检测代理是否被火球杀死。
不过,和真实游戏环境不同,我们发现可以给虚拟环境增加额外的不确定性,从而使梦中的游戏更具挑战性。我们可以通过增加zt+1的取样过程的温度参数τ来增加不确定性。增加不确定性后,梦中环境比实际环境更难了。火球的移动可能更加随机化,沿着相比实际环境更难预测的路径。有时代理甚至可能单纯因为运气不好而莫名其妙地死亡。
我们发现,在高温设定下表现良好的代理通常在普通设定下表现得更好。事实上,增加τ有助于防止我们的控制者利用世界模型的不完美——我们以后将深入讨论这一点。
迁移策略至实际环境
我们测试了在虚拟环境中训练的代理在原VizDoom场景下的表现。100次连续随机测试的成绩是约1100帧,远远超过所需的750帧,也比虚拟环境中的得分要高很多(虚拟环境难度较高)。
左为实际环境帧截图,右为从 潜向量重建的帧
我们看到,尽管V模型不能正确地捕捉每帧的所有细节,比如,怪兽的数量错了,代理仍能使用学习到的策略在真实环境中导航。虚拟环境同时没有留意准确的怪兽数量,而一个可以在更噪杂、更不确定的虚拟噩梦环境幸存下来的代理,将在整洁、无噪的环境下兴旺。
创建世界模型
我们小时候可能遇到以游戏原设计者预料之外的方式进行游戏的情况。玩家发现了收集无穷生命或血条的方法,利用这些漏洞,玩家可以轻易地完成原本困难的游戏。然而,在这么做的过程中,玩家可能丧失了学习技能的机会,按照游戏设计者的意图,这些技能本来是需要玩家精通的。

例如,在我们刚开始的实验中,我们注意到代理发现了一个恶意策略,能够以特定方式移动,从而虚拟环境中由M模型控制的怪兽在一些场次中不发一枚火球。即使出现了形成火球的信号,代理仍然可以通过特定方式的移动魔术般地熄灭火球,就好像代理有超能力一样。
由于我们的世界模型仅仅是一个逼近环境的概率模型,偶尔它会生成不受实际环境的法则约束的轨迹。正如我们之前看到的,即使是房间另一侧的怪兽的数目,都未由世界模型精确再现。正如一个学习空中物体的小孩常常摔倒在地,小孩可能会想象不切实际的在天上飞行的超级英雄。因此,我们的世界模型会有漏洞被控制者利用,即使实际模型并不存在同样的漏洞。
而由于我们使用M模型为代理生成虚拟的梦中环境,我们同样给了控制者访问M的所有隐藏状态的权限。这基本上让我们的代理得以访问所有内部状态和游戏引擎的内存。因此我们的代理可以高效地探索破解直接操作游戏引擎隐藏状态的方法,以最大化它的期望累计奖励。所以,我们的代理很容易就能找到我们的动态模型的对抗样本。
许多之前的研究在RL环境下学习动态模型,但并没有实际使用这些模型完全取代实际环境,原因可能就是上述弱点。使用贝叶斯模型在某种程度上预估不确定性有助于应对这一问题,然而,这并没有完全解决这一问题。最近的研究结合了这一基于模型的方法与传统的无模型RL训练方法,首先基于学习到的策略初始化策略网络,但之后在实际环境中对这一策略的调优必须使用非模型方法。
为了让我们的C模型更难利用M模型中的缺陷,我们选择MDN-RNN作为动态模型。MDN-RNN建模实际环境的可能输出的分布,而不是预测一个决定性的未来。即使实际环境是决定性的,MDN-RNN事实上也会将它作为随机环境加以逼近。这让我们获得了在任何环境的一个更随机的版本中训练C模型的优势——我们可以直接调整温度参数τ以控制M模型中的随机性,从而控制现实性和可破解性的折衷。
使用混合高斯模型可能看起来是杀鸡用牛刀,因为VAE编码的潜向量只不过是对角高斯。然而,混合密度模型中的离散模态对一个带有随机离散事件的环境是有益的。随机离散事件的一个例子是怪兽决定发射火球或静止不动。尽管高斯分布可能足以编码单独的帧,对带有离散随机状态的更复杂的环境而言,配备混合密度输出层的RNN要更容易建模。
我们让温度τ成为M模型的一个可调参数,从而查看在不同水平的随机性下,在幻想出的虚拟环境中训练C模型的效果,以及迁移策略至实际环境的效果。
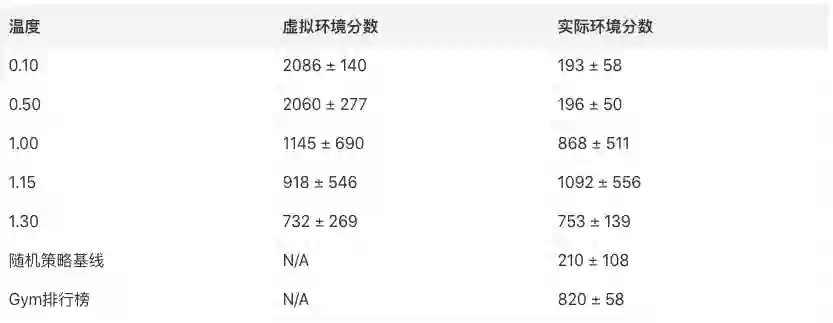
我们看到,虽然增加M模型的温度使C模型更难找到恶意策略,但温度增加过高会导致虚拟环境太困难,以至于代理难以学到东西。因此在实践中这是一个我们可以调整的超参数。温度同时影响代理发现的战略类型。例如,尽管最佳的成绩是温度1.15处的1092 ± 556,将τ增加到1.30会降低分数,但同时也降低了方差,也就是更稳健的战略。作为比较,OpenAI Gym排行榜上的记录是820 ± 58.
迭代训练过程
在上面的实验中,任务相当简单,通过随机收集策略就可以训练出一个合理的世界模型。但是如果我们的环境变得更复杂呢?在复杂环境下,代理在学习导航策略前可能仅可在世界的一部分活动。
更复杂的任务需要迭代训练过程。也就是说,代理将记录探索过程中的行动和观测,然后训练M。如果不足以完成任务,则重新开始探索,并基于扩大了的探索成果再训练M。如此循环往复,直到完成任务。
同时,我们可以改进探索的过程,奖励代理的主动探索行为。特别地,我们可以基于压缩质量的提升增强奖励函数。
在我们目前的方法中,由于M是一个建模下一帧的概率分布的MDN-RNN,如果它表现不好,那么这就意味着代理进入了不熟悉的世界区域。因此我们可以重用M的训练损失函数以奖励代理的好奇心。通过反转M在实际环境下的损失函数的符号,我们可以鼓励代理探索它所不熟悉的世界。它所收集的新数据可能改进世界模型。
更复杂的任务可能需要M模型不仅预测下一个观测x和done,同时预测下一时步的行动和奖励。例如,假设我们的代理需要学习复杂的机动技能以便在环境中行走,那么世界模型将学习仿制自己的C模型,该模型将学习行走。当行走之类的复杂的机动技能被具有很多能力的大型世界模型理解后,较小的C模型可以依赖世界模型已经理解的机动技能,以集中精力学习更高层级的技能。这有点类似肌肉记忆。例如,当你会弹钢琴之后,你不用特意将单个音符转换为手指的移动,这些都在下意识层面编码好了。
迭代训练使C-M模型可以发展出一种自然的层级学习方式。最近RL领域关于self-play和PowerPlay的研究同样在探索导向自然的课程学习的方法。我们觉得这是强化学习最激动人心的研究领域之一。
相关研究
近几年提出的PILCO是一个基于概率模型的策略搜索方法。基于从环境中收集的信息,PILCO使用高斯过程(Gaussian process,GP)模型学习系统动力学,接着使用这一模型取样轨迹,以训练控制者执行所需任务,例如摇动钟摆或骑独轮车。
尽管高斯过程在低维数据的较小集合上表现良好,其计算复杂性使其难以扩展到长期的高维观测。另一些最近的研究使用贝叶斯神经网络取代GP学习动态模型。当状态已知且定义明确,同时观测相对低维时,这些基于贝叶斯神经网络的方法在富有挑战性的控制任务上展示出了有前途的结果。这里,我们感兴趣的是建模观测到的高维视觉数据,我们的输入是原始像素帧序列。
在机器人控制应用中,能够仅仅通过摄像头得到的视频输入学习系统的动力学是一个富有挑战性的重要问题。早期的RL研究训练FNN,接受视频序列的当前图像帧,以预测下一帧,然后使用这一预测模型训练中心凹移动控制网络以尝试在视觉场景中找到目标。为了克服直接学习高维像素图像的动态模型的训练困难,研究人员探索了使用神经网络首先学习视频帧的压缩表示。这一方向上最近的研究通过自动编码器的瓶颈隐藏层学习低维特征向量,以训练控制器基于像素输入控制钟摆。基于压缩潜空间学习模型的动力学使RL算法更加数据高效。我们邀请读者观看Finn的Model-Based RL(基于模型的RL)讲座以了解更多内容。
作为新想法的试验场,视频游戏环境在基于模型的RL研究中同样很流行。Guzdial等使用一个前馈卷积神经网络(CNN)学习视频游戏的前馈模拟模型。对玩游戏的代理而言,学习预测不同的行动如何影响环境中未来的状态是很有用的。因为如果我们的代理可以预测根据当前状态和行动预测未来会发生什么,它就可以直接选择符合其目标的最佳行动。早期的研究和最近的研究都展示了这一点。
上面提到有研究使用FNN预测视频的下一帧,我们可能想要使用能够捕捉长期依赖关系的模型。RNN是适合建模序列的强大模型。在Hallucination with RNNs(RNN造幻)这一讲座中,Graves演示了在雅达利环境下RNN学习概率模型的能力。他训练RNN学习这一游戏的结构,然后展示了RNN可以自行产生相同水平游戏的幻觉。
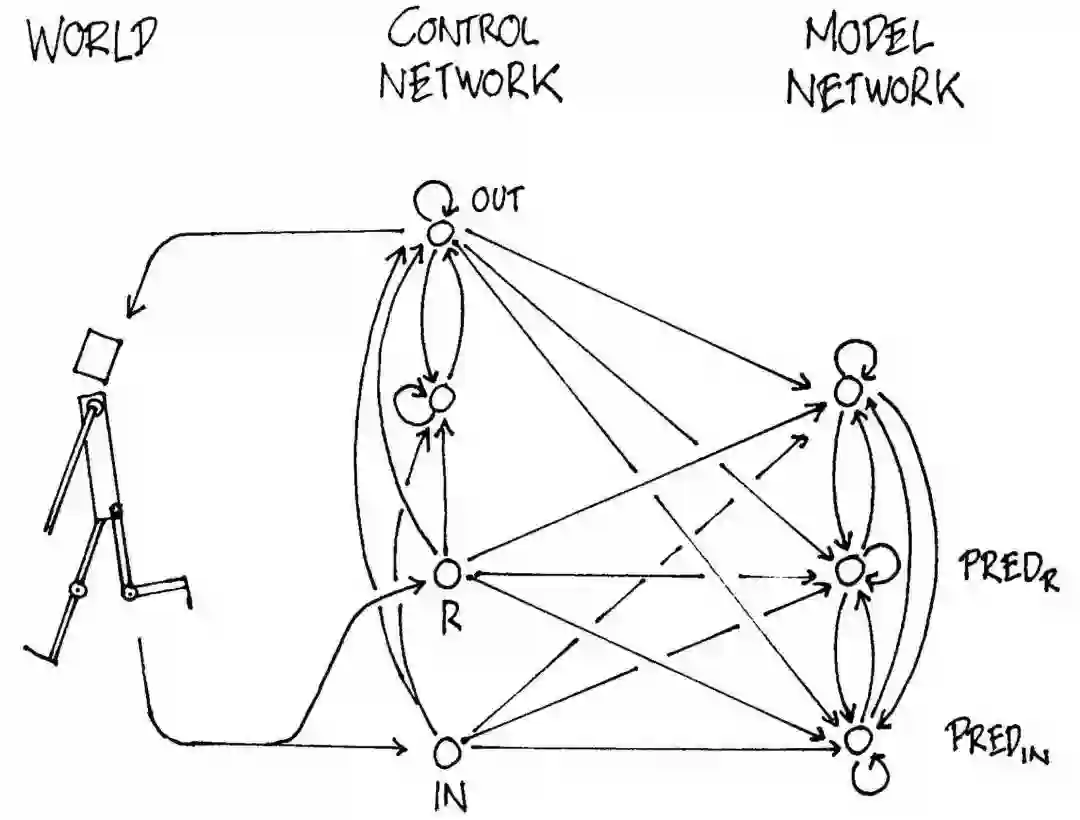
1990年发表的论文Making the World Differentiable(让世界可微)最早探索了如何使用RNN作为内部模型推断未来。最近发表的论文Learning to Think展现了一个统一的框架以构建基于RNN的通用问题求解程序,该求解程序可以学习环境的世界模型,并基于该模型推断未来。后续的研究使用基于RNN的模型生成未来的许多帧,并使用基于RNN的内部模型推断未来。
本文使用演化策略训练控制者,因为它有很多优势。比如,我们只需给优化器提供最终累积奖励,而无需提供整个历史。ES同样易于并行化。最近的一些研究也确认了,在很多强基线任务(strong base task)中,用ES替代传统深度RL方法是可行的。
在深度RL方法流行之前,基于演化的算法已经在求解RL问题上显示出了有效性。基于演化的算法甚至可以解决基于高维像素输入的困难RL任务。最近的研究组合了VAE和ES,和我们的方法比较类似。
讨论
梦中学习
我们展示了完全在模拟的潜空间梦中世界训练代理执行任务的可能性。这一方法有很多优势,比如,运行算力密集的游戏引擎需要将大量计算资源用于渲染图像,或计算和游戏不直接相关的物理。在真实世界中训练代理则更加昂贵。而在模拟环境中训练代理则可以节省算力,也让我们有机会做更多不同的尝试。
可微世界模型
我们的世界模型是完全可微的,因此可以在分布式环境中使用GPU加速我们的世界模型训练。
分别/同时训练V和M
分别训练V模型和M模型有其局限性,因为V模型可能编码和任务无关的观测。毕竟,根据定义,无监督学习无法知道什么对手头的任务是有用的。比如,我们的VAE重建了Doom环境中不重要的墙面砖块纹理,却没有重建赛车环境中和任务相关的地砖(赛车的目标是在尽可能短的时间内通过尽可能多的地砖)。
同时训练V和M可能使VAE学习聚焦图像的任务相关领域,但付出的代价是不经重新训练,可能无法有效地在新任务中复用VAE。
其他表示
以后的工作可能尝试探索使用无监督分割层(比如SE3-Pose-Nets)提取更好的特征表示(也许会比VAE学习到的表示更有用,更好解读)。
LSTM的局限
尽管我们的迭代训练过程中使用的存储设备能储存大量历史信息,基于LSTM的世界模型很可能无法将所有记录的信息保存在权重连接之中。以后的工作中,如果我们想让代理学习探索更复杂的世界,我们可能会探索使用“记性更好”的模型,比如:
稀疏门控专家混合层
超网络
循环高速超网络
WaveNet
Transformer
或者,我们可能包含一个外部的记忆模块。
计划和推断
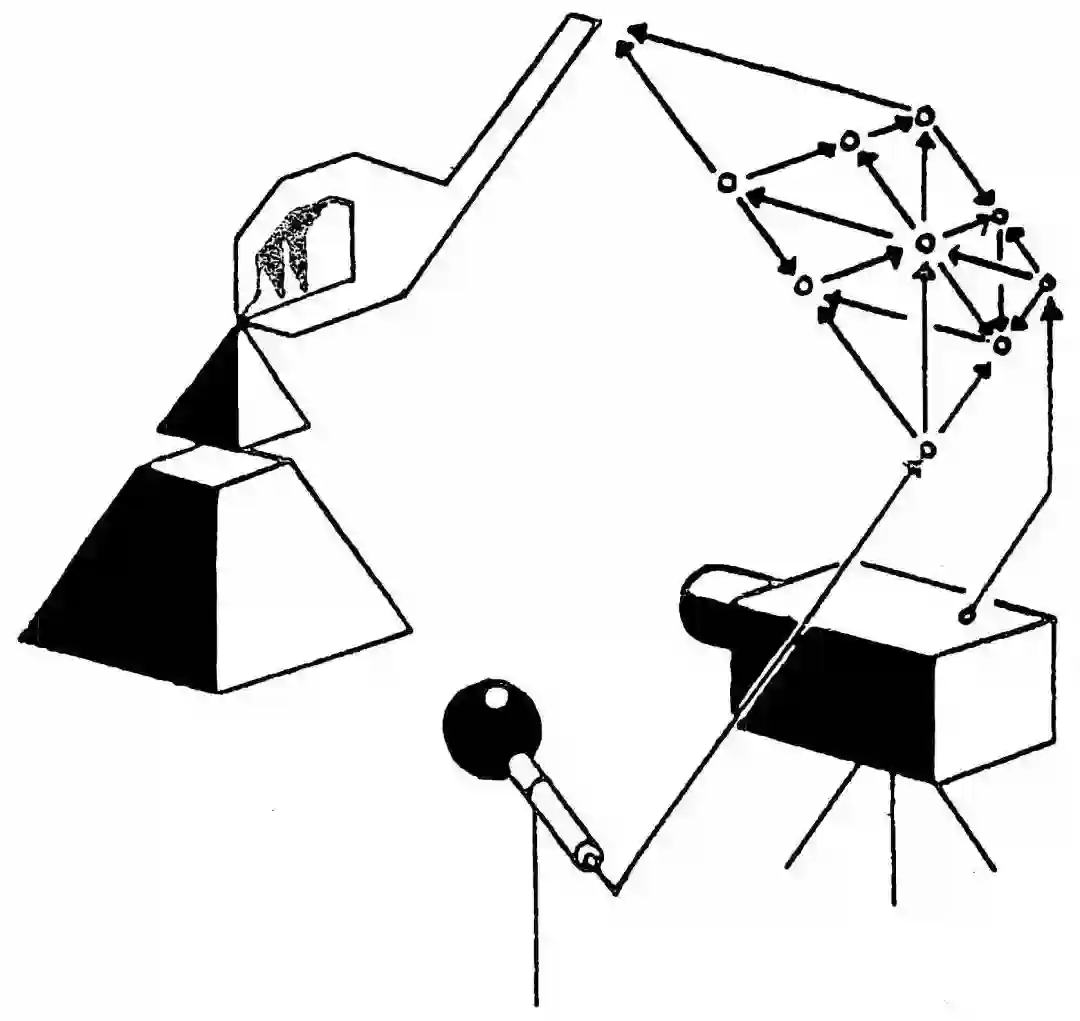
和早期的基于RNN的C-M系统一样,我们的模型据时步模拟可能的未来,而没有使用类似人类的层级计划和抽象推断(经常忽略无关的时空细节)进行优化。不过,更一般的Learning To Think方法并不局限在这一非常幼稚的方法。相反,它允许一个循环C学习处理循环M的“子过程”(subroutine),然后以任意的可计算方式重用子过程以求解问题,例如,通过层级计划或其他利用M的类似程序的权重矩阵的手段。最近的C-M方法扩展One Big Net将C和M塌缩为单一网络,并使用类似PowerPlay的回放(其中,教师网络的行为被压缩进学生网络)来在学习新内容时避免遗忘旧预测和控制技能。试验这些更一般的方法留待以后。
引用
如果你的研究需要引用本篇论文,可以使用如下格式:
Ha and Schmidhuber, "World Models", 2018. https://doi.org/10.5281/zenodo.1207631
BibTex格式:
@article{Ha2018WorldModels,
author = {Ha, D. and Schmidhuber, J.},
title = {World Models},
year = {2018},
url = {https://worldmodels.github.io},
doi = {10.5281/zenodo.1207631}
}
原文地址:https://worldmodels.github.io/





